음악 딥러닝과 mel-spectrogram
1.음악 딥러닝과 mel-spectrogram

앞으로 쓸 글 들은 음악, 음성 딥러닝에 사용되는 Mel-spectrogram을 공부하고 얻어낸 결과를 정리한 것 들이다. 학사 졸업논문을 작성하며 밴드 악기 분류 딥러닝 모델을 세우고 Mel-spectromgram의 특성을 알아내었다. 차근차근히 이론, 데이터 프로세
2.이 글 시리즈 소개
시리즈를 보며 주의할 점 음악 딥러닝에 대한 이론편 음악 딥러닝에 맞는 데이터 가공과 실제 CNN 프로젝트
3.mel-spectrogram과 음악이론(1)
음악 딥러닝에 사용되는 데이터는 2가지로 MFCC와 mel-spectrogram이 있다. 요즘엔 mel-spectrogram이 자주 사용되기 때문에 mel-spectrogram에 대해서 설명할 것 이다. mel-spectrogram에 대해서 찾아보면 대부분 나오는 설명
4.mel-spectrogram과 음악이론(2)
저번 글에 인간은 소리를 음계로 듣고 음계는 선형적이라고 밝혔다. 사실 주파수의 물리적 특성과는 많이 다르다. 음계를 물리적으로 분석해 보면 한 옥타브를 올릴 때마다 주파수가 2배가 되는 것을 알 수 있다. 옥타브 사이의 12개의 음계는 이걸 지수함수적으로 12등분 한
5.푸리에 변환 - (1)
옛날엔 물리하던 사람이 수학하고 수학하던 사람이 물리하고 그랬다.푸리에도 현의 진동 문제와 열의 흐름에 대해 연구하다가 파동을 급수로 표현하는 걸 발견했다. 그래서 푸리에 변환을 이해하기 위해선 물리적인 현상인 진동하는 현을 예시로 들면 쉽다.정상파와 진행파를 생각하면
6.푸리에 변환 - (2)
물리에서 파동을 입문할 때 단순 조화운동을 이용해서 개념을 확장시켜나간다. 최소 작용의 원리라고 물리현상의 방정식을 알아내는 만능 툴이 있다. 물론 물리 전공생이 아니면 알 필요가 없어서 뉴턴의 방정식을 이용해서 설명하겠다. 조화진동자는 변위에 따라서 힘이 변하는 운동
7.푸리에 변환 - (3)
물리 현상을 분석할 때 변수로 쓰이는 게 시간과 공간이다. 파동도 예외는 아니여서 파동을 나타내는 방정식엔 변위에 관한 식, 시간에 관한 식이 포함되어야 한다. 정상파는 옆으로 움직이지 않고 제자리에서 위아래로 움직이는 파동처럼 보인다.이걸 수학적으로 표현하면 파동을
8.푸리에 변환 - (4)
이전 푸리에 변환을 설명하는 글 들에서 정상파와 이동하는 파동들에 대해서 간단히 설명했다. 물리는 우아한 식을 만들고 싶어해서 정상파든 이동하는 파동이든 하나의 방정식으로 나타내길 원한다. 파동의 시간의 미분방정식을 풀면 ψ(t) = Asinmt + Bcosmt파동의
9.신호 처리
앞에 시리즈에서 푸리에 해석 진짜 길게도 써놨다. 물리와 수학에 관심 없는 사람을 위해서 다 빼고 결과만 간단하게 썼는 데 이거 왜 쓸까?클로바 같은 음성인식 인공지능이나 음악 딥러닝 같은 거에 쓰이는 데이터는 당연히 음원파일이다. 보통 wav파일을 mel-spectr
10.악기분류 딥러닝을 만들기 전에
딥러닝은 데이터를 확보하는 게 제일 중요하다. 뭐? 데이터를 확보하는 게 가장 중요하다. 뭐? 데이터를 확보하는 게 가장 중요하다. 뭐? 데이터를 확보하는 게 가장 중요하다. 뭐? 데이터를 확보하는 게 가장 중요하다. 뭐? 데이터를 확보하는 게 가장 중요하다. 뭐? 데
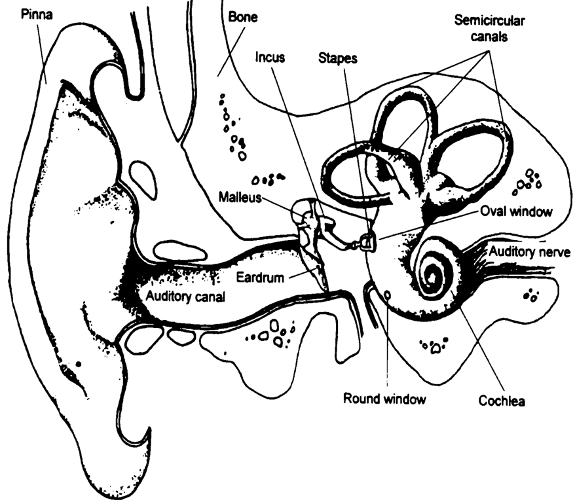
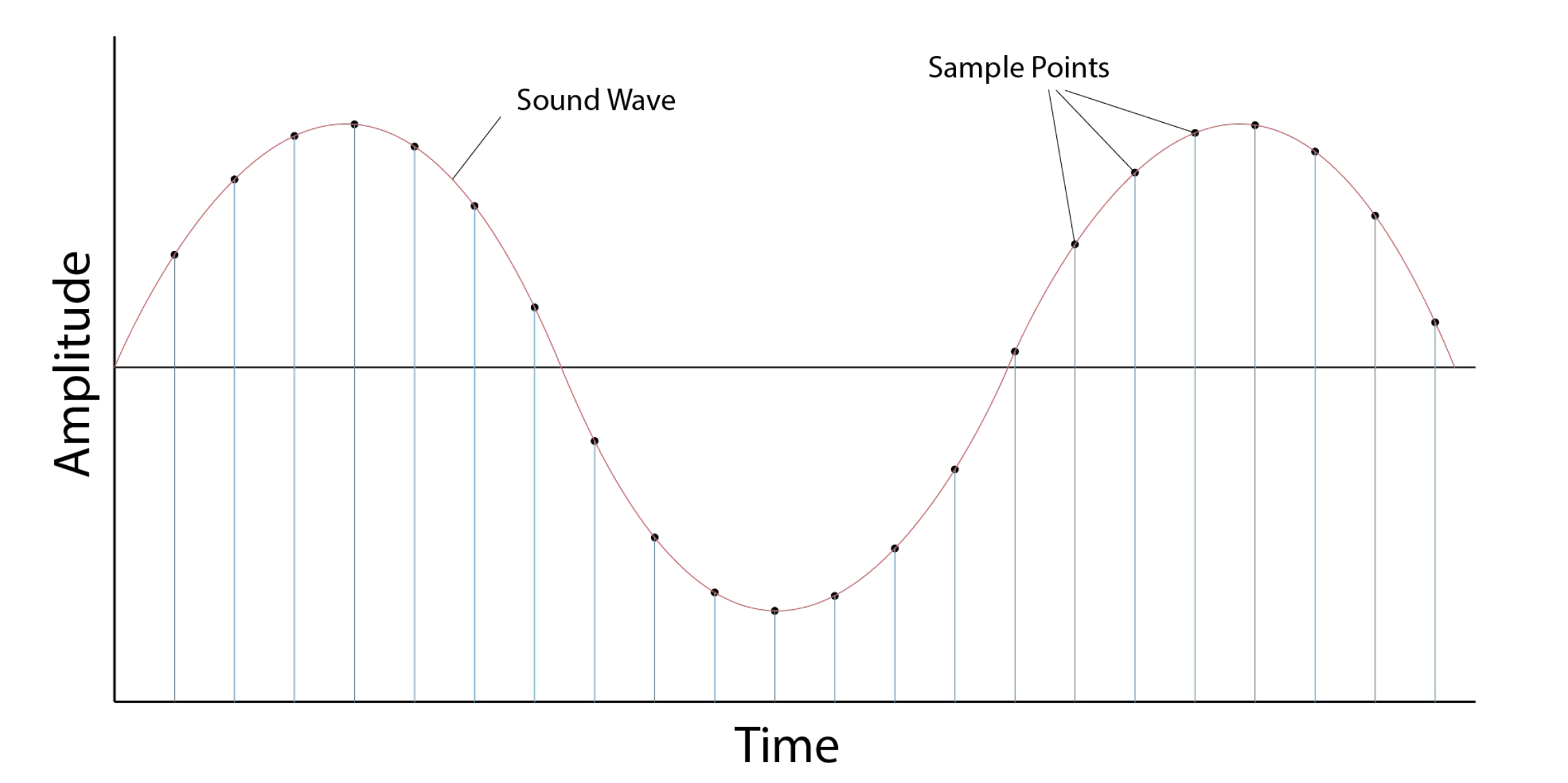
11.오디오 신호의 이해 - 1
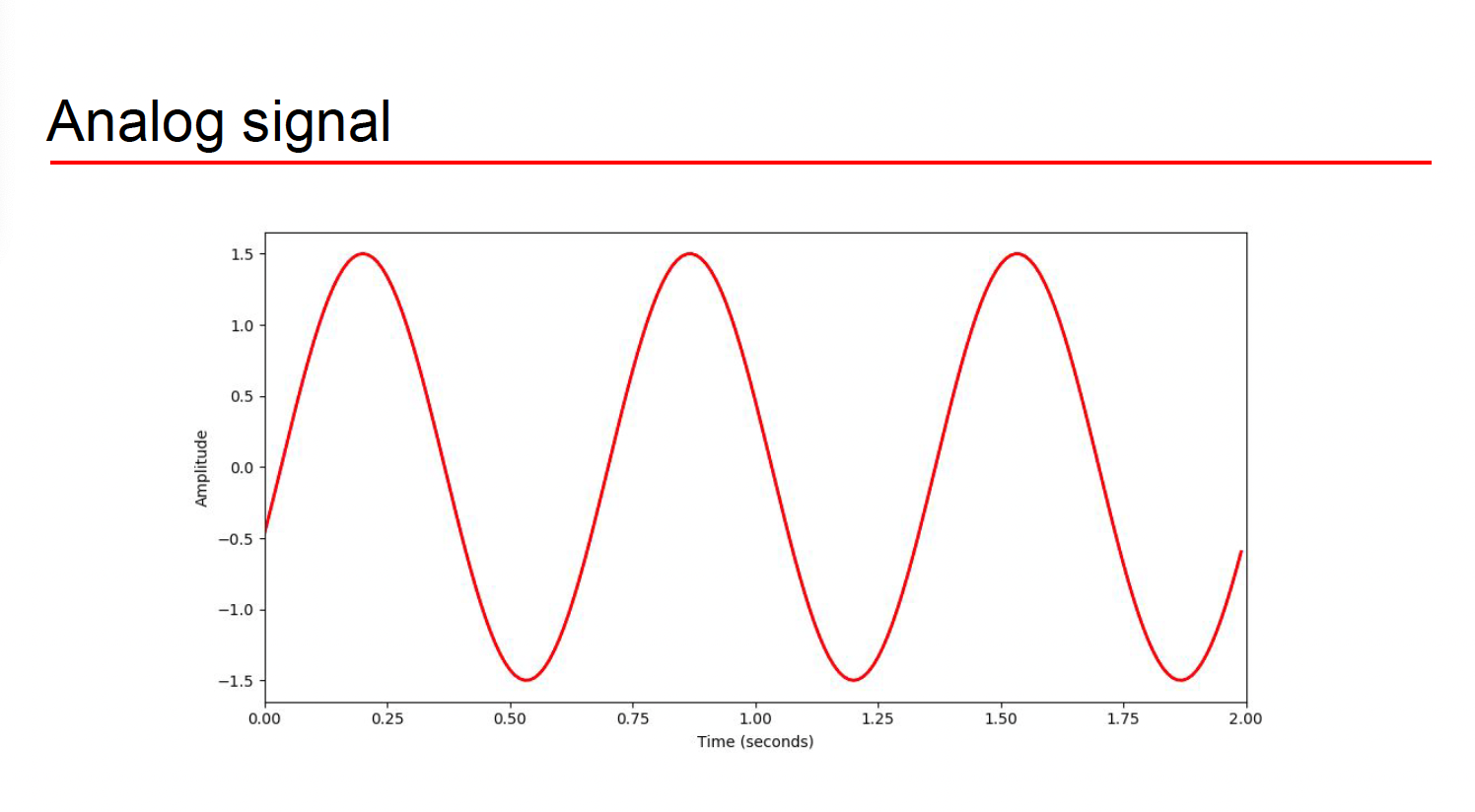
우리가 일상 생활에서 발생하는 신호를 analog signal이라고 한다. 일상의 모든 소리는 파동이 연속적이다. 위 그림을 보라 이상적이고 연속적이고 매끄러운 데이터이다. 이런 일상적인 파동은 연속적이고 미분가능해서 푸리에 변환에 큰 무리가 없다. 근데 문제가 기계의
12.오디오 신호의 이해 - 2
frames 저번 시간에 음원 파일을 존나 나눈것을 샘플링이라고 했다. 그럼 우리가 분석을 할 때 샘플링 하나하나를 모두 분석을 할까? 샘플링은 음원을 존나 나눈것이라 작다. 아무래도 샘플 하나만을 분석하기엔 너무 작으니 샘플을 모아서 덩어리처럼 구간별로 다루는게 좋
13.librosa 설치
아나콘다 기준으로 설명하겠다.터미널에 다음과 같이 입력해주면 된다.
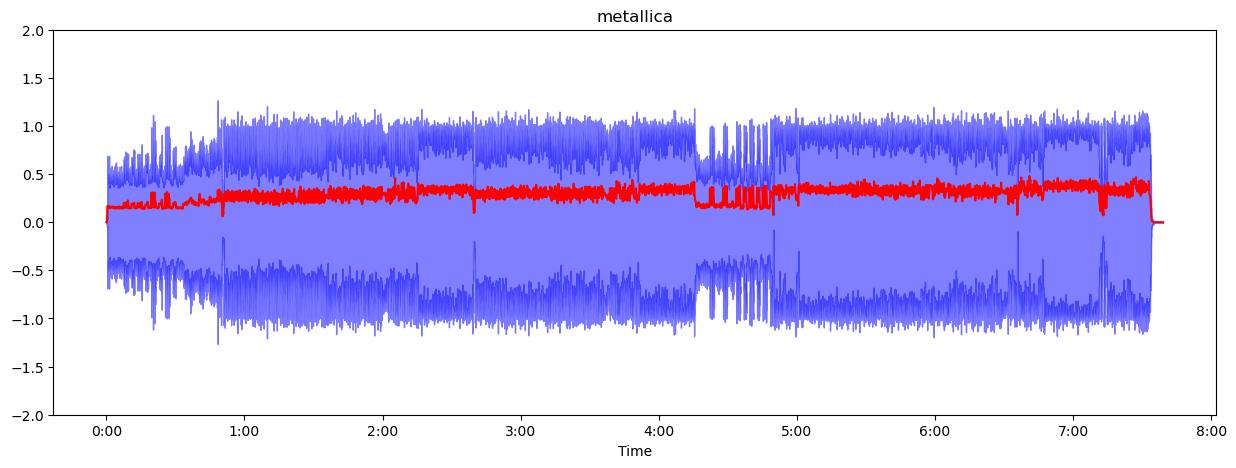
14.오디오 신호의 이해 - time domain features
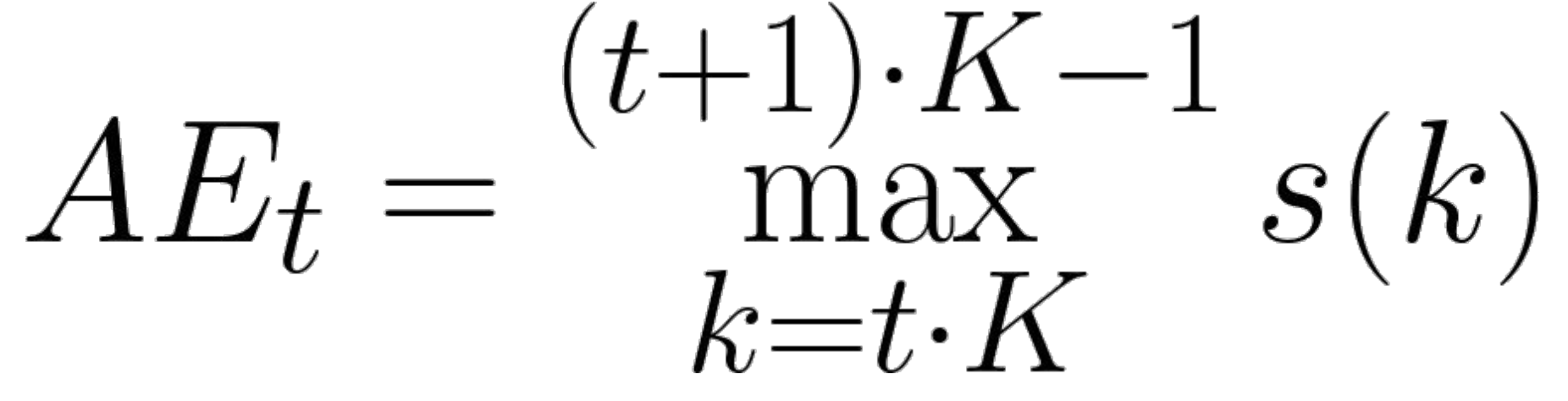
프레임의 샘플 중에 가장 aplitude가 높은 값을 말한다.좌변은 프레임t에서 가장 높은 값을 의미한다. 우변은 프레임의 첫 번째 샘플부터 마지막 샘플까지 샘플의 aplitude중에서 최대값을 찾는 식이다.예제로 위의 파형에서 프레임을 나눴을 때 가장 높은 ampli
15.librosa로 amplitude envelop 구하기
ipynb 파일 하나 만들어주자. 1. 라이브러리 로드 필요한 라이브러리 가져오자. librosa.display는 matplotlib를 이용해서 내가 분석한 오디오 파일의 모습을 보여준다. IPython은 파이썬에서 오디오 파일을 가져오게 해준다. 2. 파일 로드
16.librosa로 Root-Mean Square Energy and Zero-Crossing Rate 구하기
물리 에너지 공식 음파의 경우도 줄에서 유도한 에너지 공식을 쓸 수 있다. 왜냐하면 본질적으로 주기운동인점이 같아서. 대충 그림으로 볼려고 했는데 그림 찾기 귀찮아서 말로 설명함 줄의 파동을 보면 줄이 제자리에서 이동하는 것과 옆으로 이동하는 환장의 콜라보인걸 알수
17.Fourier Transform 구하기
준비 라이브러리 로드해주자. 오디오 파일도 확인 해주자. librosa도 로드해주자. 이번 실습에선 되도록 짧은 길이의 파일을 구하자. 그게 시각화가 잘 된다. 음원 그래프를 확인해주자. scipy로 fourier transform 구하기 fourier t
18.librosa DFT 변환 구하기
기계가 무한대의 푸리에 변환을 계산할 수 없다. 그래서 잘게 쪼개서 계산한다는것이 DFT이다.위 그림과 같이 time에 대해서 불연속적으로 잘라주자. 그러면 시간에 대한 푸리에 변환을 위와 같이 n에 대한 식으로 바꿀 수 있다. 전체적으론 이렇게 이산적으로 n에 대한
19.Spectral leakage

Spectral leakage 구글에 한글로 된 자료가 없다 없어 한글로 된 유일한 자료가 위키인데 오해에 저렇게 박아놨다. 근데 영어로 된 자료를 여러개 봤는데 죄다 신호처리 박사들이랑 교수들이 나와서 spectral leakage가 이산 푸리에 변환에 의해 발
20.librosa와 STFT로 spectrogram 얻는법

STFT 전 시리즈에서 DFT와 spectral leakage를 보며 전처리에서 fourier transfrom이 어떻게 이용되는지 알아봤다. DFT를 이용한 데이터는 우리가 딥러닝에 이용할 수 없다. 우리가 음악을 들을 때 가장 중요한 게 바로 시간의 흐름이다.
21.librosa로 mel-spectrogram 얻기
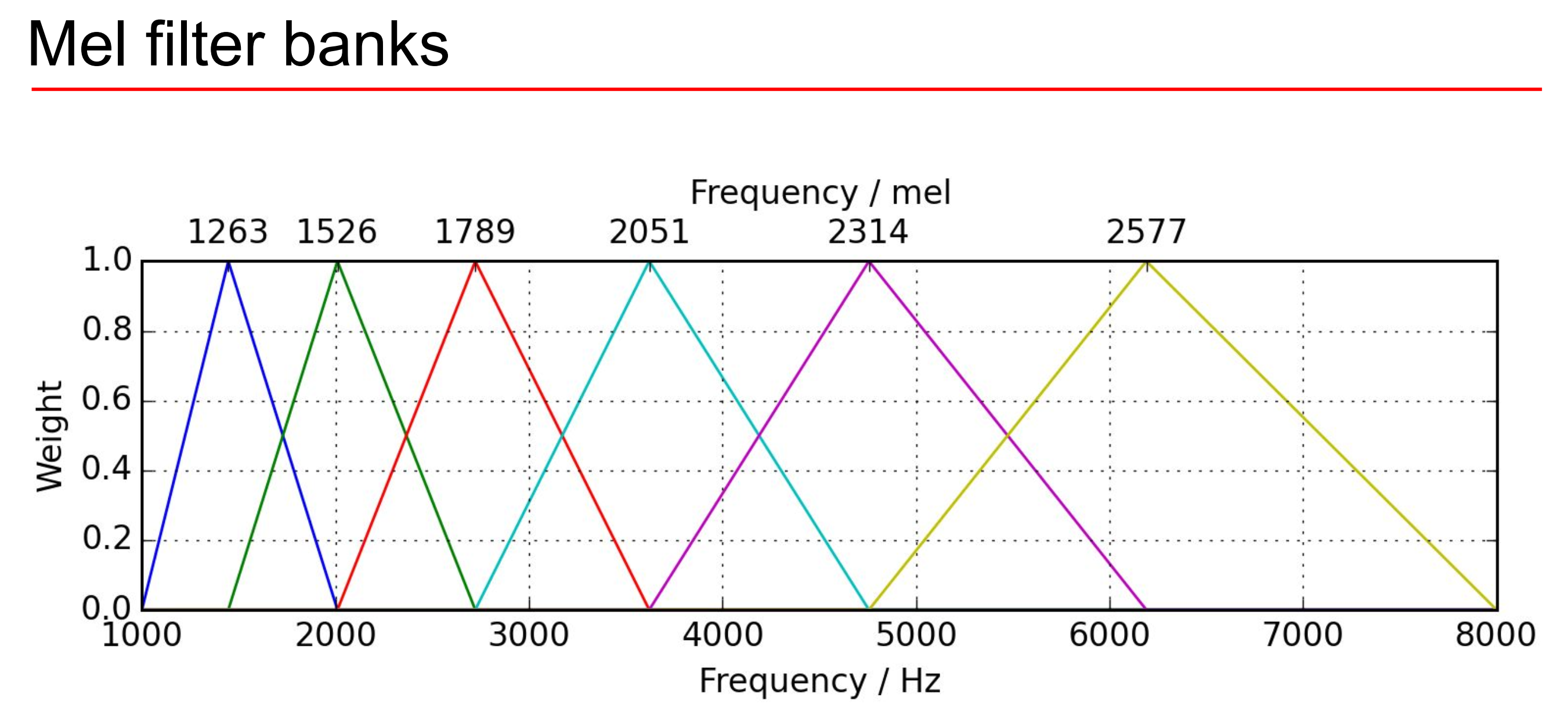
mel-spectrogram mel-spectrogram의 자세한 내용은 이 시리즈의 초반부에 자세히 설명했다. 내용은 전 글을 참고하자. 간단하게 말하자면 spectrogram이 우리가 딥러닝에 사용할 데이터인데 mel-spectrogram은 우리가 실제로 사용하는
22.음악, 음성 딥러닝 데이터 선택(중요)

딥러닝에서 모델에 따라 어떤 데이터를 선택하는지, 어떤 데이터의 특성을 의도적으로 강화해 전처리 하는지, 어떤 데이터 형태로 가공할 건지 정하는 것이 딥러닝에서 가장 중요한 것 같다.실제 딥러닝에서 가장 시간을 많이 할애하는 요소는 다음과 같다.사실 1번에서 가장 많이
23.음악 분류 딥러닝을 만들자(1) - 사전지식
악기 분류 딥러닝 모델을 만들기 위해서 음원을 확보한다.원하는 악기들만 분리된 음원이 필요하다. 얻는 법은 다음과 같다.제일 좋은 방법이다. 내가 원하는 대로, 의도하는 대로 녹음해서 데이터를 확보 할 수 있기 때문에 가장 좋다.내가 이 분야를 꾸준히 연구하고 싶다면
24.음악 분류 딥러닝을 만들자(2) - 데이터 특성 선택
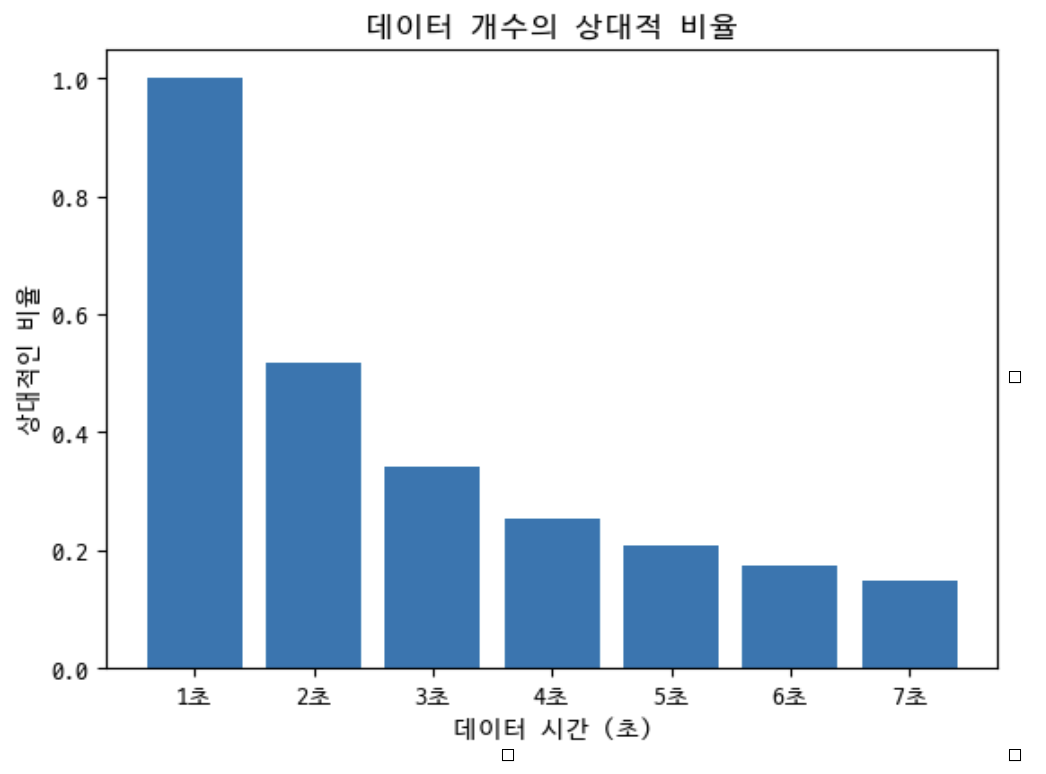
보통은 mel-spectrogram의 단위를 샘플 단위로 많이 이용한다. 하지만 나는 시간 단위인 초(s)를 이용하겠다.mel-spectrogram의 크기는 초 단위로 hop-length의 크기는 framesize의 절반으로 전체 음원을 framesize로 나누어 여러
25.음악 분류 딥러닝을 만들자(3) - wav파일 변환
충분한 데이터를 가져왔니?그럼 시작함딥러닝 데이터를 만들기 전에 모아온 음원 파일은 wav파일로 만드는 게 좋다. 인터넷에 올라온 파일들은 mp3, mp4 파일이 대부분이니 wav파일로 먼저 만들자.필요한 거 가져오자모아온 파일을 하나의 폴더에 넣어서 경로 지정을 해주
26.음악 분류 딥러닝을 만들자(4) - 객체지향
부트캠프에서 자바를 배우며 객체지향적으로 만드는 걸 배웠는 데 머신러닝 프로젝트에서도 적용 해보자.IDE - Pycharmpython - 3.11stack - librosa, pytorch, pandas, anaconda소스 코드는 저번에 작성한 모든 음원을 wav파일
27.음악 분류 딥러닝을 만들자(5) - 데이터 전처리

폴더 안의 파일을 mel-spectrogram으로 바꾸자 우리가 해야 될 일은 다음과 같다.
28.음악 분류 딥러닝을 만들자(6) - 데이터 라벨링
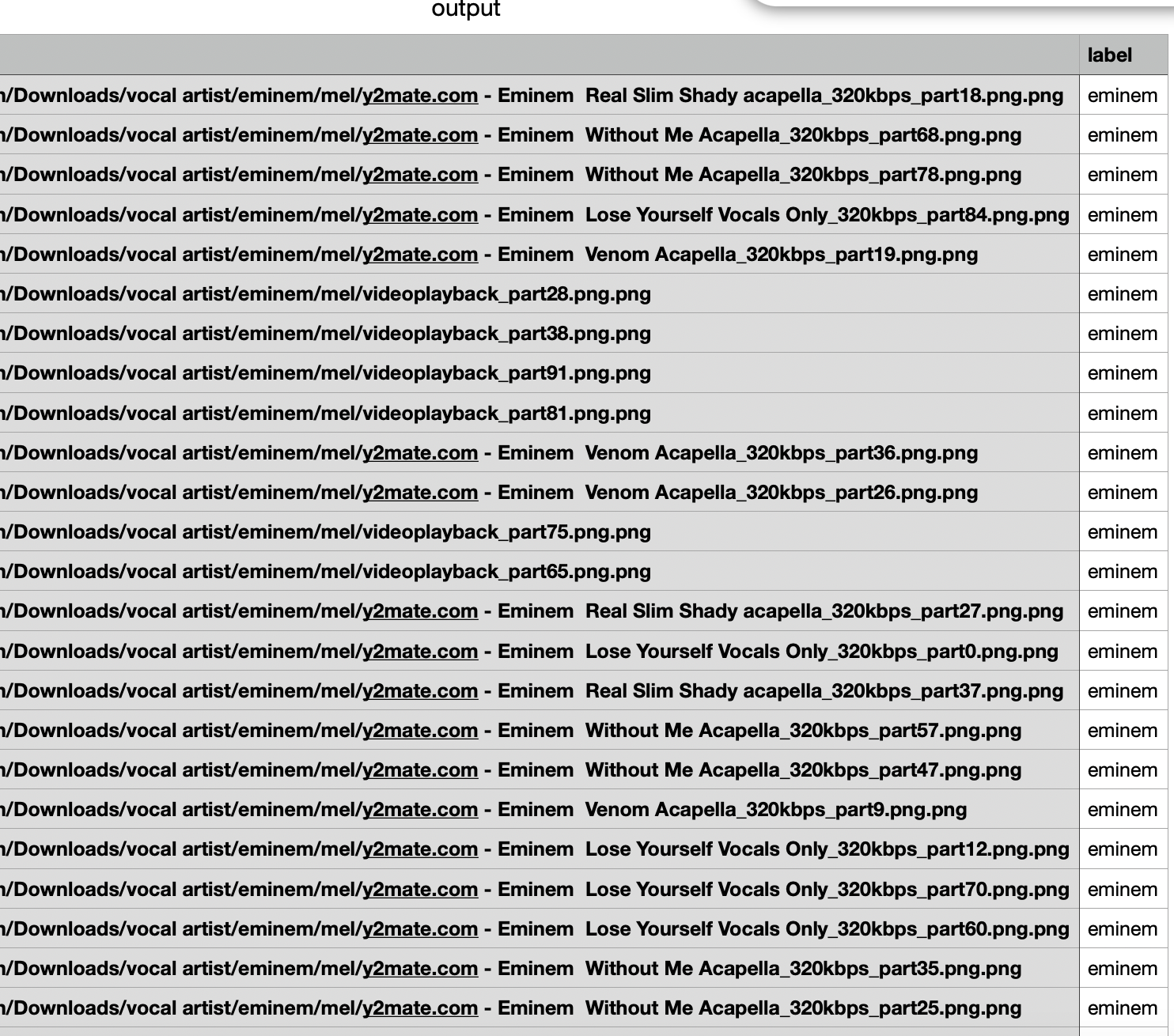
기본적으로 데이터 관리는 mysql 같은 데이터 베이스를 이용해서 하는 것이 좋다. 성능과 관리에서 아주 뛰어나기 때문에 서비스를 만든다면 무조건 데이터 베이스에 데이터를 관리하자.하지만 이번엔 간단한 실습 프로젝트이고 데이터의 개수가 작기 때문에 라벨링한 데이터를 p
29.음악 분류 딥러닝을 만들자(7) - 데이터셋과 training, validation set
이번엔 파이토치의 dataset class를 상속받아 사용자 정의 dataset을 만들것이다. 위 작업은 꼭 필요한데 우선 각 프로젝트의 도메인이 다르고 데이터의 저장방법이 다르기 때문에 사용자의 프로젝트에 따라 데이터셋을 커스텀해야한다.주의 할 점은 상속받아서 재정의
30.음악 분류 딥러닝을 만들자(8) - CNN 모델 구성
CNN 모델의 구성을 살펴보고 들어가자 이제껏 시리즈에서 데이터를 가공하고 로드하는 걸 객체지향적으로 만들어놨다. 대부분의 참고자료는 재생산성을 무시한 절차적 프로그램에 가깝다고 생각한다. 절차지향적으로 코드를 구성하는 건 너무 쉬운 일이지만 이번엔 최대한 객체지향적
31.음악 분류 딥러닝을 만들자(9) - 모델 선정
VIT - 큰 테이터 셋에 적합하고 비용이 커서 경량화랑 잘 안 맞음 -> 탈락 CNN + VIT 혼합 모델 중에서 MobileVit, TinyVit 고려 CNN 경량화 모델과 경량화 혼합 모델 2개를 선정하여 성능비교 CNN 경량화 테크닉 pruning qua
32.음악 분류 딥러닝을 만들자(10) - 최종 모델과 사전준비
ㄴㅇㄹ
33.음악 분류 딥러닝을 만들자(11) - mobileNetV1 설명
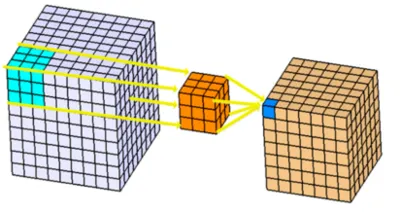
기존 CNN 아키텍처를 생각 해보기 전에 입력 데이터의 공간에 대해서 생각하자.이미지에서 입력 데이터는 벡터로 표현되고 공간과 채널에 대한 3차원 데이터로 주어진다.공간 데이터는 이미지가 어느 공간에 있는 지를 알려준다. 예를 들어서 이미지 파일을 2차원으로 생각하면
34.음악 분류 딥러닝을 만들자(12) - depthwise, pointwise 구현
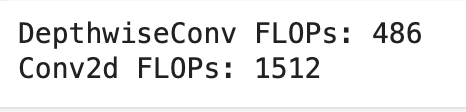
저번 시간에 depthwise의 개념에 대해 알았고 그걸 구현해보자.depthwise의 핵심은 입력 채널이 커널의 채널과 일대일 대응한다는 점이다.직접 만들 수 있지만 torch에 이미 conv에 대한 구현이 있다. 우리가 주목할건공식문서를 찾아보면 group에 대한
35.음악 분류 딥러닝을 만들자(13) - mobileNetV2 아키텍처

특징 mobileNetv2의 아키텍처의 특징은 the inverted residual with linear bottleneck이다. mobileNet 시리즈의 특징이 그렇듯 이전 버전의 아키텍처와 현재 버전 사이에 중요한 경량화 아키텍처를 모두 흡수해 정제하는 구조를
36.음악 분류 딥러닝을 만들자(14) - mobileNetV2 구현
InvertedResidual 우선 mobileNetV2 경량화의 핵심은 bottleNeck과 residual의 개념을 합친 것이고 그 개념은 전 편에서 소개했었다. 이번엔 InvertedResidual를 모듈식으로 구현 해보자. depthwise, pointwise
37.음악 분류 딥러닝을 만들자(16) - mobileNetV3 구현 전 설계
객체지향적으로 만들고 있기 때문에 mobileNetV3의 모듈을 최대한 작게 나눌것 이다.일단은 다음과 같이 생각하고 있다.InvertedResidual: 사실상 많이 바뀐 부분이고 레시피가 정해져있기 때문에 주의할 것SE Block (Squeeze-and-Excita
38.음악 분류 딥러닝을 만들자(17) - mobileNetV3 구현 1
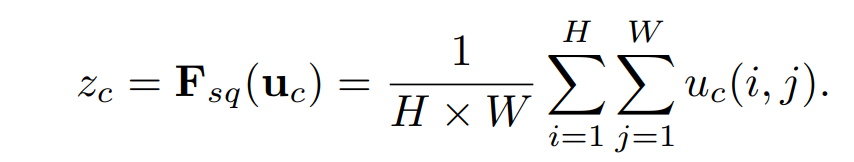
구현할 것 InvertedResidual SE Block (Squeeze-and-Excitation Block) H-Swish Activation NetAdapt h-swish 고민을 좀 했다. 이미 구현되어 있는게 nn에 있어서 근데 이번 시리즈는 학습을
39.음악 분류 딥러닝을 만들자(15) - mobileNetV3 개념
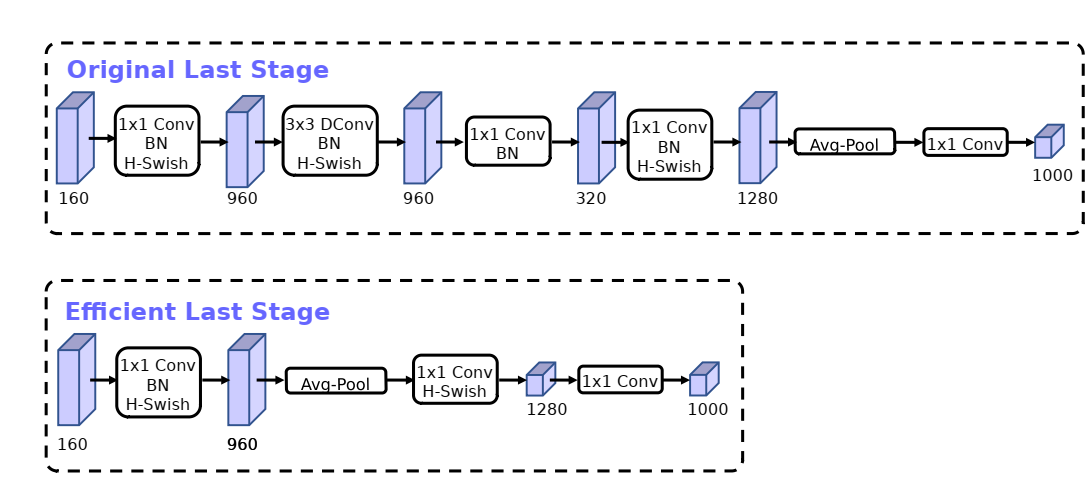
mobileNet v3 목표 mobileNet v2까지 경량화는 flops, parameter와 같은 실제적인 연산량을 줄이려고 노력했다면 mobileNet v3, v4를 비롯한 다른 최신 경량화 모델은 latency, memory의 병목 등을 신경쓰기 시작했다. 현
40.음악 분류 딥러닝을 만들자(18) - NetAdapt
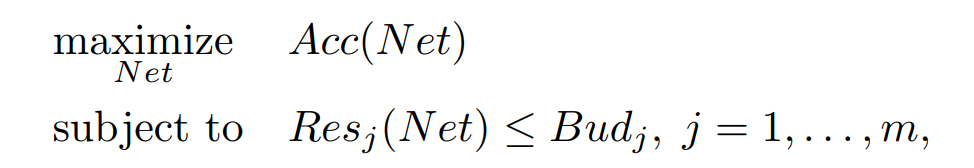
NetAdapt 참고 논문 https://arxiv.org/abs/1804.03230 과정 NAS과정을 통해 시작점인 seed network architecture를 설정한다 기존 아키텍처를 이것저것 수정해본 여러개의 아키텍처를 만든다 변형한 아키텍처가 지연
41.음악 분류 딥러닝을 만들자(19) - NetAdapt-resourceMeasure
resource를 직접 측정하는 코드filter를 pruning하는 코드ShortTermFineTuner ClassAccuracyEvaluator ClassNetAdaptAlgorithm Class이런식으로 일단 나눴다. 오늘은 그 중 resource를 직접 측정하는
42.음악 분류 딥러닝을 만들자(20) - NetAdapt-filter
filter pruning 기준치 이하의 필터를 통채로 없애는게 논문의 포인트이다. 없애고 torch.argsort(layer.weight.abs().sum(dim=[1, 2, 3]))[numfiltersto_prune:] 를 이용해서 weight의 절대값의 합이 적
43.음악 분류 딥러닝을 만들자(21) - finetuning
파인튜닝 별 거 없고 모두가 아는 그 과정을 통해 구현했다. 옵티마이저는 gpt가 추천하는 adamw를 사용했다. adamw는 나중에 학습할 예정이다.논문 레시피에 따르면 proposal 마다 파인튜닝을 진행하고 있다. layerwise에서 pruning을 진행하고 바
44.음악 분류 딥러닝을 만들자(22) - Nas-search space 구현
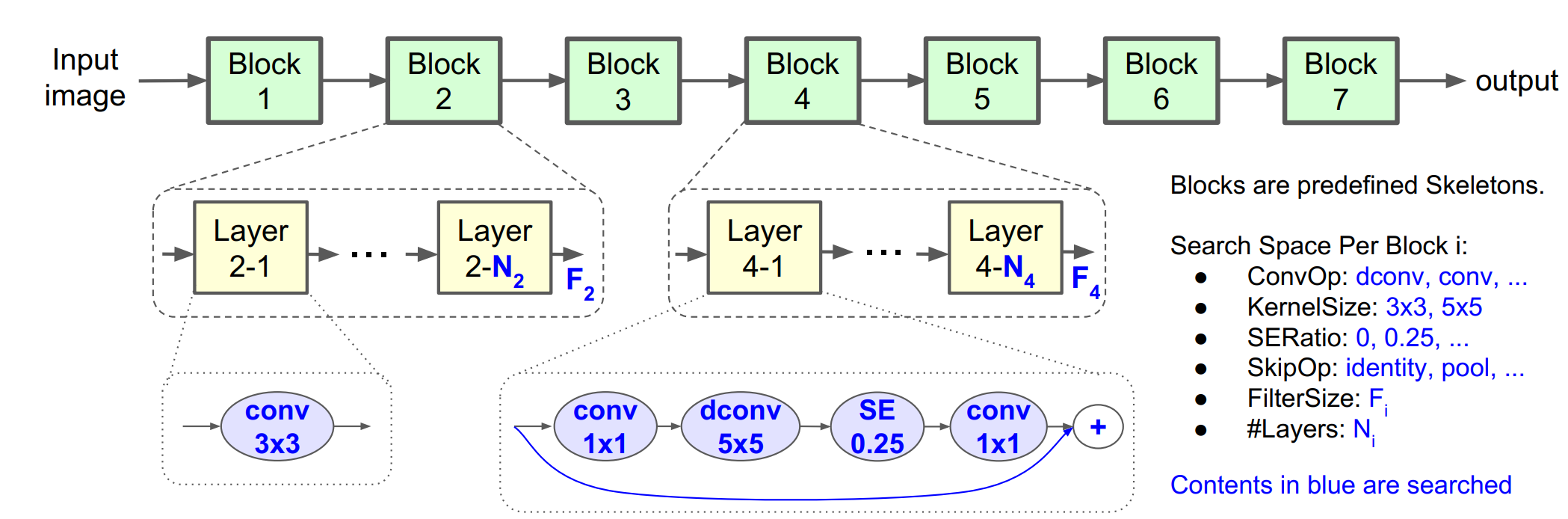
mobileNetv3와 mobileNetv4는 각각 Nas 알고리즘중에서 Mnas, Tunas를 이용한 구현체를 사용한다. mobileNetv3에서 mnas구현체를 이용해서 구한 아키텍처에 NetAdapt를 적용하여 경량화를 이끌어낸다. 이 시리즈의 목적이 단순히 구현
45.음악 분류 딥러닝을 만들자(23) - Nas 정책
sd
46.음악 분류 딥러닝을 만들자(24) - Nas 아키텍처
다수의 논문을 검토해본 결과 학습하는 데 매우 많은 시간과 자원이 드는것을 알 수 있었다. 따라서 일단 nas자체도 경량화를 하면서 mobileNetv3에서 사용되는 mnas와 결합하여 새로운 nas를 만들도록 하자.경량화의 경우 Enasreward의 경우 Mnas이
47.음악 분류 딥러닝을 만들자(25) - search space를 객체지향적으로 refactor
저번 시간에 구성한 mobileNetv3 search space를 확장성을 위해서 리팩터링하자.우선 위와 같은 search space를 만들어주고 위와 같은 아이템을 뽑는 클래스를 만들어주자
48.음악 분류 딥러닝을 만들자(26) - Mnas의 2가지 search space
Mnas의 search space의 구조는 두 가지가 있다. macro search space, micro search space논문을 읽을 때 이 부분이 헷갈렸는데 그냥 위 2가지 방법으로 아키텍처를 만드는 것이다.Macro search space: 처음부터 끝까지
49.*표시된건 선택 사항으로 필수가 아님, *음악 분류 딥러닝을 만들자(27) - Enas의 controller와 Parameter 초기화
강화학습을 기반으로 한 nas 알고리즘에선 컨트롤러가 대부분의 역할을 한다. 이번 시간에선 macro contoller를 이용해서 모델의 파라미터를 초기화하는 매서드를 만들어보자. 우선 컨트롤러에 필요한 걸 위와 같이 초기화 해주자. 많지만 포함되면 좋을걸 일단 위처
50.* 음악 분류 딥러닝을 만들자(28) - Enas의 controller와 build_sampler
build_sampler 이제 컨트롤러를 이용해 파라미터를 초기화하는 매서드를 만들었으니 이번에 레이어들을 샘플링해서 모델을 만드는 build_sampler()를 만들자. https://github.com/melodyguan/enas/blob/master/src/c
51.*음악 분류 딥러닝을 만들자(29) - build_sampler의 설명
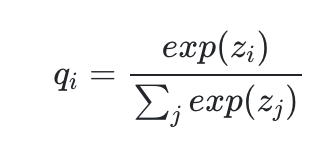
with와 no_grad()는 효율적인 메모리 관리를 위해 준 것, with는 컨텍스트 관리, no_grad()는 그래디언트를 사용하지 않는다. 샘플링은 역전파과정이 없어서 그래디언트 없어도 됨anchors: 이전 레이어의 출력을 저장하는 리스트. 어텐션 계산 시 사용
52.*음악 분류 딥러닝을 만들자(30) - 초기화 매서드
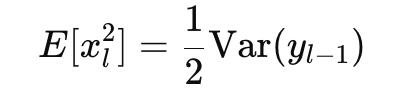
weight, bias 초기화 모델을 본격적으로 학습하는 코드를 만들기 전에 학습에 필요한 weight와 bias를 초기화하는 매서드를 만들자. 일전에 만들어 둔 common_ops란 파일에 만들 것 이다. He 초기화 가중치를 초기화하는 과정은 머신러닝의 학습에
53.*음악 분류 딥러닝을 만들자(31) - macro_child 매개변수
오늘 코드 역시 https://github.com/melodyguan/enas/blob/master/src/cifar10/general_child를 참고했다. 현재는 이걸 기본으로 거의 같게 구현하지만 나중에 enas + mnas + tunas 섞이면 바뀔 수
54.음악 분류 딥러닝을 만들자(32) - factorized reduction 요약
Enas 논문에선 나오진 않으나 논문 저자의 구현체 중 general child에 factorized reduction이란 게 있다. Learning Transferable Architectures for Scalable Image Recognition란 구글 브레인의
55.음악 분류 딥러닝을 만들자(33) - batchNorm 구현

구현체를 참고할 때 대부분 텐서플로를 사용해서 batchnorm을 구현하는 데 난 파이토치를 이용해서 구현할거다. batchNorm에 대한 자세한 내용은 각자 학습하길 바람image_ops란 파일을 만들어주고 batch_norm을 만들어주자.파이토치에서 제공하는 nn.
56.음악 분류 딥러닝을 만들자(34) - factorized reduction 구현 및 아키텍처 경우의 수 계산
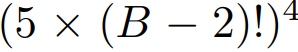
앞서 설명했지만 압축해서 설명하자면 경로 1: 평균 풀링(average pooling)을 적용한 후, 1x1 필터 크기의 컨볼루션(conv2d)을 사용하여 필터 개수를 조정경로 2: 입력 이미지를 패딩한 후, 우측 하단으로 시프트하여 동일하게 평균 풀링을 적용하고, 1
57.음악 분류 딥러닝을 만들자(35) - 정보 압축, bottleNeck,pointwise
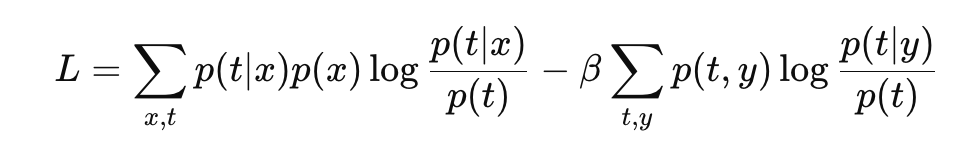
주의 사항 이 글은 상당히 이론적인 글이 될 것이다. 아키텍처를 만드는 데 도움은 안되며 bottleNeck 구조의 이유에 대해서 이론적으로 다룰 글이니 넘겨도 된다. 이 글 쓴 이유 https://github.com/melodyguan/enas/blob/mast
58.*음악 분류 딥러닝을 만들자(36) - conv_branch 매서드와 각종 수정

초기화를 커스텀하기 위해서 다음과 같은 파일을 수정 논문 레시피에 따르면 초기화를 kaiming으로 해야한다. 파이토치에서 좋으면서 안 좋은점이 그냥 nn.Conv2d로 레이어를 만들어 주면 자동으로 가중치를 초기화 한다. 그러면 kaiming 초기화가 안되서 초기
59.*음악 분류 딥러닝을 만들자(37) - enas_layer, fixed_layer
논문 레시피에 따르면 enas의 operation은 총 6개로 커널 크기가 3, 5인 conv, seperable conv 4개커널 크기가 3인 max, average pool 2개 해서 총 6개이다.따라서 구현할 브랜치는 총 6개의 경우의 수를 선택할 수 있게 한다.
60.음악 분류 딥러닝을 만들자(38) - model compression(경량화)에 필요한 Nas 정리
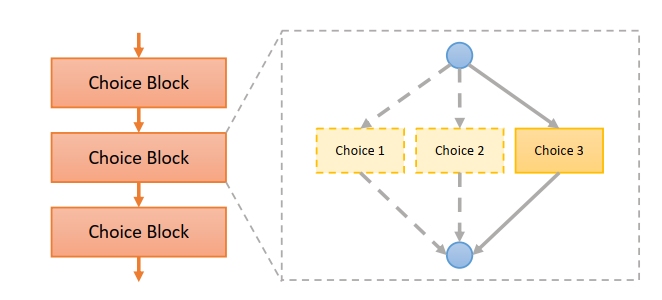
경량화에 Nas(Neural Architecter Search)가 필요한 이유는 연구의 흐름을 살펴봐야한다.mobileNet을 필두로 squeeze and exited, effientNet 등등 경량화의 테크닉들이 점점 개발되었다.경량화에 레이어 테크닉이 개발되면 이
61.음악 분류 딥러닝을 만들자(39) - proxyless Nas
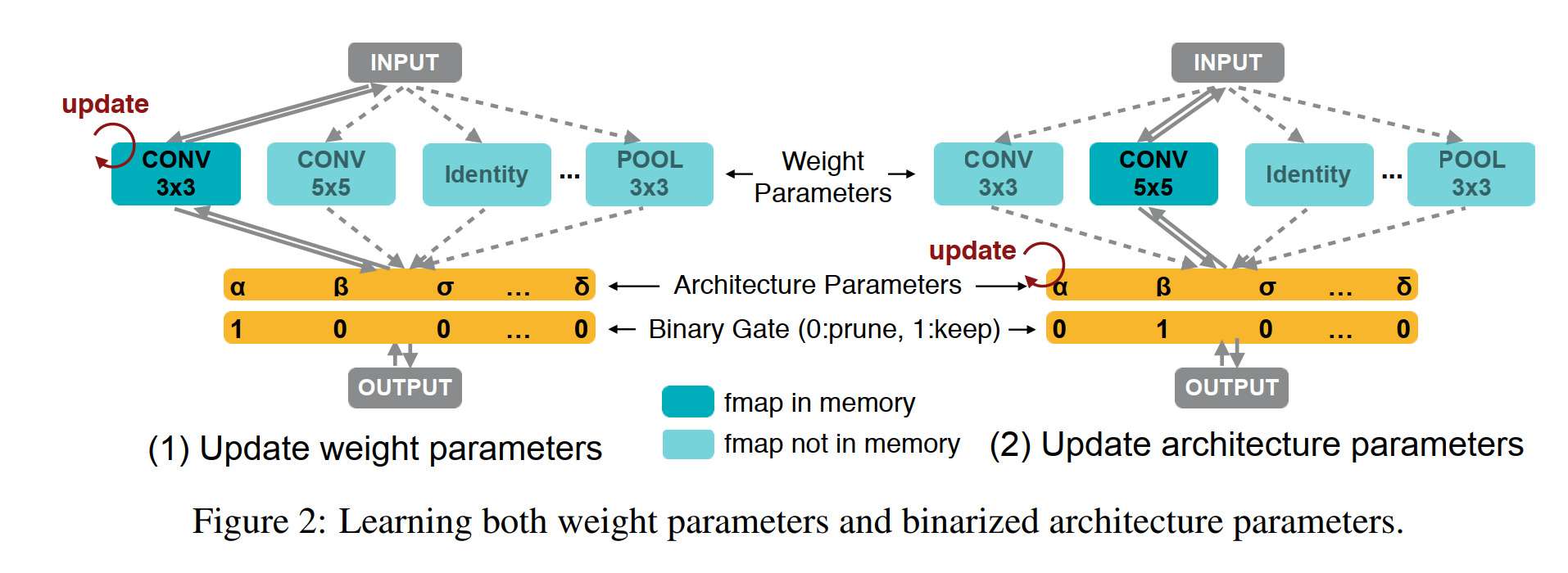
proxyless Nas proxyless를 알아보기 전에 Nas에서 proxy가 뭔지 짚고 넘어가자. cifar-10 우선 논문을 많이 읽어보면 알겠지만 CNN 이미지 분류 실험은 보통 cifar-10으로 많이 실험한다. 규모가 작은편이고 이미 많이 써왔기 때문
62.*음악 분류 딥러닝을 만들자(40) - evolution Nas

굉장히 주관적인 리뷰 사실 once-for-all 논문의 방법론에 Regularized Evolution for Image Classifier Architecture Search란 논문의 evolution nas를 이용했다고 해서 살펴보았다. 논문이나 글 들을 보면
63.음악 분류 딥러닝을 만들자(41) - Predicting Neural Network Accuracy from Weights 논문 리뷰, accuracy, latency predictor
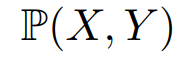
CNN 모델의 성능 평가 학습된 CNN의 모델 평가는 다양한 지표로 이루어지며 가장 직관적으로 사용되는 지표는 accuracy다. 딥러닝을 처음 배울 땐 accuracy, f1 score, precision, recall 이 4개를 평가지표로 배우고 accuracy
64.음악 분류 딥러닝을 만들자(42) - Bayesian, gaussian, VAE 등을 위한 사전 준비
이제 적용할 기법은 bayesian, guassian, MCMC, VAE, Diffusion등 확률론과 관련된 기법들을 적용할 것이다.이 모든 기법은 베이지안 통계학을 기초로 하고 있어서 베이지안에 대한 내용을 학습해야한다.이미 2020년 정도에 BANANAS란 경량화