TimeSeries 임베딩 : Rocket
다음과 같은 행동 순서가 있다고 치자
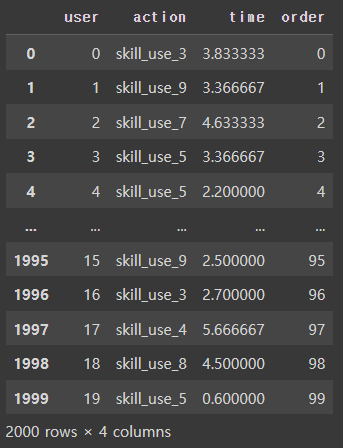
- 무작위 11가지 행동을 하며
- 시간차는 대략 포아송 분포를 따르게 했다.
- 20명의 100개 액션 시퀀스로 볼 수 있다.
def create_action(x=None):
x = np.random.poisson(5, 1)
for i in range(1,11):
if x<i:
return f'skill_use_{i}'
return 'skill_use_11'
def create_time(x=None):
x1 = np.random.poisson(5, 1)
x2 = np.random.poisson(6, 1)
return x1[0]/1.5 + x2[0]/10
def create_user(x):
user = x%20
return int(user)
def create_order(x):
user = x%100
return int(user)
action_seq['action'] = action_seq['action'].apply(lambda x : create_action(x) )
action_seq['user'] = action_seq.index
action_seq['user'] = action_seq['user'].apply(lambda x : create_user(x) )
action_seq['order'] = action_seq.index
action_seq['order'] = action_seq['order'].apply(lambda x : create_order(x) )
action_seq['time'] = action_seq['time'].apply(lambda x : create_time(x) )
action_seq이걸 임베딩을 하는 방법은 정말 여러가지 이다.
그런데 이왕이면
- Unsupervised 하면서
- 빠르고 가벼웠으면 한다.
그런 방법 중에 Rocket 이라는게 있어서 써본다.
ROCKET: Exceptionally fast and accurate time series
classification using random convolutional kernels



컨셉 자체는 가중치가 랜덤으로 세팅된 10000개의 Convolution layer 를 생성한 뒤, 각 레이어를 통과시키는 것이다.
대조군으로 순차적으로 5개 행위를 반복하는 시퀀스를 생성한다.
- 특이사항으로 시간차가 약간 존재하지만 대체로 3초 부근으로 고정되어 있다.
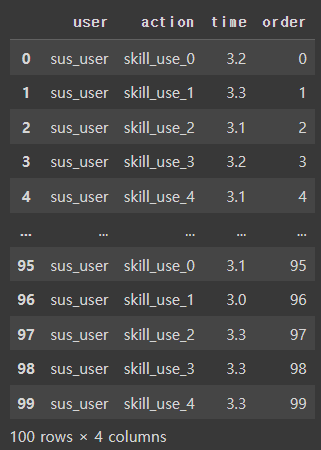
i = x%5
return f'skill_use_{i}'
def create_sus_time(x=None):
x = np.random.poisson(2, 1)
return 3+(x[0]/10)
sus_seq = pd.DataFrame(np.zeros((100,3)) , columns=['user','action','time'])
sus_seq['user'] = sus_seq.index
sus_seq['action'] = sus_seq['user'].apply(lambda x : create_sus_action(x))
sus_seq['order'] = sus_seq.index
sus_seq['order'] = sus_seq['order'].apply(lambda x : create_order(x) )
sus_seq['time'] = sus_seq['user'].apply(lambda x : create_sus_time(x))
sus_seq['user'] = 'sus_user'
sus_seq이후에는 별거없다.
trf = MiniRocketMultivariate(num_kernels=512)
trf.fit(action_seq_dummies)
21명의 시퀀스가 임베딩되었다.
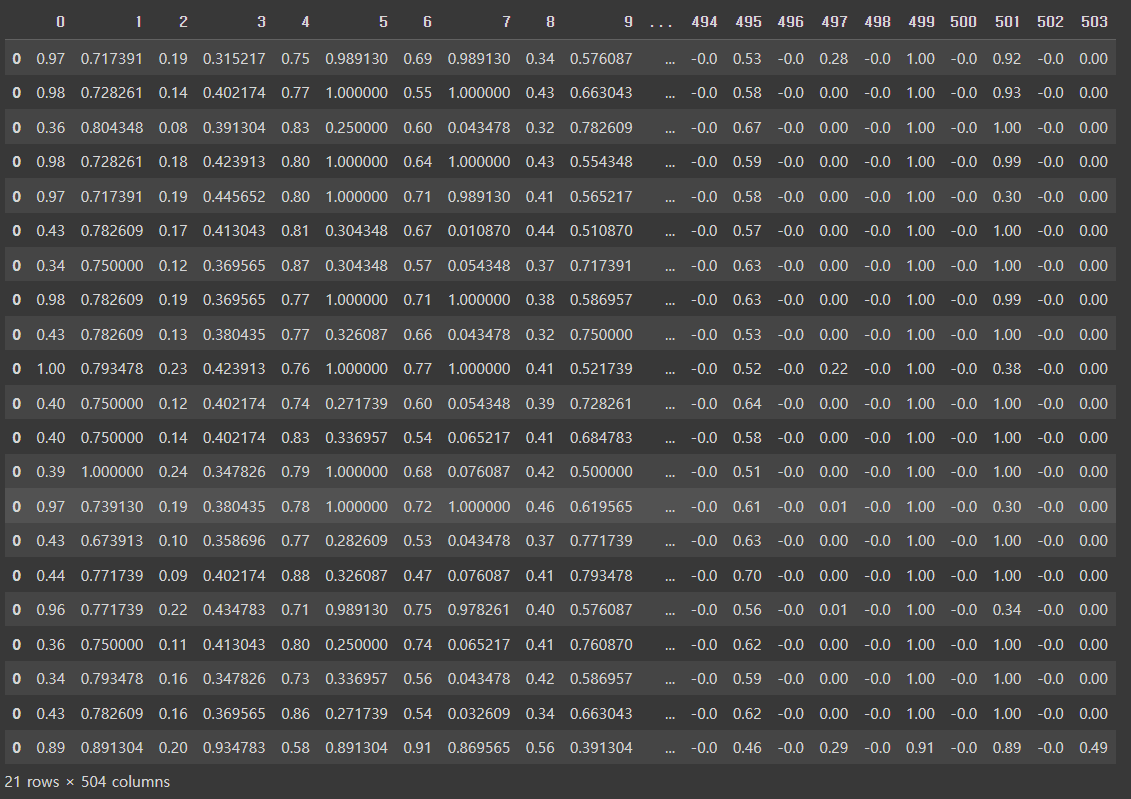
잘 될수도 안될수도 있다.
PCA로 시각화를 해서 보자.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
# pca_model = pca.fit(result)
pca_result = pca.fit_transform(result)
pca_result = pd.DataFrame(pca_result, columns=['x','y'])
pca_result
pca_result['label'] = int(0)
pca_result.loc[20,'label'] = int(1)
pca_result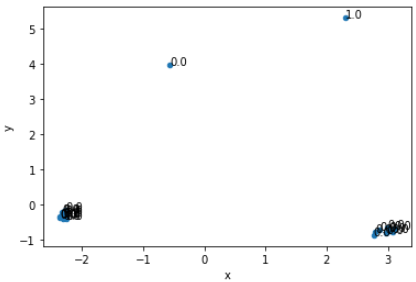
흠..
- ref : SKTIME https://github.com/sktime/sktime/tree/main/sktime

공부용 혹은 정리용 혹은 개인저장용