들어가기에 앞서
[TFilter - 개인정보 검출 프로그램을 만들어 보자(2)]
https://velog.io/@sostar0832/TFilter-%EA%B0%9C%EC%9D%B8%EC%A0%95%EB%B3%B4-%EA%B2%80%EC%B6%9C-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%A8%EC%9D%84-%EB%A7%8C%EB%93%A4%EC%96%B4-%EB%B3%B4%EC%9E%902
이전에 작상한 글과 이어진다.
이번에는 TFBoardCrawler와 TFilterPrivacyBoard를 만들어보려고 한다.
자 그런데 들어가기에 앞서 고민이 좀 있었다.
일단 기본적으로 github에 코드를 공유하기도 하고,
코드를 쓰면서 생각한 것들을 정리하기 위해 코드를 공유하면서 글을 쓰고 있었는데...
지금 만들고 있는 것이 말이 좋아야 "개인정보 검출 프로그램"이지
남이 쓸 때 "개인정보 유출 프로그램"이 될 수 있다는 것이다...
만약 내 코드를 그대로 가져가서 어떤 사람이 개인정보를 털고 나서
'와! 석훈씨 덕분에 개인정보 털기가 쉬워졌어요!'
라고 말해버리면... 바로 깜방행이지 않을까?
이런 생각이 들었다.
그래서 TFBoardCrawler 코드는 공유하지 않고, github에도 올리지 않으려고 한다.
다만 어떤 식으로 동작하는 지는 작성하고, 주로 selenium을 사용하면서 생겼던 불편한 점들을 공유하려고 한다.
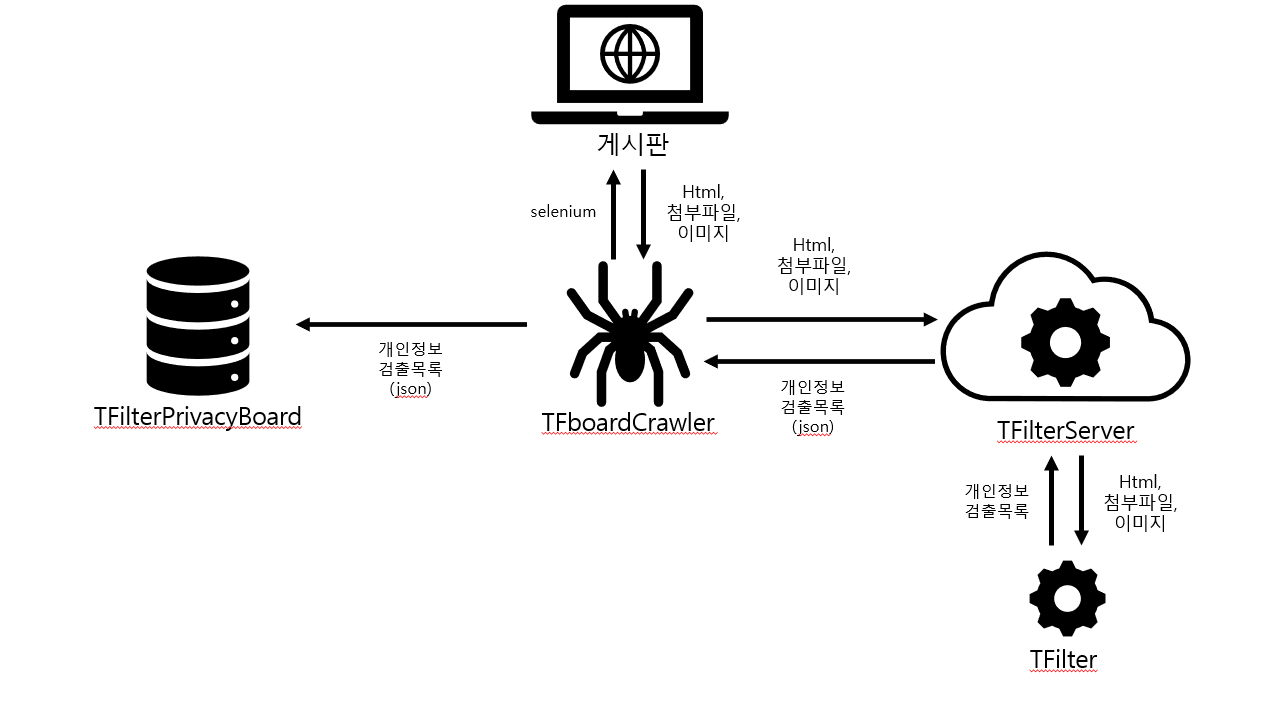
TFboardCrawler
작동 방식
import TFcrawler
import config
config.loading_time = 2
config.group_id = "test-group"
crawler = TFcrawler.TFcrawler()
crawler.open()
# 필수입력
crawler.set_board_url("https://www.cau.ac.kr/cms/FR_CON/index.do?MENU_ID=100#page1")
crawler.set_page_selector("#p_pagingFH > ul > li > a")
crawler.set_move_page_func("location.href = 'https://www.cau.ac.kr/cms/FR_CON/index.do?MENU_ID=100#page", "';")
crawler.set_view_selector("div.txtL > a")
# 진단 대상이 아닌 경우 주석처리
crawler.set_board_title_selector("#container > div.sVisual > div > strong")
crawler.set_view_title_selector("#sendForm > div > dl > dt > div.txtL > p")
crawler.set_view_date_selector("#sendForm > div > dl > dt > div.txtInfo > span.date")
crawler.set_attach_selector("#sendForm > div > dl > dd > div.fileArea > p > a")
crawler.set_view_img_selector("#sendForm > div > dl > dd > p > img")
# run(strPage, endPage) : 게시판 시작 페이지, 끝 페이지 설정
crawler.run(1, 10)
crawler.close()대충 이런 느낌이다.
게시판, 게시글, 첨부파일과 관련된 selector를 입력하고,
crawler.run을 실행하면 지정된 페이지 만큼 탐색을 시작한다.
그냥 이 코드를 보여주면 이런 이야기가 나올 것 같다.
'아니 지정된 곳만 탐색하고 하위 url 탐색도 못하는 게 무슨 크롤러냐?'
'DOM구조 바뀌면 못 써먹는거 아님? 너무 허접한데?'
TFilter - 개인정보 검출 프로그램을 만들어 보자(1)
이 글에서도 설명했지만, http request를 사용하는 방식은 'javascript가 작동한 이후 브라우저에서 생성되는 게시판'을 탐색하지 못한다.
그래서 selenium을 사용해서 javascript가 실행된 환경을 구한 것인데,
문제는 selenium을 사용하면 통신 속도가 드럽게 느리다는 것이었다.
기존 크롤러가 작동하는 것처럼 사방팔방 하위 url을 모두 수집하면,
홈페이지 탐색을 완료하는데 평생 걸릴 것이 뻔했다.
그래서 타협을 본 것이, 탐색할 대상을 직접 정해주는 것이었다.
이것 저것 테스트했을 때, 대충 9개 정도만 지정을 해주면 깔끔하게 탐색이 가능했다.
물론 게시판 구조가 바뀌면, 설정도 다시 바꿔야 하지만...
게시판 한 개 설정하는데 5분이 안 걸리니 나는 나름 만족했다.
TFcrawler 코드는 못 보여주지만, 대충 설명하자면
탐색하면서 게시글에 있는 본문, 첨부파일, 이미지 등을 TFilterServer에 전송하고,
개인정보 검출 결과가 있는 경우 "http://localhost:1888/tfilter/add_json_data" 로 전송하도록 설계했다.
Selenium을 쓰면서..
다운로드 경로 설정
# 크롬 드라이버 설정
options = Options()
options.add_experimental_option("prefs", {
"download.default_directory": self.download_path,
})selenium은 다운로드 받는 경로를 변경할 수 있다. 다만...
download_temp_path = r"c:\pyProject\TFboardCrawler\temp_download\"위와 같이 절대 경로로 표현하지 않거나,
경로에 백슬래시(\)를 쓰지 않거나,
마지막이 백슬래시로 끝나지 않는 경우 경로가 재대로 변경되지 않는다.
와 무슨 경로하나 지정하는데 이렇게 까다롭나....
이거 때문에 2시간을 날렸다.
wait
[Selenium - Waiting Strategies]
https://www.selenium.dev/documentation/webdriver/waits/
selenium은 특정 요소가 조건을 만족할 때까지 대기하는 Explicitly Wait를 지원한다.
다만 javascript로 페이지가 변한 경우, 해당 요소가 생성이 됐는데도 계속 기다리는 모습이 허다하다.
t = 0
while(t <= config.loading_time):
t += 0.5
time.sleep(0.5)
try:
body = self.driver.execute_script("return document.querySelector('"+selector+"').innerText")
except:
body = ""
if(body != "" and body != self.body): break그래서 나는 driver.execute_script를 사용했을 때,
이전과 다른 값이 나올 때까지 대기하도록 별도로 코드를 작성했다.
이 코드도 조금 불편한 점이 존재하긴 하지만
selenium에서 제공하는 Explicit waits 보다는 더 쓸만했다.
driver.find_element
wait에서 말한 문제와 같은 문제이다.
javascript로 페이지가 변한 경우, 특정 요소가 생성이 됐는데도 해당 요소를 인식 못하는 경우가 종종있다.
script = "return document.querySelectorAll(\'"+self.attach_selector+"\').length"
attach_check = self.driver.execute_script(script) > 0이런 경우에도 그냥 driver.execute_script를 사용해서 파악하는 방식을 사용했다.
정말 쓰면 쓸 수록 selenium에 하자가 많이 느껴졌다..
TFilterPrivacyBoard
Django를 써보자
[django 홈페이지]
https://www.djangoproject.com/
이번에 웹 페이지를 만드는 김에 django도 같이 공부해보기로 했다.
뭐 nodejs express 쓰면서 MVC 구조도 조금은 알고 있으니까
그렇게 어렵지는 않을 것 같았다.
[django - 시작하기]
https://docs.djangoproject.com/ko/5.0/intro/
대표홈페이지 가이드를 보면서 대충 공부하고, 바로 만들어 보았다.
tfilter.models
class Group(models.Model):
group_id = models.CharField(max_length=200)
group_name = models.CharField(max_length=200)
create_date = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.group_name
class Filter(models.Model):
group = models.ForeignKey(Group, on_delete=models.CASCADE)
board_name = models.CharField(max_length=200)
view_name = models.CharField(max_length=200)
view_date = models.CharField(max_length=200)
key = models.CharField(max_length=200)
value = models.CharField(max_length=200)
url = models.CharField(max_length=500)
upload_date = models.DateTimeField(auto_now_add=True)
def __str__(self):
return self.view_nameGroup에서 그룹을 생성하고
Filter에서 해당 그룹에 대한 개인정보 검출 내용을 저장하는 방식을 사용했다.
def add_json(self, json_data):
data = json.loads(json_data)
values = data["values"]
self.board_name = data["board"]
self.view_name = data["view"]
self.view_date = data["date"]
self.url = data["url"]
self.group = Group.objects.get(group_id=data["id"])
for k in values.keys():
items = values[k]
if(len(items) == 0): continue
for item in items:
self.value = item
f = Filter(
group = self.group,
board_name = self.board_name,
view_name = self.view_name,
view_date = self.view_date,
key = k,
value = item,
url = self.url
)
f.save()add_json 함수를 통해 TFboardCrawler에서 얻은 json 데이터를 Filter에 추가했다.
tfilter.views.add_json_data
@csrf_exempt
def add_json_data(request):
try:
print(request.body)
f = Filter()
f.add_json(request.body)
except:
return HttpResponse("오류가 발생했습니다.")
return HttpResponse("json 데이터가 db에 추가되었습니다.")/tfilter/add_json_data에 json 데이터가 전송되면
add_json을 실행하는 방식이다.
TFilterPrivacyBoard & TFboardCrawler 연동 확인
자 이제 크롤러에서 전송한 json이 db에 추가되는지 확인해보자.
1888 포트로 서버를 실행하고
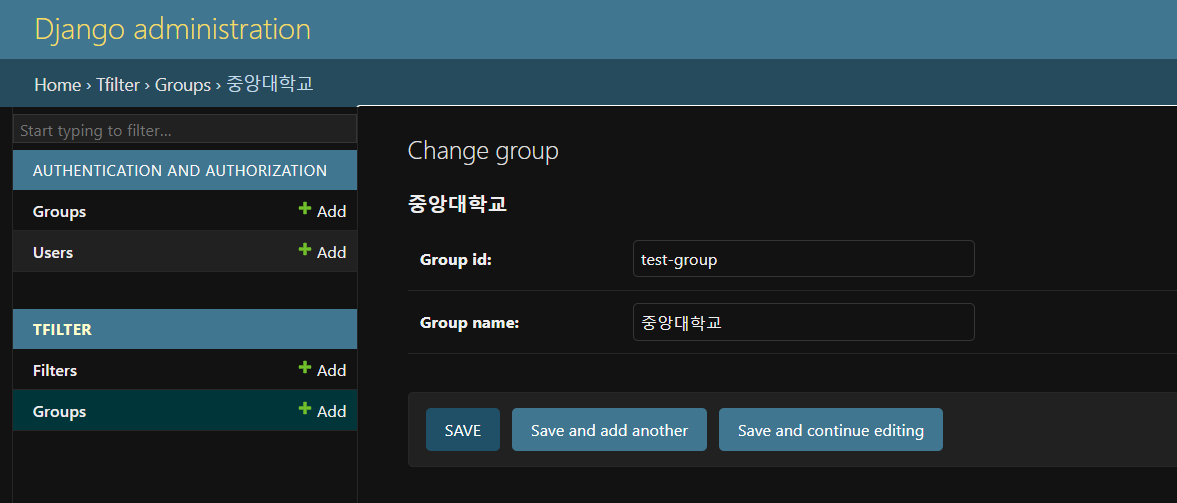
django admin 페이지에서 그룹을 생성한 후에

TFboardCrawler로 크롤링을 진행하면

짜잔! db에 데이터가 잘 쌓인다.
아 혹시 몰라 말하는데, 이메일이나 전화번호가 검출되기는 했으나 모두 관리자 정보여서 큰 문제가 되지 않았다.
그래도 일단 모자이크 처리는 했다.
개인정보 검출 현황 게시판 구현
tfilter.urls
자 마지막으로 개인정보 검출 현황을 보여주는 게시판을 구현하자
from django.urls import path
from . import views
urlpatterns = [
path("", views.index, name="index"),
path("<int:page>", views.index_page, name="index_page"),
path("<str:group_id>/result/<int:page>", views.result, name="result"),
# ex: /tfilter/input/
path("add_json_data", views.add_json_data, name="add_json_data"),
]tfilter/index_page에서 그룹을 선택하면
tfilter/group_id/result/page에서 결과를 보여주는 방식이다.
tfilter.views
def index_page(request, page):
latest_group_list = Group.objects.order_by("-create_date")[(page-1)*5: (page-1)*5+5]
leftpage = page-1
rightpage = page+1
context = {"latest_group_list": latest_group_list, "page": page, "leftpage": leftpage, "rightpage": rightpage}
return render(request, "tfilter/index.html", context)
def result(request, group_id, page):
group = Group.objects.get(group_id=group_id)
filter_list = Filter.objects.filter(group=group).order_by("-upload_date")[(page-1)*10: (page-1)*10+10]
title = group.group_name
leftpage = page-1
rightpage = page+1
context = {"filter_list": filter_list, "title": title, "group_id": group_id, "page": page, "leftpage": leftpage, "rightpage": rightpage}
return render(request, "tfilter/result.html", context)대충 위와 같이 template에 전달하면
브라우저 화면
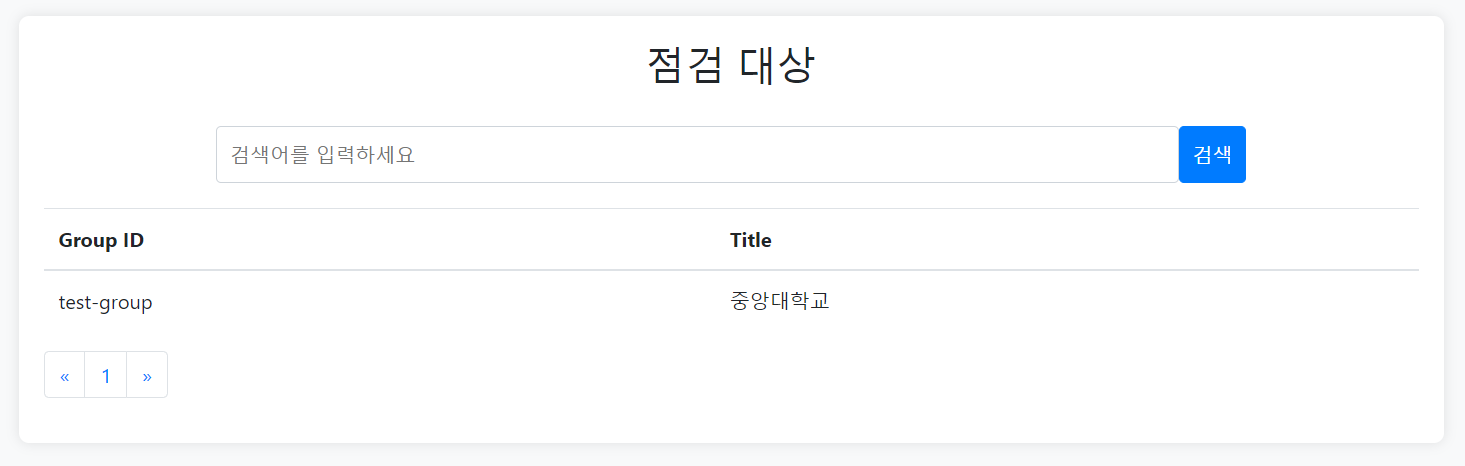
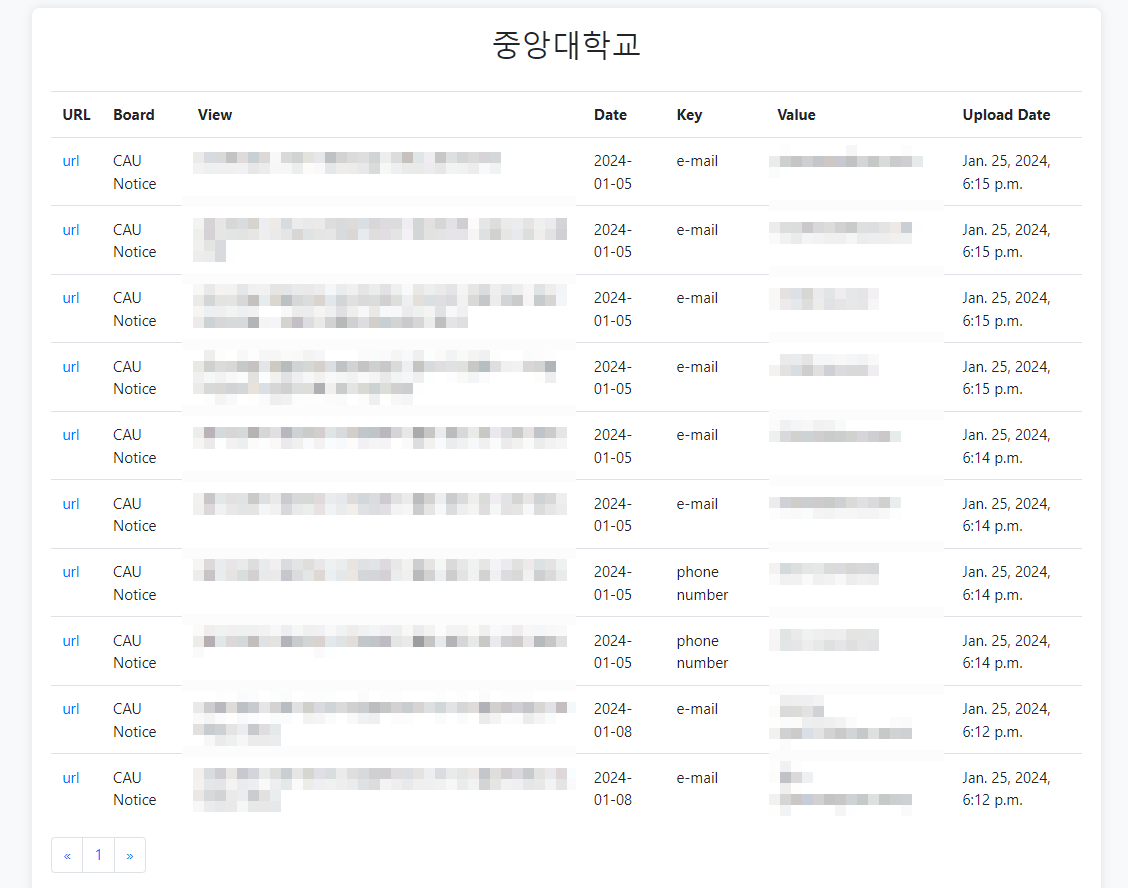
이런 느낌으로 완성되었다.
게시판 구조는 우리 전지전능하신 gpt 형님이 만들어 주셨다.
고마워요! chatGPT!
마무리하며
으아.. 드디어 프로젝트가 마무리 됐다.
처음에는 나름 재미있었는데, 뒤로 갈수록.. 어우....
특히 크롤러 만드는 과정에서 귀찮아서 때려치고 싶었다.
뭐 어떻게든 코드를 다 짜긴했는데, 마지막에 글도 써야해서 정말 하기 싫었다.
이번 글도 보면, 이전 글들에 비해 대충 쓴 느낌이 강한데, 정말 귀찮아서 설렁설렁 넘어 가서 그렇다. 블로그 글 쓰시는 분들 존경한다...
사실 TFilterPrivacyBoard의 경우 추가해야 할 기능이 많다.
- 로그인 기능
- group 추가 페이지
- 점검결과 key 및 value 검색 기능
- Date 및 upload_date 정렬 및 검색기능
- 기간별 개인정보 노출건수 총합
- 계정별 group 조회 제한
등등.. 실제 제품에 비하면 너무 부실하게 구현했다.
한 두달 정도 시간을 투자하면 나름 그럴사한 구성을 만들 수도 있을 것 같은데... 귀찮아서 하기 싫다.
이번 프로젝트는 여기까지..
만약 나중에 한 번 생각나면 업데이트를 할 수도 있고 안 할 수도 있다.
