1. DatePrepper Overview

-
Data Prepper는 오픈소스 Server Side Data Collector임.
-
Raw log 수집에서부터 interactive ad-hoc analyses까지 end-to end lifecycle 분석을 목표로 하고 있음.
-
Star수를 보았을때 Opensearch에서 초기단계의 프로젝트이다. (2021년 6월 Launch)

-
Opensearch Project에서 개발했음 (Apache 2 license)
OpenSearch (https://opensearch.org/)
Copyright OpenSearch Contributors
This product includes software developed by
Elasticsearch (http://www.elastic.co).
Copyright 2009-2018 Elasticsearch
This product includes software developed by The Apache Software
Foundation (http://www.apache.org/).
This product includes software developed by
Joda.org (http://www.joda.org/). -
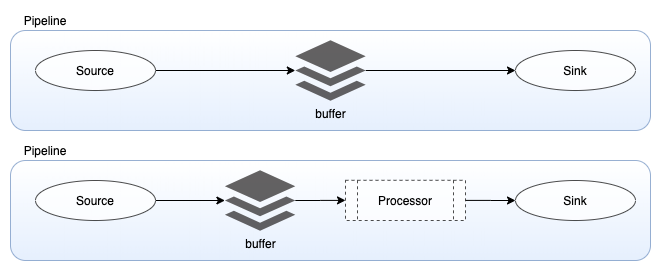
Source, Buffer, Sink, Processor 4개의 핵심요소로 나누어져 있음.
2. Components
- Source : input component로 Data prepper Pipeline의 메커니즘을 정의
- http/s로 수신하거나 Kafka, SQS, Cloudwatch와 같은 External endpoint에서 자료를 읽어들일 수 있음.
- string/json/cloudwatch logs/open telemetry trace와 같은 자체 Configuration을 가짐
- 이런 record를 바탕으로 Buffer 쪽으로 기록
- Buffer : Source와 Sink 사이의 Layer
- Memory 나 Disk 기반
- Default는 Bounded Blocking Queue 기반
- Bounded Blocking Queue란 ? (BBQ)
- Queue에 자리가 없으면 새로운 항목 호출 차단, Queue에 항목이 없으면 Queue에서 빼내는 호출을 차단.
- Sink : Pipeline의 Output component
- 최종목적지는 Opensearch나 S3와 같은 저장소가 된다.
- Security나 Request batch와 같은 목적성을 기반으로 자체 Config를 가질 수 있다.
- Processor : 사용자가 Sink에 게시하기 전에 원하는 형식으로 레코드를 필터링, 변환 및 정제할 수 있는 중간 처리 장치 (위의 그림과 같이 Buffer와 Sink 사이에 위치함)
3. Config 훑어보기
3-1 Minimal component 구성
- Input & Output의 심플한 구성 (Source / Sink)
sample-pipeline:
source:
file:
path: path/to/input-file
sink:
- file:
path: path/to/output-file 3-2 All components 구성
- Source / Buffer / Processor / sink 구성
sample-pipeline:
workers: 4 #Number of workers
delay: 100 # in milliseconds, how often the workers should run
source:
file:
path: path/to/input-file
buffer:
bounded_blocking:
buffer_size: 1024 # max number of records the buffer will accept
batch_size: 256 # max number of records the buffer will drain for each read
processor:
- string_converter:
upper_case: true
sink:
- file:
path: path/to/output-file3-3 input - output 1 / output2 구성
input-pipeline:
source:
file:
path: path/to/input-file
sink:
- pipeline:
name: "output-pipeline-1"
- pipeline:
name: "output-pipeline-2"
output-pipeline-1:
source:
pipeline:
name: "input-pipeline"
processor:
- string_converter:
upper_case: true
sink:
- file:
path: path/to/output-1-file
output-pipeline-2:
source:
pipeline:
name: "input-pipeline"
processor:
- string_converter:
upper_case: false
sink:
- file:
path: path/to/output-2-file3-4. 조건부 Routing을 활용한 구성
- application로그는 application 라벨링을 따라서 routing
- http로그는 apache 라벨링을 따라서 routing
- all로그는 3번째 sink를 따라서 routing
이런식으로 저장소 경로를 지정해서 구성할 수 있다. - 아래 코드에 Block Keyword가 있어 포스팅이 안돼 부득이 사진으로 게시했음.
route:
- application-logs: '/log_type == "application"'
- http-logs: '/log_type == "apache"'
4. With Fluent bit
- Data ingestion이란 데이터베이스에서 즉시 사용하거나 저장하기 위한 프로세스를 말함
- Data Prepper는 Server Side collector로 명시되어있지만 Logstash처럼 정제의 기능도 수행함
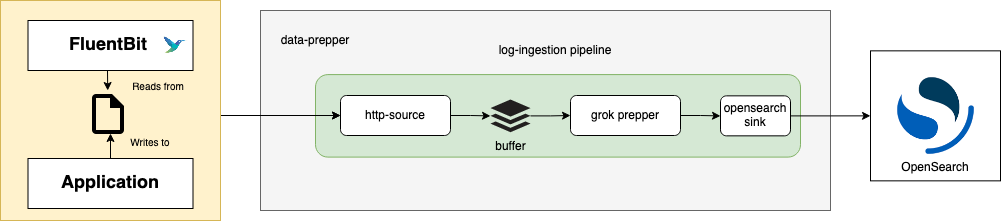
- FluentBit -> data-prepper -> Opensearch -> Dashboard식의 구성도 가능함.
4-1. Example Yaml file
Data-prepper-fluentbit-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
labels:
k8s-app: fluent-bit
data:
# Configuration files: server, input, filters and output
# ======================================================
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020
@INCLUDE input-kubernetes.conf
@INCLUDE filter-kubernetes.conf
@INCLUDE output-data-prepper.conf
input-kubernetes.conf: |
[INPUT]
Name tail
Tag kube.*
Path /var/log/containers/*my-app*.log
Parser docker
DB /var/log/flb_kube.db
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
filter-kubernetes.conf: |
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
Merge_Log_Key log_processed
K8S-Logging.Parser On
K8S-Logging.Exclude Off
output-data-prepper.conf: |
[OUTPUT]
Name http
Match kube.*
Host host.docker.internal
Port 2021
Format json
URI /log/ingest
parsers.conf: |
[PARSER]
Name docker
Format json
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
Time_Keep On5. Conclusion
- Data-prepper github에 의거하면 Gatling에서 초당 로그기록이 data-prepper 19,684 / Logstash 12,618개로 56프로 더 빠른 처리속도를 가지고 있다고 주장.
(https://github.com/opensearch-project/data-prepper/blob/main/docs/latest_performance_test_results.md) - 지원하는 Plugin이 아직까지는 작고 reference가 적음.
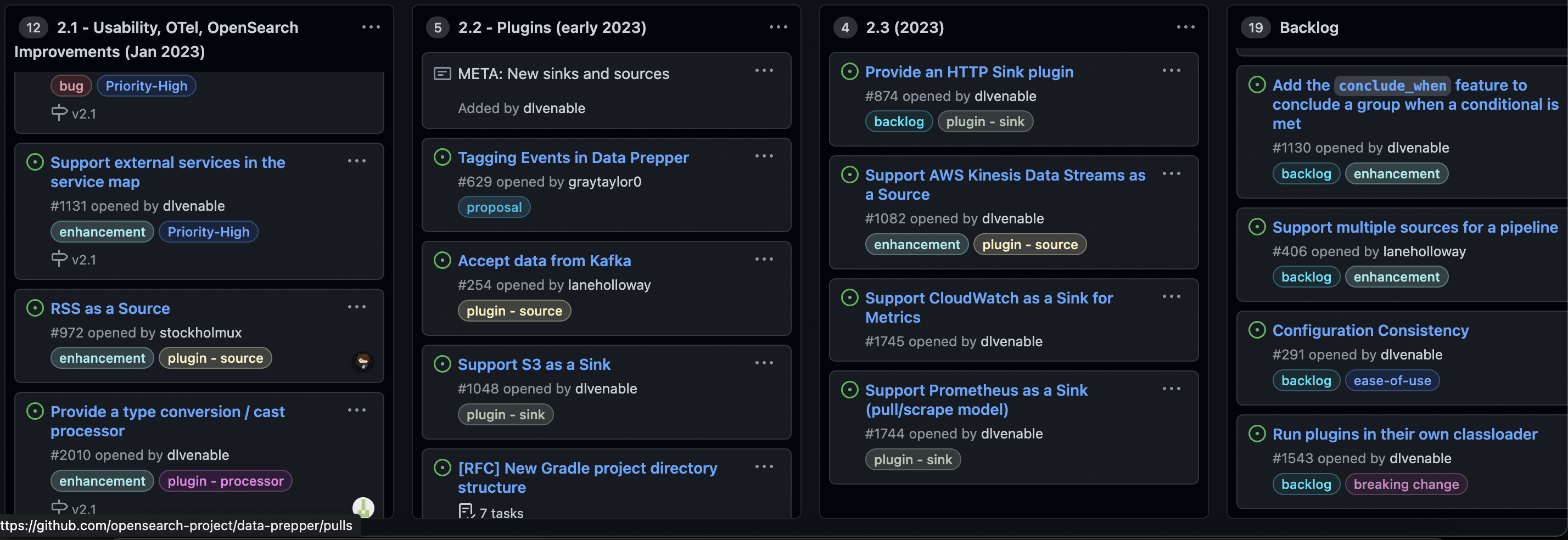
- Roadmap으로 구체적인 향후 비젼을 알 수 있다. (수집 & 정제)
(https://github.com/opensearch-project/data- prepper/projects/1)