
안녕하세요! 소리입니다 👋
이번 글에서는 빠른 데이터 탐색의 기초인 이분 탐색에 대한 내용을 준비했어요.
🚀 이분 탐색이란?
여러분은 Up&Down 게임을 아시나요?
한명이 1부터 100까지 숫자 중 하나를 생각하면, 나머지 사람들은 생각한 숫자를 맞추는 게임이에요.
이때, 추측한 숫자보다 정답이 크면 Up, 작으면 Down을 외쳐요.
Up&Down 게임에서 어떻게 숫자를 맞출 수 있을까요?
가장 확실한 방법은 1부터 100까지 차례대로 말하는 방법이에요.
이 방법을 사용하면 숫자를 무조건 맞출 수 있지만, 일일이 확인한다는 점에서 비효율적이죠.

좀 더 효율적으로 맞추려면, 정답의 범위를 절반씩 줄여나가는 방법을 사용하면 돼요.
범위 중간의 숫자를 말하고, Up이라면 말한 숫자를 하한으로 잡고 다시 범위를 줄여나갈 수 있어요.
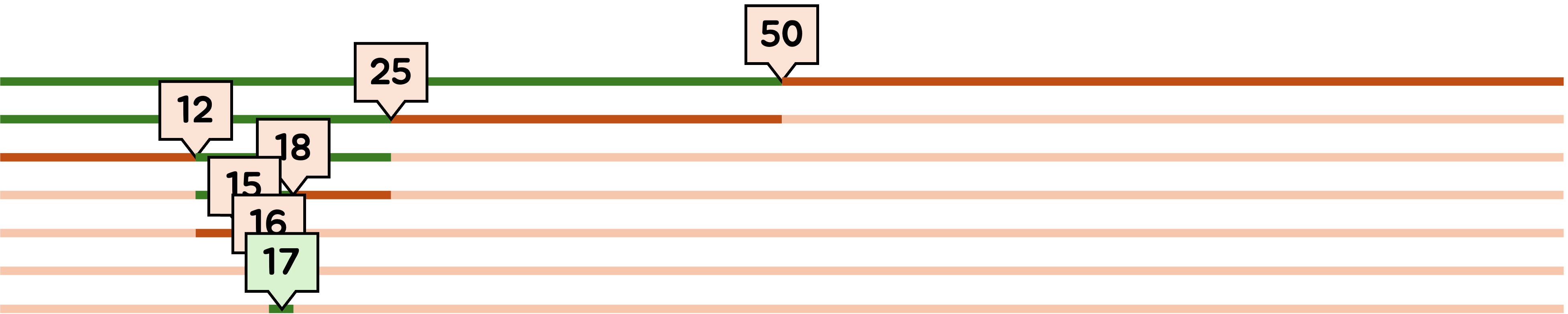
이분 탐색은 이처럼 범위를 이분하며 탐색하는 방법이에요.
정렬된 데이터를 탐색할 때, 범위를 절반씩 줄여나가며 찾고자 하는 요소를 찾아요.
🤔 분할 정복이란?
분할 정복은 어떤 문제를 같은 유형의 작은 문제들로 나누어 각각 해결하고 결과를 합하는 과정을 재귀적으로 반복해서 문제를 해결하는 접근법이에요.
이분 탐색은 탐색 범위를 줄인 후 다시 탐색을 진행하는 것을 반복하기 때문에 분할 정복에 속해요.
이분 탐색의 장점
이분 탐색은 선형 탐색에 비해 매우 효율적인 방법이에요.
선형 탐색은 최악의 경우, 의 시간이 걸려요.
그러나 이분 탐색은 어떠한 경우에도 의 시간을 보장해요.
| 선형 탐색 | 이분 탐색 | |
|---|---|---|
| 최적의 경우 | ||
| 최악의 경우 | ||
| 평균 |
⚠️ 참고해주세요!
이분 탐색을 하기 위해서는 데이터가 정렬되어 있어야 해요.
정렬되지 않은 경우, 범위를 줄일 때 어떤 부분에 대상 요소가 있는지 확신할 수 없기 때문이에요.
🧑💻 이분 탐색 구현하기
이분 탐색은 여러가지 유형이 있어요.
이 글에서는 세 가지 유형으로 구현했어요.
- 정확한 값 찾기
- 기준보다 크거나 같은 값 찾기 (Lower Bound)
- 기준보다 큰 값 찾기 (Upper Bound)
정확한 값 찾기
어떤 데이터에 특정 값이 있는지 찾을 때 사용하는 방법이에요.
이 방법은 탐색 도중 값을 발견하면 바로 탐색을 중단하도록 해 빠른 탐색이 가능해요.
다만, 중복된 값이 있는 경우 순서는 보장하지 않아요.
Python
def binary_search(arr, d):
left, right = 0, len(arr)
while left < right:
# 중간 인덱스 구하기
mid = left + (right - left) // 2
# 탐색 도중 요소 발견
if arr[mid] == d:
return mid
# 탐색 범위 줄이기
if arr[mid] < d:
left = mid + 1
else:
right = mid
# 값이 존재하지 않는 경우
return NoneRust
fn binary_search<T: Ord>(arr: &[T], d: T) -> Result<usize, usize> {
let (mut left, mut right) = (0, arr.len());
while left < right {
// 중간 인덱스 구하기
let mid = left + (right - left) / 2;
// 탐색 도중 요소 발견
if arr[mid] == d {
return Ok(mid);
}
// 탐색 범위 줄이기
if arr[mid] < d {
left = mid + 1;
} else {
right = mid;
}
}
// 값이 존재하지 않는 경우, Err와 함께 삽입 위치 반환
Err(left)
}Lower Bound
어떤 데이터에서 특정 값보다 크거나 같은 값의 위치를 탐색하는 방법이에요.
데이터의 삽입 위치를 찾거나, 중복된 값에서 가장 왼쪽의 요소를 찾아야 할 때 유용해요.
Python
def lower_bound(arr, d):
left, right = 0, len(arr)
while left < right:
# 중간 인덱스 구하기
mid = left + (right - left) // 2
# 탐색 범위 줄이기
if arr[mid] < d:
left = mid + 1
else:
right = mid
# 배열 범위를 넘어가면 None 반환
return left if left < len(arr) else NoneRust
fn lower_bound<T: Ord>(arr: &[T], d: T) -> Option<usize> {
let (mut left, mut right) = (0, arr.len());
while left < right {
// 중간 인덱스 구하기
let mid = left + (right - left) / 2;
// 탐색 범위 줄이기
if arr[mid] < d {
left = mid + 1;
} else {
right = mid;
}
}
// 배열 범위를 넘어가면 None 반환
if left < arr.len() {
Some(left)
} else {
None
}
}Upper Bound
어떤 데이터에서 특정 값보다 큰 값의 위치를 탐색하는 방법이에요.
중복된 값에서 가장 오른쪽의 요소를 찾아야 할 때 유용해요.
특히 Lower Bound와 같이 사용하면 특정 요소의 개수를 간단하게 구할 수 있어요.
💡 중복되는 요소의 개수 구하기
Upper Bound에서 구한 인덱스와Lower Bound에서 구한 인덱스를 빼면 요소의 개수를 빠르게 구할 수 있어요.
Python
def upper_bound(arr, d):
left, right = 0, len(arr)
while left < right:
# 중간 인덱스 구하기
mid = left + (right - left) // 2
# 탐색 범위 줄이기
if arr[mid] <= d:
left = mid + 1
else:
right = mid
# 배열 범위를 넘어가면 None 반환
return left if left < len(arr) else NoneRust
fn upper_bound<T: Ord>(arr: &[T], d: T) -> Option<usize> {
let (mut left, mut right) = (0, arr.len());
while left < right {
// 중간 인덱스 구하기
let mid = left + (right - left) / 2;
// 탐색 범위 줄이기
if arr[mid] <= d {
left = mid + 1;
} else {
right = mid;
}
}
// 배열 범위를 넘어가면 None 반환
if left < arr.len() {
Some(left)
} else {
None
}
}🔍 매개변수 탐색 (파라메트릭 서치)
매개변수 탐색은 최적화 문제를 결정 문제로 만들어 최적의 값을 이분 탐색의 원리를 이용해 최적의 답을 찾는 방법이에요.
🤔 최적화 문제란?
주어진 조건을 만족하면서, 어떤 목표의 최적의 값을 찾는 문제를 뜻해요.
최적의 값은 목표를 해결할 수 있는 값 중 최댓값·최솟값을 가지게 돼요.
🤔 결정 문제란?
특정 값으로 문제를 해결할 수 있는지 판단할 수 있는 문제를 뜻해요.
결정 문제의 답은true와false로 표현이 가능한, 논리적인 답이어야 해요.
매개변수 탐색은 세 단계로 구분할 수 있어요.
-
정답 범위 구하기
최적의 값이 존재할 수 있는 상한선과 하한선을 구해요. -
최적화 문제를 결정 문제로 바꾸기
최적화 문제를 결정 문제로 변환해요. -
이분 탐색의 원리로 최적의 값 구하기
범위의 중간값이 결정 문제를 해결하면 더 좋은 값이 속한 범위를, 해결하지 못한다면 반대를 선택해요.
범위 좁히기를 반복하면 최적의 값을 구할 수 있어요.
문제풀이 예시: 나무 자르기 (BOJ 2805)
- 문제 요약
다양한 높이의 나무들을 톱날의 높이 를 설정해서 자를 때, 잘려진 부분의 합이 이상이 되게 하는 의 최대값 구하기
- 입력
- 나무의 수 ()
- 필요한 나무의 길이 ()
- 나무 높이
- 출력
- 조건을 만족하는 톱날의 최대 높이
문제 해결 설계
나무 자르기 문제는 조건을 만족하면서 목표를 해결할 수 있는 값의 최댓값을 찾는 문제예요.
따라서, 매개변수 탐색으로 나무 자르기 문제를 해결할 수 있어요.
-
정답 범위 구하기
의 하한은 , 상한은 나무의 최대 높이인 으로 정할 수 있어요. -
최적화 문제를 결정 문제로 바꾸기
주어진 문제를 결정 문제로 바꾸면 아래와 같아요.임의의 높이 로 나무를 자를 때, 잘려진 부분의 합이 이상인가?
-
이분 탐색의 원리로 최적의 값 구하기
범위의 중간 값으로 나무를 자를 때 결정 문제가 참이 되는지 확인하고, 참이라면 더 높은 쪽을, 거짓이라면 더 낮은 쪽을 탐색해서, 1번에서 구한 범위를 점차 줄여가요.
해결 방법 검토
문제 해결의 시간 복잡도를 구해볼게요.
-
결정 문제를 확인하는 시간
결정 문제가 참인지 확인하기 위해서는 나무 배열을 순회하며 잘리는 부분의 합을 구해야 해요.
따라서 시간 복잡도는 이에요. -
범위를 줄여나가는 시간
이분 탐색의 시간 복잡도는 이에요.
따라서 범위를 N에 대입하면 으로 구할 수 있어요.
구한 시간들을 이용해 문제 해결 과정 전체의 시간 복잡도를 구하면 이고, 각 변수의 최댓값을 대입하면 이므로, 제한 시간 내에 최적의 값을 구할 수 있어요.
지금까지 이분 탐색의 개념과 여러 구현 방법을 알아봤어요.
이분 탐색은 데이터를 다룰 때 기본적으로 알아야 할 중요한 알고리즘이에요.
또한, 이분 탐색을 기본 원리로 하는 매개변수 탐색은 최적화 문제를 푸는 핵심적인 도구예요.
따라서 이 두 가지를 잘 배워 둔다면, 수많은 문제를 해결하는 데 큰 도움이 될 거에요.
다음에도 유익한 내용으로 찾아올게요! 😁
