PART3
- 출력되는 행 제한하기
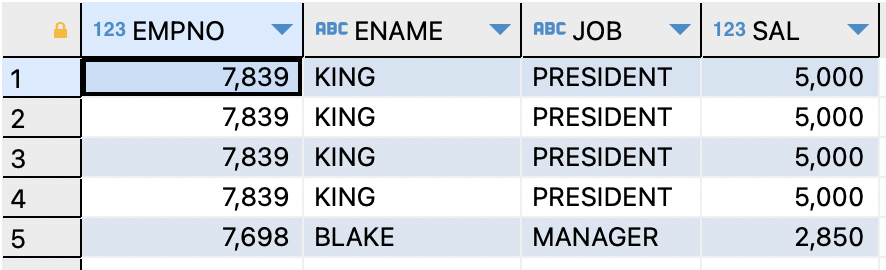
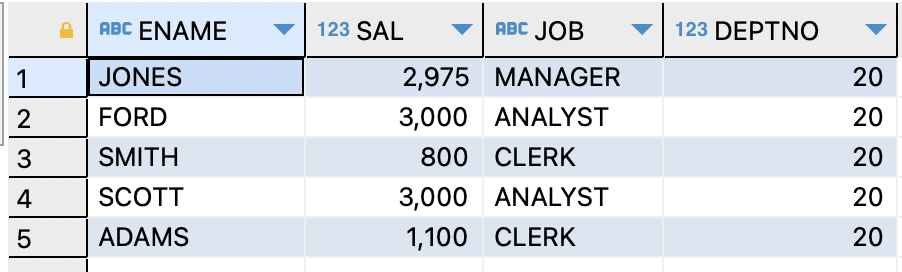
ROWNUMex) 사원번호,이름,직업,월급을 상단 5개만 추출
SELECT empno,ename,job,sal FROM emp WHERE ROWNUM <=5;
=>
ROWNUM는 감춰진 컬럼
=>WHERE절에 사용하여 행 갯수 제한
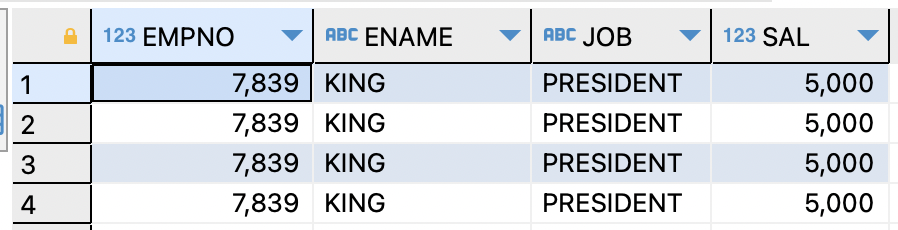
- 출력되는 행 제한하기 (Simple Top-n Queries)
ex) 사원번호,이름,직업,월급을 4개의 행으로 제한SELECT empno,ename,job,sal FROM EMP ORDER BY sal DESC FETCH FIRST 4 ROWS ONLY;
=>Simple Top-n Queries는 정렬된 결과로부터,
위쪽 또는 아래쪽 n개의 행을 반환하는 쿼리
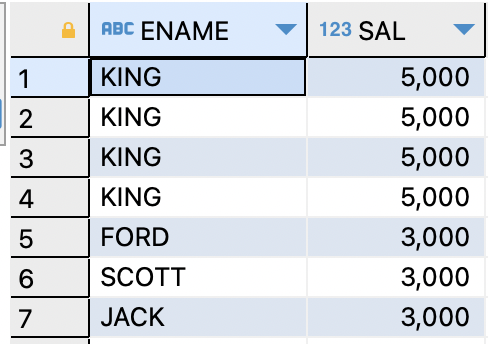
=>FETCH FIRST ROWS ONLY는 단순하게 위의 쿼리를 출력할 수 있다.ex)월급이 높은 사원들중 20%에 해당하는 사원만 출력
SELECT empno,ename,job,sal FROM EMP ORDER BY sal DESC FETCH FIRST 20 PERCENT ROWS ONLY;
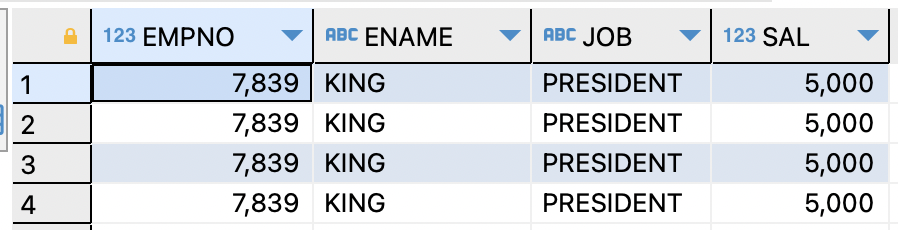
※
WITH TIES옵션을 사용하면 여러 행이 N값과 동일하다면 같이 출력해준다.SELECT empno,ename,job,sal FROM EMP ORDER BY sal DESC FETCH FIRST 2 ROWS WITH TIES;
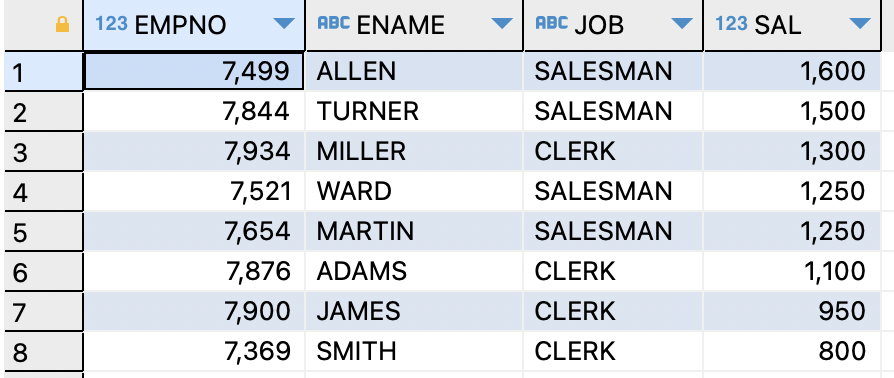
※
OFFSET옵션을 사용하면 시작되는 행의 위치를 지정할 수 있다.SELECT empno,ename,job,sal FROM EMP ORDER BY sal DESC OFFSET 9 ROWS;
※
OFFSET과FETCH조합SELECT empno,ename,job,sal FROM EMP ORDER BY sal DESC OFFSET 9 ROWS FETCH FIRST 2 ROWS ONLY;
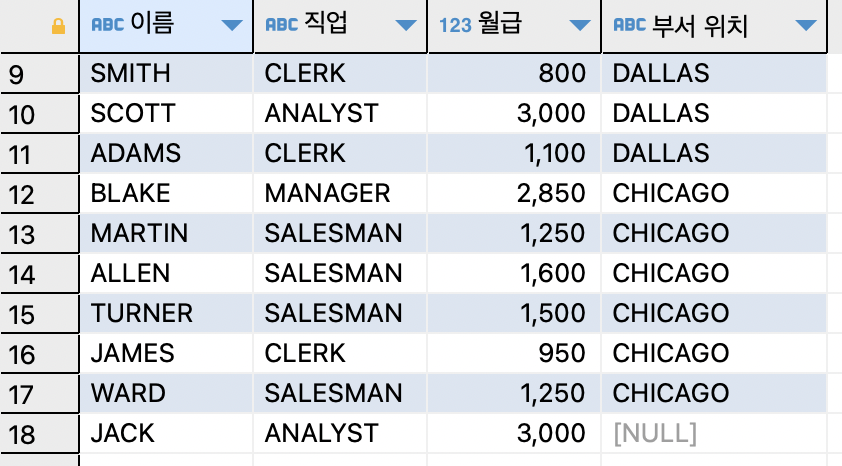
- 여러 테이블의 데이터를 조인해서 출력하기
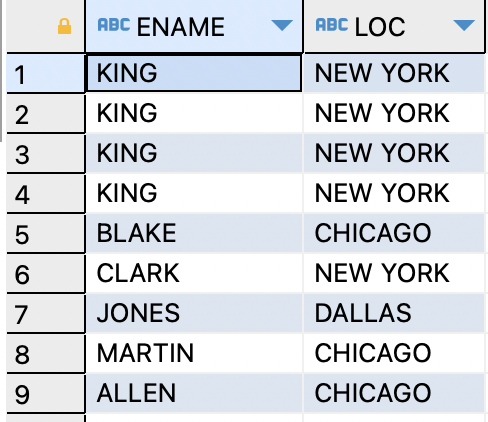
(EQUI JOIN)ex)사원 테이블과 부서 테이블을 조인하여 이름과 부서 위치를 출력하기
SELECT ename,loc FROM emp,dept WHERE emp.deptno=dept.DEPTNO ;
empno.deptno=dept.deptno를WHERE조건에 추가해준다.
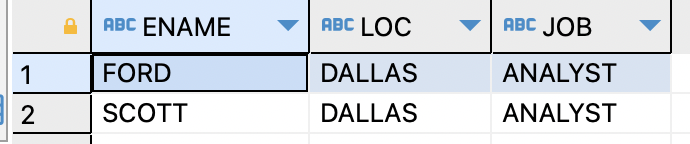
=> 조인조건이 이퀄(=)이면EQUI JOINex)사원 테이블과 부서 테이블을 조인하여 이름과 부서 위치, 직업이 ANALYST인 사원들만 출력
SELECT ename,loc,job FROM emp,dept WHERE emp.deptno=dept.DEPTNO AND emp.job='ANALYST';
※ 조인한 두 테이블에 있는 공통된 컬럼을 출력할 시에는 테이블명.컬럼명으로 출력해야 함
SELECT ename,loc,job,emp.deptno FROM emp,dept WHERE emp.deptno=dept.DEPTNO AND emp.job='ANALYST';
- 여러 테이블의 데이터를 조인해서 출력하기
(NON EQUI JOIN)
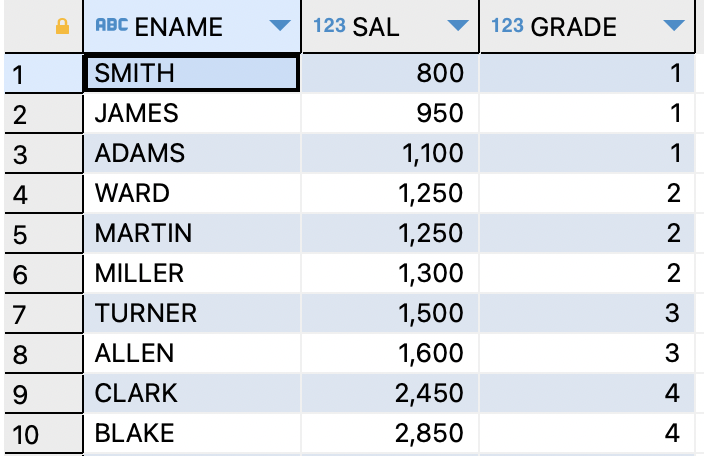
ex) 사원테이블과 급여 등급 테이블을 조인하여,이름,월급,급여 등급을 출력하기SELECT e.ename,e.sal,s.grade FROM emp e,salgrade s WHERE e.sal BETWEEN s.losal AND s.hisal;
NON EQUI JOIN
- 여러 테이블의 데이터를 조인해서 출력하기
(OUTER JOIN)
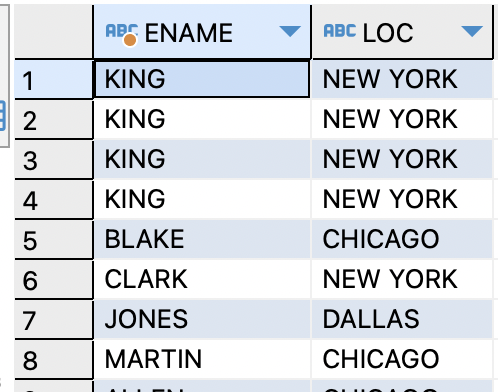
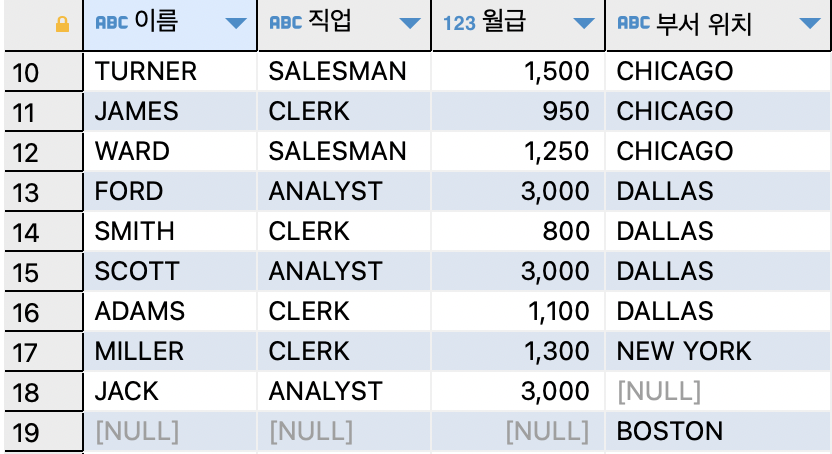
ex)사원 테이블과 부서 테이블을 조인하여
이름과 부서 위치를 출력하는데,BOSTON도 같이 출력하기SELECT e.ename,d.loc FROM emp e,dept d WHERE e.deptno (+) = d.deptno;
=>OUTER JOIN은EQUI JOIN문법에(+)를 결과가 덜나오는 쪽에 붙인다.
- 여러 테이블을 조인해서 출력하기
(SELF JOIN)
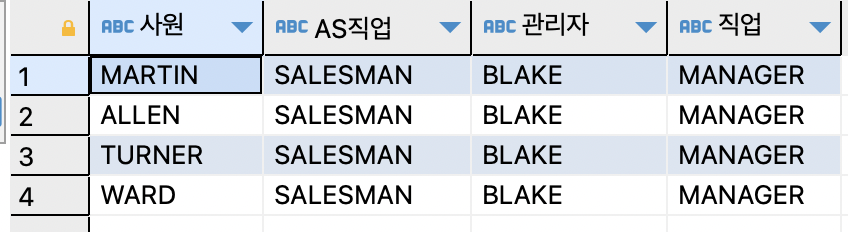
ex)사원 테이블 자기 자신의 테이블과 조인하여 이름,직업,해당 사원의 관리자 이름과 관리자의 직업을 출력하기SELECT e.ename AS 사원,e.job AS 직업,m.ename AS 관리자,m.job AS 직업 FROM emp e,emp m WHERE e.mgr=m.empno AND e.job='SALESMAN';
mgr 컬럼의 번호와 empno 사원번호가 동일하여
조인 조건으로 적용
- 여러 테이블을 조인하여 출력하기 (ON절)
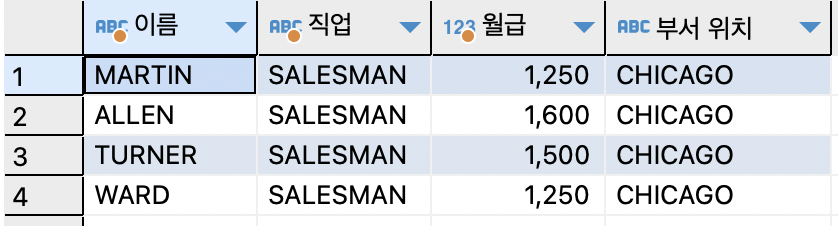
ex)ON 절을 사용한 조인 방법으로 이름과,직업,월급,부서 위치를 출력해보기SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e JOIN dept d ON (e.deptno=d.deptno) WHERE e.job='SALESMAN';
=> 여러개의 테이블을 조인할때는 조인조건의 수= 테이블의 수 -1※ 오라클 EQUI JOIN 과 ON절을 사용한 조인
# EQUI JOIN SELECT e.ename,d.loc FROM emp e,dept d WHERE e.deptno=d.deptno; # ON절을 사용한 조인 SELECT e.name,d.loc FROM emp e JOIN dept d ON (e.deptno=d.deptno); # 여러 개의 테이블을 조인할 때 # EQUI JOIN SELECT e.ename,d.loc FROM emp e,dept d ,salgrade s WHERE e.deptno=d.deptno AND e.sal BETWEEN s.losa AND s.hisal; # ON절을 사용한 조인 SELECT e.name,d.loc,s.salgrade FROM emp e JOIN dept d ON (e.deptno=d.deptno) JOIN salgrade s ON (e.sal BETWEEN s.losa AND s.hisal);
- 여러 개의 테이블의 데이터를 조인해서 출력하기
(USING)
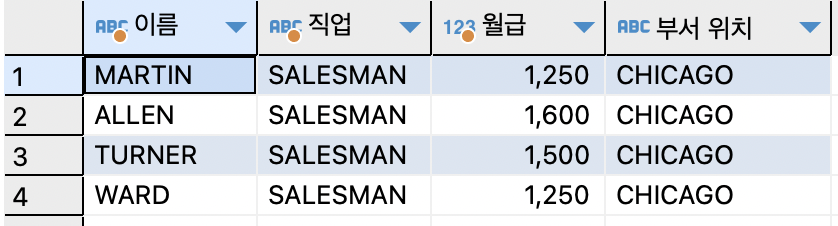
ex)USING절을 사용한 조인 방법으로, 이름,직업,월급,부서 위치 출력하기SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e JOIN dept d USING (deptno) WHERE e.job='SALESMAN';
=> 컬럼명 앞에 테이블명이나 별칭 사용 할 수 없다.# EQUI JOIN SELECT e.ename,d.loc FROM emp e,dept d WHERE e.deptno=d.deptno; > # USING절을 사용한 조인 SELECT e.name,d.loc FROM emp e JOIN dept d USING (deptno)
- 여러 테이블의 데이터를 조인해서 출력하기
(NATURAL JOIN)
ex)NATURAL 조인방법으로 이름,직업,월급과 부서위치 출력하기SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e NATURAL JOIN dept D WHERE e.job='SALESMAN';=>조인 조건을 명시하지 않아도,
NATURAL JOIN을 기술하면 조인이 되는 쿼리
=> 두테이블에 공통으로 존재하는 컬럼을 자동으로 찾아서 조인
=>NATURAL JOIN에 사용된 컬럼은 별칭이나 테이블명을 접두어로 사용할 수 없다.
- 여러 테이블의 데이터를 조인해서 출력하기
(LEFT/RIGHT OUTER JOIN)
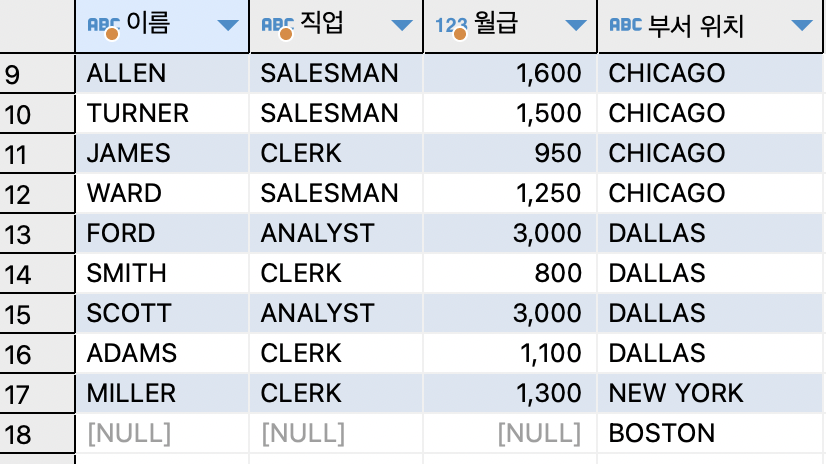
ex)RIGHT OUTER 조인방법으로 이름,직업,월급과 부서위치 출력하기SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e RIGHT OUTER JOIN dept d ON (e.deptno=d.deptno);
※ 오라클 OUTER JOIN VS 1999 ANSI/ISO JOIN
# 오라클 RIGHT OUTER JOIN SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e , dept d WHERE e.deptno(+)=d.deptno; # 1999 ANSI/ISO RIGHT OUTER JOIN SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e RIGHT OUTER JOIN dept d ON (e.deptno=d.deptno);ex)1999 ANSI/ISO LEFT OUTER JOIN
SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e LEFT OUTER JOIN dept D ON (e.deptno = d.deptno);
※ 오라클 OUTER JOIN VS 1999 ANSI/ISO JOIN
# 오라클 LEFT OUTER JOIN SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e , dept d WHERE e.deptno=d.deptno(+); # 1999 ANSI/ISO LEFT OUTER JOIN SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e LEFT OUTER JOIN dept d ON (e.deptno=d.deptno);
- 여러 테이블의 데이터를 조인해서 출력하기
(FULL OUTER JOIN)
ex)FULL OUTER JOIN방법으로 이름,직업,월급,부서위치를 출력하기SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e FULL OUTER JOIN dept D ON (e.deptno = d.deptno);
=>FULL OUTER JOIN은 오라클 작성법은 사용 불가,대신 다음과 같은 쿼리로 사용SELECT e.ename AS 이름,e.job AS 직업,e.sal AS 월급,d.loc AS "부서 위치" FROM emp e LEFT OUTER JOIN dept D ON (e.deptno = d.deptno) UNION SELECT e.ename,e.job,e.sal,d.loc FROM emp e RIGHT OUTER JOIN dept D ON (e.deptno = d.deptno);=>RIGHT OUTER JOIN +LEFT OUTER JOIN
- 집합 연산자로 데이터를 위아래로 연결하기
(UNION ALL)
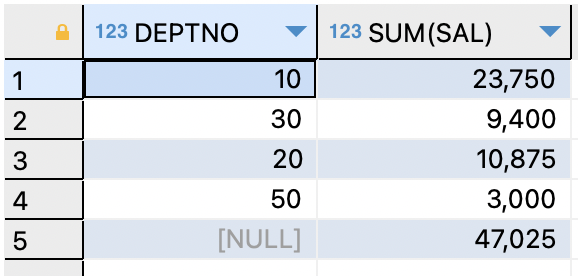
ex)부서 번호와 부서 번호별 월급을 출력하는데 ,
맨아래쪽 행에 토탈 월급을 출력하기SELECT deptno,sum(sal) FROM EMP GROUP BY deptno UNION ALL SELECT TO_NUMBER(null) AS deptno,sum(sal) FROM EMP;
=>중복을 제거하지 않음※ 집합 연산자 사용 시 주의사항
UNION ALL
1.위쪽,아래쪽쿼리 컬럼의 개수가 같아야한다.
2.위쪽,아래쪽 쿼리 컬럼의 데이터 타입이 같아야한다.
3.결과로 출력되는 컬럼명은 위쪽 쿼리의 컬럼명으로 출력
4.ORDER BY절은 제일 아래쪽 쿼리에만 작성 할 수 있다.
- 집합 연산자로 데이터를 위아래로 연결하기
(UNION)
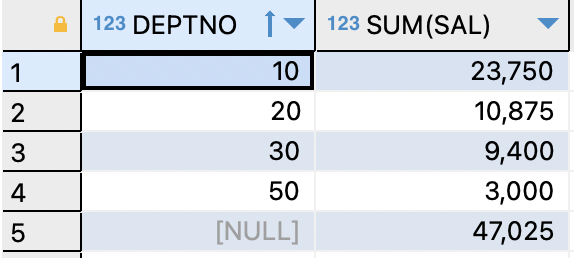
ex)부서 번호와 부서 번호별 월급을 출력하는데,
맨아래쪽 행에 토탈 월급을 출력하기SELECT deptno,sum(sal) FROM EMP GROUP BY deptno UNION SELECT NULL AS deptno,sum(sal) FROM EMP;
※
UNION ALL와UNION이 다른점
1.중복된 데이터를 하나의 고유한 값으로 출력
2.첫 번째 컬럼의 데이터 기준으로 내림차순으로 정렬하여 출력한다.
- 집합 연산자로 데이터의 교집합을 출력하기
(INTERSECT)
ex) 부서 번호 10번,20번인 사원들을 출력하는 쿼리의 결과와 부서 번호 20,30번을 출력하는 쿼리 결과의 교집합 출력하기SELECT ename,sal,job,deptno FROM EMP WHERE deptno IN (10,20) INTERSECT SELECT ename,sal,job,deptno FROM EMP WHERE deptno IN (20,30);
=>중복 데이터 제거,결과 데이터를 내림차순 정렬
- 집합 연산자로 데이터의 차이를 출력(MINUS)
ex)부서 번호 10번,20번인 사원들을 출력하는 쿼리의 결과와 부서 번호 20,30번을 출력하는 쿼리 결과의 차이 출력하기SELECT ename,sal,job,deptno FROM EMP WHERE deptno IN (10,20) MINUS SELECT ename,sal,job,deptno FROM EMP WHERE deptno IN (20,30);
- 서브 쿼리 사용하기
(단일행 서브쿼리)
ex) JONES보다 더 많은 월급을 받는 사원들의 이름과 월급을 출력하기# 메인쿼리 SELECT ename,sal FROM emp WHERE sal> (SELECT sal # 서브 쿼리 FROM EMP WHERE ename='JONES');
ex)SCOTT보다 더 많은 월급을 받는 사원들의 이름과 월급을 출력하기
SELECT ename,sal FROM EMP WHERE sal=(SELECT sal FROM emp WHERE ename='SCOTT') AND ename!='SCOTT';
- 서브 쿼리 사용하기
(다중 행 쿼리)
ex) 직업이 SALESMAN인 사원들과 같은 월급을 가진 사원들의 이름과 직업을 출력해보기SELECT ename,sal FROM EMP WHERE sal IN (SELECT sal FROM EMP WHERE job='SALESMAN');
=> 직업이 SALESMAN인 사원이 여러명이기 때문에 이퀄 (=)을 사용하면 오류가 발생
=> 이럴때에는 in 사용=>서브쿼리에서 메인 쿼리로 하나의 값이 아니라,
여러 개의 값이 반환되는 것을 다중 행 서브쿼리라고한다.※1.단일 서브 쿼리
-서브쿼리에서 메인쿼리로 하나의 값 반환
-연산자 : =,!=,<,>,>=,<=
2.다중 행 서브 쿼리
-서브쿼리에서 메인쿼리로 여러 개의 값이 반환
-연산자:in,not in,>any,<any,>all,>any
3.다중 컬럼 서브 쿼리
서브쿼리에서 메인쿼리로 여러 개의 컬럼값 반환
- 서브 쿼리 사용하기 (NOT IN)
ex)관리자가 아닌 사원들의 이름,월급,직업 출력SELECT ename,sal,job FROM EMP WHERE empno NOT IN (SELECT mgr FROM EMP WHERE mgr IS NOT NULL);=>
NOT IN을 사용할경우 서브쿼리에서 메인쿼리로 하나라도NULL값이 나오면 결과가 출력되지 않는다.
- 서브 쿼리 사용하기
(EXISTS와 NOT EXISTS)
ex)부서테이블에 있는 부서 번호 중에서 사원 테이블에도 존재하는 부서 번호의 부서 번호,부서명,부서위치 출력하기SELECT * FROM DEPT d WHERE EXISTS (SELECT * FROM EMP e WHERE e.deptno=d.deptno);=>테이블 A에 존재하는 데이터가 테이블 B에 존재하는지 여부를 확인할때에는
EXISTS또는NOT EXISTS를 사용한다.
=>WHERE 절에 따로 컬럼명 기재는 하지 않는다.
- 서브 쿼리 사용하기 (Having)
ex) 직업과 직업별 토탈월급을 출력하는데,
직업이 SALESMAN인 사원들의 토탈 월급보다 더 큰 값들만 출력하기SELECT job,sum(sal) FROM EMP GROUP BY job HAVING sum(sal)>(SELECT sum(sal) FROM EMP WHERE job='SALESMAN');
WHERE이 아닌HAVING절 사용SELECT문에서 서브쿼리를 사용할 수 있는 절
- SELECT/가능/스칼라 서브 쿼리
- FROM/가능/IN LINE VIEW
- WHERE/가능/서브 쿼리
- GROUP BY/불가능
- HAVING/가능/서브 쿼리
- ORDER BY/가능/스칼라 서브 쿼리
- 서브 쿼리 사용하기
(FROM절의 서브 쿼리)
ex)이름과 월급과 순위를 출력하는데 순위가 1위인 사원만 출력하기SELECT v.ename,v.sal,v.순위 FROM (SELECT ename,sal,RANK() OVER (ORDER BY sal DESC)순위 FROM emp) v WHERE v.순위=1;
=>WHERE절에는 분석함수를 사용할 수 없어서
FROM절 의 서브쿼리사용
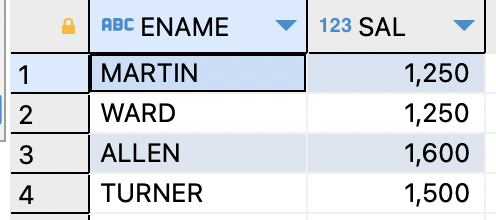
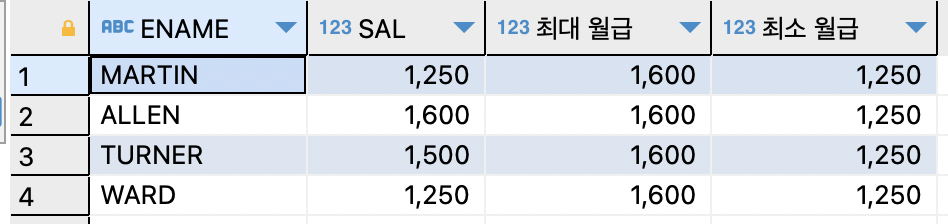
- 서브 쿼리 사용하기 (SELECT절의 서브 쿼리)
ex)직업이 SALESMAN인 사원들의 이름과 월급을 출력하는데,직업이 SALESMAN인 사원들의 최대 월급과 최소 월급도 같이 출력해보기SELECT ename,sal,(SELECT max(sal) FROM emp WHERE job='SALESMAN') AS "최대 월급", (SELECT min(sal) FROM emp WHERE job='SALESMAN') AS "최소 월급" FROM EMP WHERE job='SALESMAN'
- 데이터 입력하기 (INSERT)
ex)사원 테이블에 데이터를 입력하는데 사원 번호 2812,사원이름 JACK,월급 3500,입사일 2019년 6월 5일,직업 ANALYST로 해보기INSERT INTO emp(empno,ename,sal,hiredate,job) VALUES (2812,'JACK',3500,TO_DATE('2019/06/05','RRRR/MM/DD'),'ANALYST');=>
INSERT INTO테이블명VALUSE기입데이터
=>숫자는 그대로기입,문자와 날짜는 싱글쿼테이션 마크
※ 테이블에 NULL 값 기입할때
-명시적 방법 :NULL,''기입
-암시적 방법: 아무것도 쓰지 않기=> 테이블을 입력하고 수정하고 삭제하는
SQL문 : DML
INSERT:데이터입력
UPDATE:데이터수정
DELETE:데이터삭제
MERGE:데이터입력,수정,삭제를 한번에 수행
- 데이터 수정하기 (UPDATE)
ex) SCOTT의 월급을 3200으로 수정하기UPDATE EMP SET sal=3200 WHERE ename='SCOTT';=>
UPDATE테이블명SET변경할 데이터
WHERE변경할 데이터 제한하는 조건ex)SCOTT의 월급과 커미션을 동시에 변경하는 UPDATE문이다.
UPDATE EMP SET sal=3200,comm=200 WHERE ename='SCOTT';ex)UPDATE문에서 서브쿼리 사용하기
SET절에 서브 쿼리를 사용한 예제
SCOTT의 월급을 KING의 월급으로 변경하기UPDATE EMP SET sal =(SELECT sal FROM emp WHERE ename='KING') WHERE ename='SCOTT';=>
UPDATE문 모든 절에서 서브쿼리 사용 가능 함
- 데이터 삭제하기(DELETE,TRUNCATE,DROP)
ex)사원 테이블에서 SCOTT의 행 데이터 삭제DELETE FROM EMP WHERE ename='SCOTT';※ 오라클에서 데이터를 삭제하는 명령어
데이터/저장 공간/저장 구조/취소 여부/플래쉬백 여부
DELETE:삭제/남김/남김/가능/가능
TRUNCATE:삭제/삭제/남김/불가능/불가능
DROP:삭제/삭제/삭제/불가능/가능
TRUNCATE는 모든 데이터를 삭제,테이블 구조만 남김
DROP은 테이블 전체를 한번에 삭제 ,복구 가능DDL문
CREATE:객체 생성
ALTER: 객체 수정
DROP: 객체 삭제
TRUNCATE:객체 삭제
RENAME:객체 이름 수정
=>DDL문은 암시적인 COMMIT발생
- 데이터 저장 및 취소하기
(COMMIN,ROLLBACK)
ex)사원 테이블에 입력한 데이터가 데이터베이스에 저장되도록 해보기INSERT INTO emp (empno,ename,sal,deptno) VALUES (1122,'JACK',3000,20); COMMIT; UPDATE EMP SET sal=4000 WHERE ename='SCOTT'; ROLLBACK;=>
COMMIT:COMMIT이전에 수행했던 DML작업들을 데이터베이스에 영구히 반영하는 TCL이다.
=>ROLLBACK:마지막COMMIT명령어를 수행한 이후 DML문을 취소하는 TCL이다.※ TCL
COMMIT:모든 변경 사항을 데이터베이스에 반영
ROLLBACK: 모든 변경 사항을 취소
SAVEPOINT: 특정 지점까지의 변경을 취소
- 데이터 입력,수정,삭제 한번에 하기 (MERGE)
ex)사원 테이블에 부서 위치 컬럼을 추가하고, 부서 테이블을 이용하여 해당 사원의 부서 위치로 값이 갱신되도록 해보기 .
만약 부서 테이블에 존재하는 부서인데 사원 테이블에 없는 부서 번호라면 새롭게 사원 테이블에 입력되게 하기MERGE INTO emp e USING dept d ON (e.deptno=d.deptno) WHEN MATCHED THEN UPDATE SET e.loc=d.loc WHEN NOT MATCHED THEN INSERT (e.empno,e.deptno,e.loc) VALUES (1111,d.deptno,d.loc); # MERGE문을 사용하지 않는다면, 동일한 SQL UPDATE emp e SET loc =(SELECT loc FROM dept d WHERE d.deptno=e.deptno);=>
MERGE:데이터 입력과 수정과 삭제를 한번에 수행하는 명령어
- 락(LOCK)이해하기
ex)같은 데이터를 동시에 갱신할 수 없도록 하는 락(LOCK)을 이해해보기
=>LOCK을 사용하여 UPDATE문을 수행하면 해당 행에 LOCK을 건다.
- 서브 쿼리를 사용하여 데이터 입력하기
ex)EMP테이블의 구조를 그대로 복제한 EMP2테이블에 부서 번호가 10번인 사원들의 사원 번호,이름,월급,부서 번호를 입력해보기INSERT INTO emp2(empno,ename,sal,deptno) SELECT empno,ename,sal,deptno FROM EMP WHERE deptno=10;=>
VALUES절에 대신 서브 쿼리문을 기술
=>기본INSERT문은 한번에 하나의 행만 입력되지만, 서브 쿼리를 사용하여 INSERT문을 수행하면 여러 개의 행을 한번에 테이블에 입력할 수 있다.
- 서브 쿼리를 사용하여 데이터 수정하기
ex)직업이 SALESMAN인 사원들의 월급을 ALLEN의 월급으로 변경해보기UPDATE EMP SET sal=(SELECT sal FROM EMP WHERE ename='ALLEN') WHERE job='SALESMAN';※ SET절에 여러 개의 컬럼들을 기술하여 한 번에 갱신할 수도 있다.
UPDATE EMP SET (sal,comm)=(SELECT sal,comm FROM EMP WHERE ename='ALLEN') WHERE ename='SCOTT';
- 서브 쿼리를 사용하여 데이터 삭제하기
ex)SCOTT보다 더 많은 월급을 받는 사원들을 삭제해보기DELETE FROM EMP WHERE sal >(SELECT sal FROM EMP WHERE ename='SCOTT');ex) 월급이 해당 사원이 속한 부서 번호의 평균 월급보다 크면 삭제하는 서브 쿼리를 사용한 DELETE문 사용하기
DELETE FROM emp e WHERE sal>(SELECT avg(sal) FROM EMP s WHERE s.deptno=e.deptno);
- 서브 쿼리를 사용하여 데이터 합치기
ex)부서 테이블에 숫자형으로 SUMSAL컬럼을 추가한다.
사원 테이블을 이용하여 SUMSAL 컬럼의 데이터를 부서 테이블의 부서 번호별 토탈 월급으로 갱신MERGE INTO dept d USING (SELECT deptno,sum(sal) sumsal FROM EMP GROUP BY deptno) v ON (d.deptno=v.deptno) WHEN MATCHED THEN UPDATE SET d.sumsal =v.sumsal; # MERGE문을 수행하지 않고 서브 쿼리를 사용한 UPDATE문으로 수행하기 UPDATE dept d SET sumsal =(SELECT SUM(SAL) FROM emp e WHERE e.deptno=d.deptno);
- 계층형 질의문으로 서열을 주고 데이터 출력하기
ex)계층형 질의문을 이용하여 사원 이름,월급,직업을 출력하는데
사원들 간의 서열을 같이 출력하기SELECT rpad(' ',level*3) || ename AS employee,level,sal,job FROM emp START WITH ename='KING' CONNECT BY prior empno=mgr;=>
START WITH절에서 루트 노드의 데이터 지정
=>CONNECT BY절에서 부모 노드와 자식 노드들 간의 관계 지정
부모 노드 PRIOR 자식 노드ex) 위 문제에서 BLAKE와 BLAKE의 직속 부하들은 출력되지 않도록 하기
SELECT rpad(' ',level*3) || ename AS employee,level,sal,job FROM emp START WITH ename='KING' CONNECT BY prior empno=mgr AND ename!='BLAKE';ex)계층형 질의문을 이용해서 사원 이름,월급,직업을 서열과 같이 출력하는데,서열 순서를 유지하면서 월급이 높은 사원부터 출력해보기
SELECT rpad(' ',level*3) || ename AS employee,level,sal,job FROM emp START WITH ename='KING' CONNECT BY prior empno=mgr ORDER SIBLINGS BY sal DESC;=>
ORDER와BY사이에SIBLINGS을 사용하여 정렬하면
계층형 질의문의 서열 순서를 깨트리지 않으면서 출력할 수 있다.ex)계층형 질의문과 SYS_CONNECT_BY함수를 이용하여 서열 순서를 가로로 출력해보기
SELECT ename,SYS_CONNECT_BY_PATH(ename,'/') AS PATH FROM emp START WITH ename='KING' CONNECT BY PRIOR empno=mgr;
- 일반 테이블 생성하기 (CREATE TABLE)
ex)사원 번호,이름,월급,입사일을 저장할 수 있는 테이블을 생성CREATE TABLE EMP01 (EMPNO NUMBER(10), ENAME VARCHAR2(10), SAL NUMBER(10,2), HIREDATE DATE);※ 테이블 생성 시 사용할 수 있는 주요 데이터 유형
CHAR: 고정 길이 문자 데이터 유형, 최대 길이 2000
VARCHAR2: 가변 길이 문자 데이터 유형,최대 길이 4000
LONG: 가변 길이 문자 데이터 유형,최대 2GB 문자 데이터 허용
CLOB: 문자 데이터 유형이며,최대 4GB 문자 데이터 허용
BLOB: 바이너리 데이터 유형,최대 4GB의 바이너리 데이터를 허용
NUMBER: 숫자 데이터 유형
DATE: 날짜 데이터 유형
- 임시 테이블 생성하기 (CREATE TEMPORARY TABLE)
ex)사원 번호,이름,월급을 저장할 수 있는 테이블을 생성하는데 COMMIT할때까지만 데이터를 저장할 수 있도록 생성CREATE GLOBAL TEMPORARY TABLE EMP37 (EMPNO NUMBER(10), ENAME VARCHAR2(10), SAL NUMBER(10)) ON COMMIT DELETE ROWS;=> ON COMMIT DELETE ROWS를 옵션으로 두고 만든 임시 테이블은
COMMIT을 하면 데이터가 사라진다.
- 복잡한 쿼리를 단순하게 하기 (VIEW)
ex)직업이 SALESMAN인 사원들의 사원 번호,이름,월급,직업,부서번호를 출력하는 VIEW를 생성CREATE VIEW EMP_VIEW AS SELECT empno,ename,sal,deptno FROM EMP WHERE job='SALESMAN';
=>VIEW는 보안상 공개하면 안되는 데이터들이 있을 때 유용ex)부서 번호와 부서 번호별 평균 월급을 출력하는 VIEW를 생성
CREATE TABLE EMP_VIEW2 AS SELECT deptno,round(avg(sal)) "평균 월급" FROM EMP GROUP BY deptno;=>뷰 생성시,함수나 그룹 함수를 작성할 때는 반드시 컬럼 별칭을 사용해야함.
※ 뷰의 종류
단순 VIEW:테이블의 개수 1개/함수포함 /데이터 수정 가능
복합 VIEW:테이블 개수2개이상,함수 포함,데이터 수정불가SELECT e.ename,e.sal,e.deptno,v.평균 월급 FROM emp e,(SELECT deptno,round(avg(sal)) "평균 월급" FROM EMP GROUP BY deptno) v WHERE e.deptno=v.deptno AND e.sal>v.평균 월급;=> 복잡한쿼리를 단순화
SELECT e.ename,e.sal,e.deptno,v.평균 월급 FROM emp e,emp_view2 v WHERE e.deptno=v.deptno AND e.sal>v.평균 월급;
- 데이터 검색 속도를 높이기 (INDEX)
ex)월급을 조회할 때,검색속도를 높이기 위해 월급에 인덱스를 생성CREATE INDEX EMP_SAL ON EMP(SAL);=>
ON절 다음에 인덱스를 생성하고자 하는 테이블(컬럼명)으로 작성
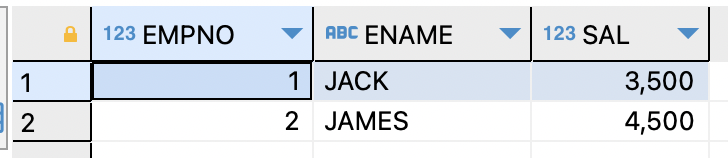
- 절대로 중복되지 않는 번호 만들기 (SEQUENCE)
ex)숫자 1번부터 100번까지 출력하는 시퀀스를 생성해보기CREATE SEQUENCE SEQ1 START WITH 1 INCREMENT BY 1 MAXVALUE 100 NOCYCLE;시퀀스를 사용하여 테이블 생성,데이터 입력 방법
# 테이블 생성 CREATE TABLE EMP02 (EMPNO NUMBER(10), ENAME VARCHAR2(10), SAL NUMBER(10)); # 데이터 입력 INSERT INTO EMP02 VALUES(SEQ1.NEXTVAL,'JACK',3500); INSERT INTO EMP02 VALUES(SEQ1.NEXTVAL,'JAMES',4500);
- 실수로 지운 데이터 복구하기 (FLASHBACK QUERY)
ex)사원 테이블의 5분 전 KING데이터를 검색해보기SELECT * FROM EMP AS OF TIMESTAMP(SYSTIMESTAMP-INTERVAL '5' MINUTE) WHERE ENAME='KING';※ 테이블을 플래쉬백할 수 있는 골든 타임은 기본이 15분
이 시간은 데이터베이스의 파라미터인 UNDO_RETENTION으로 확인해 볼 수 있다.SELECT name,value FROM "V$PARAMETER" WHERE name='undo_retention';
- 실수로 지운 데이터 복구하기 (FLASHBACK TABLE)
ex)사원 테이블의 5분 전으로 되돌리기ALTER TABLE emp ENABLE ROW MOVEMENT; FLASHBACK TALBE emp TO TIMESTAMP(SYSTIMESTAMP-INTERVAL '5' MINUTE);=>플래쉬백이 가능한 상태로 변경해줘야하는데
ALTER명령어로 가능한 상태로 설정한다.
=> 설정후 확인방법SELECT row_movement FROM user_tables WHERE table_name='EMP';
=>성공적으로 플래쉬백이 되었다면 데이터를 확인한 후,COMMIT을 해야 변경된 상태가 영구히 반영됨
- 실수로 지운 데이터 복구하기 (FLASHBACK DROP)
ex)DROP된 사원 테이블을 휴지통에서 복원해보기FLASHBACK TABLE emp TO BEFORE DROP;테이블 ROP후 휴지통에 존재하는지 확인하는 방법
DROP TABLE emp; SELECT ORIGINAL_NAME,DROPTIME FROM USER_RECYCLEBIN;휴지통에서 복구할 때 테이블명을 다른 이름으로 변경하는 방법
FLASHBACK TABLE emp TO BEFORE DROP RENAME TO emp2;
- 실수로 지운 데이터 복구하기
(FLASHBACK VERSION QUERY)
ex) 사원 테이블의 데이터가 과거 특정 시점부터 지금까지 어떻게 변경되어 왔는지 이력 정보를 출력해보기SELECT ename,sal,versions_starttime,versions_endtime,versions_operation FROM emp VERSIONS BETWEEN TIMESTAMP TO_TIMESTAMP('2019-06-30 08:20:00','RRRR-MM-DD HH24:MI:SS') WHERE ename='KING' ORDER BY versions_starttime;
- 실수로 지운 데이터 복구하기
(FLASHBACK TARNSACTION QUERY)
ex)사원 테이블의 데이터를 5분 전으로 되돌리기 위한 DML문 출력SELECT undo_sql FROM flachback_transaction_query WHERE table_owner ='SCOTT' AND table_name='EMP' AND commit_scn between 9757390 AND 9457397 ORDER BY start_timestamp desc;
- 데이터의 품질 높이기 (PRIMARY KEY)
CREATE TABLE DEPT2 (DEPTNO NUMBER(10) CONSTRAINT DEPT2_DEPTNO_PK PRIMARY KEY, DNAME VARCHAR2(14), LOC VARCHAR2(10));=>PRIMARY KEY제약이 걸린 컬럼은 중복 데이터와 NULL값 불가
=>CONSTRAINT+테이블명_컬럼명_제약종류축약제약을 확인하는 방법
SELECT a.CONSTRAINT_NAME,a.CONSTRAINT_TYPE,b.COLUMN_NAME FROM USER_CONSTRAINTS a,USER_CONS_COLUMNS b WHERE a.TABLE_NAME='DEPT2' AND a.CONSTRAINT_NAME=b.CONSTRAINT_NAME;
제약을 생성하는 시점은
테이블 생성 시점, 테이블 생성 후에 두가지로 가능테이블 생성 후 제약을 생성하는 방법
CREATE TABLE DEPT2 (DEPTNO NUMBER(10), DNAME VARCHAR2(13), LOC VARCHAR2(10)); ALTER TABLE DEPT2 ADD CONSTRAINT DEPT2_DEPTNO_PK PRIMARY KEY(DEPTNO);=> PRIMARY KEY다음에는 괄호를 열고 어느 컬럼에 제약을 생성할지 명시
- 데이터의 품질 높이기 (UNIQUE)
CREATE TABLE DEPT3 (DEPTNO NUMBER(10), DNAME VARCHAR2(14) CONSTRAINT DEPT3_DNAME_UN UNIQUE, LOC VARCHAR2(10));=>
UNIQUE는 중복된 데이터가 있어서는 안되는 컬럼에 제약 걸수 있다.
=>PRIMARY KEY와는 달리 UNIQUE제약이 걸린 컬럼에 NULL값은 입력할 수 있다.
- 데이터의 품질 높이기 (NOT NULL)
CREATE TABLE DEPT5 (DEPTNO NUMBER(10), DNAME VARCHAR2(14) LOC VARCHAR2(10) CONSTRAINT DEPT5_LOC_NN NOT NULL);=>특정 컬럼에 NULL값입력을 허용하지 않게하려면 NOT NULL제약 생성
테이블 생성되는 이후에 가능하다.
CREATE TABLE DEPT6 (DEPTNO NUMBER(10), DNAME VARCHAR2(14) LOC VARCHAR2(10)); ALTER TABLE DEPT6 MODIFY LOC CONSTRAINT DEPT6_LOC_NN NOT NULL;=> NOT NULL제약은 ADD가 아니라 MODIFY로 생성
=>NOT NULL뒤에 괄호 열고 컬럼 명시하지 않음
=>기존의 데이터중 NULL값이 포함되어 있다면 ALTER명령어로 LOC컬럼에 NOT NULL제약 생성 불가
- 데이터의 품질 높이기 (CHECK)
ex)사원 테이블을 생성하는데,월급이 0에서 6000사이의 데이터만 입력되거나 수정될 수 있도록 제약을 걸어 생성해보기CREATE TABLE EMP6 (EMPNO NUMBER(10), ENAME VARCHAR2(20), SAL NUMBER(10) CONSTRAINT EMP6_SAL_CK CHECK (SAL BETWEEN 0 AND 6000) );=>CHECK제약은 특정 컬럼에 특정 조건의 데이터만 입력되거나 수정되도록 제한을 거는 제약
=> CHECK 다음에 나오는 괄호 안에 제한하고 싶은 데이터에 대한 조건 기술제약을 삭제하는 명령어
ALTER TABLE emp6 DROP CONSTRAINT emp6_sal_ck;
- 데이터의 품질 높이기 (FOREIGN KEY)
ex)사원 테이블의 부서 번호에 데이터를 입력할때 부서 테이블에 존재하는 부서 번호만 입력될 수 있도록 제약을 생성CREATE TABLE DEPT7 (DEPTNO NUMBER(10) CONSTRAINT DEPT7_DEPTNO_PK PRIMARY KEY, DNAME VARCHAR2(14), LOC VARCHAR2(10)); CREATE TABLE EMP37 (EMPNO NUMBER(10), ENAME VARCAHR2(20), SAL NUMBER(10), DEPTNO NUMBER(10) CONSTRAINT EMP7_DEPTNO_FK REFERENCES DEPT7(DEPTNO));DEPT7테이블의 PRIMARY KEY 삭제
ALTER TABLE DEPT7 DROP CONSTRAINT DEPT7_DEPTNO_PK cascade;=> CASCADE옵션을 붙여야 삭제가 됨