들어가기에 앞서
나는 21년-23년동안 개인정보 보안 관련 IT 중소기업에서 산업체 복무를 마쳤다.
주업무는 서버 설치, 유지보수, 고객응대 쪽이었는데,
주로 고객 요청 홈페이지를 분석하고, 개인정보를 찾아주는 업무를 많이 했다.
이 업무를 하면서 한이 좀 생겼던게...
회사에서 만든 크롤러 엔진이 http get/post 통신만을 사용하다 보니
javascript가 작동한 이후 브라우저에서 페이지가 변하는 경우에는
해당 게시글을 크롤링 할 수 없었다.

대충 예시를 들자면 네이버의 경우에도
cirt+u를 통해 보는 코드와, 개발자도구로 본 코드가 다른 것을 볼 수 있는데
이는 브라우저를 통해 자바스크립트가 실행되기 전과, 실행된 후의 차이라고 할 수 있다.
이런 경우에는 어떻게 했느냐면,
내가 직접 브라우저에서 첨부파일을 하나 하나 다운로드 받은 후에, 첨부파일 주소를 크롤러 설정파일에 추가하는 방식으로 해야했다.
게시판 하나에 게시글이 수백개, 많으면 수천개가 있는데...
그걸 일일이 들어가면서 주소를 하나 하나씩 수집하는 것이... 여간 귀찮은 일이 아니였다..
(물론 별도의 요령이 있어 노가다 작업을 줄일 수는 있었지만, 그래도 꽤 시간이 걸리는 작업이었다.)
그러다 23년 4월인가 산업체 복무도 마치고,
24년 3월 복학까지 시간이 많이 남게 되었다.
몇 개월 빈둥거리니 문득 이런 생각이 들었다.
'쓰읍... 그때 그 크롤러 selenium으로 만들어 볼 수 있을 거 같은데..?'
[selenium - 대표홈페이지]
https://www.selenium.dev/
selenium이 뭐냐면, chromedriver를 제어하여 원하는 데이터를 수집할 수 있는 패키지다.
이 친구는 크롬 브라우저로 실행했을 때 환경과 동일한 데이터를 수집할 수 있기 때문에, 게시판이 javascript 실행 후 생성되더라도 데이터를 수집할 수 있을 것이라고 생각했다.
문제는 javascript가 실행되기까지 기다려야 하기 때문에
일반적인 http 통신에 비해 속도가 압도적으로 느릴 것이란 거다...
흐음.. 아 몰라.
나는 이걸로 사업할 생각이 없기 때문에 그냥 신경쓰지 않기로 했다.
일단 시작해!
개인정보 파싱 엔진(TFilter)을 만들어 보자
Apache Tika를 써보자
[Office 문서(doc, ppt, xls) 텍스트, 이미지 추출을 해보자]
https://velog.io/@sostar0832/Office-%EB%AC%B8%EC%84%9Cdoc-ppt-xls-%ED%85%8D%EC%8A%A4%ED%8A%B8-%EC%9D%B4%EB%AF%B8%EC%A7%80-%EC%B6%94%EC%B6%9C%EC%9D%84-%ED%95%B4%EB%B3%B4%EC%9E%90
이 과정 중 하나가 위 프로젝트였다.
결국 망해버리긴했지만 한 가지 소득이 있었다.
[Apache Tika]
https://tika.apache.org/
바로 Apache Tika를 알게 된 것이다.
우리 대단하신 Apache 형님들께서는 OfficeDocument(doc, ppt, xls), pdf 등 파일로부터 텍스트를 추출하는 프로그램을 만들어 배포하셨다.
[Apache Tika - Download]
https://tika.apache.org/download.html
대충 여기서 tika-app.jar 파일을 다운로드 하고
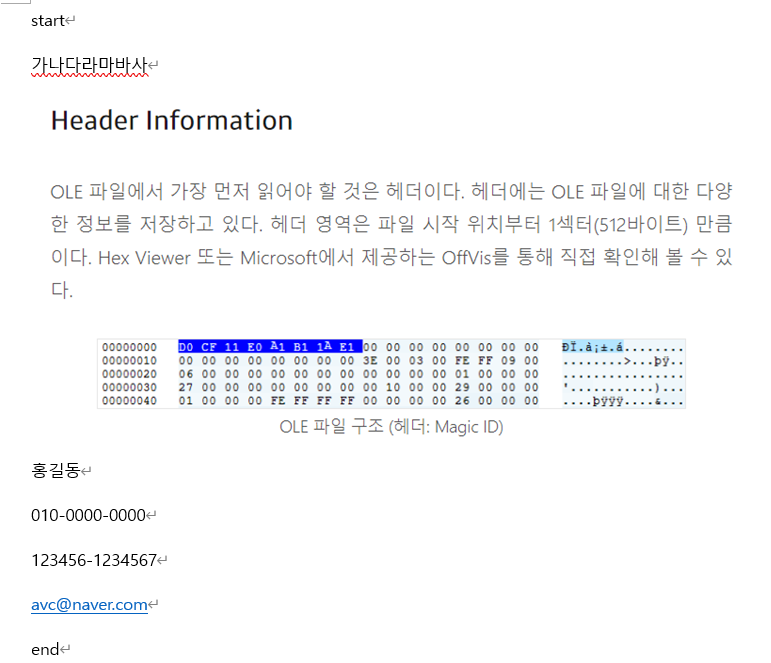
이 따위로 작성된 doc.doc 파일을 검사하면
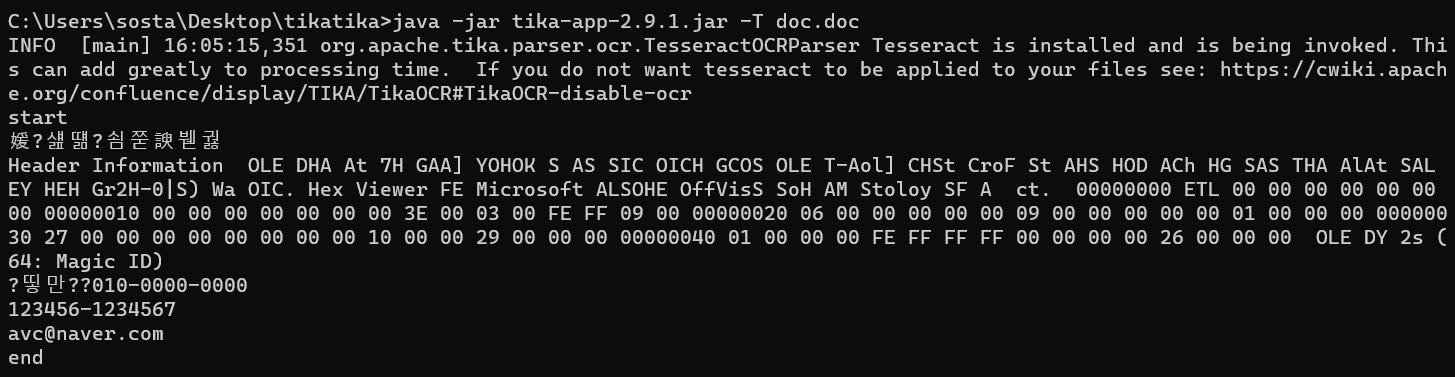
와우! 브라보!
tika 내부에 tesseractOCR도 있어 이미지에 있는 텍스트도 함께 파싱한 것을 볼 수 있다.
다만 내부 tesseract의 기본 언어 설정이 영어다 보니 한글이 깨져서 파싱이 된다.
'아.. 이미지 파싱은 좋은데 한글 깨지면 안되는데....'
귀찮은데 넘어갈까 생각하다가 결국 구글링을 1~2시간 해보았다.
[cwiki : TikaServer - TIKA - Apache Software Foundation]
https://cwiki.apache.org/confluence/display/TIKA/TikaServer
Overriding the configured language as part of your request
Different requests may need processing using different language models. These can be specified for specific requests using the X-Tika-OCRLanguage custom header. An example of this is shown below:
curl -T /path/to/tiff/image.jpg http://localhost:9998/tika --header "X-Tika-OCRLanguage: eng"
Or for multiple languages:
curl -T /path/to/tiff/image.jpg http://localhost:9998/tika --header "X-Tika-OCRLanguage: eng+fra"
아 tika-app 말고 tika-server를 쓰면 명령어로 ocr 언어설정이 가능해?
오케 오케
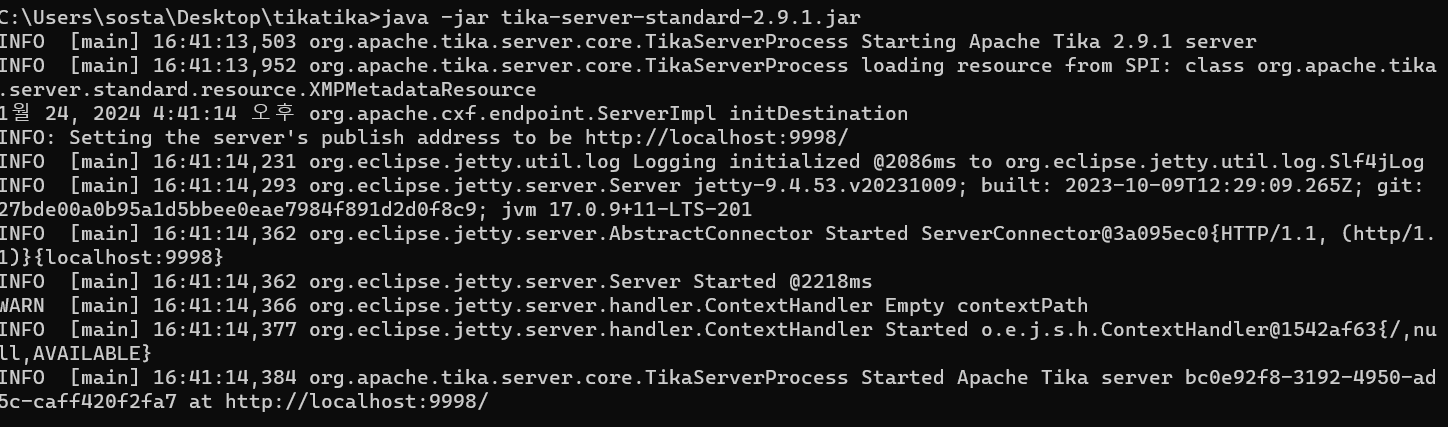
이번에는 tika-server.jar 파일을 다운로드하고
사진처럼 tika-server를 실행 후
curl 명령어를 입력하면
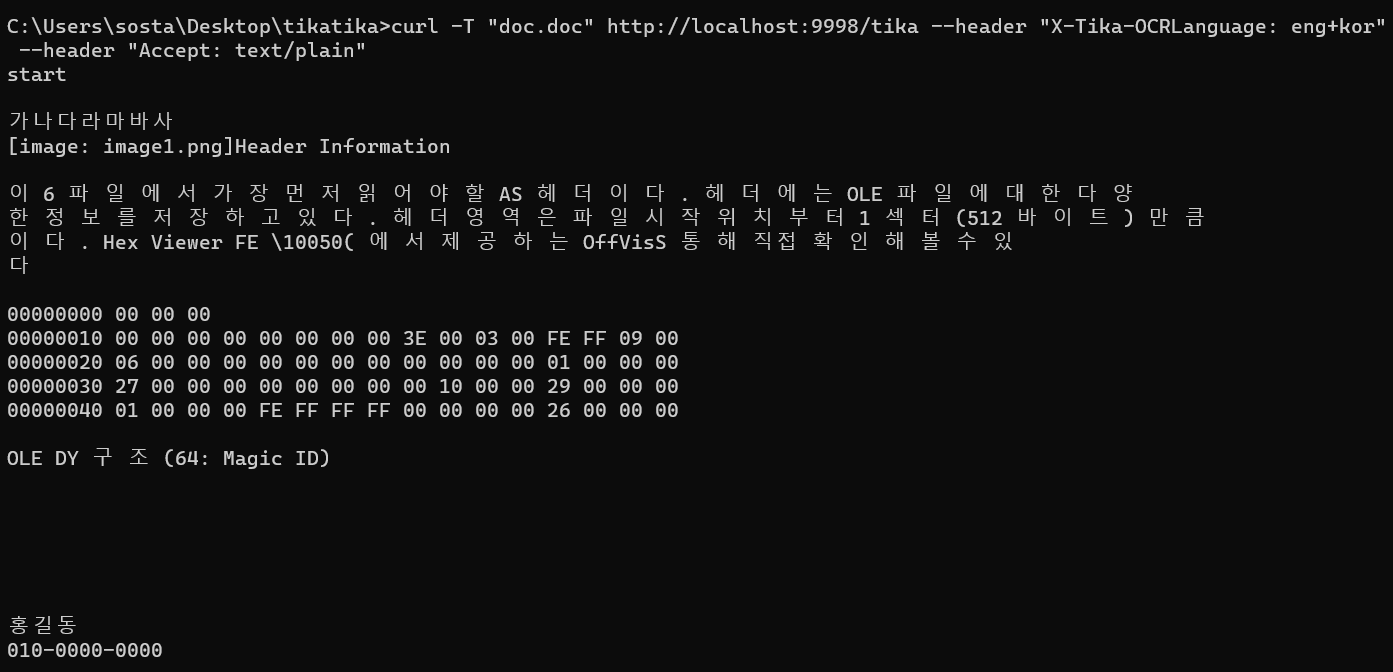
한글도 정상적으로 추출하는 것을 볼 수 있다. 와우!
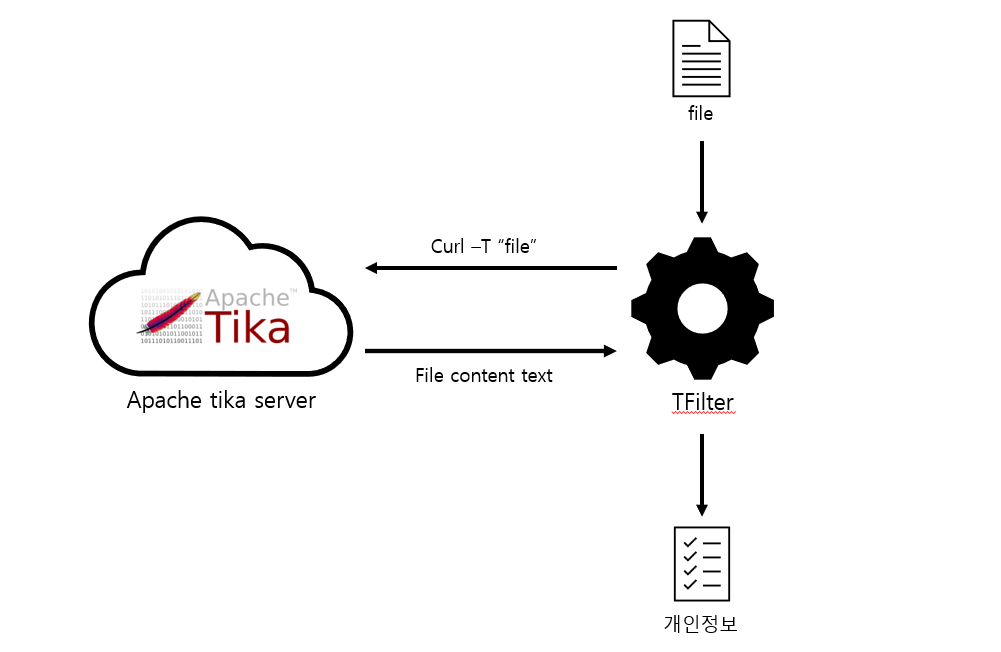
Tfilter를 작성해보자
Tfilter 구상

대략 구상은 위와 같다.
파일을 받으면, curl을 통해 tika-server에 전송하고
tika-server에서 텍스트를 받으면, 그 텍스트 중 개인정보 내용을 출력하는 것이다.
자 이제 시작해보자.
config.py 생성
# tempDir : 이미지 temp 값이 잠깐 저장되는 위치
tempDir="C:/pyProject/TFilter/temp"
# tikaServerName : tika-server 연결 url
tikaServerName="http://localhost:9998/tika"
# tikaOCRLang : tika-server의 tesseract 언어 설정
tikaOCRLang="eng+kor"
# regularExpress : 기본으로 적용되는 정규식
regularExpress = dict()
regularExpress["social number"] = "\d\d(0[1-9]|10|11|12)(0[1-9]|[1-2][0-9]|30|31)[^\d]?[^\d]?[^\d]?[0-9]{7}"
regularExpress["phone number"] = "01[0-9][^\d]?[0-9]{4}[^\d]?[0-9]{4}"
regularExpress["e-mail"] = "[^\\s]{1,30}@[^\\s]{1,20}"config.py 파일에는 tikaServer의 url과, 개인정보 페턴을 저장해두기로 했다.
tempDir은 나중에 이미지 파일 같은 임시파일을 사용해야 할 때 사용하기 위해 경로를 저장해 두었다.
tfilter 클래스
class TFilter:
def __init__(self):
self.filter = config.regularExpress
self.osName = self.get_osName()
self.filepath = ""
self.content = b""
def open(self, filepath):
self.filepath = filepath
self.content = self.get_content()TFilter 클래스를 생성 후
TFilter.open(filepath) 함수를 사용하여 파일의 텍스트를 추출하도록 작성했다.
tfilter.get_content
def get_content(self):
if(self.osName == "Windows"):
return self.get_content_win()
return b""
def get_content_win(self):
content = b""
cmd = "curl -T \""+ self.filepath + "\""\
+ " \""+config.tikaServerName + "\""\
+ " --header \"X-Tika-OCRLanguage: " + config.tikaOCRLang\
+"\" --header \"Accept: text/plain\""
print(cmd)
content += subprocess.check_output(cmd, text=False)
doc_type_cmd = "java -jar \"" + config.tikaDir + "\""\
+ " -d \"" + self.filepath + "\""
doc_type = subprocess.check_output(doc_type_cmd, text=False)
if(doc_type == b"application/x-hwp-v5\r\n"):
content += self.extract_text_from_hwp_img()
return contentget_content는 curl을 사용할 때 window와 linux가 다를 것을 대비해서 get_content_win 함수를 따로 만들어주었다.
한 가지 고생을 한 것은
content += subprocess.check_output(cmd, text=False)처음에 curl 명령어를 사용할 때,
subprocess.check_output이 아닌 os.system을 사용했는데
특정 기능을 구현할 때 뭔가 오류가 발생하면서 os.system으로 작성했던 모든 코드를 subprocess.check_output로 교체하게 되었다.
정확히 무슨 문제였는지는 따로 작성해둔게 없다보니 기억이 안난다.
그 외에 text=False 설정 안하고 str 타입으로 받으면
encoding 문제가 발생해서 그냥 binary type으로 받았다.
if(doc_type == b"application/x-hwp-v5\r\n"):
content += self.extract_text_from_hwp_img()이 친구는 한글파일인 경우 별도로 extract_text_from_hwp_img 햠수를 작동한다는 의미이다.
apache tika가 다 좋은데, 슬프게도 hwp 파일 본문에 있는 이미지를 추적하지 못한다.
그래서 생각한 것이 파일이 hwp 파일 구조인 경우,
별도로 이미지를 추출한 후, 추출된 이미지에서 텍스트를 추출하는 것이었다.
hwpImgParser.parser 클래스
Office 문서(doc, ppt, xls) 텍스트, 이미지 추출을 해보자
아까 위에서 잠깐 언급했던 프로젝트다.
이 프로젝트를 하면서 이미 hwp 파일에서 이미지를 추출하는 방법을 정리해 두었다.
class Parser:
def __init__(self):
self.ole = None
self.fileName = ""
self.fileType = ""
self.streamList = None
def open(self, filepath):
self.ole = olefile.OleFileIO(filepath)
self.fileName = os.path.splitext(filepath)[0]
self.fileType = os.path.splitext(filepath)[1]
self.streamList = self.getOLEStreamList()시작할 때는 위와 같이 설정하고
def get_images(self, outfilepath):
if(outfilepath[-1] != '/'):
outfilepath = outfilepath + '/'
imgNames = list()
for stream in self.streamList:
if('jpg' in stream or 'png' in stream or 'bmp' in stream):
fileName = stream.replace("/", "_")
imgNames.append(self.hwp_img_zlib(self.ole.openstream(stream).read(), outfilepath, fileName))
return imgNames
def hwp_img_zlib(self, binData, outfilepath, fileName):
try:
data = zlib.decompress(binData, -15)
except:
data = binData
now = datetime.now().strftime("%Y%m%d_%H%M%S_")
imgName = os.path.join(outfilepath, now + fileName)
fp = open(imgName, 'wb')
fp.write(data)
fp.close()
return imgName위 함수를 사용해서 이미지를 추출해내는 방식이다.
대충 설명하자면 olefile 라이브러리를 사용하여 stream을 나누고
jpg, png, bmp 이름을 가진 stream의 경우
zlib을 사용하여 압축을 해제하는 방식이다.
def close(self):
self.ole.close()하나 신경 쓸 점은 olefile 라이브러리를 사용 후,
ole.close를 사용하지 않으면
나중에 os나 subprocess를 사용할 때 오류가 발생한다는 것이다.
[비얌의 블로그 - [파이썬] PermissionError: [WinError 32] 해결하기]
https://m.blog.naver.com/kellygirl4028/222545821922
위 블로그를 작성한 분께 정말 감사드린다.
이거 몰라서 몇 시간 고생을 했다.
tfilter.extract_text_from_hwp_img
def extract_img_from_hwp(self, filepath, outDir):
hwpParser = hwpImgParser.Parser()
hwpParser.open(filepath)
imgNames = hwpParser.get_images(outDir)
hwpParser.close()
return imgNames
def extract_text_from_hwp_img(self):
imgNames = self.extract_img_from_hwp(self.filepath, config.tempDir)
img_content = b""
for imgPath in imgNames:
cmd = "curl -T \""+ imgPath + "\""\
+ " \""+config.tikaServerName + "\""\
+ " --header \"X-Tika-OCRLanguage: " + config.tikaOCRLang\
+"\" --header \"Accept: text/plain\""
img_content += (imgPath.split("/")[-1]+"\r\n").encode(encoding='UTF-8')
img_content += subprocess.check_output(cmd, text=False)
for imgPath in imgNames:
if os.path.isfile(imgPath):
os.remove(imgPath)
return img_contentextract_img_from_hwp 함수를 통해 config.tempDir에 이미지를 추출하고
tika-server에 해당 이미지들을 전송하여 텍스트를 얻는 방식이다.
마지막에 os.remove를 사용하여 tempDir에 있는 이미지를 처리한다.
그외 개인정보 설정 및 확인 함수들
def put(self, key, value):
self.filter[key] = value
def delete(self, key):
del self.filter[key]
def get(self):
content_text = self.content.decode(encoding="utf-8")
counts = dict()
keys = list()
values = dict()
for key in self.filter.keys():
keys.append(key)
counts[key] = 0
values[key] = list()
reg = self.filter[key]
pattern = re.compile(reg)
items = pattern.finditer(content_text)
for item in items:
values[key].append(item.group())
counts[key] += 1
result = {"keys" : keys, "counts" : counts, "values" : values}
return result파일로부터 텍스트를 추춯하는 기능을 위에서 구현했으니
추출한 텍스트로 부터 개인정보에 해당하는 텍스트를 추출하기만 하면 된다.
def put(self, key, value):
self.filter[key] = value
def delete(self, key):
del self.filter[key]put과 del을 사용해서 개인정보에 해당하는 정규식을 추가하거나 삭제하고
def get(self):
content_text = self.content.decode(encoding="utf-8")
counts = dict()
keys = list()
values = dict()
for key in self.filter.keys():
keys.append(key)
counts[key] = 0
values[key] = list()
reg = self.filter[key]
pattern = re.compile(reg)
items = pattern.finditer(content_text)
for item in items:
values[key].append(item.group())
counts[key] += 1
result = {"keys" : keys, "counts" : counts, "values" : values}
return resultget 함수를 사용하여 filter에 해당하는 값들을
dictionary 형태로 리턴받는 것이다.
테스트 해보자
전화번호 이메일 등이 적혀있는 w_명함.doc 파일을 준비했다.
import TFilter
tfilter = TFilter.TFilter()
filepath = "C:/pyProject/TFilter/testfiles/w_명함.doc"
tfilter.open(filepath)
print(tfilter.get())간단하게 코드를 작성하고 실행해보면
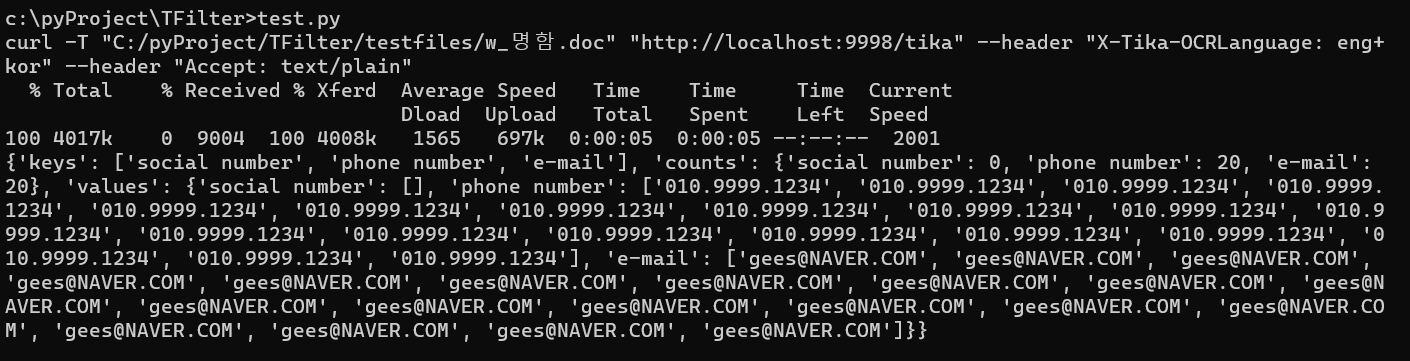
오케오케
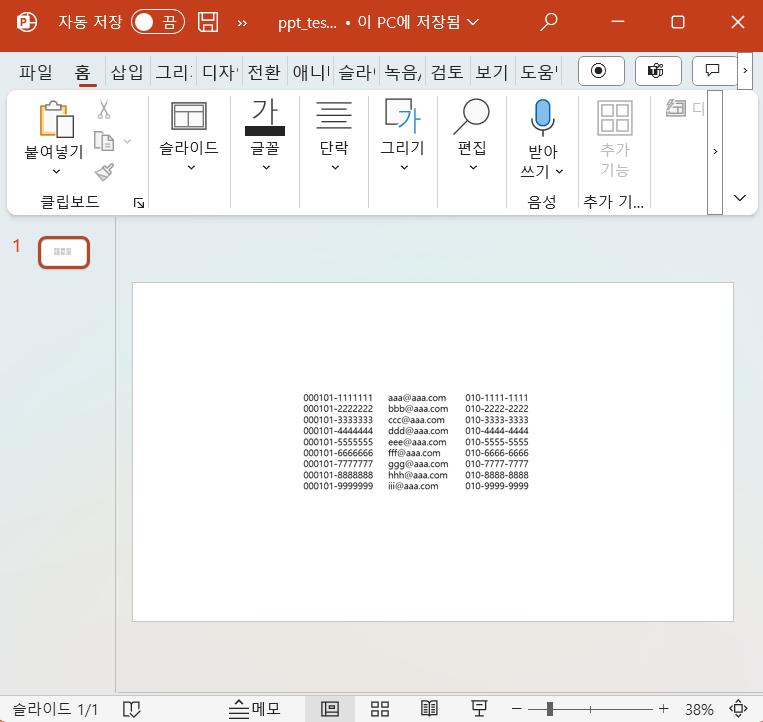
이번에는 ppt에 개인정보가 적힌 이미지를 넣었다.
import TFilter
tfilter = TFilter.TFilter()
filepath = "C:/pyProject/TFilter/testfiles/ppt_test.ppt"
tfilter.open(filepath)
print(tfilter.get())똑같이 실행해 보면
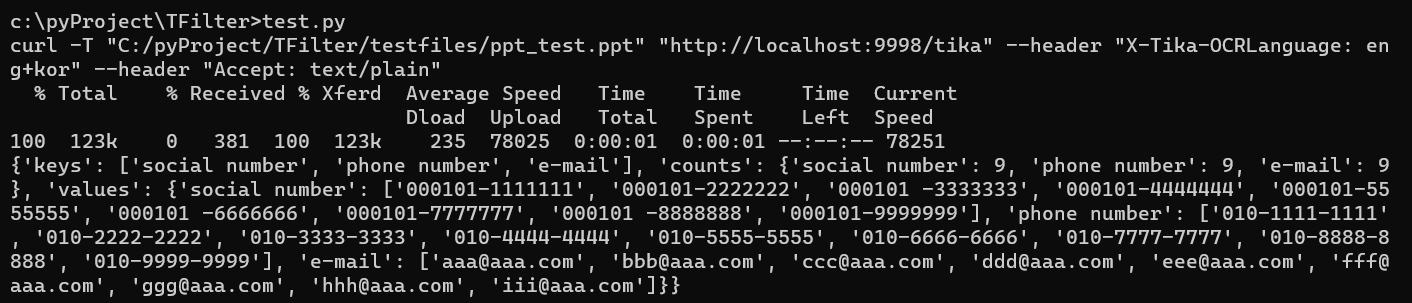
좋다. 잘 된다.
개인정보 검출 프로그램 구상
이제 개인정보 파싱 엔진도 만들었겠다.
전체적인 그림을 그려보았다.
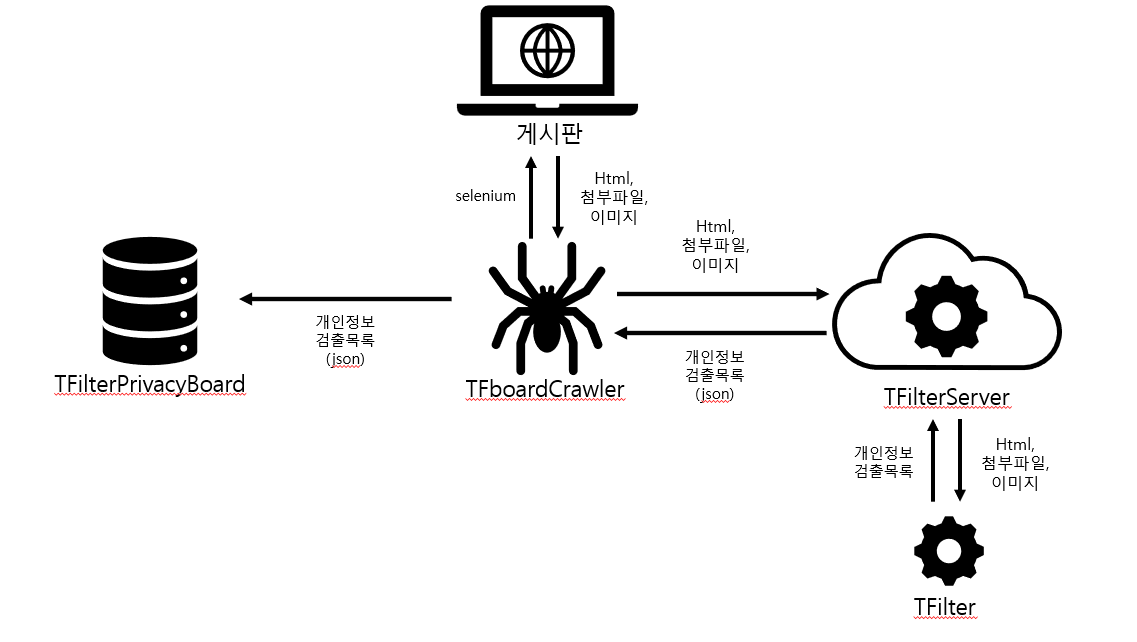
우선 TFilter를 TFboardCrawler에 포함하지 않고 별도의 TFilterServer를 만드려고 한다.
크롤링이 끝나고 나중에 TFilterPrivactBoard에 개인정보 검출내역을 확인했을 때,
게시글의 어떤 파일에서 개인정보가 검출됐는지 찾아야 하는데
이 때 직접 TFIilterServer를 사용하면 쉽게 개인정보를 찾을 수 있기 때문이다.
TFboardCrawler는 게시판에서 게시글(html), 첨부파일, 이미지 파일 등을 다운로드 하고, 이를 curl을 통해 TFilterServer에 전송하는 방법으로 개인정보 검출 결과를 얻을 것이다.
만약 개인정보가 검출된 경우,
TFilterPrivacyBoard에 개인정보 검출 목록 json을 전송하고,
TFilterPrivacyBoard에 등록된 게시판인 경우에 DB에 저장하면 된다.
이번 글은 여기서 마치고
다음 글에서 TFilterServer를 구현하는 과정을 작성하려고 한다.
