[ 8장 정리 ]
8.1 합성곱 신경망 소개 p283
컨브넷 정의와 컨브넷이 컴퓨터 비전 관련 작업에 잘 맞는 이유에 대해 이론적 배경을 알아봅시다. 하지만 먼저 간단한 커브넷 예제를 둘러보죠. 2장에서 밀집 연결 신경망으로 풀었던 mnist 숫자 이미지 분류에 컨브넷을 사용해 보겠습니다. 기본적인 컨브넷이더라도 2장에서 다룬 완전 연결된 모델의 성능을 훨씬 앞지를 것입니다.
코드 8-1)은 기본적인 컨브넷 모습입니다. Conv2D MaxPooling2D 층을 쌓아 올렸습니다.
잠시 후에 이들이 무엇인지 알아보겠습니다. 이전 장에서 소개한 함수형 API를 사용해서 모델을 만들겠습니다.
# 8-1) 간단한 컨브넷 만들기
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x)
x = layers.Flatten()(x) # 클래스다다
outputs = layers.Dense(10, activation="softmax")(x)
model = keras.Model(inputs=inputs, outputs=outputs)CNN > DNN
컨브넷이 배치 차원을 제외하고(높이,넓이,채널) 크기의 입력 텐서를 사용한다는 점이 중요합니다. 이 예제에서는 MNIST 이미지 포맷인 (28,28,1)크기의 입력을 처리하도록 컨브넷을 설정해야 합니다.
이 컨브넷의 구조를 출력해 보조.
# 8-2) 모델의 summary() 메서드 출력
model.summary()Conv2D MaxPooling2D 층의 출력 크기는 (3,3,128)입니다. 즉, 128개의 채널을 가진 3x3 크기의 특성맵입니다. 다음 단계는 이 출력을 밀집 연결 분류기로 주입하는 것입니다. 이 분류기는 Dense 층을 쌓은 것으로 이미 익숙한 구조입니다. 이 분류기는 1D 백터를 처리하는데, 이전 층의 출력이 랭크-3 텐서입니다. 그래서 Dense 층 이정에 Flatten 층으로 먼저 3D 출력을 1D 텐서로 펄쳐야 합니다.
마지막으로 10개의 클래스르 분류하기 위해 마지막 층의 출력 크기를 10으로 하고 소프트맥스 활성화 함수를 사용합니다.
이제 MNIST 숫자 이미지에 이 컨브넷을 훈련합니다. 2장의 MNIST 예제 코드를 많이 재사용 하겠습니다. 소프트맥스 활성화 함수의 출력을 바탕으로 10개의 클래스를 분류하기 때문에 범주형 크로스엔트로피 손실을 사용하겠습니다. 레이블 정수이므로 희소한 크로스엔트로피 손실인 sparse_categorical_crossentropy를 사용하겠습니다.
# 8-3) MNIST 이미지에서 컨브넷 훈련하기
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype("float32") / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype("float32") / 255
model.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
model.fit(train_images, train_labels, epochs=5, batch_size=64)3차원 -> 4차원
테스트 데이터에서 모델을 평가해 보죠.
# 8-4) 컨브넷 평가하기
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"테스트 정확도: {test_acc:.3f}")2장의 완전 연결 네트워크는 97.8%의 테스트 정확도를 얻은 반면 기본적인 컨브넷은 99.1%의 테스트 정확도를 얻었습니다. 에러율리 (상대적으로) 60%나 줄었다.
완전 연결된 모델보다 왜 간단한 컨브넷이 더 잘 작동할까? 이에 대해 알아보기 위해 Conv2D MaxPooling2D층이 어떤 일을 하는지 살펴보겠다.
8.1.1 합성곱 연산
완전 연결 층과 합성곱 층 사이의 근본적인 차이는 다음과 가다. Dense층은 입력 특성 공간에 있는 전역 패턴(예를 들어 MNIST 숫자 이미지에서는 모든 픽셀에 걸친 패턴)을 학습하지만 합성곱 층은 지역 패턴을 학습합니다. 이미지일 경우 작은 2D 윈도우로 입력에서 패턴을 찾습니다. 앞의 예에서 이 윈도우는 모두 3X3 크기였습니다.
이 핵심 특징은 컨브넷에 두가지 흥미로운 성질을 제공합니다.
-
학습된 패턴은 평행 이동 불변성을 가집니다. 컨브넷이 이미지를 효율적으로 처리하게 만든다. (근본적으로 우리가 보는 세상은 평행 이동으로 인해 다르게 인식되지 않습니다.) 적은 수의 훈련 샘플을 사용해서 일반화 능력을 가진 표현을 학습 할 수 있습니다.
-
컨브넷은 패턴의 공간적 계층 구조를 학습할 수 있습니다. 컨브넷은 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있습니다. 근본적으로 우리가 보는 세상은 공간적 계층 구조를 가지고 있기 떄문입니다.
합성곱 연산은 특성 맵이라고 부르는 랸크-3 텐서에 적용됩니다. 이 텐서는 2개의 공간 축(높이와 너비)과 깊이 축(채널 축이라고도 합니다.)으로 구성됩니다.RGB 이미지는 3개의 컬러 채널을 가지므로 깊이 축의 차원이 3이 됩니다. MNIST 숫자처럼 흑백 이미지는 깊이 축의 차원이 1입니다. 합성곱 연산은 입력 특성 맵에서 작은 패치들을 추출하고 이런 모든 패치에 같은 변환을 적용하여 출력 특성 맵을 만듭니다.
출력 특성 맵도 높이와 너비를 가진 랭크-3텐서입니다.출력 텐서의 깊이는 층의 매개변수로 결정되기 때문에 상황에 따라 다릅니다. 이렇게 되면 깊이 축의 채널은 더 이상 RGB 입력처럼 특정 컬러를 의미하지 않습니다. 그 대신 일종의 필터를 의미합니다. 필터는 입력 데이터의 어떤 특성을 인코딩합니다. 예를 들어 고수준으로 보면 하나의 필터가 '입력에 얼굴이 있는지'를 인코딩 할 수 있습니다.
MNIST 예제에서는 첫 번째 합성곱 층이 (28,28,1) 크기의 특성 맵을 입력 받아 (26,26,32)크기의 특성 맵을 출력합니다. 즉 입력에 대해 32개의 필터를 적용합니다. 32개의 출력 채널 각각은 26X26 크기의 배열 값을 가집니다. 이 값은 입력에 대한 필터의 응답 맵입니다. 입력의 각 위치에서 필터 패턴에 대한 응답을 나타냅니다.
특성 맵이라는 말이 의미하는 것은 다음과 같습니다. 깊이 축에 있는 각 차원은 하나의 특성(또는 필터)이고, 랭크-2 텐서는 입력에 대한 이 필터 응답을나타내는 2D 공간상의 맵입니다.
합성곱은 핵심적인 2개의 파라미터로 정의됩니다.
- 입력으로부터 뽑아낼 피치의 크기 : 전형적으로 33또는 55 크기를 사용합니다. 이 예에서는 일반적으로 많이 사용하는 3*3크기를 사용했습니다.
- 특성 맵의 출력 깊이 : 합성곱으로 계산할 필터 개수입니다. 이 예에서는 깊이 32로 시작해서 깊이 128로 끝났습니다.
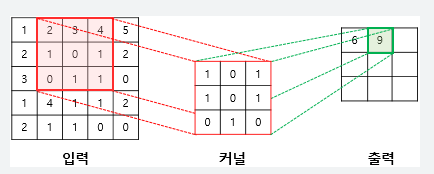
3D 입력 특성 맵 위를 33 또는 55 크기의 윈도우가 슬라이딩 하면서 모든 위치에서 3D 특성 패치를 추출하는 방식으로 합성곱이 작동합니다. 이런 3D 패치는 합성곱 커널 이라고 불리는 하나의 학습된 가중치 행렬과의 텐서 곱셈을 통해 크기의 1D 벡터로 변환됩니다. 동일한 커널이 모든 패치에 걸쳐서 재사용됩니다. 출력 특성 맵의 공간상 위치는 입력 특성 맵의 같은 위치에 대응됩니다.
두 가지 이유로 출력 높이와 너비는 입력의 높이,너비와 다를 수 있습니다.
- 경제 문제, 입력 특성 맵에 패딩을 추가하여 대응할 수 있습니다.
- 잠시 후에 설명할 스트라이드의 사용 여부에 따라 다릅니다.
이 개념을 좀 더 자세히 알아봅시다.
경제 문제와 패딩 이해하기
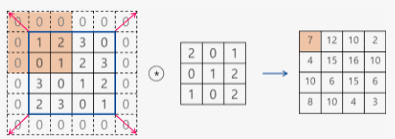
55 크기의 특성 맵을 생각해 보겠습니다(총 25개의 타일이 있다고 생각합니다.) 33 크기인 윈도우의 중앙을 맞출 수 있는 타일은 33 격자를 형성하는 9개 뿐입니다.따라서 특성 맵은 33 크기가 됩니다. 크기가 조금 줄어들었습니다. 여기에서는 높이와 너비 차원을 따라 정확히 2개의 타일이 줄어들었습니다. 앞선 예에도 이런 경계 문제를 볼 수 있습니다. 첫번째 합성곱 층에서 2828 크기의 입력이 2626 크기가 되었습니다.
입력과 동일한 높이와 너비를 가진 출력 특성 맵을 얻고 싶다면 패딩을 사용할 수 있습니다. 패딩은 입력 특성 맵의 가장자리에 적절한 개수의 행과 열을 추가합니다. 그래서 모든 입력타일에 합성곱 윈도우 중앙을 위치시킬 수 있습니다. 3*3 윈도우라면 위아래에 하나의 행을 추가하고 오른쪽, 왼쪽에 하나의 열을 추가합니다. 윈도우라면 2개의 행과 열을 추가합니다.
Conv2D 층에서 padding 매개변수로 설정할 수 있습니다. 2개의 값이 가능합니다.'valid'는 패딩을 사용하지 않는다는 뜻입니다. (윈도우를 놓을 수 있는 위치만 사용합니다.) "same"은 입력과 동일한 높이와 너비를 가진 출력을 만들기 위해 패딩한다.라는 뜻입니다. padding 매개변수의 기본값은 "valid"입니다.
