
안녕하세요! 소리입니다 👋
이번 글에서는 구간 쿼리를 처리하기 위한 대표적인 자료구조인 세그먼트 트리(Segment Tree)에 대한 내용을 준비했어요.
🚀 세그먼트 트리란?
세그먼트 트리는 이진 트리를 사용해 구간의 연산 정보를 효율적으로 저장하는 자료구조예요.
구간에 대한 쿼리를 처리하거나 갱신하는 작업을 효율적으로 처리할 수 있어서 매우 많이 쓰여요.
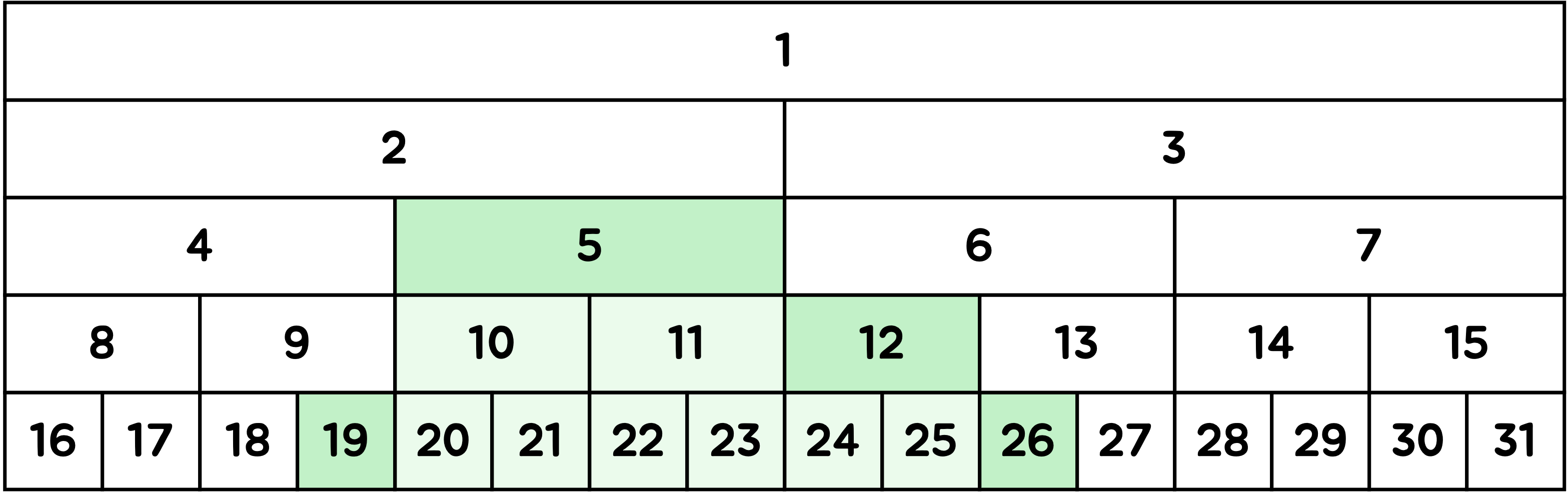
세그먼트 트리는 배열이나 부분합보다 효율적으로 연산을 처리할 수 있어요.
세그먼트 트리에서는 부모 노드가 자녀 노드의 값들을 대표하기 때문에, 모든 데이터를 확인하지 않고 필요한 구간을 대표하는 일부 노드만 확인하는 방법으로 값을 구할 수 있기 때문이에요.
| 배열 | 부분 합 | 세그먼트 트리 | |
|---|---|---|---|
| 쿼리 계산 | |||
| 갱신 |
연산
세그먼트 트리는 크게 구성, 쿼리, 갱신 단계로 나눌 수 있어요.
-
구성
구성 단계는 주어진 데이터를 이용해 세그먼트 트리를 구성하는 단계예요.
배열을 이용해 포화 이진 트리를 만든 후, 리프 노드에 데이터를 채우고 상위 노드의 값을 구하는 방법으로 구성 가능해요.이 과정은 데이터의 개수에 비례하므로, 의 시간이 소요돼요.

-
쿼리
구간에 대한 요청이 들어왔을 때, 세그먼트 트리를 탐색하며 쿼리의 값을 구하는 단계예요.요청을 처리할 때, 탐색 구간을 절반으로 나누며 처리하므로, 탐색 시간은 트리의 높이에 비례해요.
따라서 쿼리 단계를 처리하는 시간은 이에요. -
갱신
특정 데이터의 값 변경 요청이 들어왔을 때, 변경될 요소와 연관된 노드의 값을 변경하는 단계예요.갱신 단계에서 값이 변하는 노드 개수는 트리의 높이와 같아요.
따라서 갱신 단계를 처리하는 시간은 이에요.
구성 조건
세그먼트 트리는 구간에 대한 요청과 갱신이 동시에 존재하는 쿼리를 처리하는 작업에 용이하지만, 모든 데이터에 대해 사용할 수는 없어요.
세그먼트 트리를 사용하기 위해서는 데이터가 결합 법칙을 만족해야 해요.
🤔 결합 법칙이란?
결합 법칙은 연산이 반복될 때, 연산 순서와 상관없이 계산 후 같은 값을 도출하는 것을 말해요.
세그먼트 트리는 분할 정복의 원리로 구간 요청을 처리하기 때문에, 데이터가 결합 법칙을 만족해야 사용할 수 있어요.결합 법칙이 성립하는 대표적인 연산으로는 덧셈과 곱셈이 있어요.
- 덧셈의 결합 법칙
🧑💻 세그먼트 트리의 동작과 구현
세그먼트 트리는 대부분 배열을 이용해 구현해요.
세그먼트 트리는 이진 트리 형태 기반의 자료구조이기 때문이에요.
아래 예제에서는 구간에서의 최댓값을 구할 수 있는 세그먼트 트리를 구현해볼게요.
일반적인 구현
세그먼트 트리 구성
먼저 세그먼트 트리로 사용할 배열을 선언해요.
배열의 크기는 데이터를 저장할 수 있는 완전 이진 트리의 최솟값인 로 지정해요.
는 의 비트의 길이만큼 2를 왼쪽 시프트한 것과 같아요.
- 이라면,
그 후, 데이터를 세그먼트 트리의 리프 노드에 차례대로 저장해요.
세그먼트 트리 배열의 번 칸부터 리프 노드예요.
마지막으로 상위 노드의 값을 구해요.
이때, 리프 노드에서 가까운 노드들부터 구해야 해요.
// 데이터가 100,000개인 경우
let mut segtree = vec![0; 2 << 17];
// 데이터를 리프 노드에 저장
for i in 0..100000 {
segtree[i | 1 << 17] = data[i];
}
// 리프 노드의 상위 노드의 값 계산
for i in (1..1 << 17).rev() {
segtree[i] = segtree[i << 1].max(segtree[i << 1 | 1]);
}구간 쿼리 구하기
세그먼트 트리에서 구간의 최댓값을 구하는 함수를 설계해볼게요.
먼저 루트 노드부터 시작해서 노드가 주어진 구간 안의 범위인지 확인해요.
이때 경우의 수에 따라 동작이 나뉘어요.
-
노드가 구간 안에 속하는 경우
구간 안에 속한다면 노드의 값을 그대로 반환해요. -
일부가 겹치는 경우
일부만 겹친다면 자녀 노드로 내려가서 다시 범위를 확인해요.
이 과정은 재귀로 처리할 수 있어요. -
전혀 겹치지 않는 경우
범위 밖의 노드라면 항등원을 반환해요.
fn query(segtree: &[i32], left: usize, right: usize) -> i32 {
// 재귀용 함수 (left·right: 요청한 범위, start·end: 현재 노드의 담당 범위)
fn query_recursive(segtree: &[i32], left: usize, right: usize, idx: usize, start: usize, end: usize) -> i32 {
// 구간에 속하는 경우
if left <= start && end <= right {
segtree[idx]
}
// 일부만 겹치는 경우
else if start <= right && left <= end {
let mid = (start + end + 1) >> 1;
// 재귀로 자녀 노드 확인
let a = query_recursive(segtree, left, right, idx << 1, start, mid - 1);
let b = query_recursive(segtree, left, right, idx << 1 | 1, mid, end);
a.max(b)
}
// 전혀 겹치지 않는 경우
else {
// max 연산의 항등원 (n.max(i32::MIN) == n)
i32::MIN
}
}
// 루트 노드(1번 노드)에서부터 노드 확인
query_recursive(segtree, left, right, 1, 0, (1 << 17) - 1)
}데이터 갱신
세그먼트 트리에서 특정한 데이터를 변경하려면 리프 노드의 값을 변경한 후, 부모 노드로 이동하며 값을 새롭게 갱신해주면 돼요.

fn update(segtree: &mut [i32], idx: usize, val: i32) {
// 데이터가 위치한 리프 노드 인덱스
let mut idx = idx | 1 << 17;
segtree[idx] = val;
// 루트 노드까지 올라가며 노드 갱신
while idx > 1 {
idx >>= 1;
segtree[idx] = segtree[idx << 1].max(segtree[idx << 1 | 1]);
}
}구조체 구현
위에서 구현한 것을 바탕으로 범용적으로 사용 가능한 세그먼트 트리 구조체를 만들었어요.
struct SegmentTree<T, F> {
depth: usize, // ⌈log2(N)⌉ 값
tree: Vec<T>, // 세그먼트 트리 배열
default: T, // 연산의 항등원
operator: F, // 연산 함수
}
impl<T: Clone, F: for<'a, 'b> Fn(&'a T, &'b T) -> T> SegmentTree<T, F> {
// 구조체 생성 (size: 데이터 개수, default: 항등원, operator: 연산 함수)
fn new(size: usize, default: T, operator: F) -> SegmentTree<T, F> {
let depth = if size == 0 { 0 } else { (usize::BITS - (size - 1).leading_zeros()) as usize };
SegmentTree { tree: vec![default.clone(); 2 << depth], depth, default, operator }
}
// 세그먼트 트리 구성
fn init(&mut self, data: &[T]) {
for i in 0..data.len() {
self.tree[i | 1 << self.depth] = data[i].clone();
}
for i in (1..1 << self.depth).rev() {
self.tree[i] = (self.operator)(&self.tree[i << 1], &self.tree[i << 1 | 1]);
}
}
// 구간 쿼리 구하기
fn query(&self, left: usize, right: usize) -> T {
fn query_recursive<T: Clone, F: for<'a, 'b> Fn(&'a T, &'b T) -> T>(seg: &SegmentTree<T, F>, left: usize, right: usize, i: usize, range: Range<usize>) -> T {
if left <= range.start && range.end - 1 <= right {
seg.tree[i].clone()
}
else if range.start <= right && left < range.end {
let mid = (range.start + range.end) >> 1;
(seg.operator)(
&query_recursive(seg, left, right, i << 1, range.start..mid),
&query_recursive(seg, left, right, i << 1 | 1, mid..range.end)
)
}
else {
seg.default.clone()
}
}
query_recursive(self, left, right, 1, 0..(1 << self.depth))
}
// 데이터 갱신
fn update(&mut self, idx: usize, val: T) {
let mut idx = idx | 1 << self.depth;
self.tree[idx] = val;
while idx > 1 {
idx >>= 1;
self.tree[idx] = (self.operator)(&self.tree[idx << 1], &self.tree[idx << 1 | 1]);
}
}
}비재귀 세그먼트 트리
일반적으로 재귀 함수는 함수가 호출될 때마다 스택이 쌓이기 때문에 데이터 양이 많아지면 속도가 느려지거나 스택 오버플로우가 발생할 수 있어요.
따라서 비재귀적인 방법으로 구현하면 성능의 이점을 가져갈 수 있어요.
세그먼트 트리의 구간 쿼리 구하기를 비재귀로 구현할 수 있어요.
아래에서는 구간에서의 최댓값을 구할 수 있는 세그먼트 트리를 비재귀로 구현해볼게요.
구간 쿼리 구하기
구간 쿼리를 구할 때 필요한 노드를 재귀 없이 순회로 구할 수 있어요.
범위의 양 끝 노드부터 시작해서 범위를 훑는 방법이에요.
자세한 동작
이 방법은 left, right 두 개의 포인터를 이용해서 구해요.
먼저 두 개의 포인터를 리프 노드에서 양 끝 범위의 노드를 가리키도록 해요.
이제 두 개의 포인터가 서로 엇갈릴 때까지 다음 동작을 반복해요.
-
노드 포함 여부 판별
left포인터는 현재 층에서 범위의 가장 왼쪽의 노드를 가리켜요.
만약left포인터가 홀수 인덱스라면 현재 노드가 부모의 오른쪽 자녀라는 뜻이에요.
이 경우 부모 노드의 값은 범위를 벗어나는 값까지 포함하게 되므로 범위를 대표할 수 없는 값이에요.
따라서 현재 노드를 계산에 포함한 후,left포인터에 1을 더해야 해요.오른쪽도 마찬가지예요.
만약right포인터가 짝수 인덱스라면 현재 노드가 부모의 왼쪽 자녀라는 뜻이므로, 현재 노드의 값을 계산에 포함하고right포인터에 1을 빼야 해요.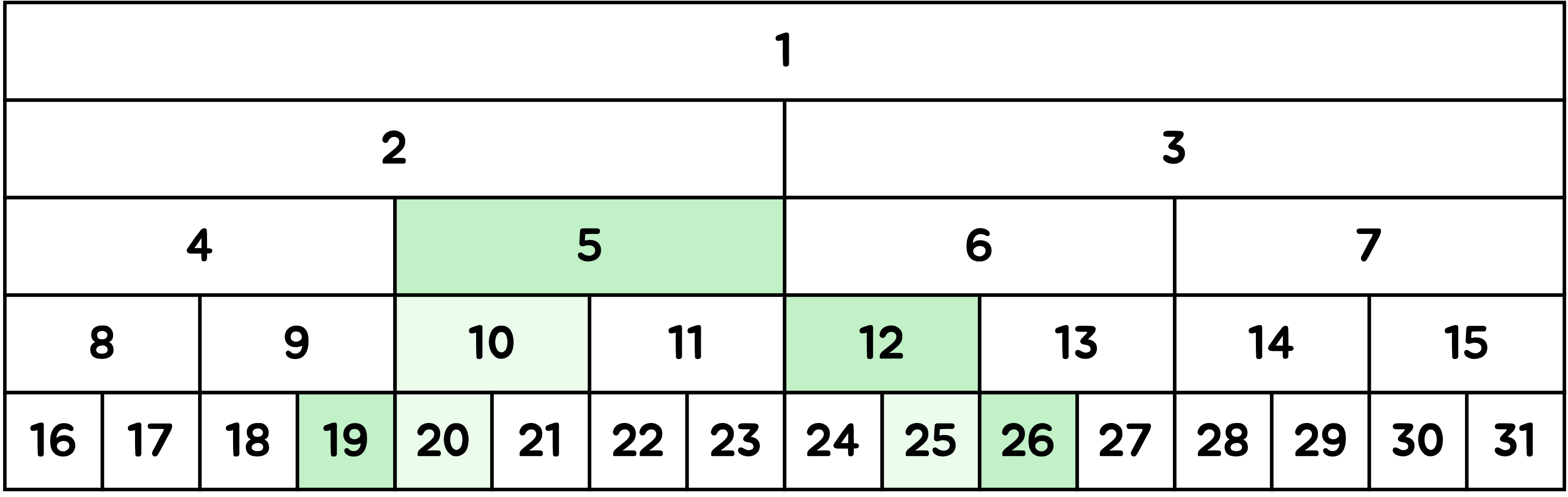
💡 자녀 노드가 어느 쪽인지 구하기
루트 노드의 인덱스를 1로 하는 배열 기반 완전 이진 트리에서는 항상 짝수 인덱스의 노드가 왼쪽, 홀수 인덱스의 노드가 오른쪽이에요.
-
포인터 이동
현재 층에서 계산이 완료되었으므로 포인터 값을 2로 나누어 각각의 부모 노드를 가리키도록 해요.
fn query(segtree: &[i32], left: usize, right: usize) -> i32 {
let mut left = left | 1 << 17;
let mut right = right | 1 << 17;
let mut res = i32::MIN;
// 두 포인터가 엇갈릴 때까지 진행
while left <= right {
// 왼쪽 포인터 노드의 인덱스가 홀수인 경우
if left & 1 == 1 {
res = res.max(segtree[left]); // 현재 노드를 계산에 포함
left += 1; // 인덱스 이동
}
// 오른쪽 포인터 노드의 인덱스가 짝수인 경우
if right & 1 == 0 {
res = res.max(segtree[right]); // 현재 노드를 계산에 포함
right -= 1; // 인덱스 이동
}
// 부모 노드로 이동
left >>= 1;
right >>= 1;
}
res
}지금까지 세그먼트 트리에 대해 알아봤어요.
세그먼트 트리는 고급 알고리즘과 자료구조를 학습하기 위한 관문이기도 해서 내용이 어려운 편이에요.
하지만 세그먼트 트리를 이해한다면 다양한 구간 쿼리 문제를 효율적으로 풀 수 있게 되는 등 얻게 되는 것이 많을 거에요.
다음에도 유익한 내용으로 찾아올게요! 😁
