(매우 흥미로운) 우버의 xgboost > deep 전환기
출처 : https://eng.uber.com/deepeta-how-uber-predicts-arrival-times/
For several years, Uber used gradient-boosted decision tree ensembles to refine ETA predictions.
The ETA model and its training dataset grew steadily larger with each release.
To keep pace with this growth, Uber’s Apache Spark™ team contributed upstream improvements [1, 2] to XGBoost to allow the model to grow ever deeper, making it one of the largest and deepest XGBoost ensembles in the world at that time.
Eventually, we reached a point where increasing the dataset and model size using XGBoost became untenable. To continue scaling the model and improving accuracy, we decided to explore deep learning because of the relative ease of scaling to large datasets using data-parallel SGD [3]. To justify switching to deep learning we needed to overcome three main challenges:
- Latency: The model must return an ETA within a few milliseconds at most.
- Accuracy: The mean absolute error (MAE) must improve significantly over the incumbent XGBoost model.
- Generality: The model must provide ETA predictions globally across all of
Uber’s lines of business such as mobility and delivery.
To meet these challenges, Uber AI partnered with Uber’s Maps team on a project called DeepETA to develop a low-latency deep neural network architecture for global ETA prediction.
기존에 우버에선 Xgboost 로 ETA(예상도착시간)를 예측했었는데,
데이터가 너무 커짐에 따라 Xgboost로 더 깊게 더 큰 모델을 학습하기 어려운 수준에 이르렀다고 한다.
3가지 요건 ( 실시간 서비스를 위한 밀리세컨드 이내 응답성, 정확도, 범용성(택시와 배달 서비스에 적용)을 만족하는 딥러닝 구조를 만들었다.
모델 구조
The DeepETA team tested and tuned 7 different neural network architectures:
MLP [4],
NODE [5],
TabNet [6],
Sparsely Gated Mixture-of-Experts [7],
HyperNetworks [8],
Transformer [9]
and Linear Transformer [10].
We found that an encoder-decoder architecture with self-attention provided the best accuracy.

Figure 2 illustrates the high-level architecture of our design. In addition, we tested different feature encodings and found that discretizing and embedding all of the inputs to the model provided a significant lift over alternatives.
우버는 셀프 어텐션을 가진 인코더/디코더 구조를 채택했다.
그리고 피쳐 엔지니어링에 대해서, 기존과는 다른 방법 ( 수치형을 범주형으로 만든 다음 임베딩 하는 것 ) 이 성능을 매우 올려주었다.
Encoder with Self-Attention
Many people are familiar with the Transformer architecture because of its applications in Natural Language Processing and Computer Vision, but it might not be obvious how Transformers can be applied to tabular data problems like ETA prediction. The defining innovation of Transformer is the self-attention mechanism. Self-attention is a sequence-to-sequence operation that takes in a sequence of vectors and produces a reweighted sequence of vectors. Details can be found in the Transformer paper [9].
트랜스포머 구조는 보통 MLP나 비전(Vit)에서 많이 쓰이는데,
아직 정형 데이터에서는 연구가 부족하다.
트랜스포머 구조의 혁신은 self 어텐션 구조에서 온다.
셀프 어텐션은 하나의 벡터에 대해서 seq2seq 동작(연산)을 하는데 가중치가 재조정된 시퀀스의 벡터를 산출한다!
In a language model, each vector represents a single word token, but in the case of DeepETA, each vector represents a single feature, such as the origin of the trip or the time of day.
NLP에서는 각 벡터가 하나의 단어 토큰을 의미하는데(w2v같이) 정형 데이터에선
하나의 피쳐를 벡터로 표현한다.
Self-attention uncovers pairwise interactions among the K features in a tabular dataset by explicitly computing a K*K attention matrix of pairwise dot products, using the softmax of these scaled dot-products to reweight the features.
k개의 변수가 있으면 행렬 곱연산을 통해(interaction을 보기 위해 이렇게 함) k x k 행렬을 생성한 후, 인풋으로 받아서 어떤 상호작용이 있는지 밝혀낸다.
k x k 행렬에서 소프트 맥스를 쓴다는데
When the self-attention layer processes each feature, it looks at every other feature in the input for clues and outputs the representation of this feature as a weighted sum of all features. This process is illustrated in Figure 3.
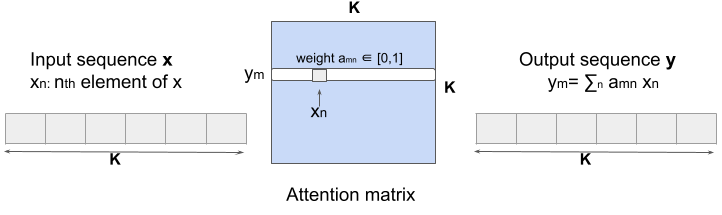
세로 열 기준으로 0~k 개를 위에서 순차적으로 쓱 훑고 내려오면
셀프 어텐션에서의 연산이 weighted sum 형태로 피쳐가 나오게 됩니다.
Through this way, we can bake the understanding of all the temporal and spatial features into the one feature currently being processed and focus on the features that matter. In contrast to language models, there is no positional encoding in DeepETA since the order of the features doesn’t matter.
일시적이고 지역 정보를 하나의 피쳐로 그리고 어떤 피쳐에 집중해야 되는지 알 수 있게 됩니다.
NLP와 반대로 위치 정보는 소실됩니다. 피쳐의 순서에 의미가 없으니까요.
중간 결론 :
피쳐 임베딩 부분이 상당히 흥미로운데
수치형 데이터 A 에 대해서
A_1, A_2, A_3 ... A_10 과 같이 끊어 놓는다면 K의 값이 상당히 커질 것 같은데
내가 이해한게 맞나 싶다.
