우선순위 큐
우선순위 큐는 데이터를 꺼낼 때 항상 우선순위가 가장 높은 요소를 먼저 반환하는 추상 자료형이에요.
우선순위 큐에는 데이터와 상황에 따라 다른 기준의 우선도를 설정해 사용할 수 있어요.
경찰서에서는 민원 신고부터 경범죄, 중범죄까지 다양한 신고와 출동 요청을 받아요.
이때 요청을 일반적인 큐의 동작처럼 요청을 접수 순서대로 처리하면 긴급 출동해야 할 강력 범죄의 출동이 늦어질 수 있죠.
이럴 때 우선순위 큐를 사용할 수 있어요.
강력 범죄 신고처럼 빠른 출동이 필요한 요청에 우선순위를 높게 매겨 먼저 처리하도록 만들 수 있어요.
🤔 추상 자료형이란?
구현 방법의 정의 없이 기능만 정의된 자료구조를 추상 자료형(ADT)이라고 해요.
연산
대표적인 우선순위 큐의 연산은 push와 pop, peek 세 종류에요.
- 삽입 (push)
데이터를 우선순위 큐에 넣는 연산이에요. - 제거 (pop)
가장 우선순위가 높은 데이터를 큐에서 꺼내는 연산이에요. - 확인 (peek)
큐에서 가장 우선순위가 높은 데이터를 확인해요.
이 연산은 우선순위 큐의 상태를 변경하지 않아요.
리스트를 이용한 우선순위 큐 구현
큰 숫자일수록 우선순위를 높게 주는 우선순위 큐를 리스트를 이용해 구현해볼게요.
데이터의 삽입 위치를 이분 탐색으로 찾아 삽입하도록 만들어 정렬된 상태를 유지하도록 해, 동작을 최적화했어요.
이 방법은 힙 트리를 이용한 방법보다 비효율적이에요.
삽입 연산이 이루어질 때 오버헤드가 많고, 데이터 삽입이 만큼 걸리기 때문이에요.
리스트를 이용한 구현은 비교와 학습용으로만 사용하는 것을 추천해요.
| 구현 방법 | 삽입 연산 | 삭제 연산 | 확인 연산 |
|---|---|---|---|
| 리스트 | |||
| 힙 트리 |
Python
class PriorityQueue:
def __init__(self):
self.list = []
def push(self, data):
# 이분 탐색으로 데이터의 삽입 위치를 탐색
left, right = 0, len(self.list)
while left < right:
mid = (left + right) // 2
if self.list[mid] < data:
left = mid + 1
else:
right = mid
self.list.insert(left, data)
def pop(self):
return self.list.pop()
def peek(self):
return self.list[-1]Rust
struct PriorityQueue<T: Ord> {
list: Vec<T>,
}
impl<T: Ord> PriorityQueue<T> {
fn new() -> Self {
Self { list: Vec::new() }
}
fn push(&mut self, data: T) {
// 이분 탐색으로 데이터의 삽입 위치를 탐색
let (mut left, mut right) = (0, self.list.len());
while left < right {
let mid = (left + right) / 2;
if self.list[mid] < data {
left = mid + 1;
} else {
right = mid;
}
}
self.list.insert(left, data);
}
fn pop(&mut self) -> Option<T> {
self.list.pop()
}
fn peek(&self) -> Option<&T> {
self.list.last()
}
}힙 트리
위에서 잠깐 설명했듯이, 우선순위 큐를 리스트를 이용해 구현하면 삽입 과정이 오래 걸려요.
데이터의 삽입이 많아질 때 성능이 낮아지게 되죠.
이 문제는 힙 트리를 사용해서 해결할 수 있어요.
힙은 부모 노드가 자녀 노드보다 항상 우선순위가 높도록 구성된 완전 이진 트리 구조를 말해요.
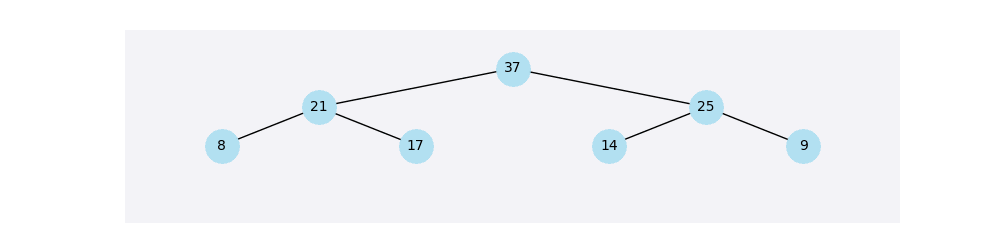
위 사진은 높은 값의 데이터에 우선순위를 높게 주는 최대 힙 트리의 예시예요.
힙 트리의 루트 노드는 항상 우선순위가 가장 높은 노드예요.
이 성질을 이용해 우선순위 큐를 만들 수 있어요.
힙 트리의 내부 연산
힙 트리의 노드 추가·삭제가 이루어지거나, 노드의 데이터가 수정되면 변화된 구조를 다시 힙 속성에 맞게 조정해야 해요.
힙 속성이 깨질 때, 다시 속성을 복원하기 위해 내부적으로 사용하는 연산이 두 가지 있어요.
-
노드 올리기 (sift-up)
특정 노드를 위로 올려 힙 속성을 유지하도록 하는 연산이에요.
특정 노드가 부모 노드보다 우선순위가 높을 때, 부모 노드와 위치를 바꿔요.아래 이미지는
최대 힙속성이 깨진 트리를25노드를 올려 복원하는 모습이에요.
-
노드 내리기 (sift-down)
특정 노드를 아래로 내려 힙 속성을 유지하도록 하는 연산이에요.
특정 노드가 자녀 노드보다 우선순위가 작을 때, 해당 자녀 노드와 위치를 바꿔요.
이때 위치가 바뀌는 자녀 노드는 자녀 노드 중에서 우선순위가 높은 노드로 선택해야 해요.아래 이미지는
최대 힙속성이 깨진 트리를25노드를 내려 복원하는 모습이에요.
힙 트리를 이용한 우선순위 큐 구현
힙 트리로 구현하면 삽입 연산을 훨씬 빠르게 만들 수 있어요.
힙 트리에서 힙 속성 복원을 위해 노드를 움직일 때, 한 노드가 이동하는 최대 거리는 트리의 높이예요.
따라서 힙 트리에 노드가 새로 추가될 때, 번의 노드 교환으로 힙 속성을 복원할 수 있어요.
🧐 완전 이진 트리를 배열로 표현하는 방법
완전 이진 트리를 배열로 표현하면 구현이 쉽고, 오버헤드를 최소화해서 성능을 향상할 수 있어요.
트리를 연결 리스트 방법으로 구현하면, 노드를 연결하는 포인터를 저장하기 위해 많은 양의 메모리를 사용하게 돼요.
그러나 배열을 사용하면, 포인터 없이 간단한 산술 연산으로 연결된 노드로 이동할 수 있어요.루트 노드를 0번 인덱스로 지정하면 다음 산술 연산이 성립해요.
- 현재 노드:
i
부모 노드 왼쪽 자녀 노드 오른쪽 자녀 노드

Python
class HeapTree:
def __init__(self):
self.tree = []
def sift_up(self, index):
child = index
while child > 0:
parent = (child - 1) >> 1
# 이미 힙 속성을 충족하는 경우
if self.tree[parent] >= self.tree[child]:
break
# 노드 교환
self.tree[parent], self.tree[child] = self.tree[child], self.tree[parent]
child = parent
def shift_down(self, index):
parent = index
child = (index << 1) + 1
while child < len(self.tree):
# 자녀 노드 중 우선순위가 높은 것 선택
if child + 1 < len(self.tree) and self.tree[child] < self.tree[child + 1]:
child += 1
# 이미 힙 속성을 충족하는 경우
if self.tree[parent] >= self.tree[child]:
break
# 노드 교환
self.tree[parent], self.tree[child] = self.tree[child], self.tree[parent]
parent = child
child = (parent << 1) + 1
class PriorityQueue():
def __init__(self):
self.heap = HeapTree()
def push(self, data):
# 노드 추가 후 노드 올리기 연산 수행
self.heap.tree.append(data)
self.heap.shift_up(len(self.heap.tree) - 1)
def pop(self):
if not self.heap.tree:
raise IndexError("PriorityQueue is empty")
# 루트 노드를 끝 노드와 교체 후 끝 노드 제거 및 반환
# 이후 루트 노드에 대해 노드 내리기 연산 수행
self.heap.tree[0], self.heap.tree[-1] = self.heap.tree[-1], self.heap.tree[0]
result = self.heap.tree.pop()
self.heap.sift_down(0)
return result
def peek(self):
if not self.heap.tree:
raise IndexError("PriorityQueue is empty")
return self.heap.tree[0]Rust
struct HeapTree<T: Ord> {
tree: Vec<T>,
}
impl<T: Ord> HeapTree<T> {
fn new() -> Self {
Self { tree: vec![] }
}
fn shift_up(&mut self, index: usize) {
let mut child = index;
while child > 0 {
let parent = (child - 1) >> 1;
// 이미 힙 속성을 충족하는 경우
if self.tree[parent] >= self.tree[child] {
break;
}
// 노드 교환
self.tree.swap(parent, child);
child = parent;
}
}
fn shift_down(&mut self, index: usize) {
let mut parent = index;
let mut child = (index << 1) + 1;
while child < self.tree.len() {
// 자녀 노드 중 우선순위가 높은 것 선택
if child + 1 < self.tree.len() && self.tree[child] < self.tree[child + 1] {
child += 1;
}
// 이미 힙 속성을 충족하는 경우
if self.tree[parent] >= self.tree[child] {
break
}
// 노드 교환
self.tree.swap(parent, child);
parent = child;
child = (parent << 1) + 1;
}
}
}
struct PriorityQueue<T: Ord> {
heap: HeapTree<T>,
}
impl<T: Ord> PriorityQueue<T> {
fn new() -> Self {
Self { heap: HeapTree::new() }
}
fn push(&mut self, value: T) {
// 노드 추가 후 노드 올리기 연산 수행
self.heap.tree.push(value);
self.heap.shift_up(self.heap.tree.len() - 1);
}
fn pop(&mut self) -> Option<T> {
if self.heap.tree.is_empty() {
return None;
}
// 루트 노드를 끝 노드와 교체 후 끝 노드 제거 및 반환
// 이후 루트 노드에 대해 노드 내리기 연산 수행
let result = self.heap.tree.swap_remove(0);
self.heap.shift_down(0);
Some(result)
}
fn peek(&self) -> Option<&T> {
self.heap.tree.first()
}
}지금까지 우선순위 큐와 힙 트리에 대해 알아보고, 리스트와 힙을 사용한 우선순위 큐 구현을 알아봤어요.
우선순위 큐는 다익스트라와 같은 중요한 알고리즘에 사용되는 추상 자료형이에요.
그리고 힙 트리는 우선순위 큐를 가장 효율적으로 구현할 수 있는 자료구조예요.
따라서 두 자료구조에 대해 이해하는 것은 알고리즘 학습에서 매우 중요해요.
다음에도 유익한 내용으로 찾아올게요! 😁
