[ 9.21 문제 복습 ]
-
- 데이터를파악 할 때 사용하는 명령어 중에서 변수 속성을 출력하는 명령어는?
: df.info()
- 데이터를파악 할 때 사용하는 명령어 중에서 변수 속성을 출력하는 명령어는?
-
- 집단별로 그룹 지을때 사용하는 함수는?
groupby()
- 집단별로 그룹 지을때 사용하는 함수는?
-
- sort_ 다음에는?
sort_values() ,sort_index()
- sort_ 다음에는?
-
- mpg를 불러와서 manufacturer가 첫번째 열이 되도록 하시오.
(1)
import pydataset
pydataset.data('mpg')
(2)
mpg = pd.read_csv("https://raw.githubusercontent.com/sidsriv/Introduction-to-Data-Science-in-python/master/mpg.csv")
mpg = mpg.iloc[:, 1:]
mpg
- 순차적으로 진행하시오.
#(1) class의 그룹 만들기
mpg.groupby(['manufacturer', 'class'])
mpg
#(2.1) class의 그룹 만들고 hwy 칼럼 뽑아내기
mpg.groupby(['manufacturer','class']).mean()[['hwy']]
(2) class의 그룹 만들고 hwy 칼럼 뽑아내기
mpg.groupby(['manufacturer','class']).agg(mean_hwy=('hwy', 'mean'))
(3) class의 그룹 만들고 hwy 칼럼 뽑아내기
mpg.groupby(['manufacturer', 'class'])[['hwy']].mean()
- class 가 compact,midsize, suv 인 자동차?
import numpy as np
(1)
mpg[(mpg['nclass'] == 'compact') | (mpg['nclass'] == 'midsize') | (mpg['nclass'] == 'suv')]
mpg.head(10)
#(2)
df[(df['class'] == 'compact') ^ (df['class'] == 'suv') ^ (df['class'] == 'midsize')]
mpg.head(10)
#(3)
mpg = mpg.rename({'class' : 'nclass'},axis = 1)
mpg.query('nclass in ["compact","midsize","suv"]')
mpg. head(20)
[9.22.목 오전수업] {p191,2}
import pandas as pd
exam = pd.read_excel("excel_exam.xlsx")
exam
exam.rename ({"class":"nclass"}, axis =1, inplace = True)
exam.iloc[0,2] = 1
exam.iloc[1,3] = 1
exam.iloc[2,4] = 1
exam[:3]
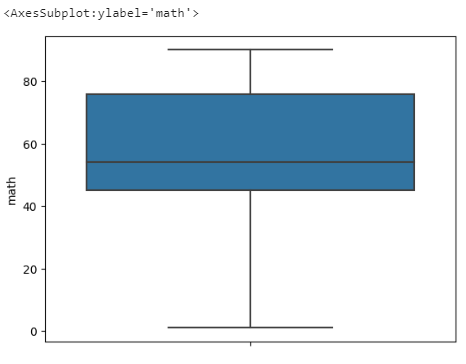
seaborn 패키지의 boxplot()을 이용하여 상자 그림 그린다.
import seaborn as sns
sns.boxplot(data = exam, y= 'math')
- 이상치를 숫자로 잡아주다.{p190}
- IQR : Inter Quartile Range , 1사분~ 3사분위
- 수염 : 1사분위(하한): - 1.5 * IQR ,
- 수염 : 3사분위(상한): + 1.5 * IQR
df.quantile()을 이용하면 분위수를 구할 수있다.
#3사분위 구하기
exam['math'].quantile(.75)
-> 75.75
#1사분위 구하기
exam['math'].quantile(.25)
-> 45.0
#이름 정해주기
pct75 = exam['math'].quantile(.75)
pct25 = exam['math'].quantile(.25)
[IQR 구하기] {p192}
IQR = pct75- pct25
IQR
#상한
pct75 + 1.5 * IQR
-> 121.875
$#하한
pct25 - 1.5 * IQR
-> -1.125
import pydataset
mpg=pydataset.data('mpg')
mpg=mpg.copy()
mpg = mpg.iloc[:,1:]
mpg
문제 cty의 수염의 극단치 값을 각각 얼마입니까?{40}
(1)
mpg.cty.describe()
print(14-7.5)
print(19+7.5)
->
6.5
26.5
(2)
pct75 = mpg['cty'].quantile(.75)
pct25 = mpg['cty'].quantile(.25)
IQR = pct75- pct25
print(pct75+1.5 IQR)
print(pct25-1.5 IQR)
->
26.5
6.5
[극단치를 결측처리하기} {p193}
문제 hwy가 40.5 이상 이거나, 4.5 이하인 것들만 골라주세요.{42}
(1)
cond1 = mpg.hwy >= 40.5
cond2 = mpg.hwy <= 4.5
mpg[cond1 | cond2]
(2)
mpg.query('hwy >= 40.5 | hwy <= 4.5')
문제 hwy의 이상치가 아닌것들의 평균을 구하시오.{49}
(1)
mpg.query('hwy < 40.5 | hwy > 4.5').mean()[['hwy']]
(2)
mpg.query("hwy < 40.5 | hwy > 4.5")['hwy'].mean()
->
23.44017094017094
(1) 그래프 만들기 {p196,50}
mpg
(2) 산점도{p199,51}
sns.scatterplot(data = mpg, x= 'displ',y='hwy', hue='drv')
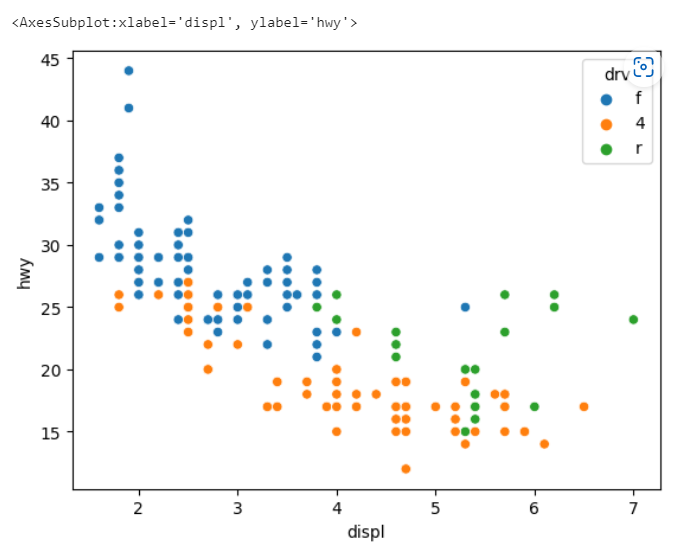
sns.scatterplot(data = mpg, x= 'displ',y='hwy', hue='drv').set(xlim=(3,6))
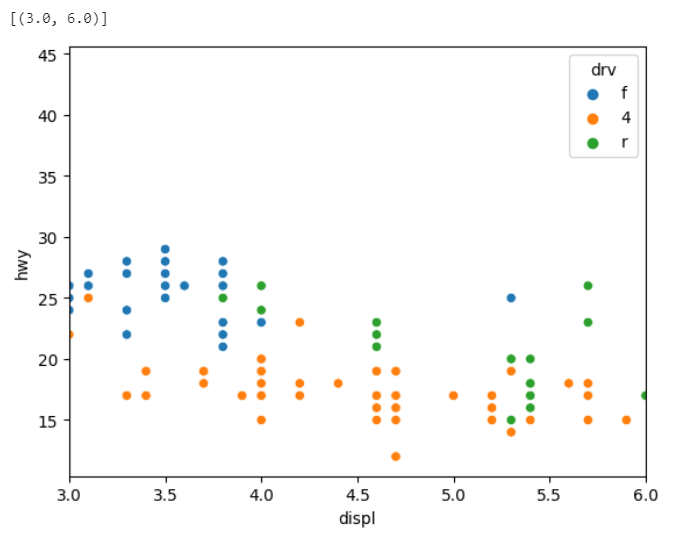
sns.scatterplot(data = mpg, x= 'displ',y='hwy', hue='drv')\
.set(xlim=(3,6), ylim=(10,30))
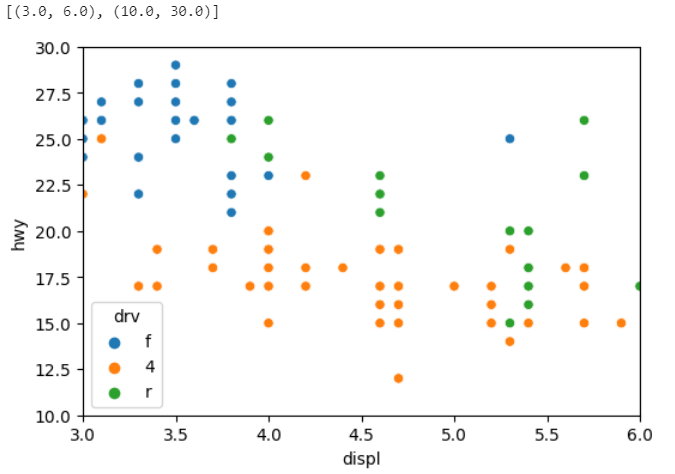
이미지 저장하는법
import matplotlib.pyplot as plt
plt.rcParams.update({'figure.figsize': [6,4]})
sns.scatterplot(data = mpg, x= 'displ',y='hwy', hue='drv').set(xlim=(3,6), ylim=(10,30))
plt.savefig('tesr.png',dpi =300)
(3) 막대그래프 {205,65}
sns.barplot(data = df_mpg, x= drv, y= hwy )
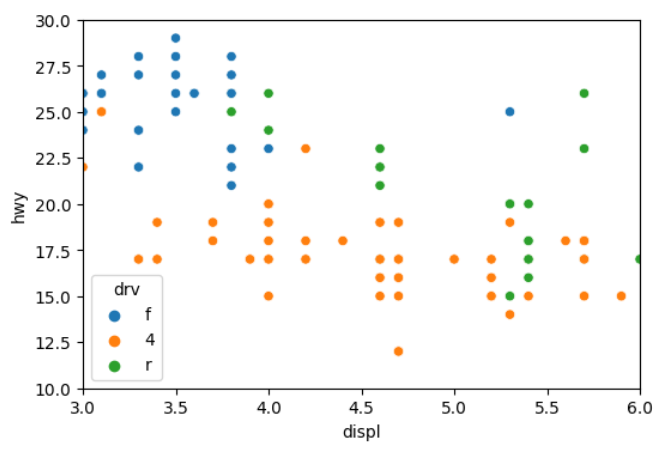
문제 drv 별로 hwy 주행연비의 평균을 구해봅시다. {71}
df_mpg = mpg.groupby("drv")[['hwy']].mean()
df_mpg

sns.barplot(data = df_mpg.reset_index() , x= 'drv' , y= 'hwy' )
인덱스를 칼럼으로 바꾸기{74}
df_mpg.reset_index()

gruoopby 로 만들때, 파라미터로 정하기{76}
df_mpg = mpg.groupby("drv", as_index = False )[['hwy']].mean()
df_mpg
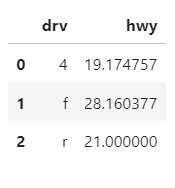
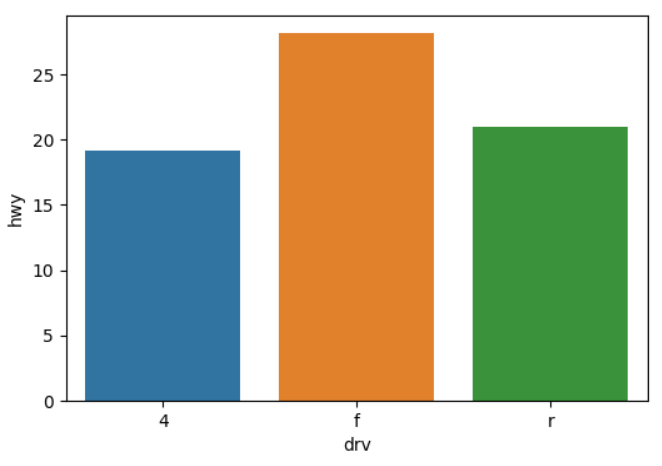
sns.barplot(data = df_mpg.reset_index() , x= 'drv' , y= 'hwy' )
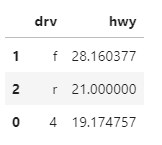
df_mpg =df_mpg.sort_values(by= 'hwy', ascending = False)
df_mpg
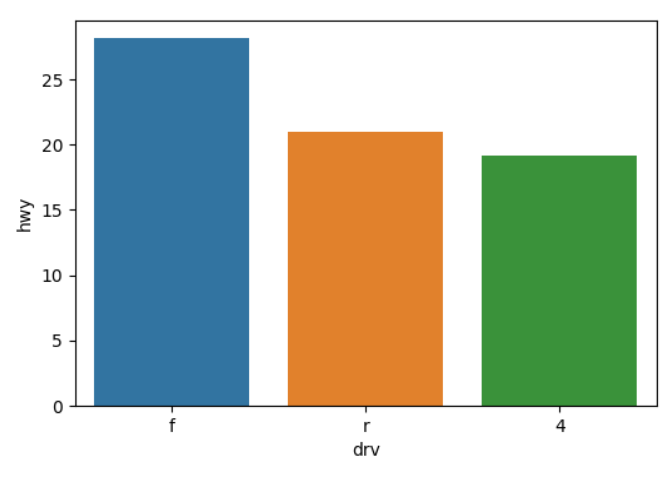
sns.barplot(data = df_mpg, x= 'drv' , y= 'hwy' )
(4) 선그래프 {p212, 88}
import pydataset
economics = pydataset.data('economics')
economics[:2]
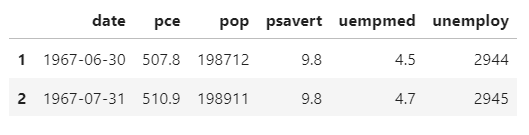
economics.info()
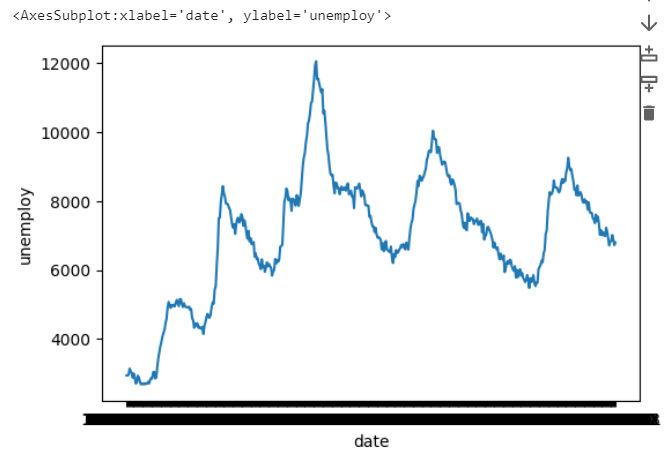
sns.lineplot(data= economics, x='date', y='unemploy' )
칼럼의 데이터 타입 바꾸기 astype(), to_datetype() {95}
economics['unemploy'] = economics['unemploy'].astype('float')
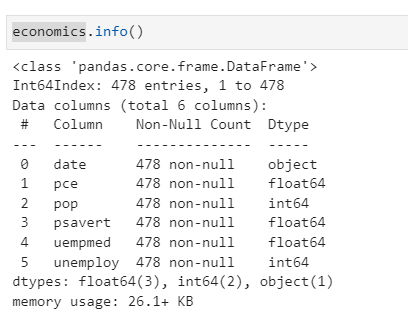
economics.info()
(1)
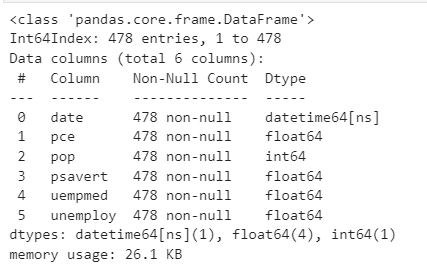
economics['date'] = economics['date'].astype('datetime64')★
economics.info()
sns.lineplot(data= economics, x='date', y='unemploy' )

(2)
economics['date'] = pd.to_datetime(economics['date'])
economics.info()
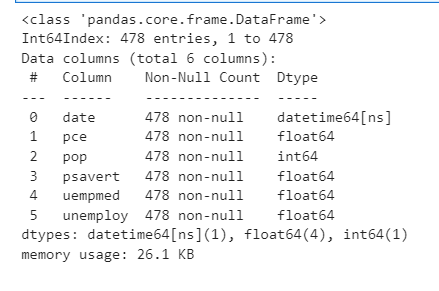
(5) 상자 그림 {p218, 105}
sns.boxplot(data = mpg , x= 'drv', y= 'hwy')
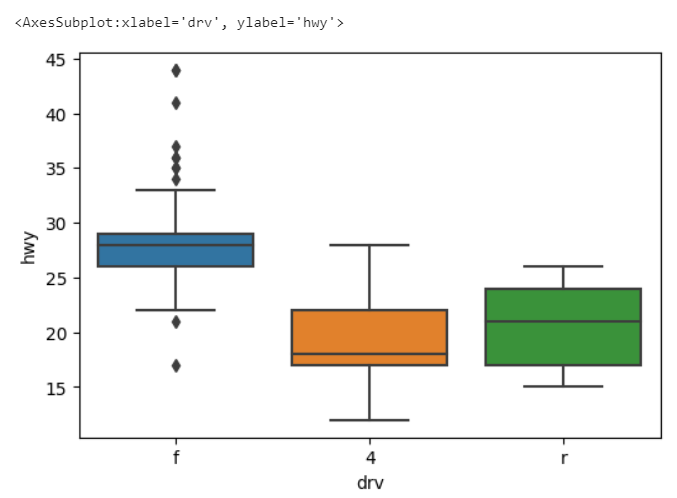
sns.boxplot(data = mpg , y= 'hwy')
데이터 분석 프로젝트 {p224, 116}
(1) 한국복지패널데이터{116}
raw_welfare =pd.read_spss("Koweps_hpwc14_2019_beta3.sav ")
raw_welfare
pip install pyreadstat
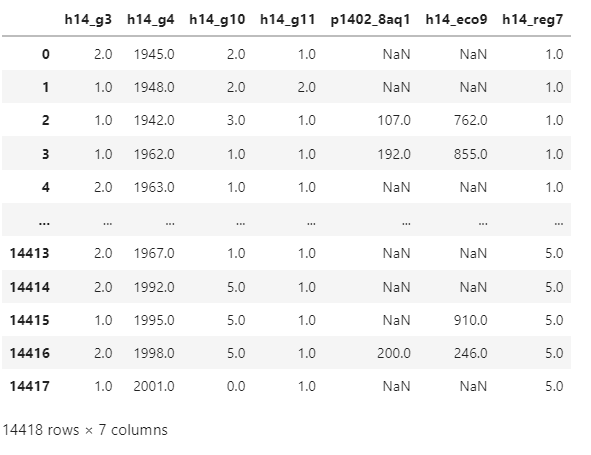
welrfare= raw_welfare.loc[:,['h14_g3','h14_g4','h14_g10','h14_g11','p1402_8aq1','h14_eco9','h14_reg7']]
welrfare
(2) 성별의 따른 월급차이 {p229,185}
#성별과 월급의 평균 구하기
welfare.groupby('sex')[['income']].mean()

#칼럼으로 성별 만들어주기
df=welfare.groupby('sex',as_index= False)[['income']].mean()
df
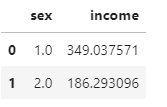
#1:남자2.여자 바꿔주어라
import numpy as np
welfare['sex'] = np.where(welfare['sex'] == 1.0, 'male', 'female')
welfare[:4]
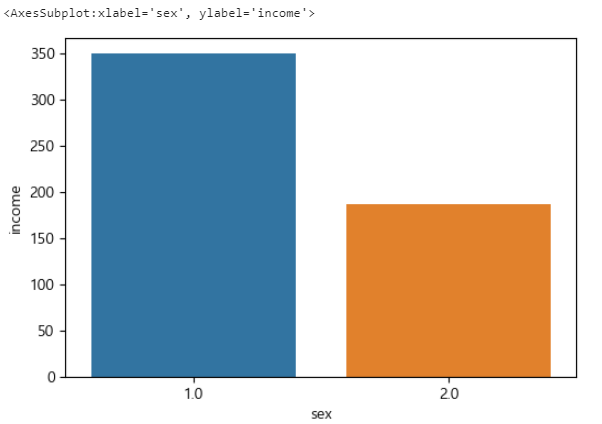
#박스그래프로 만들어주어라.
sns.barplot(data=df, x='sex', y='income')
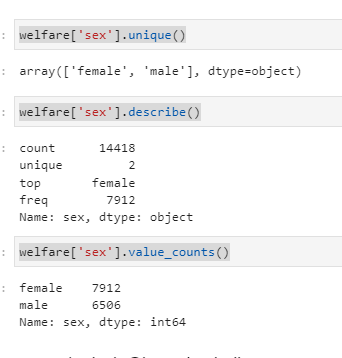
welfare['sex'].unique()
welfare['sex'].value_counts()
welfare['sex'].describe()
(3) 나이와 월급의 관계{p235, 191}
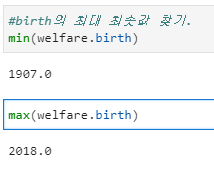
#birth의 최대 최솟값 찾기.
min(welfare.birth)
max(welfare.birth)
#age열 만들어 주세요. 2018년생 1살, 2017년 2살
welfare['age']= 2019 - welfare['birth']
welfare[:2]

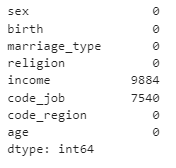
welfare.isna().sum()
#age열의 타입을 정수로 바꿔주세요.
welfare['age']= welfare['age'].astype('int')
welfare[['age']]

#나이별로 소득 평균 구해 주세요.
welfare.groupby(['age']).mean()[['income']]
df=welfare.groupby('age').agg('mean')[['income']]
df[:2]

df = df.reset_index()
df
선그래프 그리기 {p239}
sns.lineplot(data=df, x= 'age', y= 'income')
(4) 연령대에 따른 월급의 차이 {p240, 215}
(5) 연령대 및 성별 월급 차이 {p244, 241}
다양한 데이터 분석의 세계{p276}
텍스트 마이닝{p278}
워드 클라우드 만들기
