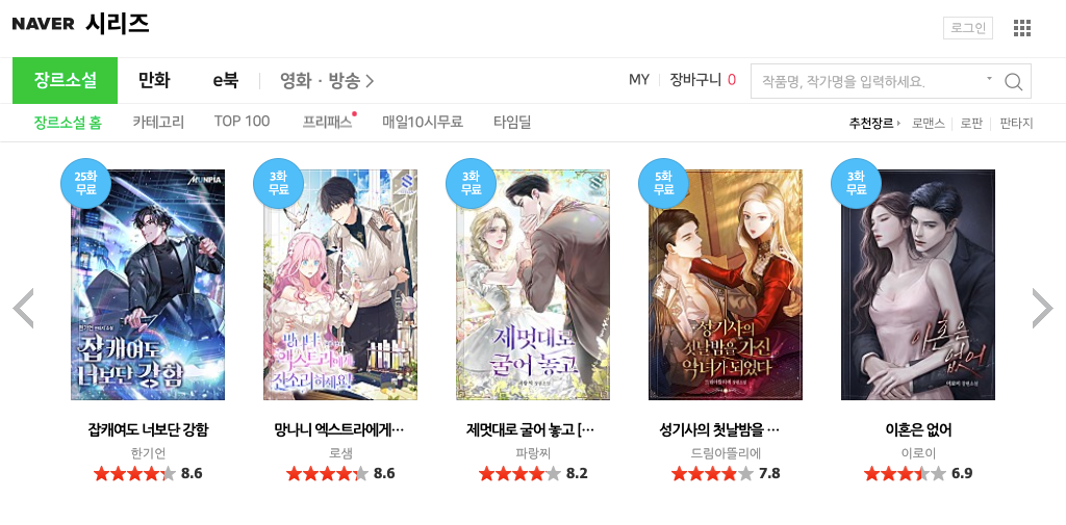
멋쟁이 사자의 첫 미니 개인 프로젝트로 스크래핑 실습을 하게 되었다.
그래서 나는 네이버 시리즈의 웹소설 제목, 시놉시스를 스크래핑 하기로 마음먹었다.
1. 라이브러리 로드
import pandas as pd
import numpy as np
import requests
2. 수집할 url 정하기
나는 네이버 웹소설 (시리즈) top100을 긁어오기로 했으니까,
시리즈 웹소설 top 100
에 들어갔다. 이 링크를 뒤에까지 쭉 보면 CategoryCode와 page가 보이는데, 추후 이것들만 건드려 줄 것이다.
그런데 지금은 일단 전체 장르 순위만 긁어올 거니까, page만 page_no 변수로 바꿔준다.
page_no = 1
# URL 만들기
url = f"https://series.naver.com/novel/top100List.series?rankingTypeCode=DAILY&categoryCode=ALL&page={page_no}"
print(url)3. requests를 통한 HTTP 요청
headers = {"user-agent":"****"])
response = requests.get(url, headers=headers)"****" 안에 들어갈 내용은 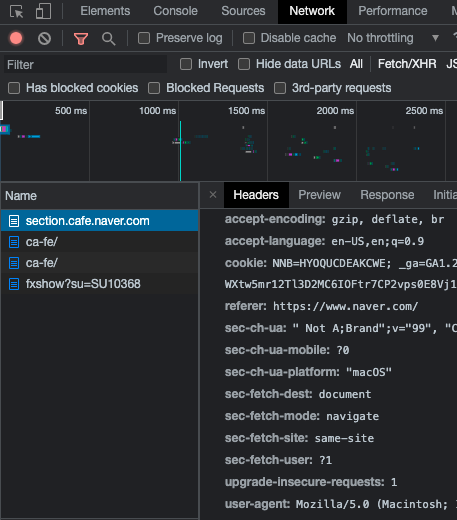
Inspect - Network - Headers 맨 아래 user_agent 정보를 복붙하면 된다.
그럼 이제 이 페이지를 긁어 보자.
response.text결과 :
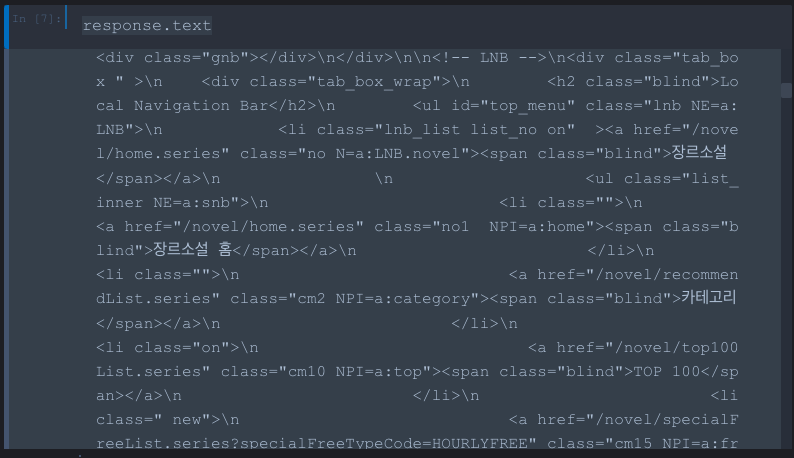
내 반응 :

이걸로는 뭐가 뭔지 알 수가 없다. 그래서 우리는 이걸 예쁘게(!)보기 위해 모듈을 하나 import 해 줄 것이다.
그 이름도 직관적인 "BeautifulSoup".
html을 파싱해주는 역할을 하는 모듈이다.
from bs4 import BeautifulSoup as bs
html = bs(response.text, "lxml")
html그 결과 :

여전히 더럽긴 하지만 아까보단 낫다. 그러나 이 아름다운수프는
soup.title
# <title>The Dormouse's story</title>
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>이런 식으로 원하는 정보만 뽑아오게 할 수 있다. 이를 테면
html.title.string이렇게 코드를 입력하면 타이틀인
"네이버 시리즈"
라는 결과가 리턴된다.
4. 원하는 정보 경로 찾기
그럼 이제 저 수많은 텍스트들 중에 내가 원하는 텍스트들만 갖고 오려면 어떻게 해야 할까. 그에 맞는 태그 값을 찾아 지정해 줘야 한다.
나는 여기서 제목이랑 줄거리만 긁어 오고 싶다. 저 별점이랑 작가랑 3화 무료 같은 것들은 내 관심사가 아니다.
그럼 다시 우리의 친구 inspect로 들어가 보자.
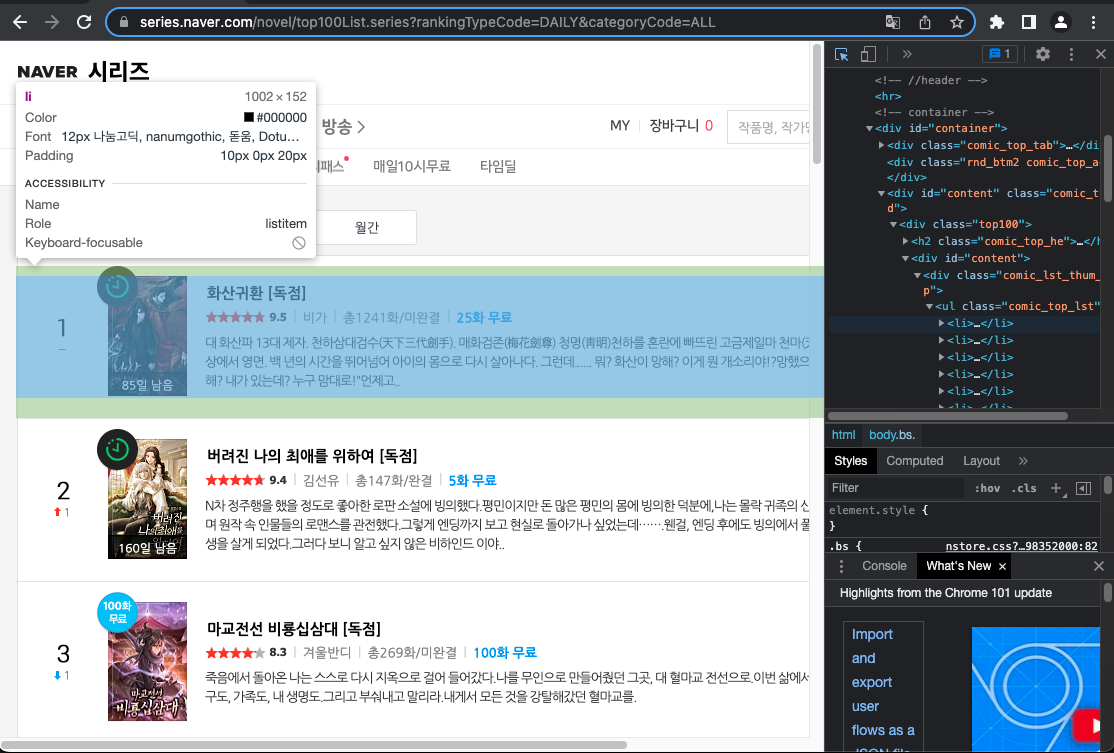
inspect에는 너무 좋은 기능이 있는 게, 저 좌측상단 화살표를 클릭하고 내가 원하는 정보값이 있는 곳을 마우스로 호버하면 영역지정이 되고, 그 영역을 클릭하면 해당 태그가 있는 곳을 inspect에 띄워 준다. 그럼 나는 또 감사하게,
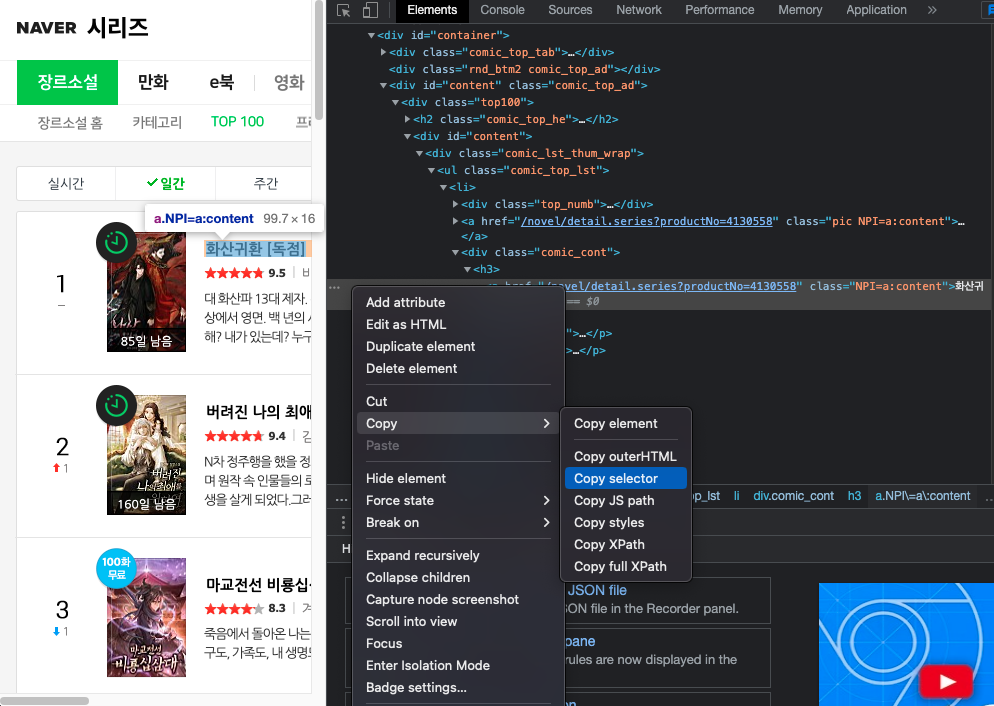
해당 태그로 들어가서 태그를 우클릭, copy에서 copy selector를 선택해 준다. 저게 바로 selector로 태그들을 찾을 수 있게 해 주는 길라잡이다.
#content > div > ul > li:nth-child(1) > div.comic_cont > h3 > a복사가 됐다! 그럼 이제 이걸 html.select에 넣어준다. 저 태그 뒤에 : 이거 뒤에 있는 것들은 지워준다.
title_list = html.select("#content > div > ul > li > div.comic_cont > h3 > a")title_list를 입력해보면,

그럼 이제 저 태그들을 다 빼고 텍스트만 추출해 보자.
.text를 사용하면 텍스트만 알아서 추출해 준다. 그럼 텍스트만 추출해서 리스트에 담아 보자.
title_list_txt = []
for i in range(len(title_list)) :
title_list_txt.append(title_list[i].text)
title_list_txt
그 결과,

(일간 순위를 수집하고 있는데 본 포스팅은 며칠에 걸쳐 작성되었으므로 순위가 조금 변동되었다. 양해부탁드린다.)

같은 방식으로 줄거리도 긁어 보자. 줄거리의 위치는
#content > div > ul > li > div.comic_cont > p이므로,
summary_list = html.select("#content > div > ul > li > div.comic_cont > p")
summary_list_txt = []
for i in range(1, len(summary_list),2) :
summary_list_txt.append(summary_list[i].text))
summary_list_txt역시 리스트에 담아 주었다.
그럼 이제 이걸 데이터프레임에 담아서 합쳐 줄 거다. 어차피 100위까지 다 긁을 거라서 100위까지 전부 리스트에 담아 준 다음 데이터프레임에 넣는 게 더 효율적이겠지만, 지금은 데이터 수도 적고 보다 쉽고 직관적으로 데이터프레임에 넣고 합쳐주는 식으로 진행해 보겠다.
5. 데이터프레임에 넣고 합치기
리스트를 데이터프레임에 넣어 주고,
df_title_list_txt = pd.DataFrame(title_list_txt)
df_summary_list_txt = pd.DataFrame(summary_list_txt)두 데이터프레임을 합쳐 보자.
title_summary = pd.concat([df_title_list_txt, df_summary_list_txt],axis=1)
title_summary
완벽하다.
6. 페이지별 데이터 수집 함수 만들기
그럼 여태까지의 과정을 함수로 만들어서 페이지를 입력하면 그 페이지의 순위를 긁어 오는 함수를 만들어 보자. 그냥 순서대로 복붙만 해주면 된다.
def get_novel_list(page_no):
url = f"https://series.naver.com/novel/top100List.series?rankingTypeCode=DAILY&categoryCode=ALL&page={page_no}"
response = requests.get(url, headers=headers)
html = bs(response.text, "lxml")
title_list = html.select("#content > div > ul > li > div.comic_cont > h3 > a")
summary_list = html.select("#content > div > ul > li > div.comic_cont > p")
title_list_txt = []
for i in range(len(title_list)) :
title_list_txt.append(title_list[i].text)
title_list_txt
summary_list_txt = []
for i in range(1, len(summary_list),2) :
summary_list_txt.append(summary_list[i].text)
df_title_list_txt = pd.DataFrame(title_list_txt)
df_summary_list_txt = pd.DataFrame(summary_list_txt)
title_summary = pd.concat([df_title_list_txt, df_summary_list_txt],axis=1)
return title_summary이제 저 page_no에 원하는 페이지 번호만 할당해 주면 해당 페이지의 소설 제목과 요약이 긁어와진다.
그런데 약간의 문제가 있다. 페이지는 5페이지까진데, 6이상의 int를 page_no에 할당하면 그냥 마지막 페이지인 5페이지의 결과를 같이 리턴하는 것이다. 그러니까 이걸 이후 if문을 사용해서 5페이지에서 함수를 멈추게 할 것이다.
7. 페이지 끝까지 순위 수집하기
#시작할 페이지 번호
page_no = 1
# 데이터를 저장할 빈 변수 선언
novel_list_df = pd.DataFrame()
while True:
#몇페이지 수집 중인지 확인
print(page_no)
get_novel_list(page_no)
get_novel_list(page_no).equals(get_novel_list(page_no-1)) :
break
#해당 페이지의 데이터 프레임과 이전 페이지의 데이터프레임이 똑같으면 while 문을 break해라.
novel_list_df = pd.concat([novel_list_df,title_summary])
page_no += 1

그럼 이제 마지막으로 컬럼명을 바꿔 주자.
novel_list_df = novel_list_df.reset_index(drop=True)
novel_list_df.columns = ["제목","요약"]
novel_list_df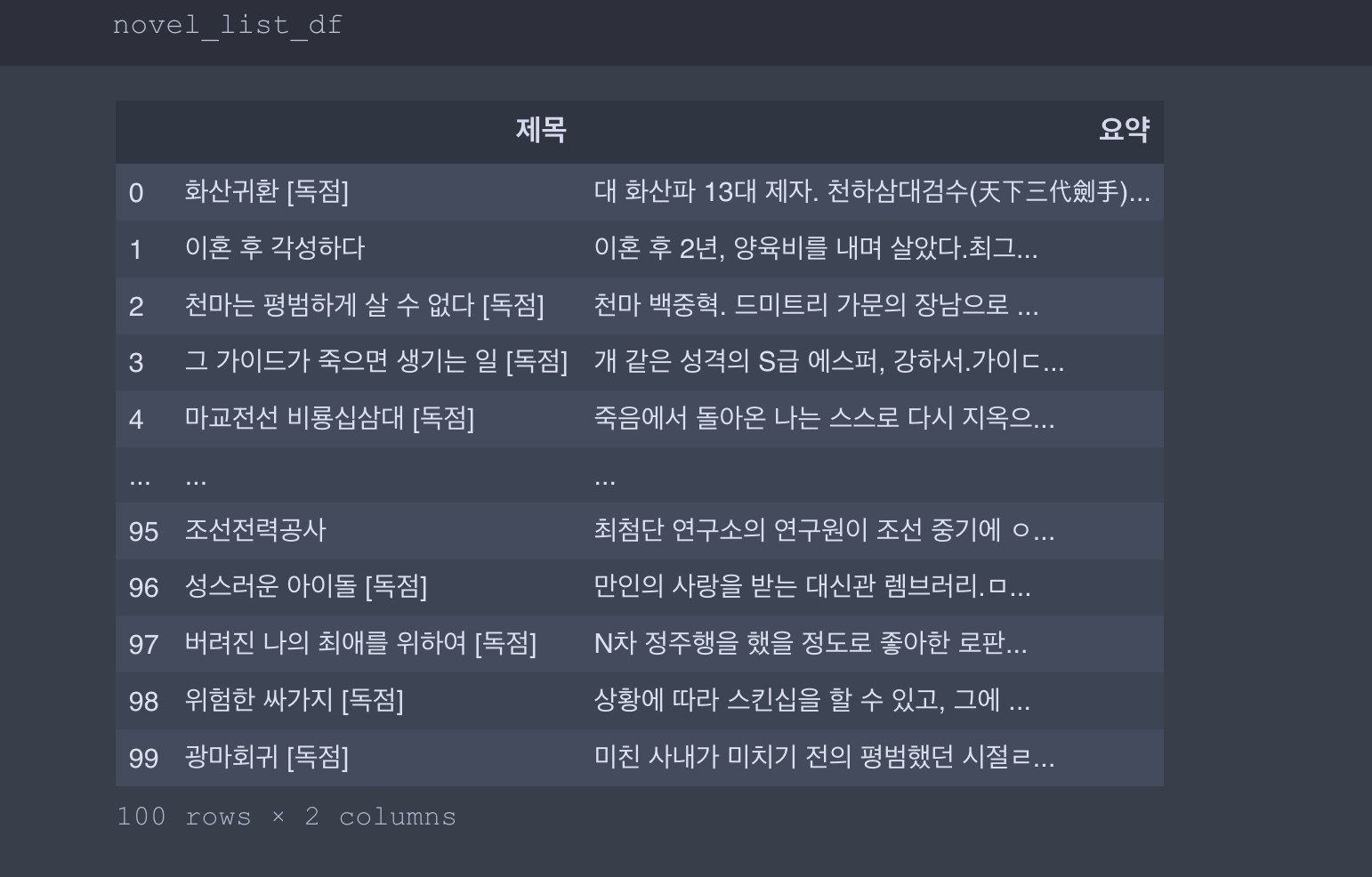
끝!!!!!
+이후, csv로 저장을 해 주면 된다.
genre = "전체 장르"
file_name = f"novel_list_top_100_{genre}.csv"
file_name
novel_list_df.to_csv(file_name, index=False)