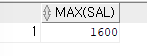PART2
-UPPER,LOWER,INITCAP
-SUBSTR
-LENGTH
-INSTR
-REPLACE
-LPAD,RPAD
-TRIM,RTRIM,LTRIM
-ROUND
-TRUNC
-MOD
-MONTHS_BETWEEN
-ADD_MONTHS
-NEXT_DAY,LAST_DAY
-TO_CHAR
-TO_DATE
-NVL,NVL2
-DECODE,CASE
-MAX,MIN,AVG,SUM,COUNT
-RANK,DENSE_RANK
-NTILE
-CUME_DIST
-LISTAGG
-LAG,LEAD
-SUM+DECODE
-PIVOT,UNPIVOT
-SUM OVER
-RATIO_TO_REPORT
-ROLLUP,CUBE,GROUPINGSETS
-ROW_NUMBER
PART 2
- 대소문자 변환 함수
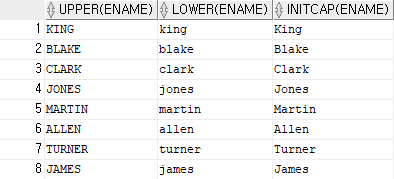
ex)사원 테이블의 이름을 출력하는데 첫 번째 컬럼은 이름을 대문자로 출력하고,
두번째 칼럼은 이름을 소문자로 출력하고,세 번째 컬럼은 이름의 첫 번째 철자는 대문자로 하고,나머지는 소문자로 출력SELECT UPPER(ename),LOWER(ename),INITCAP(ename) FROM emp;
=>
UPPER: 대문자로 출력
=>LOWER:소문자로 출력
=>INITCAP:첫 번째 철자만 대문자로 출력,나머지는 소문자로 출력
- 함수: 다양한 데이터 검색을 위해 필요한 기능
-단일행 함수:하나의 행을 입력받아,하나의 행 반환
ex)문자함수,숫자함수,날짜함수,변환 함수,일반 함수
-다중 행 함수:여러 개의 행을 입력 받아,하나의 행반환
ex)그룹 함수
- 문자 함수:UPPER,LOWER,INITCAP,LENGTH,CONCAT,INSTR,
TRIM,LPAD,RPADUPPER함수와 LOWER함수는 테이블 내 특정 문자 검색 시,
데이터가 대문자인지 소문자인지 확실하지 않을때 필요함SELECT ename,sal FROM emp WHERE LOWER(ename)='scott';
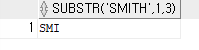
- 문자에서 특정 철자 추출 (SUBSTR)
ex)영어 단어 SMITH에서 SMI만 잘라내서 출력SELECT SUBSTR('SMITH',1,3) FROM DUAL;
=>
SUBSTR함수:문자에서 특정 위치의 문자열을 추출SELECT SUBSTR('SMITH',2,2) => MI SELECT SUBSTR('SMITH',-2,2) => TH SELECT SUBSTR('SMITH',2) => MITH
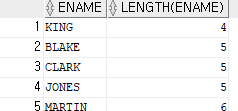
- 문자열의 길이 출력 (LENGTH)
ex)이름을 출력하고 그옆에 이름의 철자 개수를 출력SELECT ename,LENGTH(ename) FROM emp;
=>
LENGTH:문자열의 길이 출력※ 한글도 마찬가지로 문자의 길이 출력
SELECT LENGTH('가나다라마') FROM DUAL; 5※
LENGTHB:바이트의 길이를 반환
한글은 한글자에 3바이트SELECT LENGTHB('가나다라마') => 15 FROM DUAL;
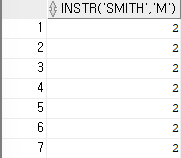
- 문자에서 특정 철자의 위치 출력 (INSTR)
ex)사원 이름 SMITH에서 알파벳 철자 M이 몇 번째 자리에 있는지 출력하기SELECT INSTR('SMITH','M') FROM emp;
ex) abcdefgh@naver.com 이메일에서 naver.com만 추출하고 싶다면 INSTR과 SUBSTR을 이용하면 추출 가능
# '@'를 INSTR로 위치 추출 SELECT INSTR('abcdefgh@naver.com','@') FROM DUAL; =>8 SELECT SUBSTR('abcdefgh@naver.com',INSTR('abcdefgh@naver.com','@')+1) FROM DUAL; =>naver.com SELECT RTRIM(SUBSTR('abcdefgh@naver.com',INSTR('abcdefgh@naver.com','@')+1),'.com') FROM DUAL; =>naver
- 특정 철차를 다른 철차로 변경 (REPLACE)
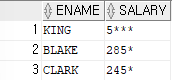
ex)이름과 월급을 출력하는데,월급을 출력할 때 숫자 0을 *(별표)로 출력해보기SELECT ename,REPLACE(sal,0,'*') as SALARY FROM emp;
REGEXP_REPLACE는 정규식 함수
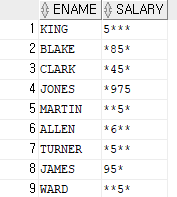
ex)이름과 월급을 출력하는데,월급을 출력할 때 숫자 0-3을 *로 출력해보기SELECT ename,REGEXP_REPLACE(sal,'[0-3]','*') as SALARY FROM emp;
ex)다음의 쿼리는 이름의 두번째 자리의 한글을 *로 출력
SELECT REPLACE(ENAME,SUBSTR(ENAME,2,1),'*') as "전광판_이름" FROM test_ename;
- 특정 철자를 N개만큼 채우기 (LPAD,RPAD)
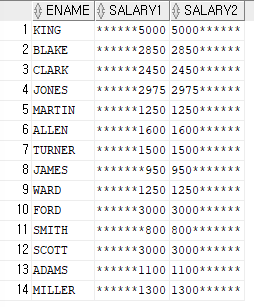
ex)이름과 월급을 출력하는데 월급 컬럼의 자릿수를 10자리수로 하고,월급을 출력하고 남은 나머지 자리에 별표 (*)를 채워서 출력SELECT ename,LPAD(sal,10,'*') as salary1,RPAD(sal,10,'*') as salary2 FROM emp;
=>
LPAD:왼쪽으로 채워서넣다
=>RPAD:오른쪽으로 채워서 넣다ex)이름과 월급을 출력하는데 월급100을 ◆로 출력하는 예제
SELECT ename,sal,lpad('◆',round(sal/100),'◆') as "bar_chart" FROM emp;
- 특정 철자 잘라내기(TRIM,LTRIM,RTRIM)
ex)첫번째 컬럼은 영어 단어 smith철자를 출력,
두번째 smith에서 s를 잘라내서 출력,세번째 컬럼은 smith에서 h를 잘라내서 출력,네번째 컬럼은 영어단어 smtihs의 양쪽에 s를 잘라서 출력SELECT 'smith',LTRIM('smith','s'),RTRIM('smith','h'),TRIM('s' from 'smiths') FROM DUAL;
- 반올림해서 출력하기 (ROUND)
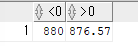
ex)876.567 숫자를 출력하는데 소수점 두 번째 자리인 6에서 반올림해서 출력SELECT ROUND(876.567,-1) as "<0" , ROUND(876.567,2) as ">0" FROM DUAL;
=>
ROUND(숫자,반올림할 숫자)
=> 숫자 >0, 반올림할 숫자 +1에서 반올림하기!!
=> 숫자 <0, 소수점이전 반올림할 숫자로 반올림!
=>ROUND(숫자,0) =ROUND(숫자)
소수점 이후 첫번째자리에서 반올림으로 동일
- 숫자를 버리고 출력하기 (TRUNC)
ex)876.567 숫자를 출력하는데 소수점 두번째 자리인 6과 그이후의 숫자들을 모두 버리고 출력SELECT '876.567' as 숫자,TRUNC(876.567,1) FROM DUAL;
=> 숫자 >0, 버릴 숫자 +1부터 버리기
=> 숫자 <0, 소수점이전 버릴숫자부터 버리기
=>TRUNC(숫자,0) =TRUNC(숫자)
소수점이후를 모두 버리고 출력
- 나눈 나머지 값 출력 (MOD)
ex)숫자 10을 3으로 나눈 나머지값이 어떻게 되는지 출력SELECT MOD(10,3) FROM DUAL;
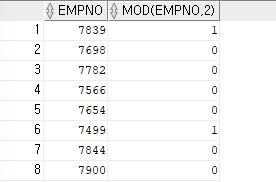
ex)사원 번호와 사원 번호가 홀수이면 1,짝수이면 0을 출력하는 쿼리
SELECT empno,MOD(empno,2) FROM emp;
ex)사원 번호가 짝수인 사원들의 사원 번호와 이름을 출력하는 쿼리
SELECT empno,ename FROM emp WHERE MOD(empno,2)=0;
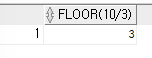
10을 3으로 나눈 몫을 출력하는 쿼리
SELECT FLOOR(10/3) FROM DUAL;
- 날짜 간 개월 수 출력하기 (MONTHS_BETWEEN)
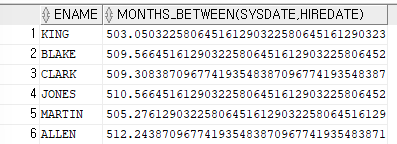
ex)이름을 출력하고 입사한 날짜부터 오늘까지 총 몇달을 근무했는지 출력SELECT ename,MONTHS_BETWEEN(sysdate,hiredate) FROM emp;
=>SYSDATE:오늘 날짜를 확인하는 함수
=>MONTHS_BETWEEN:날짜를 다루는 함수
=>MONTHS_BETWEEN(최신날짜,예전날짜)※날짜만 가지고 연산을 해야한다면,
날짜와 산술 연산만 이용해서 산술식 작성**
ex)2018년 10월 1일에서 2019년 6월 1일 사이의 총 일수 출력SELECT TO_DATE('2019-06-01','RRRR-MM-DD') - TO_DATE('2018-10-01','RRRR-MM-DD') FROM DUAL;
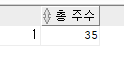
ex)2018년 10월 1일에서 2019년 6월 1일 사이의 총 주(week)수를 출력SELECT ROUND((TO_DATE('2019-06-01','RRRR-MM-DD') -TO_DATE('2018-10-01','RRRR-MM-DD'))/7) AS "총 주수" FROM DUAL;
- 개월 수 더한 날짜 출력하기(ADD_MONTHS)
ex) 2019년 05월 1일부터 100달뒤의 날짜 출력SELECT ADD_MONTHS(TO_DATE('2019-05-01','RRRR-MM-DD'),100) FROM DUAL; # 동일한 SQL SELECT TO_DATE('2019-05-01','RRRR-MM-DD')+ interval '100'month FROM DUAL;
ex) 2019년 05월 1일부터 100일 후에 돌아오는 날짜 출력SELECT TO_DATE('2019-05-01','RRRR-MM-DD')+100 FROM DUAL;
※ interval 함수를 활용하면 좀더 섬세하게 날자 산술 연산을 할 수 있다.
ex) 2019년 05월 1일부터 1년 3개월 후의 날짜를 출력하는 쿼리SELECT TO_DATE('2019-05-01','RRRR-MM-DD')+ interval '1-3'year(1) to month FROM DUAL;
interval 표현식
-INTERVAL '4' YEAR
=>4년의 0달
-INTERVAL '123' YEAR(3)
=>123년의 0달
-INTERVAL '5' MONTHS
=>5달
-INTERVAL '500' MONTH(S3)
=>4년의 0달
-INTERVAL '400' DAY
=>400일ex) 2019년 05월 1일부터 3년 후의 날짜를 출력하는 쿼리
SELECT TO_DATE('2019-05-01','RRRR-MM-DD')+ interval '3'year(1) FROM DUAL;
※ TO_YMINTERVAL 함수는 년,개월 후의 날짜를 출력할 수 있다.
ex) 2019년 05월 1일부터 3년 5개월 후의 날짜를 출력하는 쿼리SELECT TO_DATE('2019-05-01','RRRR-MM-DD')+ TO_YMINTERVAL('03-05') as 날짜 FROM DUAL;
- 특정 날짜 뒤에 오는 요일 날짜 출력하기
(NEXT_DAY)
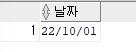
ex)2019년 5월 22일부터 바로 돌아올 월요일의 날짜 출력SELECT '2019/05/22' as 날짜,NEXT_DAY('2019/05/22','월요일') FROM DUAL;
ex)오늘부터 앞으로 돌아올 화요일의 날짜 출력
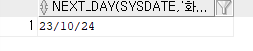
SELECT NEXT_DAY(SYSDATE,'화요일') FROM DUAL;
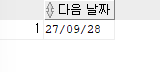
ex)2019년 5월 22일부터 100달 뒤에 돌아오는 화요일의 날짜
SELECT NEXT_DAY(ADD_MONTHS('2019/05/22',100),'화요일') AS "다음 날짜" FROM DUAL;
ex)오늘부터 100달뒤에 돌아오는 월요일의 날짜
SELECT NEXT_DAY(ADD_MONTHS(SYSDATE,100),'월요일') FROM DUAL;
- 특정 날짜가 있는 달의 마지막 날짜 출력
(LAST_DAY)
ex)2019년 05월 22일의 마지막 날짜가 어떻게 되는지 출력SELECT LAST_DAY('2019/05/22') as "마지막 날짜" FROM DUAL;
ex)오늘부터 이번달 말까지 총 몇일이 남았는지 출력
SELECT LAST_DAY(SYSDATE)- SYSDATE as "남은 날짜" FROM DUAL;
ex)이름이 KING인 사원의 이름,입사일,입사한 달의 마지막 날짜를 출력하는 쿼리
SELECT ename,hiredate,LAST_DAY(hiredate) FROM emp WHERE ename='KING';
- 문자형으로 데이터 유형 변환하기
(TO_CHAR)
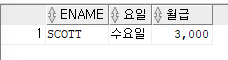
ex)이름이 SCOTT인 사원의 이름과 입사한 요일을 출력하고, SCOTT의 월급에 천 단위를 구분할 수 있는 콤마를 붙여 출력SELECT ename,TO_CHAR(hiredate,'DAY') as 요일,TO_CHAR(sal,'999,999') as 월급 FROM emp WHERE ename='SCOTT';
=>
TO_CHAR
숫자형 데이터 유형을 문자형으로 변환
날짜형 데이터를 문자형으로 변환
=>날짜를 문자로 변환해서 출력하면
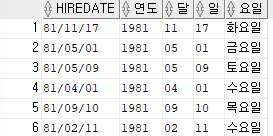
날짜에서 년,월,일,요일등을 추출할 수 있다.SELECT hiredate,TO_CHAR(hiredate,'RRRR') as 연도,TO_CHAR(hiredate,'MM') as 달, TO_CHAR(hiredate,'DD') as 일,TO_CHAR(hiredate,'DAY') as 요일 FROM emp;
날짜포맷
연도:RRRR,YYYY,RR,YY
월:MM,MON
일:DD
요일:DAY,DY
주:WW,IW,W
시간:HH,HH24
분:MI
초:SSex) 1981년도에 입사한 사원의 이름과 입사일을 출력
SELECT ename,hiredate FROM emp WHERE TO_CHAR(hiredate,'RRRR')='1981';
ex) 날짜 컬럼에서 연도/월/일/시간/분/초를 추출하기 위해 EXTRACT함수를 사용
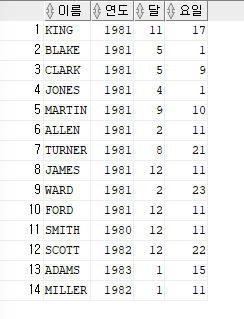
SELECT ename as 이름,EXTRACT(year from hiredate) as 연도, EXTRACT(month from hiredate) as 달,EXTRACT(day from hiredate) as 요일 FROM emp;
ex) 이름과 월급을 출력하는데,월급을 출력할 때 천단위를 표시해서 출력
SELECT ename,TO_CHAR(sal,'999,999') as 월급 FROM emp;
=>숫자 9는 자릿수이고,0-9까지 어떠한 숫자가 와도 관계없다는 뜻이다.
쉼표는 천 단위를 나타내는 표시ex) 천 단위와 백만 단위를 표시하는 예제
SELECT ename as 이름 ,TO_CHAR(sal*200,'999,999,999') as 월급 FROM emp;
알파벳 L을 사용하면 화폐 단위 \를 출력할 수 있다.
SELECT ename as 이름,TO_CHAR(sal*200,'L999,999,999') as 월급 FROM emp;
- 날짜형으로 데이터 유형 변환하기(TO_DATE)
ex)81년 11월 17일에 입사한 사원의 이름과 입사일을 출력해보기SELECT ename,hiredate FROM emp WHERE hiredate=TO_DATE('81/11/17')
- 암시적 형 변환
SELECT ename,sal FROM emp WHERE sal='3000';=>sal은 숫자형 데이터 컬림인데 '3000'문자형과 비교하고 있다.
=> '숫자형 =문자형'으로 잘못 비교했지만,
오라클이 알아서 '숫자형=숫자형'으로 변환하기때문에 에러가 발생하지 않는다.※ SET AUTO ON 명령어는 실행 계획을 한번에 보여줌
- NULL값 대신 다른 데이터 출력
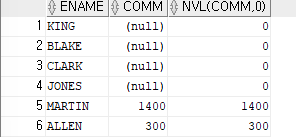
(NVL,NVL2)
ex)이름과 커미션을 출력하는데,커미션이 NULL인 사원들은 0으로 출력SELECT ename,comm,NVL(comm,0) FROM emp;
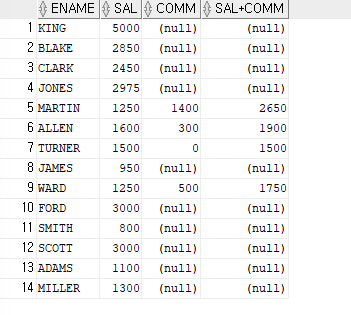
SELECT ename,sal,comm,sal+comm FROM emp;
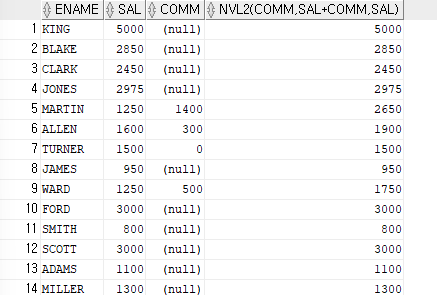
ex)NVL2함수를 이용하여 커미션이 NULL이 아닌 사원들은 SAL+COMM을 출력하고,NULL인 사원들은 sal을 출력
SELECT ename,sal,comm,NVL2(comm,sal+comm,sal) FROM emp;
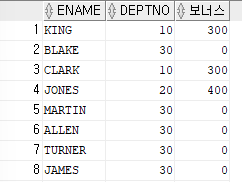
- IF문을 SQL로 구현하기 (DECODE)
SELECT ename,deptno,DECODE(deptno,10,300,20,400,0) as 보너스 FROM emp;
=>DECODE(deptno,10,300,20,400,0) 는
deptno가 10번이면 300,20번이면 400,나머지 번호는 0을 출력
=>맨끝에 0은 default값으로 앞의 값에 만족하지 않은 데이터ex)사원 번호와 사원 번화가 짝수인지 홀수인지를 출력하는 쿼리
SELECT empno,DECODE(mod(empno,2),0,'짝수',1,'홀수') as 보너스 FROM emp;
=>default값은 생략 가능하다.
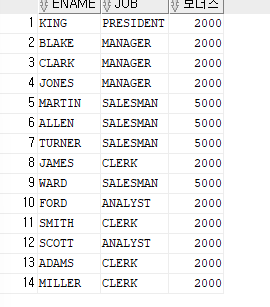
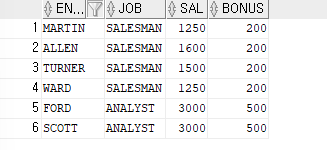
ex)이름과 직업,보너스를 출력하는데 직업이 SALESMAN이면 보너스 5000을 출력하고 나머지 직업은 보너스 2000을 출력
SELECT ename,job,DECODE(job,'SALESMAN',5000,2000) as 보너스 FROM emp;
=>else if조건이 없으면 if다음에 바로 else사용
- IF문을 SQL로 구현하기 (CASE)
SELECT ename,job,sal,CASE WHEN sal>=3000 THEN 500 WHEN sal>=2000 THEN 300 WHEN sal>=1000 THEN 200 ELSE 0 END AS BONUS FROM emp WHERE job IN ('SALESMAN','ANALYST');
=>DECODE와 CASE문의 다른점은
DECODE는 등호(=) 비교만 가능하고,
CASE는 등호(=)비교와,부등호비교 모두 가능ex)이름,직업,커미션,보너스를 출력한다.
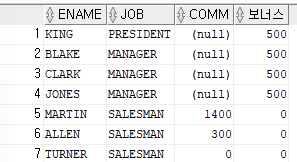
보너스는 커미션이 null이면 500출력,null 이아니면 0을 출력SELECT ename,job,comm,CASE WHEN comm IS NULL THEN 500 ELSE 0 END AS 보너스 FROM emp;
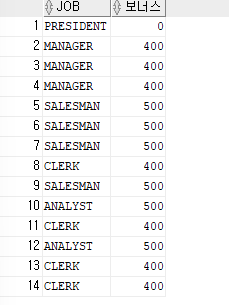
ex)보너스를 출력할때 직업이 SALESMAN,ANALYST이면 500을 출력하고, 직업이 CLERK,MANAGER이면 400을 출력하고, 나머지 직업은 0을 출력하는 쿼리
SELECT job,CASE WHEN job in ('SALESMAN','ANALYST') THEN 500 WHEN job in ('CLERK','MANAGER') THEN 400 ELSE 0 END AS 보너스 FROM emp;
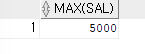
- 최대값 출력하기 (MAX)
ex)사원 테이블에서 최대 월급을 출력해보기SELECT MAX(sal) FROM emp;
ex)직업이 SALESMAN인 사원들중 최대 월급을 출력하기
SELECT MAX(sal) FROM emp WHERE job ='SALESMAN';
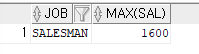
※
SELECT job, MAX(sal) FROM emp WHERE job ='SALESMAN';=>에러발생 이유는
job은 여러컬럼 출력,max는 한컬럼 출력
=> groupby절이 필요하다.SELECT job, MAX(sal) FROM emp WHERE job ='SALESMAN' GROUP BY job;
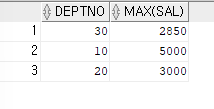
ex) 부서 번호와 부서 번호별 최대 월급을 출력하는 쿼리
SELECT deptno,MAX(sal) FROM emp GROUP BY deptno;
- 최소값 출력하기 (MIN)
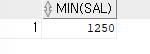
ex)직업이 SALESMAN인 사원들 중 최소 월급을 출력해보기SELECT MIN(sal) FROM emp WHERE job='SALESMAN';
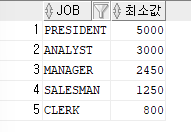
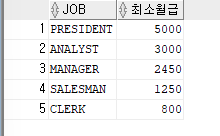
ex)직업과,직업별 최소 월급을 출력하는데,
ORDER BY절을 사용하여 최소 월급이 높은것부터 출력SELECT job,MIN(sal) as 최소값 FROM emp GROUP BY job ORDER BY 최소값 DESC;
=>
ORDER BY는 항상 맨 마지막에 작성하고 실행또한 마지막에 실행된다.
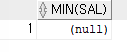
=>그룹함수의 특징은 WHERE조건이 거짓이어도 결과를 항상 출력한다SELECT MIN(sal) FROM emp WHERE 1=2;
=> WHERE절 조건이 거짓이지만 실행된다.
결과는 NULL로 출력된다.
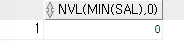
=>NVL함수로 사용해보면 알 수 있다.SELECT NVL(MIN(sal),0) FROM emp WHERE 1=2;
ex)직업,직업별 최소 월급을 출력하는데 ,직업에서 SALEMAN은 제외하고 출력하고 직업별 최소 월급이 높은것부터 출력
SELECT job,MIN(sal)as 최소월급 FROM emp WHERE job !='SALEMAN' GROUP BY job ORDER BY 최소월급 DESC;
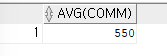
- 평균값 출력하기 (AVG)
ex)사원 테이블의 평균 월급을 출력해본다.SELECT AVG(comm) FROM emp;
=>그룹 함수는 NULL값을 무시한다.
NULL값을 제외한 나머지 데이터를 더한 후 나누어 평균 값을 출력
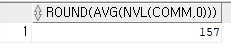
=> NULL값 대신 0으로 치환해주고 평균값을 출력하면 결괏값이 달라진다.SELECT ROUND(AVG(NVL(comm,0))) FROM emp;
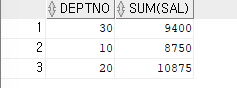
- 토탈값 출력하기 (SUM)
ex)부서번호와 부서 번호별 토탈 월급을 출력해보자SELECT deptno,SUM(sal) FROM emp GROUP BY deptno;
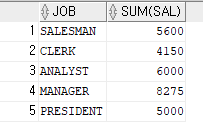
ex)직업과 직업별 토탈 월급을 출력하는데,직업별 토탈 월급이 4000이상인 것만 출력해보자
SELECT job, SUM(sal) FROM emp WHERE SUM(sal)>=4000 GROUP BY job;=> 에러 발생
=> 위와 같이 WHERE절에 그룹 함수를 사용해 조건을 주면 그룹 함수는 허가되지 않는다는 에러 발생
=> 그룹 함수로 조건을 줄때는 WHERE 절 대신
HAVING 절을 사용해야 한다.SELECT job, SUM(sal) FROM emp GROUP BY job HAVING SUM(sal)>=4000;
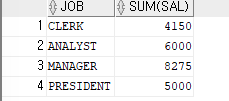
ex)직업과 직업별 토탈 월급을 출력하는데 직업에서 SALESMAN은 제외하고, 직업별 토탈 월급이 4000이상인 사원만 출력
SELECT job,SUM(sal) FROM emp WHERE job!='SALESMAN' GROUP BY job HAVING SUM(sal)>=4000;
※ GROUP BY 절에서는 컬럼 별칭을 사용할 수 없다.
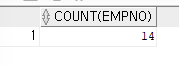
- 건수 출력하기 (COUNT)
SELECT COUNT(empno) FROM emp; # 동일한 SQL SELECT COUNT(*) FROM emp;
※ 그룹 함수는 NULL값을 무시하기때문에 NULL값 제외하고 카운트
SELECT COUNT(comm) FROM emp; => 4=>
COUNT그룹 함수는 NULL값을 계산하지 않는다.
- 데이터 분석 함수로 순위 출력하기 (RANK)
ex)직업이 ANALYST,MANAGER 인 사원들의 이름,직업,월급,월급의 순위를 출력해보기SELECT ename,job,sal,RANK() over (ORDER BY sal DESC) 순위 FROM emp WHERE job in ('ANALYST','MANAGER');
=>
RANK()는 순위를 출력하는 데이터 분석 함수
RANK()뒤에over다음에 나오는 괄호안에
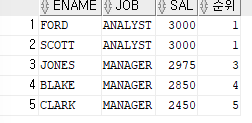
출력하고 싶은 데이터를 정렬하는 SQL문장을 넣으면 그 컬럼 값에 대한 데이터의 순위가 출력됨ex)직업별로 월급이 높은 순서대로 순위를 부여해서 각각 출력해보기
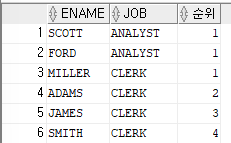
SELECT ename,job,RANK() over (PARTITION BY job ORDER BY sal DESC) as 순위 FROM emp;
=>직업별로 묶어서 순위를 부여하기 위해서
ORDER BY대신PARTITION BY사용=>
ORDER BY는 출력된 순위는 1등이 두명이어서 2등이 출력되지 않고, 바로 3등이 출력=> 바로 2등을 출력하고자 할때는
DENSE_RANK함수 이용
- 데이터 분석 함수로 순위 출력(DENSE_RANK)
ex)직업이 ANALYST,MANAGER인 사원들의
이름,직업,월급,월급의 순위를 출력하는데
순위 1위인 사원이 두명이 있을 경우,
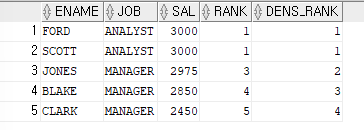
다음 순위가 3위로 출력되지 않고 2위로 출력SELECT ename,job,sal,RANK() over (ORDER BY sal DESC) AS RANK, DENSE_RANK() over(ORDER BY sal DESC) AS DENS_RANK FROM emp WHERE job in ('ANALYST','MANAGER');
=>
RANK함수는 1순위가 2명이어서 => 다음에 바로 3위를 출력했지만,
DENSE_RANK함수는 2위로 출력ex)81년도에 입사한 사원들의 직업,이름,월급,순위를 출력하는데,직업별로 월급이 높은 순서대로 순위를 부여한 쿼리
SELECT job,ename,sal,DENSE_RANK() over(PARTITION BY job ORDER BY sal DESC) AS 순위 FROM emp WHERE hiredate BETWEEN TO_DATE('1981/01/01','RRRR-MM-DD') AND TO_DATE('1981/12/31','RRRR-MM-DD');=>DENSE_RANK 괄호 안에 데이터를 넣고 사용할수 있다.
SELECT DENSE_RANK(2975) within group (ORDER BY sal DESC) 순위 FROM emp;
=>월급이 2975인 사원은 월급의 순위가 어떻게 되는지 출력하는 쿼리
ex)입사일이 81년 11월 17인 사원 테이블 전체 사원들 중 몇 번째로 입사한 것인지 출력하는 쿼리
SELECT DENSE_RANK('81/11/17') within group (ORDER BY hiredate ASC) 순위 FROM emp;
- 데이터 분석 함수로 등급 출력하기(NTILE)
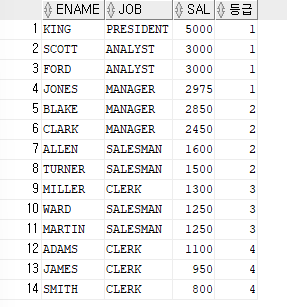
ex)이름과 월급,직업,월급의 등급을 출력해보기
월급의 등급은 4등급으로 나눔SELECT ename,job,sal,NTILE(4) over (ORDER BY sal desc nulls last) 등급 FROM emp;
=>
ORDER BY SAL DESC에서NULLS LAST는
월급이 높은 것부터 출력되게 정렬하는데,
NULL을 맨 아래에 출력하겠다는 의미.
=>NULL LAST사용 안하면 위에서부터 출력
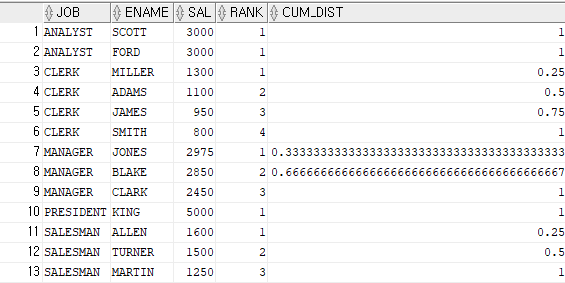
- 데이터 분석 함수로 순위의 비율 출력
(CUME_DIST)
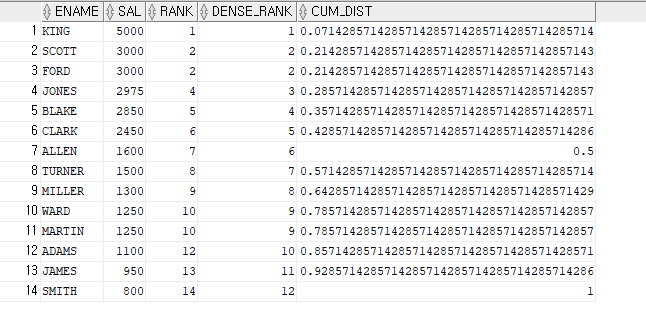
ex)이름과 월급,월급의 순위,월급의 순위 비율 출력SELECT ename,sal,RANK() over (ORDER BY sal DESC) AS RANK, DENSE_RANK() over (ORDER BY sal DESC) AS DENSE_RANK, CUME_DIST() over (ORDER BY sal DESC) AS CUM_DIST FROM emp;
=> 같은 등수가 없으면 : 1/전체 등수
=>같은 등수가 있으면, 여러 명중 마지막 등수로 계산 : 마지막등수/전체 등수ex)PARTITION BY JOB을 사용해서
직업별로 CUME_DIST 를 출력하기SELECT job,ename,sal,RANK() over (PARTITION BY job ORDER BY sal DESC) AS RANK, CUME_DIST() over (PARTITION BY job ORDER BY sal DESC) AS CUM_DIST FROM emp;
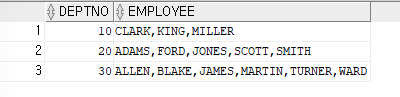
- 데이터분석 함수로 데이터를 가로로 출력하기
(LISTAGG)
ex)부서 번호를 출력하고, 부서 번호 옆에 해당 부서에 속하는 사원들의 이름을 가로로 출력해보기SELECT deptno,LISTAGG(ename,',') within group (order by ename) as EMPLOYEE FROM emp GROUP BY deptno;
=>
LISTAGG함수는 데이터를 가로로 출력하는 함수이며, 구분자로 ,를 사용(/도 가능)
=>GROUP BY절은LISTAGG함수를 사용하려면
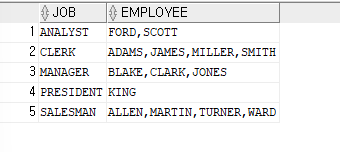
필수로 사용해야하는 절ex)직업과 그 직업에 속한 사원들의 이름을 가로로 출력하기
SELECT job,LISTAGG(ename,',') within group (order by ename) as EMPLOYEE FROM emp GROUP BY job;
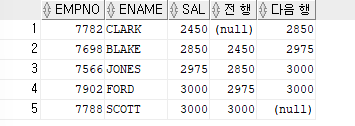
- 데이터분석 함수로 바로 전행과 다음행 출력하기
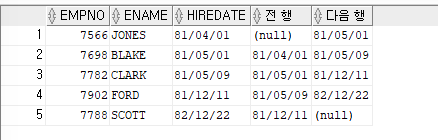
(LAG,LEAD)ex)사원번호,이름,월급을 출력하고 그옆에 바로 전 행의 월급을 출력하고, 옆에 다음행의 월급을 출력해보자
SELECT empno,ename,sal, LAG(sal,1) over (order by sal asc) "전 행", LEAD(sal,1) over (order by sal asc) "다음 행" FROM emp WHERE job in ('ANALYST','MANAGER');
=>
LAG함수: 바로 전 행의 데이터 출력
=>LEAD함수: 바로 다음 행의 데이터 출력ex)직업이 ANALYST 또는 MANAGER인 사원들의 사원번호,이름,입사일, 바로 전에 입사한 사원의 입사일, 바로 다음에 입사한 사원의 입사일 출력
SELECT empno,ename,hiredate, LAG(hiredate,1) over (order by hiredate asc) as "전 행", LEAD(hiredate,1) over (order by hiredate asc) as "다음 행" FROM emp WHERE job in ('ANALYST','MANAGER');
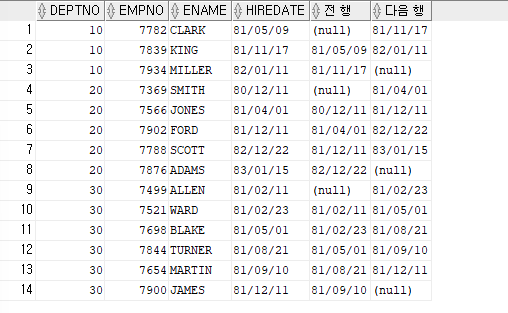
ex) 부서 번호,사원 번호, 이름,입사일, 바로 전에 입사한 사원의 일사일 출력,다음에 입사한 사원의 입사일 출력하는데, 부서 번호별로 구분해서 출력
SELECT deptno,empno,ename,hiredate, LAG(hiredate,1) over (PARTITION BY deptno ORDER BY hiredate asc) as "전 행", LEAD(hiredate,1) over (PARTITION BY deptno ORDER BY hiredate asc) as "다음 행" FROM emp;
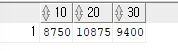
- ROW를 COLUMN으로 출력하기 (SUM+DECODE)
ex)부서 번호, 부서 번호별 토탈 월급을 출력하는데,가로로 출력SELECT SUM(DECODE(deptno,10,sal)) as "10", SUM(DECODE(deptno,20,sal)) as "20", SUM(DECODE(deptno,30,sal)) as "30" FROM emp;
ex)직업,직업별 토탈 월급을 출력하는데 가로로 출력하기
SELECT SUM(DECODE(job,'ANALYST',sal)) as "ANALYST", SUM(DECODE(job,'CLERK',sal)) as "CLERK", SUM(DECODE(job,'MANAGER',sal)) as "MANAGER", SUM(DECODE(job,'SALESMAN',sal)) as "SALESMAN" FROM emp;
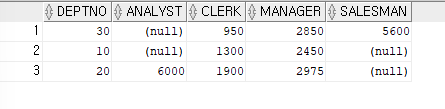
ex)부서번호별로 각각 직업의 토탈 월급의 분포를 보기
SELECT deptno,SUM(DECODE(job,'ANALYST',sal)) as "ANALYST", SUM(DECODE(job,'CLERK',sal)) as "CLERK", SUM(DECODE(job,'MANAGER',sal)) as "MANAGER", SUM(DECODE(job,'SALESMAN',sal)) as "SALESMAN" FROM emp GROUP BY deptno;
=> DEPTNO와 그룹함수와 같이 나열하였으므로,
GROUP BY에 DEPTNO추가하여 실행
- ROW를 COLUMN으로 출력하기 (PIVOT)
ex) 부서 번호,부서 번호별 토탈 월급을 PIVOT문을 사용하여 가로로 출력해보기SELECT * FROM (SELECT deptno,sal FROM emp) PIVOT (SUM(sal) FOR deptno IN (10,20,30));
=>SUM 과 DECODE를 이용해 출력한 결과를 PIVOT문을 이용하면 간단한 쿼리문으로 출력할 수 있다.ex) 직업과 직업별 토탈 월급을 가로로 출력하는 예제
SELECT * FROM (SELECT job,sal FROM emp) PIVOT (sum(sal) FOR job IN ('ANALYST' AS "ANALYST",'CLERK' AS "CLERK",'MANAGER' AS "MANAGER",'SALESMAN' AS "SALESMAN"));
=>PIVOT문을 사용할 때는 FROM 절에 괄호를 사용해서 특정 컬럼만 선택해야 한다.
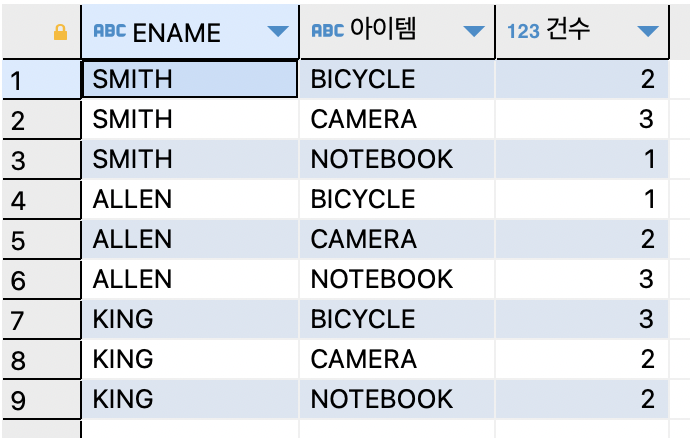
- COLUMN을 ROW로 출력하기 (UNPIVOT)
ex)UNPIVOT문을 사용하여 컬럼을 로우로 출력해 보겠습니다.SELECT * FROM order2 UNPIVOT (건수 for 아이템 in (BICYCLE, CAMERA, NOTEBOOK));
===>
=>UNPIVOT문은 열을 행으로 출력된다.
=>건수는 가로로 저장되어 있는 데이터를 세로로 unpivot시킬 출력 열 이름.
=>아이템은 가로로 되어 있는 order2테이블의 컬럼명을 unpivot시켜 세로로 출력할 열 이름이다.
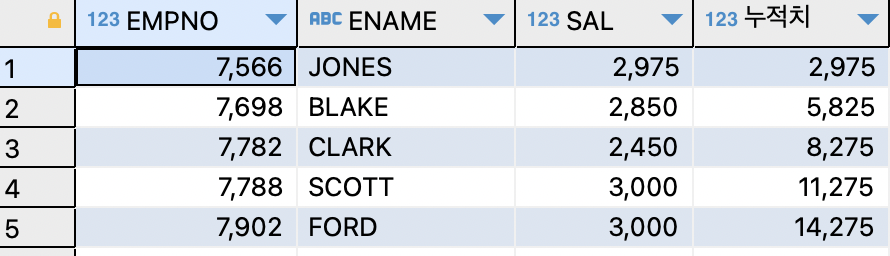
- 데이터 분석 함수로 누적 데이터 출력하기 (SUM OVER)
SELECT empno,ename,sal,SUM(sal) OVER (ORDER BY empno ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 누적치 FROM EMP WHERE job IN ('ANALYST','MANAGER');
=>OVER 다음의 괄호 안에는 값을 누적할 윈도우를 지정할 수 있다.
UNBOUNDED PRECEDING :맨 첫번째 행을 가리킨다.
UNBOUNDED FOLLOWING :맨 마지막 행을 가리킨다.
CURRENT ROW :현재 행을 가리킨다.
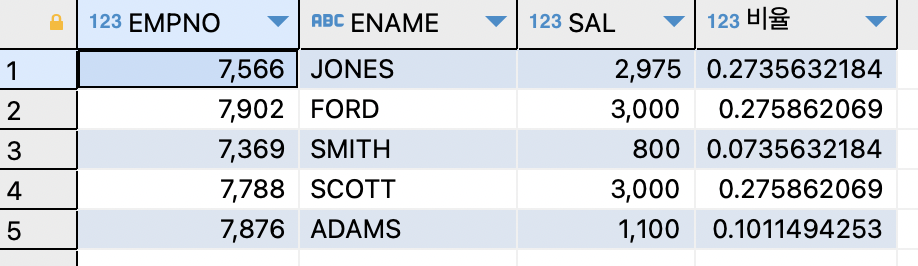
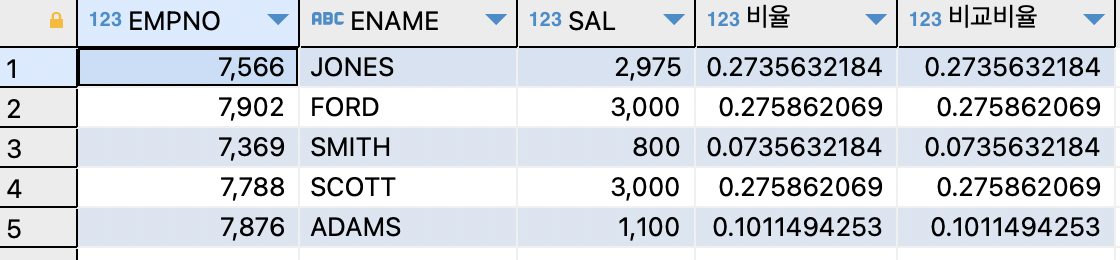
- 데이터 분석 함수로 비율 출력하기 (RATIO_TO_REPORT)
ex) 부서 번호가 20번인 사원들의 사원 번호, 이름,월급을 출력하고, 20번 부서 번호 내에서 자신의 월급 비율이 어떻게 되는지 출력해보기SELECT empno,ename,sal,RATIO_TO_REPORT(sal) OVER() AS 비율 FROM EMP WHERE deptno=20;
SELECT empno,ename,sal,RATIO_TO_REPORT(sal) OVER() AS 비율 , SAL/SUM(sal) OVER() AS "비교비율" FROM EMP WHERE deptno=20;
데이터 분석 함수로 집계 결과 출력하기 (ROLLUP)
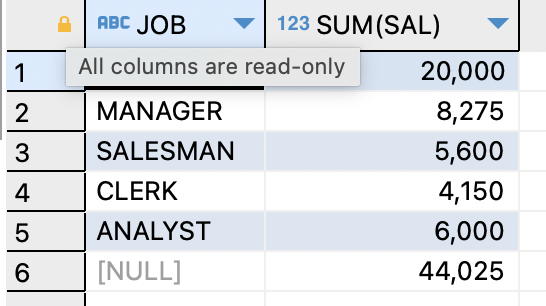
ex) 직업과 직업별 토탈 월급을 출력하는데, 맨 마지막 행에 토탈 월급을 출력해보기SELECT job,SUM(sal) FROM EMP GROUP BY ROLLUP (job);
=>
ROLLUP을 붙여주면 전체 토탈 월급을 추가가능,
job컬럼의 데이터도 오름차순으로 정렬되어 출력
=>ROLLUP에서 컬럼을 2개 사용하면 집계 결과는 컬럼의 개수+1개로 출력됨데이터 분석 함수로 집계 결과 출력하기 (CUBE)
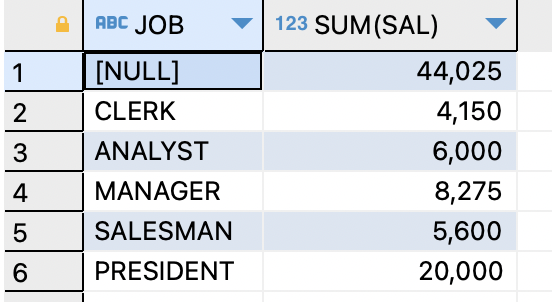
ex) 직업과 직업별 토탈 월급을 출력하는데, 첫 번째 행에 토탈 월급을 출력해보기SELECT job,sum(sal) FROM EMP GROUP BY CUBE(job);
=>GROUP BY CUBE(deptno,job)는 총 4가지 집계 결과가 나온다
=>부서 번호별/직업별/토탈 월급/부서 번호별 직업별 토탈
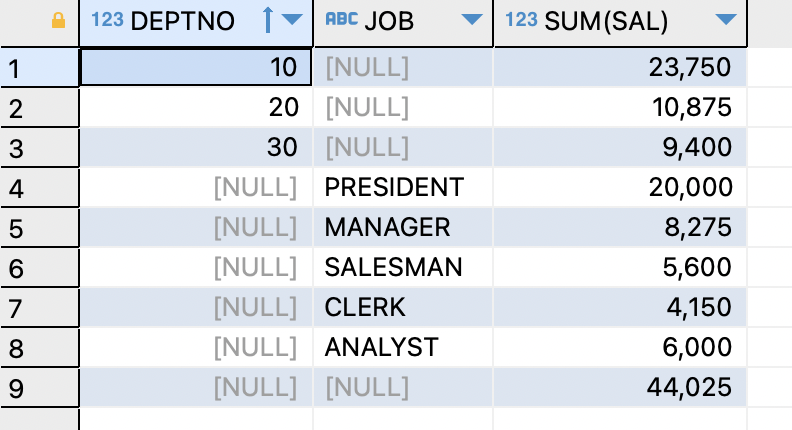
- 데이터 분석 함수로 집계 결과 출력하기 (GROUPING SETS)
ex) 부서 번호와 직업,부서 번호별 토탈 월급과 직업별 토탈 월급,전체 토탈 월급을 출력SELECT deptno,job,sum(sal) FROM EMP GROUP BY GROUPING SETS((deptno),(job),());
=>GROUPING SETS는 집계하고 싶은 컬럼들을 기술하면 그대로 출력
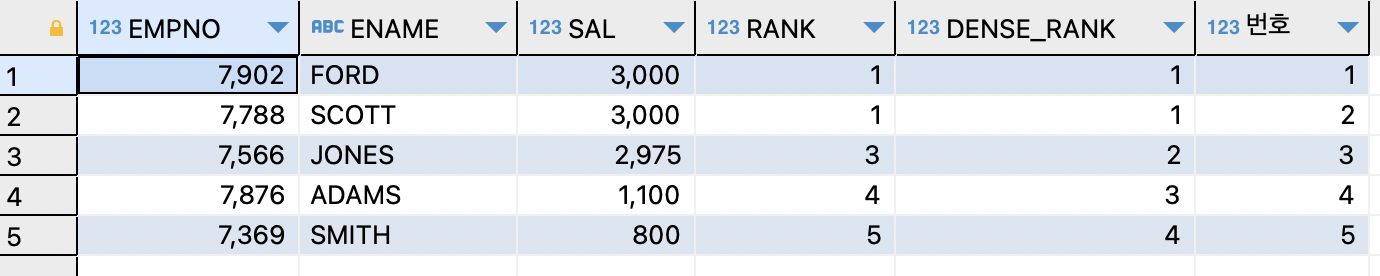
- 데이터 분석 함수로 출력 결과 넘버링 하기 (ROW_NUMBER)
SELECT empno,ename,sal,RANK() OVER (ORDER BY sal DESC) RANK, DENSE_RANK() OVER (ORDER BY sal DESC) DENSE_RANK, ROW_NUMBER () OVER (ORDER BY sal DESC) 번호 FROM emp WHERE deptno=20;
=>ROW_NUMBER은 출력되는 각 행에 고유한 숫자를 부여하는 데이터 분석 함수이다.