
1.- 기술. TTS
[각모델정리][TTS_Conversation]
Python으로 TTS(Text-to-Speech, 또는 음성합성, Speech Synthesis)는 다양한 방법으로 할 수 있다. 여기에서는 인터넷이 연결된 상태에서 자연스러운 합성음성을 제공하는 다음의 무료 서비스를 소개한다.
3.- 기술. DALL.E 2

1. 분류모델
2. unmask model
[각모델정리][Unmasked_klue/bert-base/FillMaskPipeline]
https://huggingface.co/klue/bert-base
https://wikidocs.net/153992
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("klue/bert-base")
tokenizer = AutoTokenizer.from_pretrained("klue/bert-base")pipelines
https://huggingface.co/docs/transformers/main_classes/pipelines
[MASK] 토큰 예측하기
from transformers import FillMaskPipeline
pip = FillMaskPipeline(model=model, tokenizer=tokenizer)3. STS model
[각모델정리][STS_klue/roberta-base]
: STS(Semantic Textual Similarity) 의 목표는 입력으로 주어진 두 문장간의 의미 동등성을 수치로 표현하는 것이다.
KLUE는
: 총 8개의 Task에 대해 평가할 수 있다.
- 토픽 분류 (TC)
- 의미 유사도 (STS)
- 자연어 추론 (NLI)
- 개체명 인식 (NER)
- 관계 추출 (RE)
- 의존 구문 분석 (DP)
- 기계 독해 (MRC)
- 대화 상태 추적 (DST)
4. QA봇 model
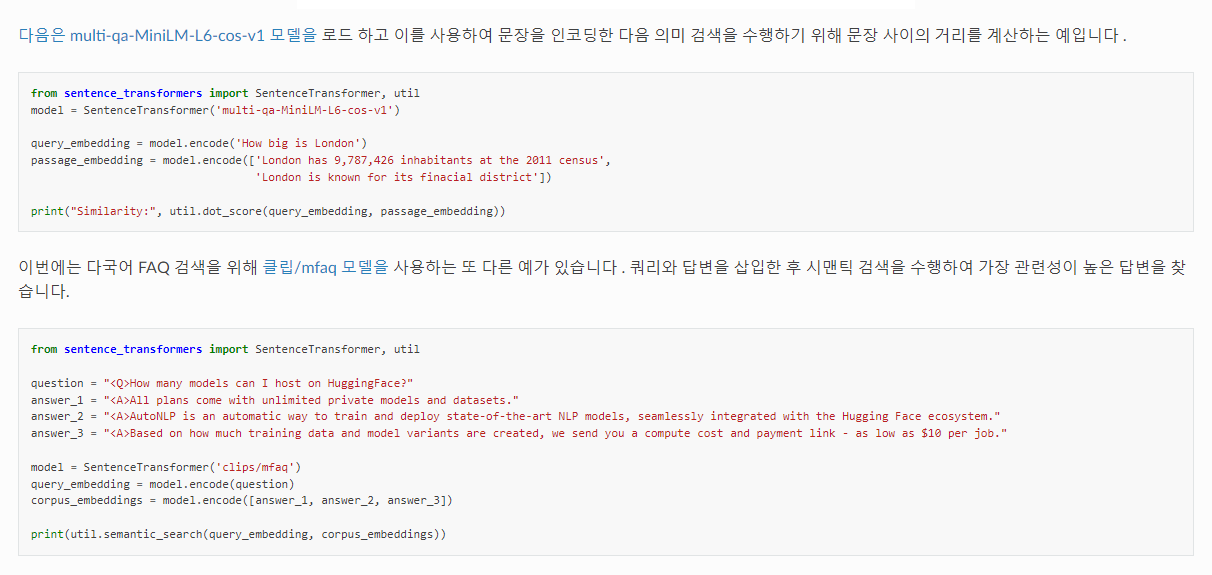
[각모델정리][QA봇/multi-qa-MiniLM-L6-cos-v1]
https://wikidocs.net/154530 : 이전 모델
https://www.sbert.net/docs/hugging_face.html#sharing-your-models
5. T5 문서 요약 model
[각모델정리][T5_eenzeenee/t5-small-korean-summarization]
https://huggingface.co/prompthero/openjourney
from diffusers import StableDiffusionPipeline
import torch
model_id = "prompthero/openjourney"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "retro serie of different cars with different colors and shapes, mdjrny-v4 style"
image = pipe(prompt).images[0]
image.save("./retro_cars.png")https://huggingface.co/eenzeenee/t5-small-korean-summarization
import nltk
nltk.download('punkt')
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained('eenzeenee/t5-small-korean-summarization')
tokenizer = AutoTokenizer.from_pretrained('eenzeenee/t5-small-korean-summarization')
prefix = "summarize: "
sample = """
안녕하세요? 우리 (2학년)/(이 학년) 친구들 우리 친구들 학교에 가서 진짜 (2학년)/(이 학년) 이 되고 싶었는데 학교에 못 가고 있어서 답답하죠?
그래도 우리 친구들의 안전과 건강이 최우선이니까요 오늘부터 선생님이랑 매일 매일 국어 여행을 떠나보도록 해요.
어/ 시간이 벌써 이렇게 됐나요? 늦었어요. 늦었어요. 빨리 국어 여행을 떠나야 돼요.
그런데 어/ 국어여행을 떠나기 전에 우리가 준비물을 챙겨야 되겠죠? 국어 여행을 떠날 준비물, 교안을 어떻게 받을 수 있는지 선생님이 설명을 해줄게요.
(EBS)/(이비에스) 초등을 검색해서 들어가면요 첫화면이 이렇게 나와요.
자/ 그러면요 여기 (X)/(엑스) 눌러주(고요)/(구요). 저기 (동그라미)/(똥그라미) (EBS)/(이비에스) (2주)/(이 주) 라이브특강이라고 되어있죠?
거기를 바로 가기를 누릅니다. 자/ (누르면요)/(눌르면요). 어떻게 되냐? b/ 밑으로 내려요 내려요 내려요 쭉 내려요.
우리 몇 학년이죠? 아/ (2학년)/(이 학년) 이죠 (2학년)/(이 학년)의 무슨 과목? 국어.
이번주는 (1주)/(일 주) 차니까요 여기 교안. 다음주는 여기서 다운을 받으면 돼요.
이 교안을 클릭을 하면, 짜잔/. 이렇게 교재가 나옵니다 .이 교안을 (다운)/(따운)받아서 우리 국어여행을 떠날 수가 있어요.
그럼 우리 진짜로 국어 여행을 한번 떠나보도록 해요? 국어여행 출발. 자/ (1단원)/(일 단원) 제목이 뭔가요? 한번 찾아봐요.
시를 즐겨요 에요. 그냥 시를 읽어요 가 아니에요. 시를 즐겨야 돼요 즐겨야 돼. 어떻게 즐길까? 일단은 내내 시를 즐기는 방법에 대해서 공부를 할 건데요.
그럼 오늘은요 어떻게 즐길까요? 오늘 공부할 내용은요 시를 여러 가지 방법으로 읽기를 공부할겁니다.
어떻게 여러가지 방법으로 읽을까 우리 공부해 보도록 해요. 오늘의 시 나와라 짜잔/! 시가 나왔습니다 시의 제목이 뭔가요? 다툰 날이에요 다툰 날.
누구랑 다퉜나 동생이랑 다퉜나 언니랑 친구랑? 누구랑 다퉜는지 선생님이 시를 읽어 줄 테니까 한번 생각을 해보도록 해요."""
inputs = [prefix + sample]
inputs = tokenizer(inputs, max_length=512, truncation=True, return_tensors="pt")
output = model.generate(**inputs, num_beams=3, do_sample=True, min_length=10, max_length=64)
decoded_output = tokenizer.batch_decode(output, skip_special_tokens=True)[0]
result = nltk.sent_tokenize(decoded_output.strip())[0]
print('RESULT >>', result)6. 질문생성/ QnA Model
[각모델정리][QnA/kobart-QuestionGeneration]
질문 생성 https://huggingface.co/Sehong/kobart-QuestionGeneration
응답 https://huggingface.co/bespin-global/klue-bert-base-aihub-mrc
- 질문생성
import torch
from transformers import PreTrainedTokenizerFast
from transformers import BartForConditionalGeneration
tokenizer = PreTrainedTokenizerFast.from_pretrained('Sehong/kobart-QuestionGeneration')
model = BartForConditionalGeneration.from_pretrained('Sehong/kobart-QuestionGeneration')
text = "1989년 2월 15일 여의도 농민 폭력 시위를 주도한 혐의(폭력행위등처벌에관한법률위반)으로 지명수배되었다. 1989년 3월 12일 서울지방검찰청 공안부는 임종석의 사전구속영장을 발부받았다. 같은 해 6월 30일 평양축전에 임수경을 대표로 파견하여 국가보안법위반 혐의가 추가되었다. 경찰은 12월 18일~20일 사이 서울 경희대학교에서 임종석이 성명 발표를 추진하고 있다는 첩보를 입수했고, 12월 18일 오전 7시 40분 경 가스총과 전자봉으로 무장한 특공조 및 대공과 직원 12명 등 22명의 사복 경찰을 승용차 8대에 나누어 경희대학교에 투입했다. 1989년 12월 18일 오전 8시 15분 경 서울청량리경찰서는 호위 학생 5명과 함께 경희대학교 학생회관 건물 계단을 내려오는 임종석을 발견, 검거해 구속을 집행했다. 임종석은 청량리경찰서에서 약 1시간 동안 조사를 받은 뒤 오전 9시 50분 경 서울 장안동의 서울지방경찰청 공안분실로 인계되었다. <unused0> 1989년 2월 15일"
raw_input_ids = tokenizer.encode(text)
input_ids = [tokenizer.bos_token_id] + raw_input_ids + [tokenizer.eos_token_id]
summary_ids = model.generate(torch.tensor([input_ids]))
print(tokenizer.decode(summary_ids.squeeze().tolist(), skip_special_tokens=True))
# <unused0> is sep_token, sep_token seperate content and answer- 응답
## Load Transformers library
import torch
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
def predict_answer(qa_text_pair):
# Encoding
encodings = tokenizer(context, question,
max_length=512,
truncation=True,
padding="max_length",
return_token_type_ids=False,
return_offsets_mapping=True
)
encodings = {key: torch.tensor([val]).to(device) for key, val in encodings.items()}
# Predict
pred = model(encodings["input_ids"], attention_mask=encodings["attention_mask"])
start_logits, end_logits = pred.start_logits, pred.end_logits
token_start_index, token_end_index = start_logits.argmax(dim=-1), end_logits.argmax(dim=-1)
pred_ids = encodings["input_ids"][0][token_start_index: token_end_index + 1]
answer_text = tokenizer.decode(pred_ids)
# Offset
answer_start_offset = int(encodings['offset_mapping'][0][token_start_index][0][0])
answer_end_offset = int(encodings['offset_mapping'][0][token_end_index][0][1])
answer_offset = (answer_start_offset, answer_end_offset)
return {'answer_text':answer_text, 'answer_offset':answer_offset}
## Load fine-tuned MRC model by HuggingFace Model Hub ##
HUGGINGFACE_MODEL_PATH = "bespin-global/klue-bert-base-aihub-mrc"
tokenizer = AutoTokenizer.from_pretrained(HUGGINGFACE_MODEL_PATH)
model = AutoModelForQuestionAnswering.from_pretrained(HUGGINGFACE_MODEL_PATH).to(device)
## Predict ##
context = '''애플 M2(Apple M2)는 애플이 설계한 중앙 처리 장치(CPU)와 그래픽 처리 장치(GPU)의 ARM 기반 시스템이다.
인텔 코어(Intel Core)에서 맥킨토시 컴퓨터용으로 설계된 2세대 ARM 아키텍처이다. 애플은 2022년 6월 6일 WWDC에서 맥북 에어, 13인치 맥북 프로와 함께 M2를 발표했다.
애플 M1의 후속작이다. M2는 TSMC의 '향상된 5나노미터 기술' N5P 공정으로 만들어졌으며, 이전 세대 M1보다 25% 증가한 200억개의 트랜지스터를 포함하고 있으며, 최대 24기가바이트의 RAM과 2테라바이트의 저장공간으로 구성할 수 있다.
8개의 CPU 코어(성능 4개, 효율성 4개)와 최대 10개의 GPU 코어를 가지고 있다. M2는 또한 메모리 대역폭을 100 GB/s로 증가시킨다.
애플은 기존 M1 대비 CPU가 최대 18%, GPU가 최대 35% 향상됐다고 주장하고 있으며,[1] 블룸버그통신은 M2맥스에 CPU 코어 12개와 GPU 코어 38개가 포함될 것이라고 보도했다.'''
question = "m2가 m1에 비해 얼마나 좋아졌어?"
qa_text_pair = {'context':context, 'question':question}
result = predict_answer(qa_text_pair)
print('Answer Text: ', result['answer_text']) # 기존 M1 대비 CPU가 최대 18 %, GPU가 최대 35 % 향상
print('Answer Offset: ', result['answer_offset']) # (410, 446)KoGPT2
[각모델정리][QnA/kobart-QuestionGeneration]
7. MRC model
