SQL을 공부하면서 COUNT(restaurant_name) - COUNT(DISTINCT restaurant_name)을 써야 할 것 같았는데, 전혀 예상치 못한 결과가 나왔던 경험이 있나요? 저도 처음에는 헷갈렸지만, 이제는 COUNT()와 GROUP BY의 작동 원리를 이해하게 되었어요. 이 글에서는 제가 배운 내용을 공유합니다!
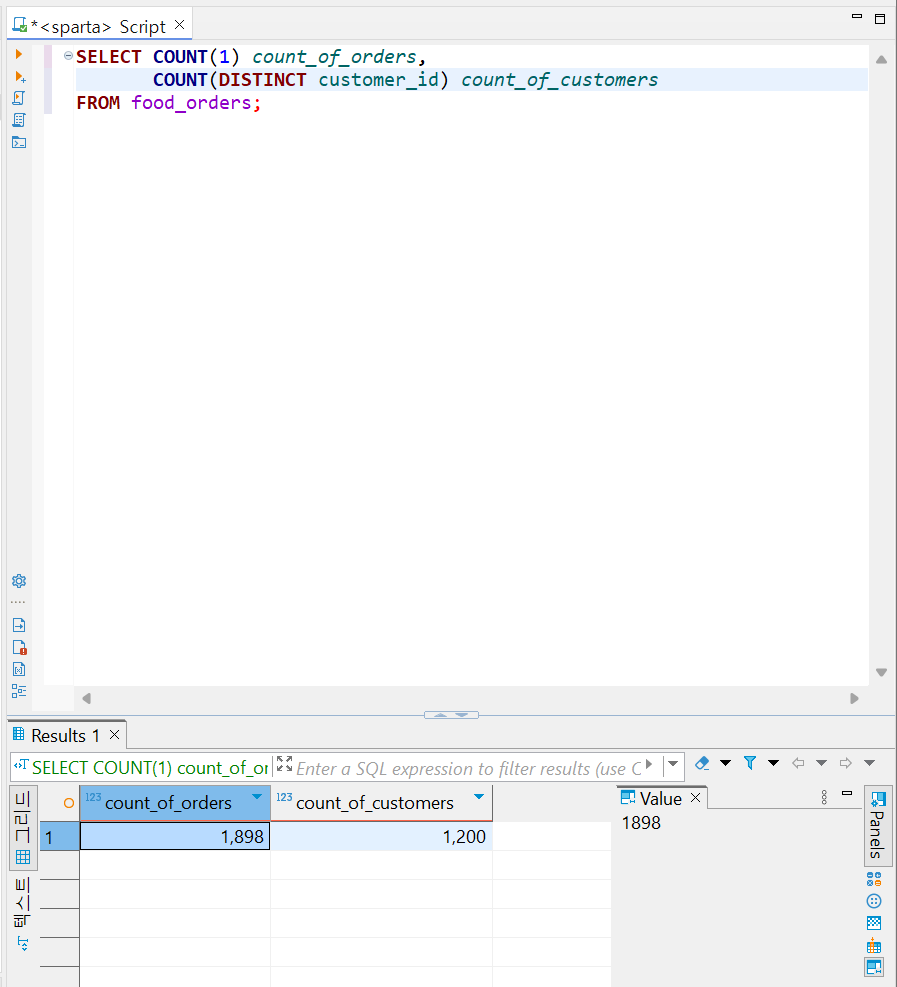
위 이미지를 설명하겠습니다.
1. COUNT( 1 ) === COUNT( * )
1과 별( * )은 전체라는 뜻입니다.
2. DISTINCT
그냥 전체 값은 1,898개이고 DISTINCT 값은 1,200개입니다. DISTINCT는 밑과 같은 뜻을 갖고 있습니다.
DISTINCT를 이용하면 중복되는 값을 제외하고, 진짜 실제 ID가 몇개가 있는지 확인할 수 있습니다.
🧠 COUNT() 함수의 동작 원리
SQL에서 데이터를 집계할 때 흔히 COUNT()를 사용합니다. 하지만 아래와 같은 코드가 헷갈릴 수 있죠.
SELECT COUNT(restaurant_name) - COUNT(DISTINCT restaurant_name) AS result
FROM food_orders;이 코드가 의미하는 바는 중복된 restaurant_name의 수를 계산하는 것입니다. 하지만 우리가 원한 것은 각 음식점(이름+지역+종류)별 주문 수였죠. 따라서 이 코드는 우리가 의도한 결과를 내지 않습니다.
📍 올바른 코드: COUNT(*)
SELECT CONCAT('[', SUBSTR(addr, 1, 2), ']', restaurant_name, '(', cuisine_type, ')') AS restaurant_info,
COUNT(*) AS number_of_orders
FROM food_orders
GROUP BY restaurant_info;이 코드가 올바른 이유:
GROUP BY restaurant_info: 동일한 음식점 정보(지역, 이름, 종류)를 하나의 그룹으로 묶음.COUNT(*): 해당 그룹의 모든 주문 건수를 세는 함수.
⚠️ 오해 주의:
COUNT(1)과COUNT(*)은 성능상의 차이가 거의 없습니다. 단순히 가독성의 차이일 뿐이죠.
🔍 GROUP BY 1이란?
SQL에서 GROUP BY 1은 SELECT 절의 첫 번째 컬럼을 기준으로 그룹화하라는 의미입니다.
다음 쿼리를 보세요:
SELECT CONCAT('[', SUBSTR(addr, 1, 2), ']', restaurant_name, '(', cuisine_type, ')'),
COUNT(*) AS number_of_orders
FROM food_orders
GROUP BY 1;여기서 GROUP BY 1은 SELECT 절의 첫 번째 컬럼인 음식점 정보 컬럼을 기준으로 그룹을 만드는 것입니다.
⚙️ SQL 작동 흐름:
SELECT절의 첫 번째 컬럼(음식점 정보)을 추출.- 같은 음식점 정보는 같은 그룹으로 묶음.
- 그룹별로
COUNT(*)를 통해 주문 건수를 셈.
💡 TIP: 나중에 코드를 읽을 때 헷갈리지 않도록 GROUP BY restaurant_info처럼 컬럼명을 명시하는 것을 권장합니다.
🧪 예제와 시각적 이해
food_orders 테이블이 이렇게 구성되어 있다고 가정해요:
| addr | restaurant_name | cuisine_type | order_id |
|---|---|---|---|
| 서울시 강남구 | 김밥천국 | 한식 | 1 |
| 서울시 강남구 | 김밥천국 | 한식 | 2 |
| 서울시 강남구 | 김밥천국 | 한식 | 3 |
| 부산시 해운대 | 피자헛 | 양식 | 4 |
| 부산시 해운대 | 피자헛 | 양식 | 5 |
이제 위의 쿼리를 실행하면 결과는 다음과 같습니다.
| restaurant_info | number_of_orders |
|---|---|
| [서울]김밥천국(한식) | 3 |
| [부산]피자헛(양식) | 2 |
⚠️ 흔한 오해: COUNT(restaurant_name) - COUNT(DISTINCT restaurant_name)
처음에는 중복 제거를 위해 이 로직을 사용해야 한다고 생각할 수 있어요:
SELECT COUNT(restaurant_name) - COUNT(DISTINCT restaurant_name)
FROM food_orders;그러나 이 코드는 중복된 음식점 이름의 수를 계산할 뿐입니다. 우리가 구하려는 주문 건수와는 전혀 다른 값이죠.
📌 이 로직이 잘못된 이유
COUNT(restaurant_name): 음식점 이름이 있는 모든 행 수를 계산 (모든 주문 수).COUNT(DISTINCT restaurant_name): 음식점 이름의 고유 개수를 계산 (음식점의 수).- 결과: 중복된 음식점 수 = 주문 수가 아님!
🚀 마무리: COUNT와 GROUP BY는 이렇게 이해하자!
COUNT(*)와COUNT(1): 동일하게 행 수를 세는 함수로, 그룹 내 주문 건수를 세는 데 사용.GROUP BY 1: SELECT 절의 첫 번째 컬럼을 기준으로 그룹화. 헷갈리면 컬럼 이름을 직접 명시.COUNT(column) - COUNT(DISTINCT column): 중복된 값의 개수를 구하는 로직으로, 주문 건수를 계산하는 데는 적절하지 않음.
이제는 SQL COUNT()와 GROUP BY의 작동 원리를 제대로 이해하게 되었어요. 여러분도 이 글을 읽고 나면 GROUP BY와 COUNT()의 관계를 더 쉽게 이해하길 바랍니다! 😊
