아리마2
자동상관(auto-correlation)의 문제
자동상관이 있으면 무슨 문제가 있는가?
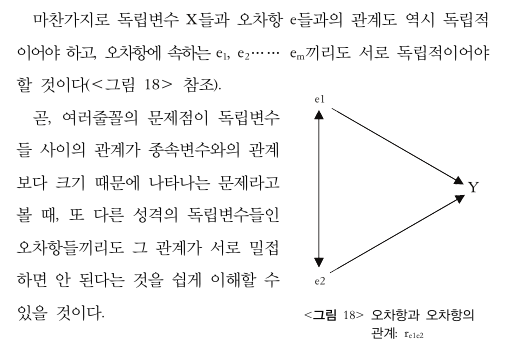
시계열 자료에서 나타나는 오차항과 오차항 간의 상관관계를 통틀어 serial correlation 이라고 한다.
시계열 자료의 경우 과거의 상태가 현재의 상태에 영향을 미치는 경우가 흔하다.
( 인구수 증가나 GDP의 증가는 전년도의 영향을 많이 받는다 )
이런 경우 만들어낸 회귀모형에서는 오차항들 사이에 자동상관의 문제가 발생한다.
자동상관이 발생하면 무슨 문제가 있는가?
모수 추정값이 불편성을 만족하더라도, 이게 적절하다고 볼 수 없다.
왜냐하면 자동회귀는 R 스퀘어 값을 실제보다 증가시키는 경향이 있기 때문이다,

위 이유로 회귀분석은 오차항들 사이에 자동상관이 존재하지 않아야 한다는 것을 전제로 한다.
이를 통계학적으로 표현하면
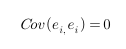
어느 한 시점의 오차항의 값은 다른 기간의 취했던 오차항의 값과 관련되어 있지 않다는 것을 뜻한다. ( Cov : 같이 움직이는 방향성을 뜻함 )

자동상관을 찾아내는 방법
1: Geary test
- 잔차들의 부호의 변화가 + - + - + - 바뀐 횟수를 찾아내는 방법이다.
- 만약 자동상관이 존재한다면 이러한 부호 변화가 굉장히 많아진다.
- 단순하지만 표본의 수가 많을때 쓸 수 있다.
2: Durbin Watson's d
- 더빈 와슨의 d값은 가장 널리 쓰이는 방법
4가지 조건을 만족하는 d값을 가정한다.
1 : 회귀 모형에 상수가 포함되어 있어야 한다
2 : 독립변수가 비확률적 변수이다.
3 : 시차 종속변수가 독립변수로 포함되어 있지 않아야 한다.
4 : 잔차들이 1차 자동회귀 계열(first order autoregressive series)를 구성한다.
( 무슨 말이나면, t 시점의 잔차(e_t) = t-1 시점의 잔차(e_t-1)의 1차 선형 방정식 꼴이라는 것이다. e_t = k * e_t-1 + v_t
여기서 k 는 임의의 계수 ( 자동상관 계수 ) 이고,
v_t 는 평균이 0인 정규 분포를 이루는 오차항이다.
여기서 더빈 와슨의 d 값은 k(자동상관계수)값이 0이라는 가설을 검증하는 것이다.
자동상관이 있을때 해결하는 방법
1: OLS 말고 좀더 일반화된 Genralized least square 방법을 쓴다. ( GLS )
2: Cohrance Orcutt 방법
3: 1차 차분한 후 OLS 방법으로 추정하는 경우. 이건 자동상관 계수가 1에 가까운 경우일때 사용한다. 그렇지 않으면 잘못된 결론을 내리기 쉽다.
아리마 시계열 분석
시계열 분석의 의미와 종류
시계열 분석의 의미 : 시간의 흐름에 따라 변화하는 변수를 분석하는 방법
회귀 분석 : 변수와 변수의 관계를 회귀 모형을 잡아내어 인과관계를 검증하는 것을 목적으로 하지만.
시계열 분석 : 하나의 변수가 시간의 흐름에 따라 움직이는 것을 수리 모형으로 잡아내어 미래를 예측하기 위한 것.
물론 시계열 분석에서도 회귀분석에서처럼 변수와 변수의 관계를 찾아내거나, 어떤 시점의 사건이 변수에 미친 영향을 시계열 모형을 통해 찾아낼수도 있지만.
이때에도 각각의 변수들을 대상으로 시간의 흐름에 따른 한 변수 시계열 모형을 만들고 난 뒤, 이를 가지고 여러 변수 시계열 모형을 만드는 것.
결국 시간의 관계를 모형화 하는것이 바탕이 된다.
이러한 시계열 모형의 종류
- 단변량 아리마 모형
- 하나의 변수가 시간의 흐름에 따라 어찌 변화되는가
반면 어떤 사건이 있을 떄 그 사건이 어떤 변수에 영향을 얼마나 줬는지 알아내기 만드는게 impact 모델이다.
한편 회귀분석처럼 두 변수의 관계를 찾아내기 위해 만드는 시계열 분석 모형이 다변량 아리마 모형이다.
시계열분석의 기본 모형
1. 정상성
시간 t를 x축에 놓고 Y의 변화를 볼 때 여러 형태가 존재한다.
증가 패턴, 감소 패턴, 오르락 내리락 패턴.
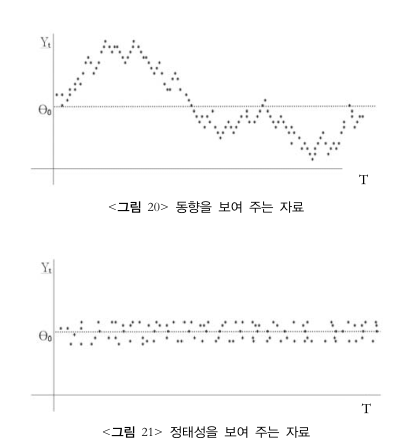
증가 패턴, 감소 패턴을 추세 trend 라 부르고 오르락 내리락을 동향 drift라고 한다.
이처럼 시간의 흐름에 따라 변화하는 Y를 모형으로 만들어 설명하기 위해서는 정상성 이라는 개념을 이해해야 한다.
계속 증가/감소하는 Y나 오르락내리락하는 Y나 모두 과거의 자기 자신이 변화함으로써 현재의 Y에 도달해 있는 것이다.
추세나 동향은 계속 변하는 것이다.
시간이라는 독립 변수를 집어넣지 않는 한 이를 설명할 수 있는 모형을 만들어내기 쉽지 않다. 그러나 시간을 변수로 넣어버리면 왜 그런지에 대한 설명을 시간이라는 변수가 모두 설명해버려서 우리가 원하는 X 와 Y의 관계를 설명할 수 없어진다.
만약 추세와 동향이 시간의 흐름에 관계없이 일정한 균형 수준을 유지할 수 있다면 이를 모형화하기 쉬워진다.
시계열 자료 자체가 동태적(dynamic)이기 떄문에 이 자료를 변환시켜 균형 수준을 유지하게 만들면 동태적인 성격은 없어지고 자료는 정상적이게 된다.
시간의 흐름에 상관없이 일정 수준에서 균형을 보여주는 모형을 만들 수 있다.
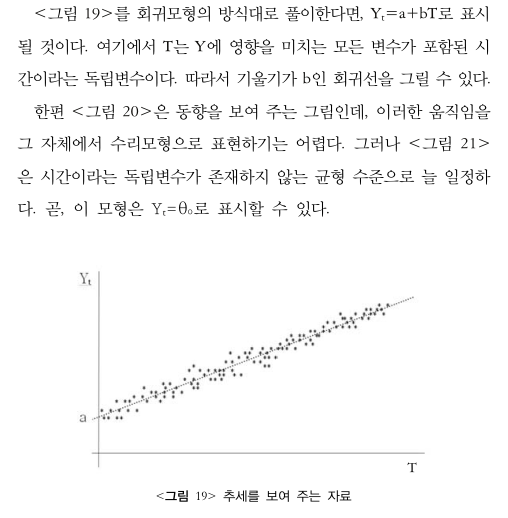
회귀분석에서는 회귀선을 찾아내는 것을 목적으로 하지만
시계열 분석에서는 정상성을 갖는 것이 첫 걸음이다.
곧 추세나 동향을 나타내주는 관찰값들을 그림 21처럼 만드는 것이 시계열 분석 모형을 만들기 위해 제일 먼저 해야할 일이다.


2: 시계열 분석의 기본 모형
위에서 시계열 분석 모형은
시계열 모형의 균형 수준을 나타내는 Theta_0 와
노이즈를 나타내는 N_t 로 구성됨을 알고 있다.
그런데 이런 교란항(N_t)은 자동회귀 요소와 이동평균 요소가 있는데 이를 표현하면
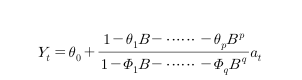
이전 식을 이렇게 표현할 수 있다.
수식이 나오니 머리가 아프다.
t 시점의 Y는 현재 시점이라고 했을때,
theta_0 는 시계열의 균형 수준이고
theta_1 ~ theta_p 는 이동평균 요소들의 모수 값이며
pie_1 ~ pie_p 는 자동회귀 요소들의 모수 값이다.
B는 부호이고
a_t는 노이즈 요소를 나타낸다.
(주석 : 수식의 형태에 대해서 생각해보자)
왜 분자에 MA 요소가 있고 분모에 AR 요소가 있을까?
그리고 분자의 형태를 상상해보자.
Y | 0 +1 +3 +5 +3 +1 0 -1 -3 -5 -3 -1 0
X | 0 0 0 0 0 0 0 0 0 0 0 0 0
d | 0 +1 +2 +2 -2 -2 -1 -1 -2 -2 +2 +2 +1

3: 모형의 형태와 종류
시계열 모형을 보통 아리마 모형이라고 부르지만
엄밀히는 differencing(추세나 동향 제거), auto-regressive(AR), moving-average(MA) 의 세가지 요소가 다 포함되어 있는 모형을 일컫는다.
노이즈의 형태에 따라 (1)AR 모형과 (2)MA 모형으로 나눌 수 있다.
(1) AR 모형
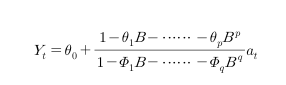
MA 요소인 theta_1 ~ theta_p 가 없는 경우, 값은 0이고
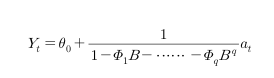
인 형태의 모형이라고 볼 수 있다.


(2) MA 모형
분모의 파이가 모두 0이므로


시계열 분석의 모수 추정 방법
정상성 확보
-
ACF 나 PACF를 조사한다.
-
정상성이 없다. (= 추세나 동향이 존재한다. ) 관찰 값들을 차분함으로써 정상성을 확보한다.
-
그래도 정상성이 없다면 2차 차분한다.
-
2차 차분했는데도 정상성이 없다면 Y를 로그화 하여 차분한다.
한편 때에 따라서는 계절적으로 차이화함으로써 정상성을 확보하기도 한다.

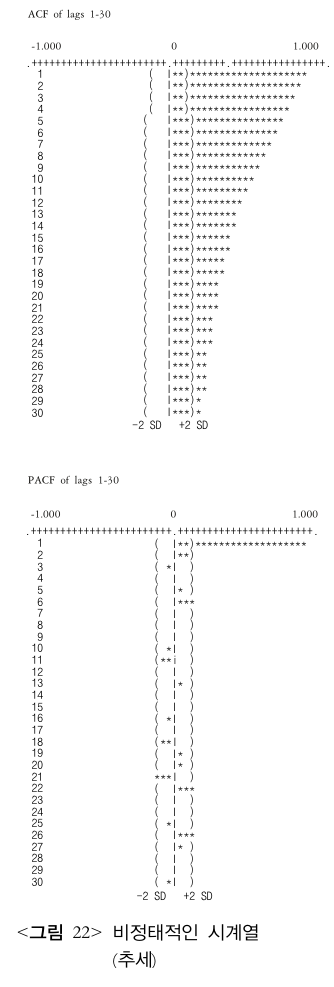
ACF 와 PACF가 시차 1에서 큰 값을 가지고 천천히 소멸한다면,
노이즈가 시간의 영향을 크게 받고 있는 것이므로 정상성이 없다고 볼 수 있다.
이를 정상성을 갖도로 해야 한다.
