http://localhost:8888/lab/tree/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%209.21(3).ipynb
[ 20일 복습 문제 풀이 ]
-
- 그래프 그릴 떄 사용하는 함수
:seaborn
- 그래프 그릴 떄 사용하는 함수
-
- describe() ???
-
- 빈도수 그래프 sns 함수는?
:countplot
- 빈도수 그래프 sns 함수는?
-
- valuue-counts 한 개의 칼럼에만 적용된다.
: x 한줄에 대해서 나온다.
- valuue-counts 한 개의 칼럼에만 적용된다.
-
- immuteable mutable 타입으로 각각 분류하시오.
[ dict, int ,float ,list ,str ,tuple ]
immutable : int, float, str, tuple
mutable : dict, list
- pasndas 를 이용하여 데이터프레임 만들기
import pandas as pd
df=pd.DataFrame({'v1' : [1, 2, 1],'v2' : [5, 3, 2]})
df

- 대문자로 칼럼 이름 바꾸기
(1)
df=pd.DataFrame({'V1' : [1, 2, 1],'V2' : [5, 3, 2]})
df
(2)
df.rename({'v1': 'V1', 'v2': 'V2'}, axis = 1)

- 종강일이 23.2.24 datetime 이용하여 남은 일수 구하기.
(1)
import datetime
datetime.datetime(2023, 2, 24) - datetime.datetime.now()
(2)
today = datetime.datetime.now()
end = datetime.datetime(2023, 2, 24)
end - today
(3)
from datetime import datetime
today = datetime.now()
last_day = datetime(2023, 2, 24)
last_day - today
-> datetime.timedelta(days=155, seconds=52692, microseconds=707010)
- 데이터 만들기
(1)
df=pd.DataFrame({'a' : [1, 2, 3],'b' : [4,5,6]})
df
(2)
pd.DataFrame([[1,4],[2,5],[3,6]],columns=['a','b'])

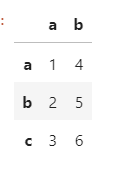
(3)인덱스 글자도 가능하다.
pd.DataFrame([[1,4],[2,5],[3,6]],index=['a','b','c'], columns=['a','b'])
- (1)
df.rename({'a' : 'A', 'b' : 'B'}, axis = 1)
- (1)
(2)
df.rename(columns={'a' : 'A', 'b' : 'B'}, inplace = True)
df

- 합의 열을 만드세요
df['합'] = df['A'] + df['B']
df

- lterable 설명에 틀린것은? -> 2

- 다음은 무슨 설명인가? -> 덕 타이핑 (duck typing)

-
- 데이터 프레임의 구도를 알아보기 위해 사용하는 함수는?
: df. info()
- 데이터 프레임의 구도를 알아보기 위해 사용하는 함수는?
-
- 다음 답은? -> 4

- df로 읽어달라.
df = pd.read_excel("excel_exam.xlsx")
df
-
- 세과목의 합의 평균 만들기.
df['평균']=(df['math']+df['english']+df['science'])/3
df
- 세과목의 합의 평균 만들기.
-
- 히스토그램으로 보여주어라.
import seaborn as sns
- 히스토그램으로 보여주어라.
(1)
df['평균'].hist()

#(2)
df['평균'].plot(kind = 'hist')
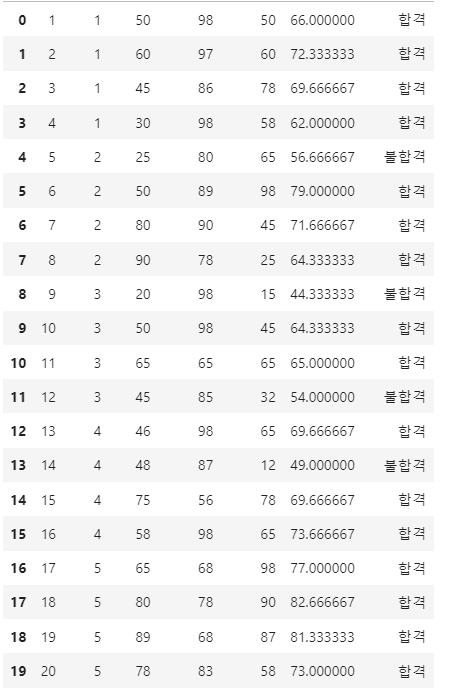
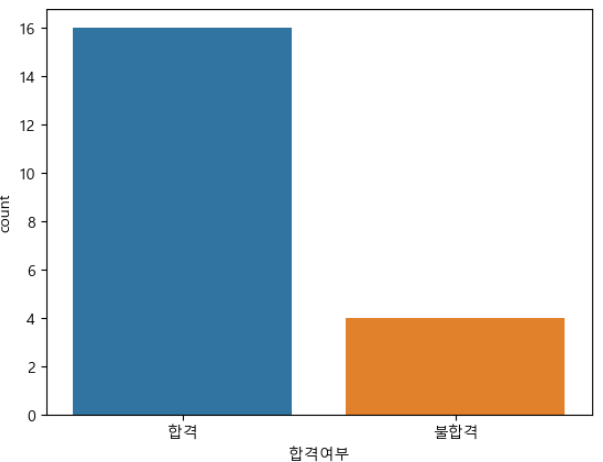
- "합격여부 "라는 열을 만들어 ,평균이 60넘으면 합격, 나머지 불합격 부여하고, countplot 을 그려주세요.
df['합격여부']=np.where(df['평균'] >= 60, '합격', '불합격')
df
import seaborn as sns
sns.countplot(data = df, x="합격여부")
☆한글 글꼴 만들어주기☆
import matplotlib.pyplot as plt
plt.rcParams['font.family']='Malgun Gothic'
[ 06.자유자재로 데이터 가공하기 {p131, 111}]
(1)데이터 전처리 - 원하는 형태로 가공하기(추출하기)
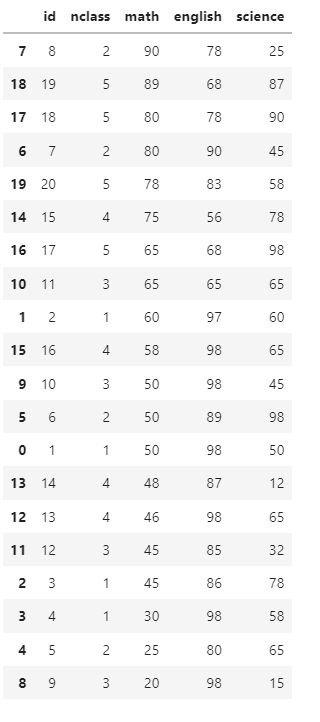
exam=pd.read_excel("excel_exam.xlsx")
exam
- class가 1인거 찾아주세요
exam[exam['class']==1]- class 가 1반이면서, math>= 50 인거 찾아라. ()묶어야함!
->(1),base
exam[(exam['class'] == 1) & (exam['math'] >= 50)]
- 조건을 변수로 만들어서 설정함. ()로 안해도 됨.
->(2),변수설정
cond1 = exam['class'] == 1
cond2 = exam['math'] >= 50
exam[cond1 & cond2]
(2)조건에 맞는 데이터만 추출 query메소드{77}
- exam.query메소드 ,
'':문자열 나타냄.
->(3),query 사용.
(1)'&'기호 사용
exam.query('math>=50 & english > 90')
(2)and글자 사용
exam.query('math>=50 and english > 90')
1반이면서 수학이 50점 이상. df.query() -> 오류가 나는 이유는? {84}
class가 예약어라서 그런 것 같다. (class-> nclass로 함)df = pd.read_excel("excel_exam.xlsx")
df.query('class==1 & math >= 50')
(3)변수 이용하여 행 추출하기 {p141, 164}
df= pd.DataFrame({'sex': ['F','M','F','M'],
'country': ['korea','china','japan','usa']})
df 
df.query('sex=="F"and country == "korea"')
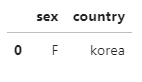
문자 변수를 이용해 조건에 맞는 행을 추출할 때는 query()에 전체 조건을 감싸는 따옴표와 추출할 문자를 감싸는 따옴표를 서로 다른 모양으로 입력해야 한다.
(4)정렬하기 sort {p150,122}
-
sort_values():오름차순 /
ascending= False:내림차순 -
sort_index()
-
수학열 기준으로
exam.sort_values(by = 'math'):내림차순
exam.sort_values(by = 'math', ascending= False):오름차순
- 여러줄 적용시 [] 사용 {p152}
- ascending= False: 내림차순
(5)파생변수 추가하기 {p154,128}
- 인덱스 기준으로 나온다.
df.sort_index()
새로운 칼럼 추가하기{156,131}
- df.assign()
exam.assign() : 새 변수명 = 변수를 만드는 공식
#total 이라는 math, english, science 합 만들기.
->
exam.assign(total1= exam['math']+exam['english']+exam['science'])
(6)집단별로 요약하기{p159,132}
- df.groupby()
- df.agg()
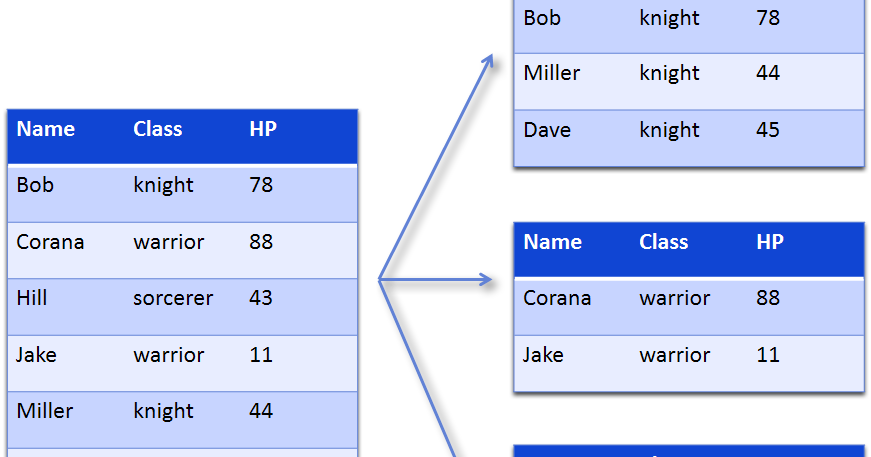
(1)
exam.groupby("nclass")
(2) nclass 그룹으로 모아줍니다.
list(exam.groupby("nclass"))
(3) 함수의 값들을 보여주내.
exam.groupby("nclass").min()
(4)
exam.groupby("nclass").min()[['math']]
집단별로 나누기 groupby() {p163,152}
groupby()에 여러 변수를 지정하면 집단을 나눈 다음 다시 하위 집단으로 나눌 수 있습니다.
예를 들어 성적 데이터를 반별로 나눈 다음 다시 성별로 나눠 각반의 성별 평균 점수를 구할 수있습니다.
-mpg 데이터 사용하기
pip install pydataset
import pydataset
mpg= pydataset.data('mpg')
mpg
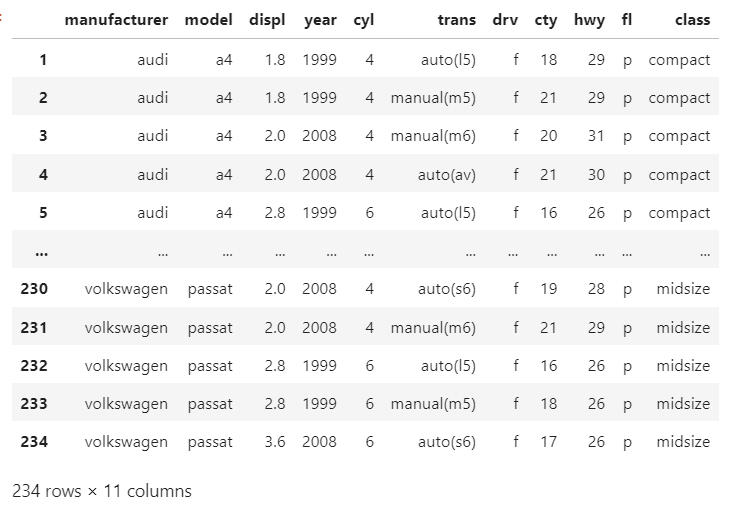
문제{154}
- drv와 class로 그룹을 짓고, 각 그룹 drv에 cty의 min() 구하기.
->
mpg.groupby(['drv', 'class']).min()['cty']

오후 수업 시작{173}
-
(1)
mpg.groupby(['drv',"class"]).min()[['cty']] -
(2)통상적으로 agg사용함.
mpg.groupby(['drv',"class"]).agg(min)[['cty']] -
(3)결과값 똑같음.
mpg.groupby(['drv',"class"]).apply(min)[['cty']]

문제{181}
-
각 칼럼별로 max, min 뽑아냄.
->
mpg.groupby(['drv',"class"]).agg([max,min]) -
cty의 max, min 뽑아냄.
->
mpg.groupby(['drv',"class"]).agg([max,min])[['cty']]
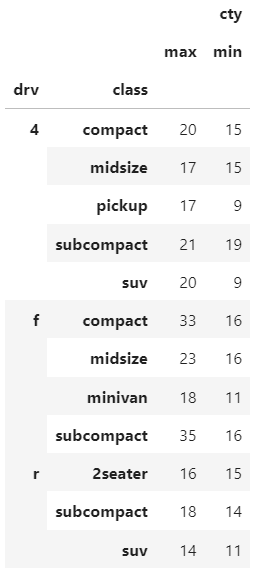
- 칼럼 마다 다른 함수를 적용시키고 싶을때 , ('cty':min,'hwy':max)
->
mpg.groupby(['drv',"class"]).agg({'cty':min,'hwy':max})
(7)데이터 합치기 {p167,192}
하나의 데이터만 가지고 분석하기도 하지만 여러 데이터를 합쳐 하나로 만든 다음 분석하기도 합니다.
- 가로로 합치기
- 세로로 합치기
< 합치기 함수 >
-
merge ★
-
concat ★
-
join
-
가로로 합치기
test1 = pd.DataFrame({'id':[1,2,3,4,5],
'midterm' : [60,80,70,90,85]})
test2 = pd.DataFrame({'id':[1,2,3,6,7],
'final': [70,83,65,95,80]})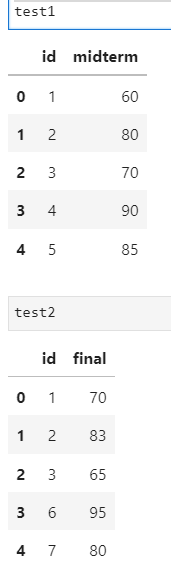
데이터를 가로로 합칠 때는
pd.merge()를 이용합니다.
1.pd.merge()에 결합할 데이터 프레임명을 나열합니다.
2. 오른쪽 입력한 데이터 프레임을 왼쪽 데이터 프레임에 결합 합니다.
how = 'left'를 입력합니다.
3. 데이터를 합칠 때 기준으로 삼을 변수명을on에 입력합니다.

문제{194}
- test1, test2의 공통된것만 나옴
->
pd.merge(test1,test2)
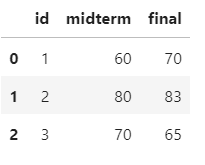
다른 변수 활용하여 변수 추가하기 {p169}
teacher = pd.DataFrame({'nclass':[1,2,3,4,5],
'teacher' : ["choi",'park','hong','kim','jeong']})
teacher
- merge(){p169,205}
pd.merge(exam, teacher)
->
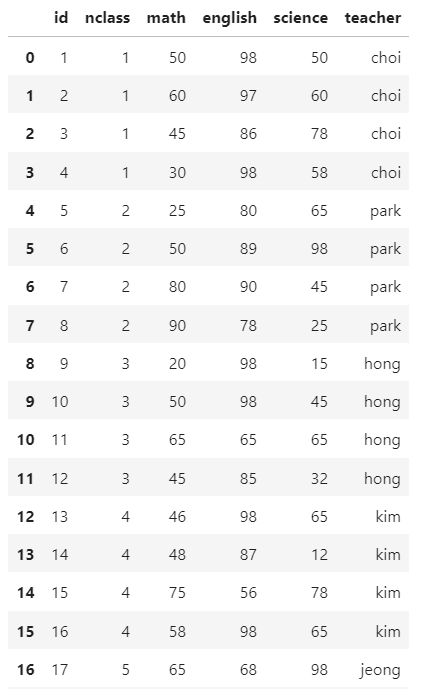
pd.merge()를 응용하면 특정 변수의 값을 기준으로 다른 데이터의 값을 추가할 수 있습니다.
- 세로로 합치기
test1 = pd.DataFrame({'id':[1,2,3,4,5],
'midterm' : [60,80,70,90,85]})
test2 = pd.DataFrame({'id':[1,2,3,6,7],
'final': [70,83,65,95,80]})문제{p170,206}
- test1, test2의 공통된것만 나옴
->
pd.concat(test1,test2)
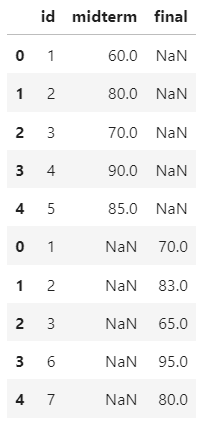
- concat()
데이터를 세로로 합칠 때는pd.concat()를 이용합니다.
pd.concat()에 결합할 데이터 프레임명을 []를 이용해 나열하면 된다.
데이터를 세로로 합칠 때는 두 데이터의 변수명이 같아야 한다.
id와 test로 같기 때문에 세로로 합칠 수 있었다.
변수명이 다르면 pd.rename으로 똑같이 맞춘 다음 합치면 된다.
문제 index {217}
- set_index()
- reset_index()
- reindex()
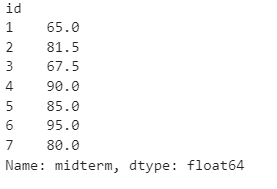
#id 별로 그룹바이해서 midterm의 평균?
-
(1)
pd.concat([test1, test3]).groupby('id')['midterm'].mean() -
(2)
group = pd.concat([test1, test3])
group.groupby('id').mean()['midterm'] -
(3)
group.groupby('id').agg(np.mean)['midterm']
http://localhost:8888/lab/tree/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B6%84%EC%84%9D%209.21(3).ipynb
[07.데이터 정제 ]
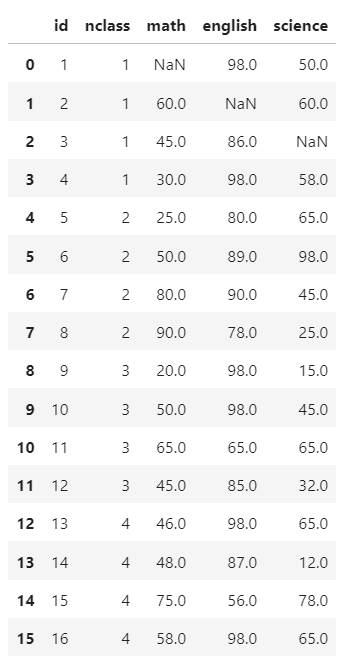
(1)결측치 만들기 {p178, 227}
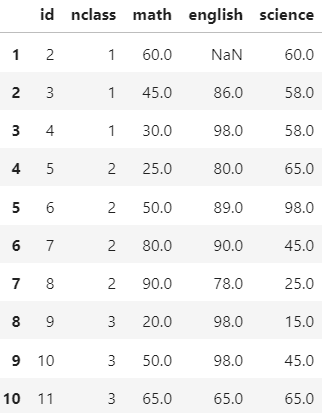
exam.iloc[0,2] =np.nan
exam.iloc[1,3]= np.nan
exam.iloc[2,4]= np.nan
exam
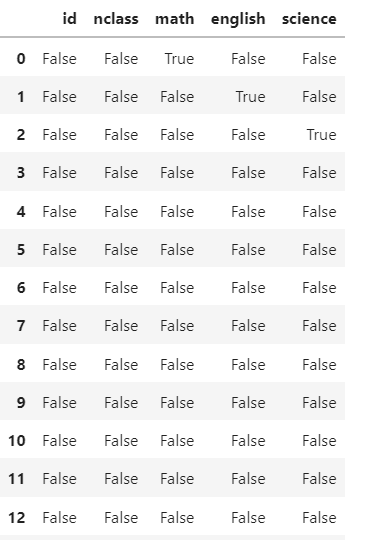
결측치 존재여부 pd.isna(df) {p179, 237}
df= exam.copy()
pd.isna(df)
pd.isna(df).sum()

pd.isna()를 이용하면 데이터를 결측치가 들어있는지 알 수있습니다.
pd.isna()에 df를 입력하면 결측치면 T, 결측치가 아니면 F로 데이터를 출력한다.
pd.isna()에 sum()을 적용하면 데이터의 결측치 총 갯수를출력할 수 있다.
결측치 제거하기 df.dropna() {p180, 244}
df.dropna()을 이용하면 결측치 있는 행을 제거할 수 있습니다.
subset 에 []를 이용하여 변수명을 입력하면 됩니다.
df.dropna(subset='math')
-> 수학값 결측치 제거 되었다.
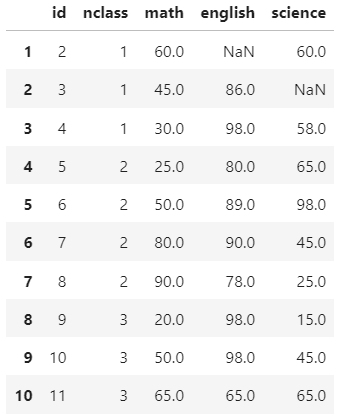
mean을 구하는 3가지 방법{251}
(1)
df['math'].mean()
(2)mean 불러오기
np.mean(df.math)
(3)apply로 사용하기
df.apply(np.mean)
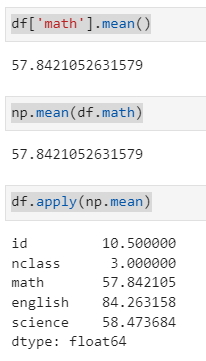
결측치 대체하기{p182, 255}
결측치를 제거하는 대신 다른 값을 채워 넣는 방법도 있는데, 이를 결측치 대처법이라고 합니다.
결측치를 다른 값으로 대체하며 데이터 손실되어 분석 결과가 왜곡되는 문제를 보완할 수 있습니 다.
m = df ['math'].mean()
m
->
57.8421052631579
df,fillna()를 이용하면 결측치를 다른 값으로 대처할 수 있습니다. 괄호 안에 결측치를 대처할 값을 입력하면 된다.
(1)
df['math']=df['math'].fillna(m)
df
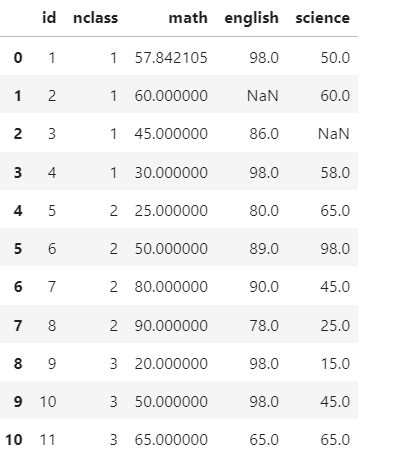
(2)method='bfill'
df['english'].fillna(method='bfill',inplace =True)
df
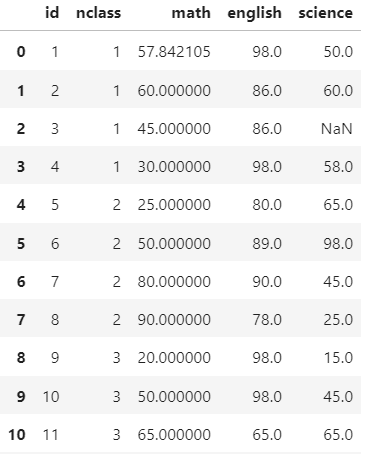
Backward fill method: 뒤로 채우기 방법
이 함수는 주어진 시리즈 객체에서 누락된 값을 채우는 데 사용됩니다.
(3)
df['science'].fillna(df['science'].mean(),inplace =True)
df

(2)이상치 찾기{p186, 270}
정상범위에서 크게 벗어난 값을 이상치 라고 하니다. 데이터 수집 과정에서 오류가 나올 수있기 때문에 이상치 제거하는 작업을 해야합니다.
- 이상치 만들기{315}
df .iloc[0,2]=10
df .iloc[1,3]=10
df
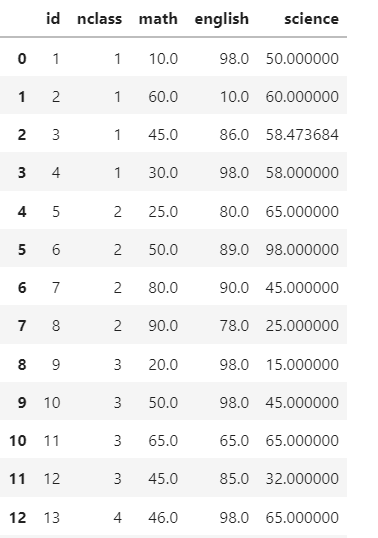
- 이상치 확인하기{p187,316}
df['math'].value_counts().sort_index()

df['english'].value_counts().sort_index()

-> 둘다 10이 있음을 확인했다.
- 결측 처리하기{p187, }
변수에 이상치가 들어 있다는 것을 확인했습니다. 이상치를 결측치로 바꾸겠습니다.
np.where()를 이용하여 이상치일 경우NAN을 부여하면 된다.
df['math']=np.where(df['math']==10, np.nan, df["math"])
df
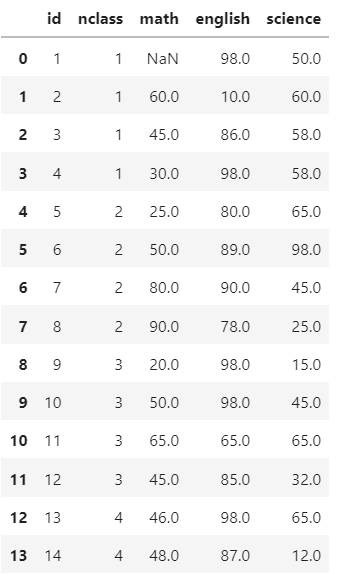
df['english']=np.where(df['english']==10, np.nan, df['english'])
df
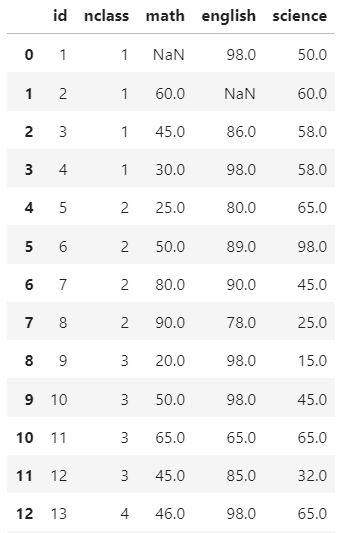
- 결측치 제거하기 df.dropna() {p188, 332}
df.dropna()
-> 결측치 값들 없어짐.
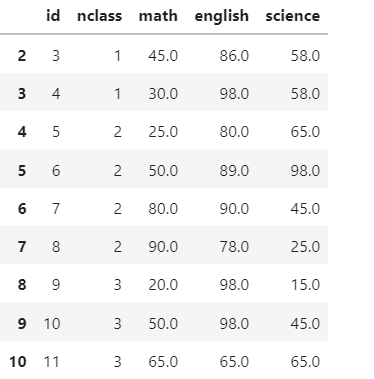
df.dropna(subset = "math")
->수학만 없어짐.
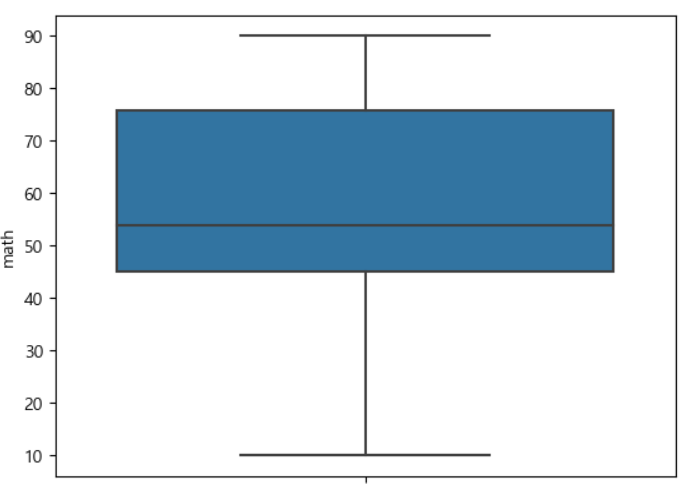
이상치 제거하기 {p191,273}
극단치란 논리적으로 존재할 수있는 극단적인 큰값, 작은값이다.
(1)상자 그림 살펴보기
mpg = pd. read_csv('mpg.csv')
import seaborn as sns
sns.boxplot(data= df, y= 'math')
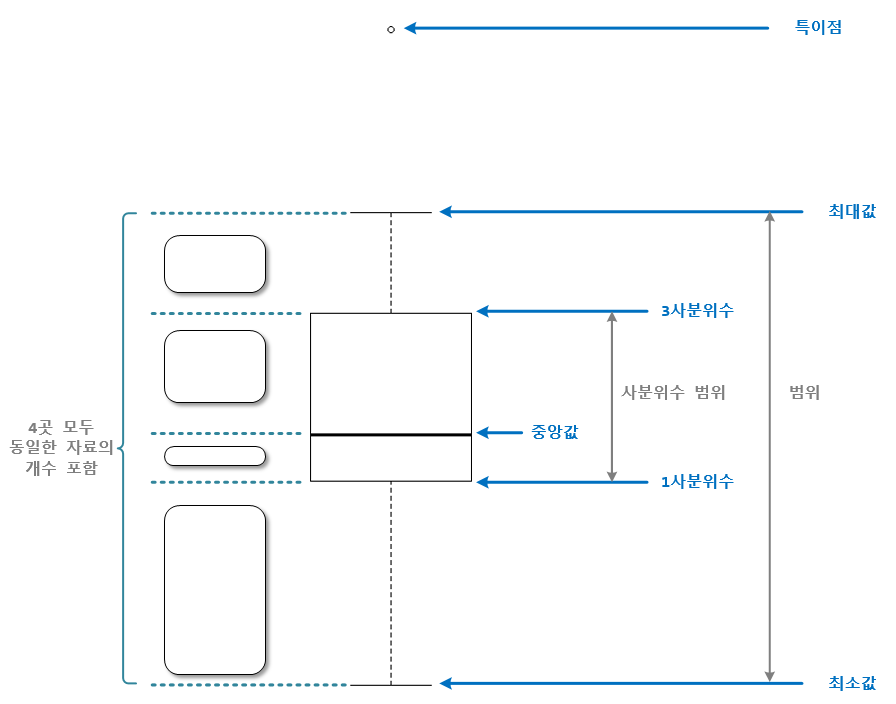
출처:
https://m.blog.naver.com/dbwjd516/222862042896 -> 데이터 가공 정리
