#설치하기
package1 <- c("ggplot2", "Rcpp", "dplyr", "ggthemes", "ggmap", "devtools", "RCurl", "igraph", "rgl", "lavaan", "semPlot")
package2 <- c("twitteR", "XML", "plyr", "doBy", "RJSONIO", "tm", "RWeka", "base64enc")
list.of.packages <- c( package1, package2)
new.packages <- list.of.packages[!(list.of.packages %in% installed.packages()[,"Package"])]
if(length(new.packages)) install.packages(new.packages)
library(plyr)
library(stringr)
삼성 & 아이폰
#아이폰
load("iphone_tweets.rda")
library(twitteR)
it <- twListToDF(iphone_tweets)
head(it,2)
names(it)
it_text <- it$text
it_text
it_gsub <- gsub("[^가-힣]"," ",it_text)
it_gsub
it_df <- as.data.frame(it_gsub)
pos.word <- scan("positive-words-ko-v2.txt", what ="character", comment.char = ";")
neg.word <- scan("negative-words-ko-v2.txt", what ="character", comment.char = ";")
score.sentiment = function(sentences, pos.words, neg.words, .progress='none')
{
scores = laply(sentences, function(sentence, pos.words, neg.words) {
word.list = str_split(sentence, '\s+');
words = unlist(word.list);
pos.matches = match(words, pos.words);
neg.matches = match(words, neg.words);
pos.matches = !is.na(pos.matches);
neg.matches = !is.na(neg.matches);
score = sum(pos.matches) - sum(neg.matches);
return(score);
}, pos.words, neg.words, .progress=.progress);
scores.df = data.frame(score=scores, text=sentences);
return(scores.df);
}
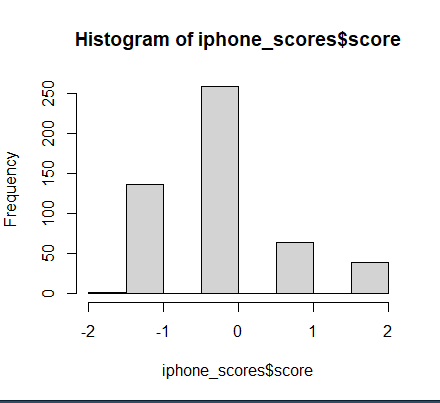
iphone_scores <- score.sentiment(it_gsub, pos.word , neg.word, .progress = 'text')
head(iphone_scores,2)
hist(iphone_scores$score)
b <- dim(iphone_scores)[1]
#갤럭시
library(twitteR)
load("gal_tweets.rda")
gt <- twListToDF(gal_tweets)
head(gt,2)
names(gt)
gt_text <- gt$text
gt_text
gt_gsub <- gsub("[^가-힣]"," ",gt_text)
gt_gsub
gt_df <- as.data.frame(gt_gsub)
pos.word <- scan("positive-words-ko-v2.txt", what ="character", comment.char = ";")
neg.word <- scan("negative-words-ko-v2.txt", what ="character", comment.char = ";")
score.sentiment = function(sentences, pos.words, neg.words, .progress='none')
{
scores = laply(sentences, function(sentence, pos.words, neg.words) {
word.list = str_split(sentence, '\s+');
words = unlist(word.list);
pos.matches = match(words, pos.words);
neg.matches = match(words, neg.words);
pos.matches = !is.na(pos.matches);
neg.matches = !is.na(neg.matches);
score = sum(pos.matches) - sum(neg.matches);
return(score);
}, pos.words, neg.words, .progress=.progress);
scores.df = data.frame(score=scores, text=sentences);
return(scores.df);
}
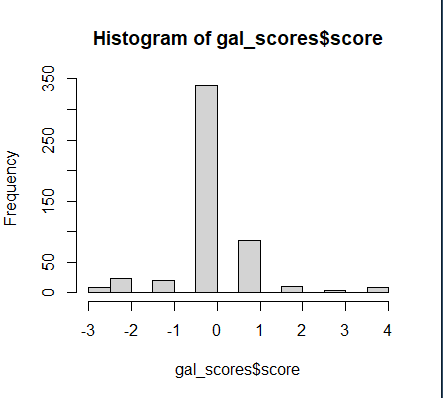
gal_scores <- score.sentiment(gt_gsub, pos.word , neg.word, .progress = 'text')
head(gal_scores,2)
hist(gal_scores$score)
a <- dim(gal_scores)[1]
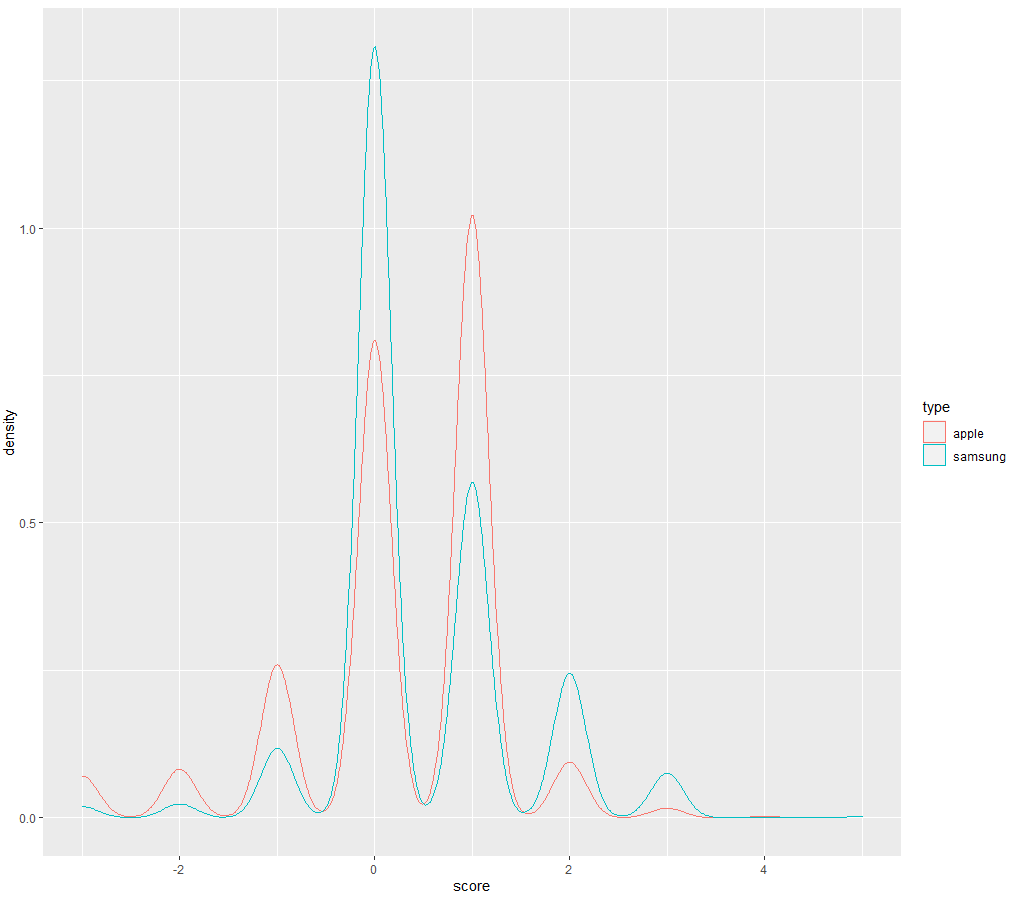
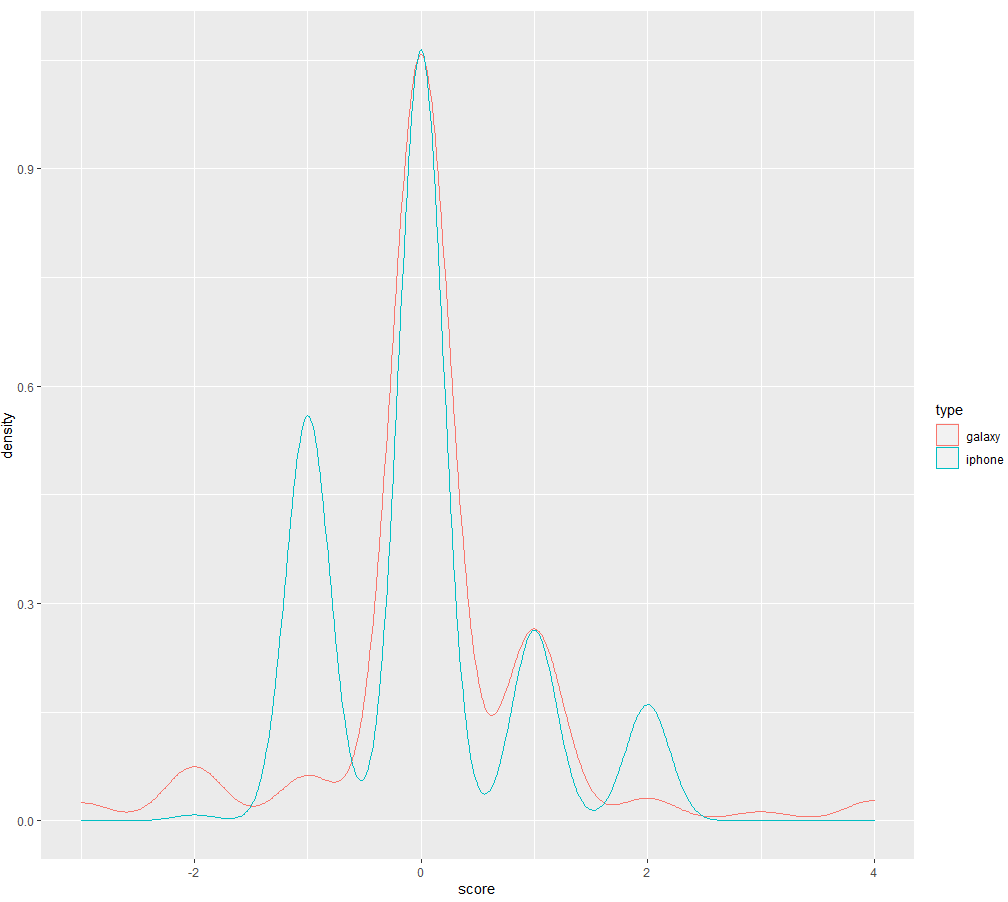
alls <- rbind(as.data.frame(cbind(type=rep("galaxy",a),score=gal_scores[,1])),as.data.frame(cbind(type=rep("iphone",b),score=iphone_scores[,1])))
allstype)
allsscore)
ggplot(alls ,aes(x=score,colour=type))+geom_density()
#아이폰
library(KoNLP)
load("iphone_tweets.rda")
it <- twListToDF(iphone_tweets)
head(it,2)
names(it)
it_text <- it$text
it_text
it_gsub <- gsub("[^가-힣]"," ",it_text)
it_gsub
it_df <- as.data.frame(it_gsub)
it_df <- unlist(it_df)
nouns <- extractNoun(it_df )
nouns
useNIADic()
#useSejongDic()
#nchar(nouns)
nouns <- nouns[nchar(nouns)>1]
nouns <- unlist(nouns)
table(nouns)
#데이터 프라임으로 바꿔줌
as.data.frame(table(nouns))
#정렬함
df_i <- as.data.frame (table(nouns))|> arrange(desc(Freq))
df_i
#ggplot사용
#ggplot(data = df,aes(x=nouns, y=Freq,fill=nouns))+geom_col()
#coord_flip(): 방향바꿔줌
#ggplot(data=df,aes(x=nouns, y=Freq,fill=nouns() +geom_col()+coord_flip()
#값 지정
df_i <- as.data.frame(table(nouns)) |> arrange(desc(Freq)) |> head(50)
df_i <- as.data.frame(table(nouns)) |> arrange(desc(Freq))
df_i
#wordcloud2: 불러오기
#install.packages("wordcloud2")
#library(wordcloud2)
wordcloud2(df_i)

#갤럭시
library(KoNLP)
load("gal_tweets.rda")
gt <- twListToDF(gal_tweets)
head(gt,2)
names(gt)
gt_text <- gt$text
gt_text
gt_gsub <- gsub("[^가-힣]"," ",gt_text)
gt_gsub
gt_df <- as.data.frame(gt_gsub)
gt_df <- unlist(gt_df)
nouns_g <- extractNoun(gt_df )
nouns_g
useNIADic()
#useSejongDic()
#nchar(nouns)
nouns_g <- nouns_g[nchar(nouns_g)>1]
nouns_g <- unlist(nouns_g)
table(nouns_g)
#데이터 프라임으로 바꿔줌
as.data.frame(table(nouns_g))
#정렬함
df_g <- as.data.frame (table(nouns_g))|> arrange(desc(Freq))
df_g
#ggplot사용
#ggplot(data = df,aes(x=nouns, y=Freq,fill=nouns))+geom_col()
#coord_flip(): 방향바꿔줌
#ggplot(data=df,aes(x=nouns, y=Freq,fill=nouns() +geom_col()+coord_flip()
#값 지정
#df_g <- as.data.frame(table(nouns_g)) |> arrange(desc(Freq)) |> head(50)
df_g <- as.data.frame(table(nouns_g)) |> arrange(desc(Freq))
df_g
#wordcloud2: 불러오기
#install.packages("wordcloud2")
#library(wordcloud2)
wordcloud2(df_g)

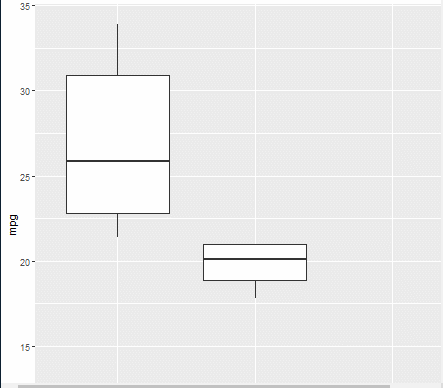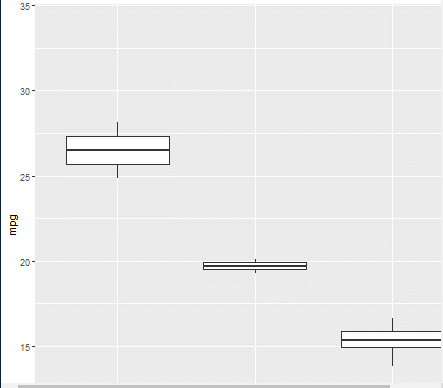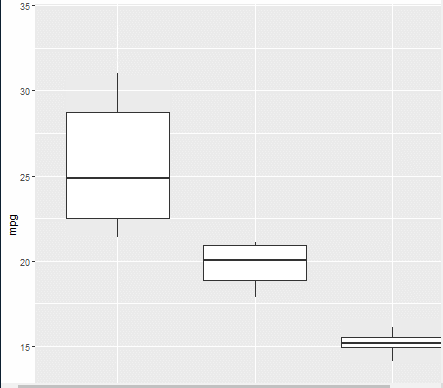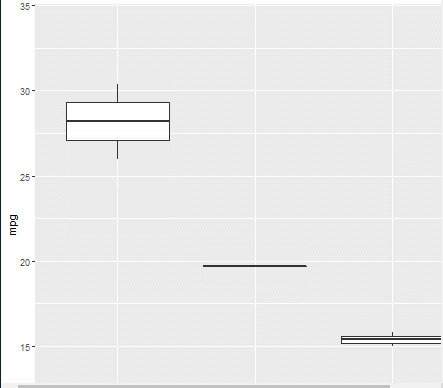
(8/31일 아침 애니메이터 효과 복습)
install.packages("gganimate")
library(ggplot2)
library(gganimate)
ggplot(mtcars, aes(factor(cyl), mpg)) + geom_boxplot() +
#Here comes the gganimate code
transition_states( gear, transition_length = 2, state_length = 1 ) +
enter_fade() + exit_shrink() + ease_aes('sine-in-out')