Linux Kernel에서 동시성(Cuncurrency)문제를 해결하기 위해 많이 사용하는 Mutex와 Spinlock의 차이에 대해 알아보자.
Preemtion and Synchronization
우선 Preemtion과 동시성 문제가 무엇인지 알아보자. 커널이 선점 가능하다(preemtible하다)는 의미는 한 프로세스가 이미 커널의 코드를 수행중이라도 자신의 의지와는 상관없이 다른 프로세스로 제어권이 양도 될 수 있다는 뜻이다. single processor 라고 하더라도 각각의 프로세스들이 커널을 선점할 수 있다.(preemptive multitasking) 따라서 각 프로세스들 공유자원에 접근할 수 있다. 때문에 single processor에서 동시성 문제가 발생할 수 있다.
커널에서는 인터럽트/ 커널의 선점/ 멀티 프로세싱/ 지연함수. 이 4가지가 동시성(cuncurrency) 문제를 발생 시킬 수 있다.
(나무위키)
프로그램은 실행되면 프로세스가 되고 프로세스는 역시 여러 쓰레드를 실행시키는데 여러 프로그램에서 만들어지는 이 쓰레드는 CPU라는 한정된 자원을 서로 사용하고자 경쟁중인 관계에 있다. 그러므로 운영체제는 CPU의 시간을 나누어 여러 쓰레드 들에게 돌아가며 실행하도록 하는데, 이 때 CPU를 차지하고 있는 쓰레드가 자신이 이제 CPU 연산이 필요 없음을 나타냈을 때에만 운영체제가 이를 회수할 수 있는 경우를 비선점형 멀티태스킹이라고 하고, 프로세스가 CPU를 차지해서 사용하더라도 운영체제가 타이머나 여타 트리거를 통해 개입하여 강제로 CPU 사용을 빼앗아 올 수 있는 경우를 선점형 멀티태스킹이라고 한다. 쉽게 말해 운영체제가 응답없는 프로세스를 강제로 죽이고 자시고 할 수 있으면 선점형, 그게 안 돼서 닥치고 리셋해야만 하는 경우라면 비선점형이다. 선점형 멀티태스킹은 스케줄러에 따라 차이가 지긴 하지만, 원론적으로는 보통 시간을 따로 정해 놓고 이 시간마다 선점(preemption)이 일어나는데, 이 시간 단위를 퀀텀 혹은 슬라이스라 한다. 퀀텀이 너무 낮으면 프로세스 바꾸는데 소모되는 리소스가 커지고, 퀀텀이 너무 높으면 반응 속도가 느려진다. 보통 빠른 타수의 사람이 키를 입력하는 속도가 약 100ms 정도이기 때문에, 퀀텀도 이정도 수준에서 좀더 낮게 결정되는 경향이 있다. 리눅스의 경우 퀀텀을 따로 설정할수도 있긴 하지만, 어차피 리눅스에서 디폴트로 사용하는 CFS 스케쥴러는 상황을 보면서 작동하기때문에 퀀텀대로만 선점을 하지는 않는다.
TL;DR
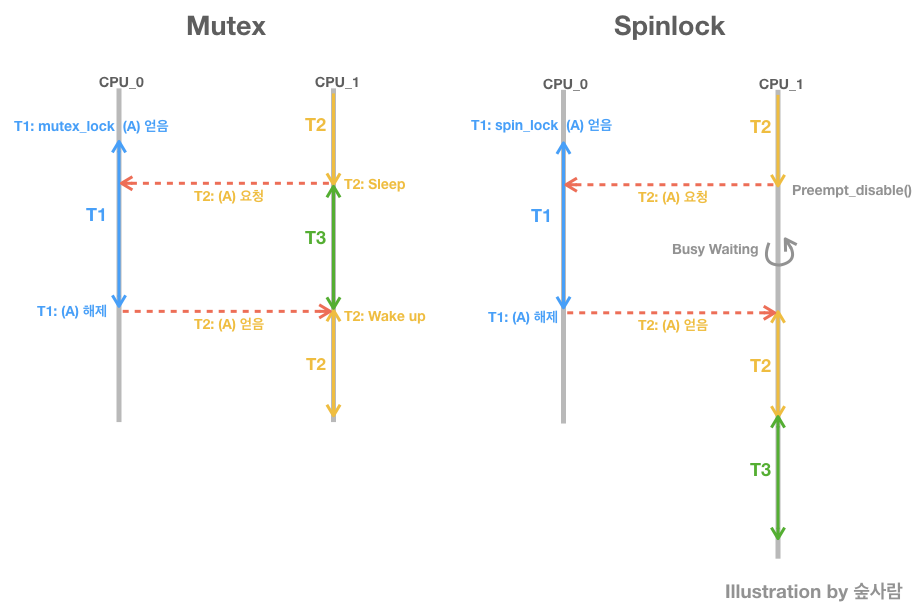
Mutex와 Spinlock 동작을 요약하면 아래 그림과 같다.
Semaphore & mutex
T1(Task 또는 Thread 1)이 이미 lock을 잡고 있는 상태에서 Task 2가 lock을 잡으려고 할때, 세마포어는 T2를 wait queue에 넣고 sleep상태로 만든다. 따라서 그사이 CPU1에는 다른 스레드(T3)가 수행된다.
세마포어는 counter 수 만큼의 프로세스가 동시에 자원에 접근 가능하다. 화장실 칸이 4개 이고 키가 4개이면 4명까지는 대기없이 바로 사용가능 하다는 뜻. 뮤텍스는 바로 키가 1개인 세마포어다.
세마포어가 mutual exclusion을 위해 사용될때 뮤텍스라고 부름. (리눅스에서 사용되는 거의모든 세마포어는 뮤텍스로 사용됨) Mutex 는 상태가 0, 1 두 개 뿐인 binary Semaphore이다. Mutex는 동기화 대상이 오직 하나뿐일 때, Semaphore는 동기화 대상이 하나 이상일 때 사용한다.
인터럽트 컨텍스트에서는 세마포어를 사용할 수 없다. 컨택스트에서는 태스크 스케줄링이 일어나면 안되기 때문. (ISR 이 sleep이 일어나면 안됨). 세마포어와 뮤텍스는 spinlock 보다 긴 시간을 기다려야하는 상황에서 자주 사용된다.
-
static
declare_semaphore_generic(name, count);count를 1로 하면 뮤텍스가 됨.
static declare_mutex(name)
아얘 뮤텍스용 인터페이스도 있음 -
궁금증: 인터럽트 핸들러에서는 mutex를 사용하면 안된다. 그런데 만약 핸들러를 request_threaded_irq()로 등록했다면? mutex로 보호해도 되나? 어차피 인터럽트 핸들러가 스케줄링되기 때문이다. 어쩌면 사이즈가 큰 threaded irq handler는 spinlock이아니라 무조건 mutex로 보호해야할지도? spinlock으로 보호하면 lock을 기다리는 다른 스레스의 cpu를 그만큼 사용할 수 없기 때문이다.
Spinlock
Spinlock의 경우 T2가 spinlock을 요청하고 T1이 spinlock을 해제할 때까지 CPU1은 Busy Waiting을 한다. 따라서 그 시간동안 CPU1은 사용할 수 없다.
Spinlock의 등장 배경은 다음과 같다. 위에서 살펴본것처럼 mutex의 경우, T1이 lock을 잡고 있는경우 T2는 sleep된다. 그러나 Critical section이 매우 짧은 경우, mutex는 퍼포먼스 낭비가 있다. sleep은 몸집이 큰 동작이다. T2가 sleep을 하기 위한 작업을 하는 시간에 lock이 풀릴 수 있기 때문이다.
커널의 많은 함수들은 태스크가 sleep상태로 들어가면 안 되는 부분이 많이 있다. 커널 코드가 인터럽트 컨텍스트에서 수행되고 있을 때가 바로 그 때이다. 이때 sleep 상태로 들어가면 안 되는 이유는 현재의 태스크의 커널 스택에 nesting된 인터럽트의 복귀 주소와 문맥(CPU register set)이 들어가 있기 때문이다. (인터럽트 Nesting: 인터럽트 문맥에서 또 다른 인터럽트 실행되는것)
이 경우에 Spinlock을 사용한다. 한 CPU가 특정 플래그의 상태를 보며 루프를 돌며 busy-wating 하고 있는것. 장점은 세마포어보다 가볍다. 물론 기다리고 있는 동안의 CPU 사용을 유용한 곳에 쓰지 못한다는 단점이 있긴 하지만 짧은 시간 동안(짧은 코드 수행영역)의 lock이라면 spinlock을 사용하는 것이 효율적이다.
기다리고 있는 동안의 CPU를 사용할 수 없는 이유는 lock을 얻기전에 preempt_diable() 을 수행하여 해당 cpu가 preemption이 안되게 막기 때문이다. 다른 프로세스가 강제로 해당 cpu 를 선점(preempt)해서 사용할 수가 없다. spin_lock을 요청한 프로세스는 해당 cpu를 독점하며 기다리고 있다.
As should be obvious from the above, using spin locks can gum up the whole machine so spin locks should just be used for very short periods of time and you should never do anything that might cause a reschedule whilst holding a lock.
The case with mutex_lock is totally different - only threads attempting to access the lock are affected and if a thread hits a locked mutex then a reschedule will occur. For this reason mutex_locks cannot be used in interrupt (or other atomic) contexts.
(https://stackoverflow.com/questions/6555358/linux-kernel-preemption-during-spin-lock-and-mutex-lock)
커널의 주요 API는 다음과 같다.
spin_lock_irq()
Thread A가 spinlock을 잡고 일을 하고 있다. 그 도중 인터럽트가 발생했다. 그 인터럽트 핸들러가 동일한 spinlock을 잡으려고 하는 경우. deadlock이 발생한다. 어떻게 처리하나? 이 문제를 해결하기 위해 spin_lock_irq() 사용. spinlock을 잡으면서 인터럽트를 disable 시켜준다.
spin_lock_irq_save()
하지만 함수 call path가 깊어지고 nesting된 spin_lock_irq가 사용되는 경우 spin_lock_irq()사용 어려움. 인터럽트는 몇번을 disable 했던지 한번만 enable하면 인터럽트가 다시 복구된다. 그러면 spin_lock_irq()를 수행하려고 할때, 만약 현재 인터럽트가 enable인지 disable상태인지 모르면, spin_unlock()을 할때 enable을 할지말지 알 수가 없다. 이 때, spin_lock_irq_save() 사용. irq를 disable함과 동시에 이전에 irq가 enable/disable인지 여부를 변수에 저장해 놓는다. (저장할 변수를 인자로 받음)
다음의 경우에 이함수를 사용하는게 좋다.
- spinlock을 이용하는 시점에서 interrup enable을 확신할 수 없는 경우
- call path가 깊은경우
- spin_lock_irq를 nesting해서 사용할 경우
spin_lock_irq_save() > spin_lock_irq() > spin_lock() 순으로 퍼포먼스 오버헤드가 크다.
참고
-
Proper Locking Under a Preemptible Kernel: Keeping Kernel Code Preempt-Safe
https://www.kernel.org/doc/Documentation/preempt-locking.txt- RULE #3: Lock acquire and release must be performed by same task
-
커널의 동기화에 관하여(김민찬)
https://www.linux.co.kr/bbs/board.php?bo_table=lecture&wr_id=1642&sst=wr_hit&sod=asc&sop=and&page=118 -
http://egloos.zum.com/nimhaplz/v/5301468 (spin_lock_irq 참고)
