UUID(Universally Unique Identifier)란?
UUID(Universally Unique Identifier)란?
네트워크 상에서 고유성이 보장되는 ID를 만들기 위한 표준 규약이다.
UUID는 Universally Unique Identifier의 약자로, 범용 고유 식별자를 나타낸다.
소프트웨어에서 객체나 엔터티를 식별하는 데 사용되는 고유한 식별자이다.
UUID는 네트워크 환경에서 발생할 수 있는 중복을 최소화하기 위해 설계되었다.
UUID의 구성
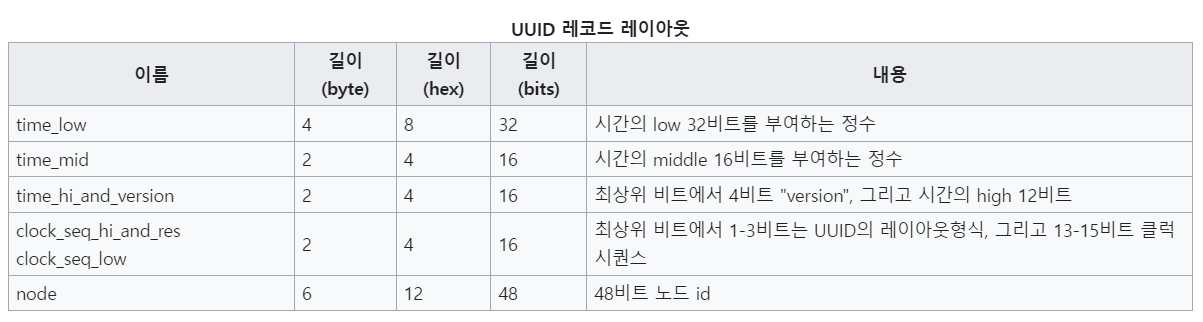
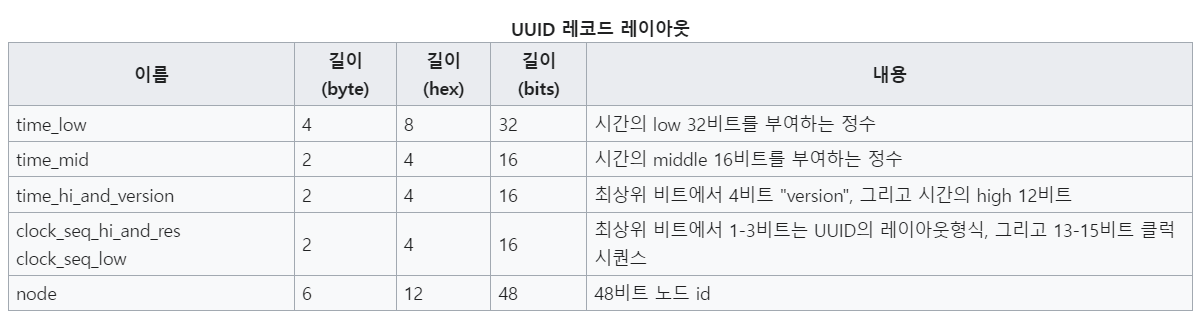
UUID는 보통 128비트의 수로 표현되며, 보통 16진수로 표현된다.
128비트는 8-4-4-4-12 형식의 5개의 그룹으로 나뉜다.
각 그룹은 하이픈('-')으로 구분되거나 구분 기호 없이 표현될 수 있다.
 (출처:https://ko.wikipedia.org/wiki/%EB%B2%94%EC%9A%A9_%EA%B3%A0%EC%9C%A0_%EC%8B%9D%EB%B3%84%EC%9E%90)
(출처:https://ko.wikipedia.org/wiki/%EB%B2%94%EC%9A%A9_%EA%B3%A0%EC%9C%A0_%EC%8B%9D%EB%B3%84%EC%9E%90)
UUID 버전
버전1 (MAC 주소)
버전2 (DCE 보안)
버전3 (MD5 해시)
버전4 (랜덤)
버전5 (SHA-1 해시)
UUID는 버전중 가장 흔하게 사용되는 것은 버전4이다.
이 버전은 시간 및 랜덤 데이터를 기반으로 생성되며, 보통 충돌 가능성이 극히 낮다.
UUID의 장점
1. 고유성
UUID는 실질적으로 중복될 가능성이 매우 낮다.
이는 UUID가 충돌 가능성을 줄이기 위해 매우 큰 수의 비트를 사용하기 때문. 따라서 대규모 시스템이나 분산 환경에서 객체의 고유성을 보장하기에 이상적이다.
2. 확장성
UUID는 수천, 수백만 개의 객체를 식별하는 데 사용할 수 있다.
새로운 객체가 추가되거나 시스템이 확장되더라도 UUID를 사용하면 객체를 고유하게 식별할 수 있다.
3. 분산 환경 지원
UUID는 분산 시스템 및 네트워크 환경에서 특히 유용하다.
중앙 집중식 식별자를 사용하는 것보다 분산된 시스템에서 중복을 피하기 쉽다.
각 노드에서 UUID를 생성할 수 있고, 이를 통해 네트워크 전체에서 고유성이 보장된다.
4. 암호학적 강도
일부 UUID 버전은 랜덤성을 기반으로 하기 때문에 암호학적으로 안전하다.
이는 예측이 어렵고, 외부에서 추측할 수 없는 무작위성을 제공하므로 보안 요구 사항을 충족할 수 있다.
5. 간편성
UUID는 상대적으로 간단하게 생성할 수 있다.
많은 프로그래밍 언어 및 플랫폼에서 UUID 생성을 위한 라이브러리나 내장 함수를 제공하므로 개발자가 쉽게 사용할 수 있다.
6. 데이터베이스에서의 유용성
데이터베이스 레코드를 고유하게 식별하고 관리할 때 UUID를 사용하는 것이 특히 유용하다.
데이터베이스 복제 및 분산 시스템에서 데이터 충돌을 방지하고 병합할 수 있다.
