mel-spectrogram의 데이터 추출 특징
보통은 mel-spectrogram의 단위를 샘플 단위로 많이 이용한다. 하지만 나는 시간 단위인 초(s)를 이용하겠다.
기본 설정
mel-spectrogram의 크기는 초 단위로 hop-length의 크기는 framesize의 절반으로 전체 음원을 framesize로 나누어 여러개의 데이터를 얻겠다.
frame size별 특징
개수
framesize의 크기별로 하나의 음원에 얻을 수 있는 데이터의 수는 다음과 같은 특징을 보인다.
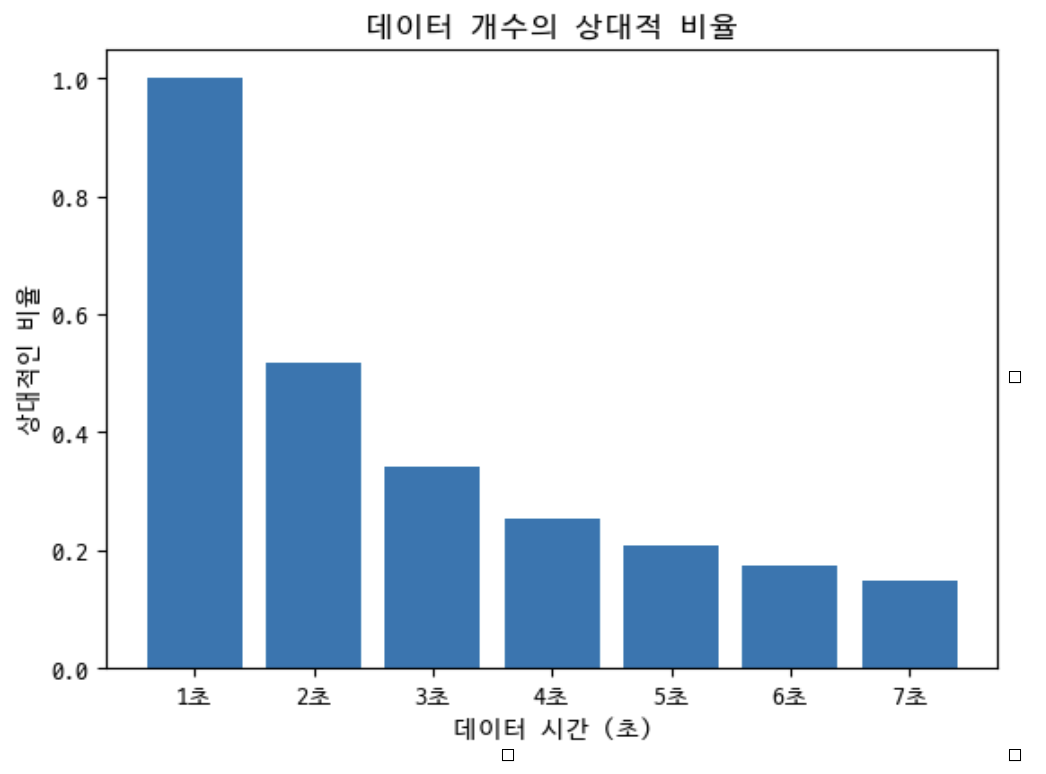
위 시간 간격은 보통 mel-spectrogram에서 자주 사용되는 시간 간격을 모은 것이다.
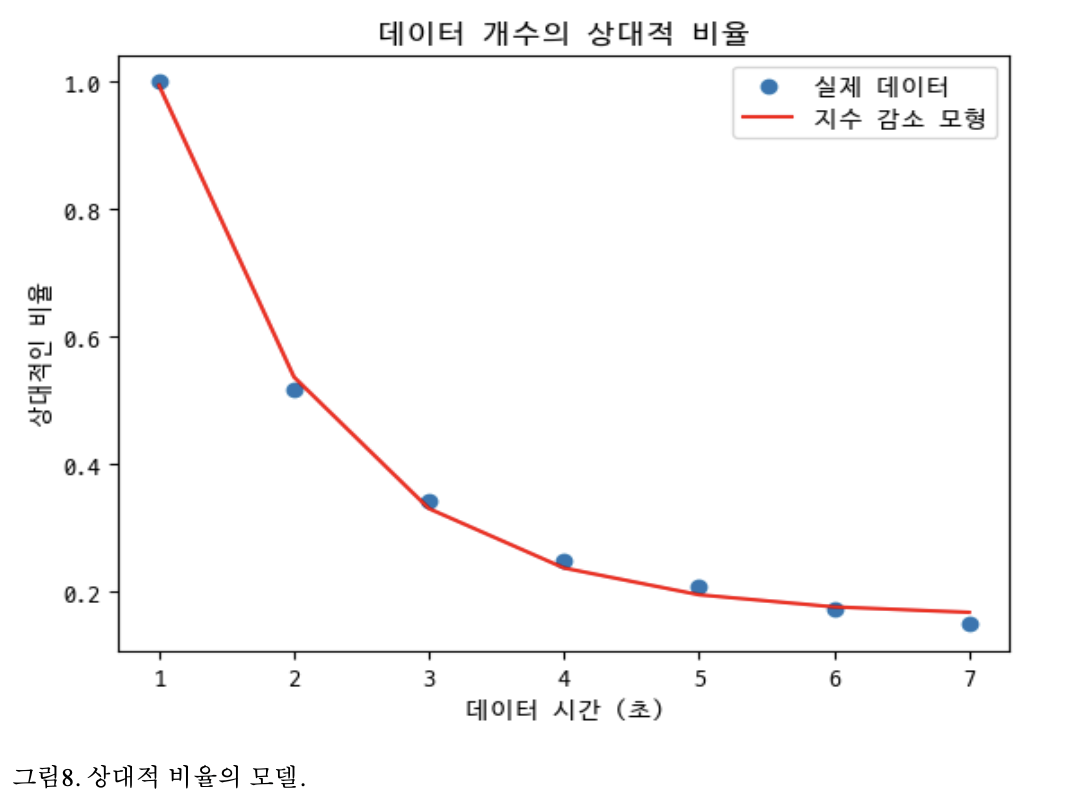
대략적으로 framesize와 데이터의 수는 지수 감소 모형을 가진다.
왜 그럴까?
hop-length의 크기는 framesize와 연관된 값이다. 전체 데이터의 갯수는 hop-lenth의 값을 전체 길이에 나눈 값인데 전체 데이터의 개수는 hop-length에 반 비례해서 1/x의 형태를 띄는 것이다.
품질
1초, 2초의 mel-spectrogram을 얻을 때 신호의 왜곡이 많았다. 경계값이 많기 때문이라고 추측되고 librosa에서 경계값에서 적당히 보정을 하는 데 1, 2초의 시간에 보정이 심하게 되서 그런 듯.
