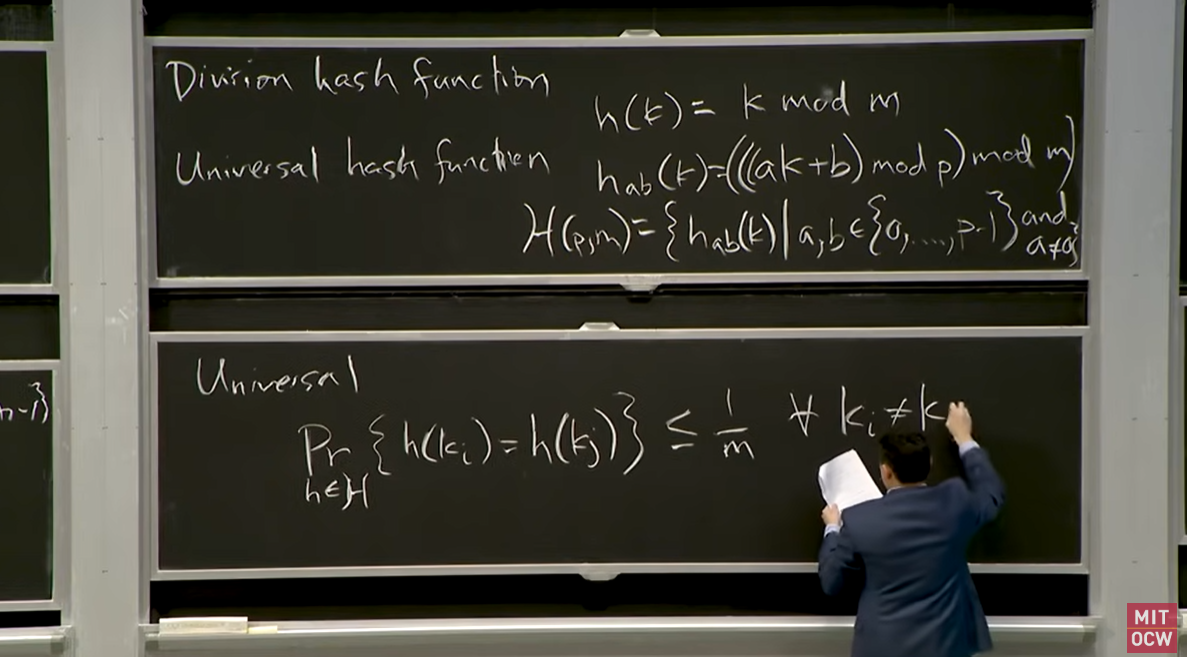
여기에 정리할 요약 노트의 원 강의는 MIT 6.006 Introduction to Algorithms, Spring 2020이다.
Comparison Model
A comparison model or comparison tree consists of internal nodes, each of which represents comparison operation, and leaves, each of which represents the final result of the operations, or, an item selected from the n items stored in a data structure. This is essentially a binary tree in that after an operation, based on whether the result is true or false, it decides whether to branch to this next node or the other one. Thus, each model should have n + 1 leaves because the model should be able to present any item off the n items and a situation where the value user is looking for doesn’t exist in the n items. The height of the tree means the number of operations that need to be done to get to the final result. The minimal height of a comparison tree is θ(log n)
Is there any way to make the height shorter than θ(log n)?
Direct Access Array/Hash Table in RAM
Suppose you have an array and an item with a key whose value is 10. You just store the item at the 10th index of the array. The find and insertion time will be constant but the length of an array can get exponentially big if the values of the keys are huge. Adding to that, if items are stored non-continuously, finding the next element will take extra time.
Hashing
Instead of having an array with the height as same as the size of the largest key, you cram the u amount of keys into an array whose length is m or θ(log n), n being a smaller number than u. Storing more than two items at a same index is inevitable, thus, the question regarding efficiency in searching is how to evenly distribute keys over the array. A hash function is a function which compresses the universe of keys from 0 to u-1 to that of 0 to m-1.
One way to handle a collision where more than two keys need to be put in the same place is open addressing, which simply put, is to store the other key in a place yet to be occupied. This is possible when m is larger than n. Another way is to have a pointer to some other data structure where you can store different keys that could have been stored at the same index. To find a key on the array, first you have to go to that index and loop up the data structure the index is pointing at. This method is called chaining and each data structure that stores keys, or, chains should be kept to a small size so that searching for a key won’t take too much time. If we add more keys to the array, meaning we grow n and a once fixed m in return, m will stop being linear in n. Then, all you need to do is to rebuild the entire hash table with a new m.
Division hash function, h(k) = k mod m, mingled with some other extra steps, is used by Python and other languages for hashing. To guarantee all the keys get stored in one place given that the size of the universe of keys is huge, you can also choose which hash function to use after the user picks input. Universal Hash functions are non-deterministic or not fixed hash functions that can provide a family of hash functions to choose from. This notion adds randomness to the whole process.
