음악 딥러닝과 데이터
음악 딥러닝에 사용되는 데이터는 2가지로 MFCC와 mel-spectrogram이 있다. 요즘엔 mel-spectrogram이 자주 사용되기 때문에 mel-spectrogram에 대해서 설명할 것 이다.
mel-spectrogram과 음악이론
mel-spectrogram에 대해서 찾아보면 대부분 나오는 설명은 '주파수를 인간의 인식에 맞게 바꾼 데이터' 정도로 설명하고 있다. 사실 처음 배우는 입장에선 짜증하는 설명이다. 인간의 인식이 무엇인지 설명하지 않고 주파수와 인간의 인식의 관계 또한 설명이 부실하다.
여기서 인간의 인식이란 바로 음악 이론을 말한다. 인간은 어떤 음을 듣던지 12개중 하나의 패턴으로 인식한다. 그게 누구나 초등학교때 부터 배워온 계이름이란 음악 이론이다. 계이름은 도레미파솔라시도 7개의 온음과 그 사이의 5개의 반음, 주로 사용되는 표기로 A,B,C,D,E,F,G 7개의 온음, A#, C#, D#, F#, G# 5개의 반음, 총 합쳐서 12개로 구성되어 있다. 다시 한 번 말하지만 인간은 어떤 소리를 듣던지 위의 12개의 음들 중 하나로 인식한다.
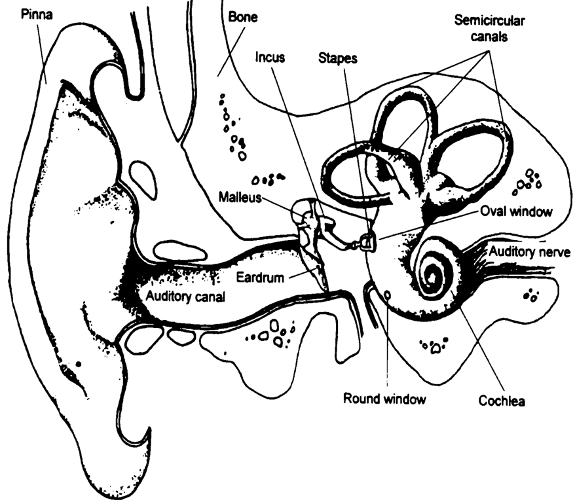
인간의 귀의 구조
왜 그럴까? 딥러닝에서 중요한 건 아니지만 허세용 지식으로 인간의 귀의 구조에 대해서 알아보자.
인간의 귀가 소리를 들으면 막이 진동해서 신경에 전달되고 그걸 소리로 인식하는 데 이걸 기저막이라고 부른다. 고주파는 기저 부근에서 최대 변위를 만들고 저주파는 기저막의 말단 부근에서 최대 변위를 만들어서 일종의 bandpass-filter의 역할을 하게 된다. 이런 구조 때문에 인간은 어떤 음을 듣던 12개 중 하나로, 그 음들의 간격은 선형적으로 인식하게 된다.
음악
음악 이론은 이 12개의 음들을 조합시켜서 어떤 느낌이 드는지 정리해논거다. 클래식부터 블루스, 락, 재즈 등의 음악 장르가 발전하면서 정말 수 많은 음조합이 나왔는데 너무 많아서 아무 음들을 뽑아서 몇 개 조합시켜도 이론이 존재할 정도다.
음악 이론이 왜 중요하냐면 소리를 분석할 때 크기, 음높이, 음색을 이용하는 데 음높이와 음색이 주파수에 관한 특징이고 주파수의 이론이 바로 음악 이론이기 때문에 중요하다.
예를 들어서 평소 목소리와 평소와 다른 목소리의 화음 관계로 감정을 추측할 수 있다. 조금 낮아진 주파수가 평소 목소리와 마이너의 관계를 가진다면 슬픈 감정, 살짝 고조된 주파수와 빠른 리듬을 듣고 화난 감정을 알아차릴 수 있다. 앞으로 음성 인식이 발달된다면 이런 특징을 이용해 사용자의 감정을 헤아릴 수 있는 AI가 나올 수 있다.
다음 글에서 소리의 물리적인 특성을 음악이론과 비교하며 mel-spectrogram이 왜 나왔는지 서술하겠다.
