proxyless Nas
proxyless를 알아보기 전에 Nas에서 proxy가 뭔지 짚고 넘어가자.
cifar-10
우선 논문을 많이 읽어보면 알겠지만 CNN 이미지 분류 실험은 보통 cifar-10으로 많이 실험한다.
규모가 작은편이고 이미 많이 써왔기 때문에 많이 선택하는데 Nas도 예외는 아니다.
대부분의 Nas가 cifar-10을 기준으로 찾는 방법인데 실제 기업에서 쓰는 데이터는 cifar-10보다 훨씬 큰 데이터다. 작은 cifar-10에서 찾는 아키텍처가 큰 데이터에서도 잘 먹힐거란 생각이 Nas에서 proxy의 의미이다.
축소된 네트워크 구조
기존의 Nas는 아키텍처를 찾을 때 축소된 모형으로 찾은 뒤 마지막에 확장하는 방법을 사용했다. 작은걸로 학습하고 보강해 큰 거에 적용해서 proxy
다른 하드웨어
다른 간단한 하드웨어 환경에서 실험을 하고 찾은 아키텍처를 복잡한 목표 하드웨어에 적용하니까 proxy
proxyless Nas의 장점
proxyless해서 좋다
이름 그대로 실제 환경
즉 큰 데이터, 실제 환경의 하드웨어에서 아케텍처를 찾아서 해당 환경에서 최적의 아키텍처를 만든다.
repeating block 삭제
초기 Nas들이 찾은 아키텍처의 block이 반복되는 형태였다.
그래서 어느 순간부터 Nas들이 block이 반복되는 것이 효율적이라는 전제를 깔고 찾는 방법을 아예 같은 block이 반복되도록 설계하였는 데
예상하다시피 근거없이 실험결과에 경험적으로 의존한거라 최상의 아키텍처는 아니다.
proxyless Nas에선 repeating block의 관행을 삭제하고 repeating block이 최선이 아님을 증명했다.
one shot보다 나은 방식
one shot Nas는 아키텍처를 탐색할 때 tree의 분기마다 모든 분기를 합쳐서 (concat) 확률 계산한 뒤 좋은 확률을 가진 분기만 선택하는 방법이다.
이 방법은 확실히 효율적이지만 메모리 측면에서 보면 각 분기의 모든 operation을 concat해서 메모리에 올려놓기 때문에 메모리 문제가 발생한다.
proxyless nas는 mask를 통해서 한 번에 하나만 분기를 탐색하는 방법으로 메모리 문제를 해결한다.(path binarization)
proxyless Nas의 학습 과정
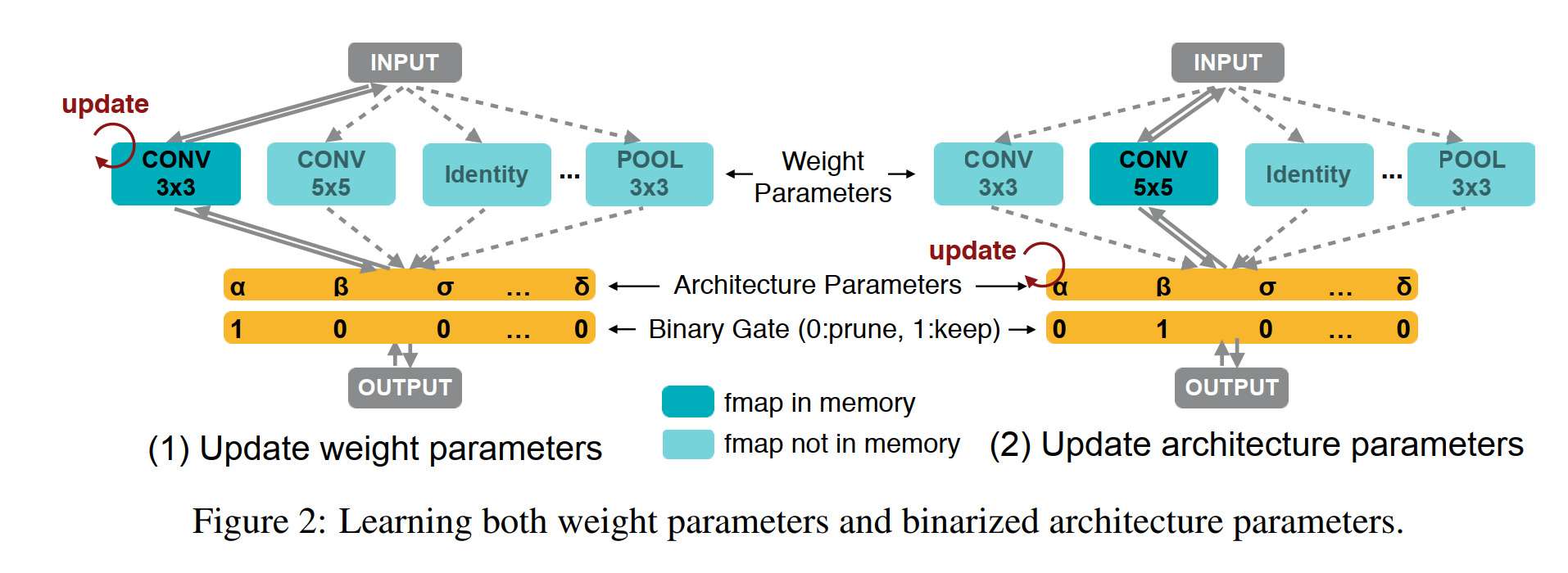
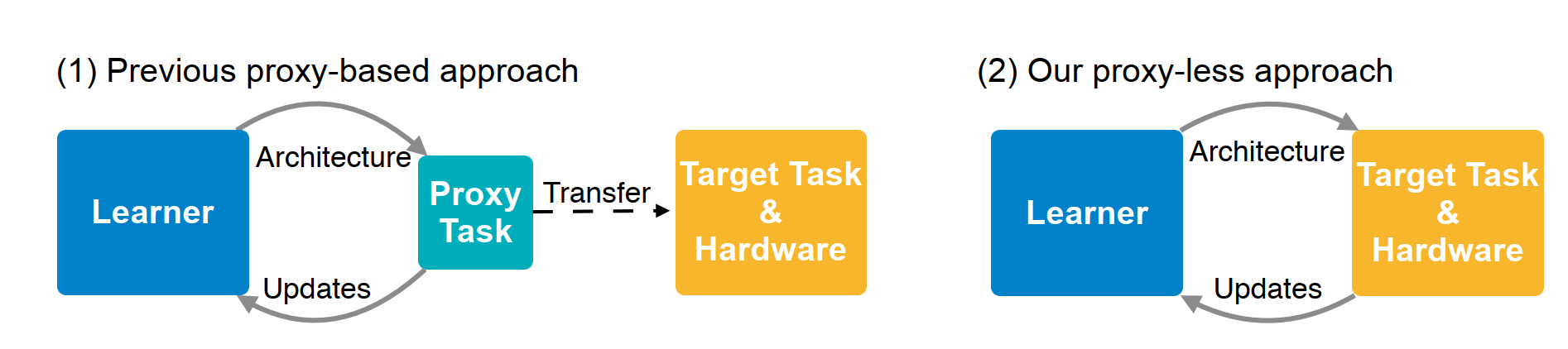
weight shared를 사용하는 거의 모든 Nas의 학습은 2가지의 반복이다.
1. training data에서 데이터를 뽑아서 weight를 학습함
2. validation data를 이용해서 아키텍처 자체를 뽑는 파라미터를 학습함
이 학습을 어떻게 하느냐에 따라서 Nas의 방법론이 갈리는 것이다.
Enas와 Mnas 등 옛날 Nas들은 메타 컨트롤러를 이용하였다.
LSTM과 같은 시계열 모델은 어떤 순서에 어떤 node를 선택할지 확률적 학습을 하는 것이다.
node를 아키텍처로 생각해서 순서를 정하는 확률적 학습을 하면 그게 Nas기 때문에 메타 컨트롤러를 이용하여 weight와 아키텍처 파라미터를 번갈아가며 학습하였다.
반면 요즘에 나온 one-shot 계열 Nas들은 메타 컨트롤러 대신 supernet을 한 번에 학습하는 방식을 채택하고 있다.
nas의 supernet 맘에 드는 그림이 없어서 ai로 그려달라고 했다 양해바람 ㅎㅎ
아무튼 이전 메타 컨트롤러들을 이용해 학습하는 Nas들은 저 supernet에서 하나의 가지만 선택해서 일일이 학습하는 구조였다.
많은 경우의 수를 일일이 따지는 방법이라 효율적이진 않았고 이를 보완한게 one-shot 계열 Nas다.
one shot계열 Nas들은 저 superNet을 한 번에 학습하는 방법 (once-for-all), 층마다 concat해서 층별로 학습하는 방법 (one-shot), 층마다 확률적인 방법으로 모든 아키텍처 후보를 고려하되 하나만 선택하는 방법 (proxyless)이 있다.
그럼 proxyless의 자세한 학습 방법을 살펴보자.
CONSTRUCTION OF OVER-PARAMETERIZED NETWORK
우선 가장 중요한 점은 weight shared를 어떻게 할 것 인지 정하는 것이다.
weight shared를 탐구하는 게 요즘 nas의 근간인 만큼 어떻게 weight 초기화하고 학습하는지에 따라 nas의 성능이 갈리게 된다.
proxyless의 weight 초기화는 over-parameterized를 채택하고 있다.
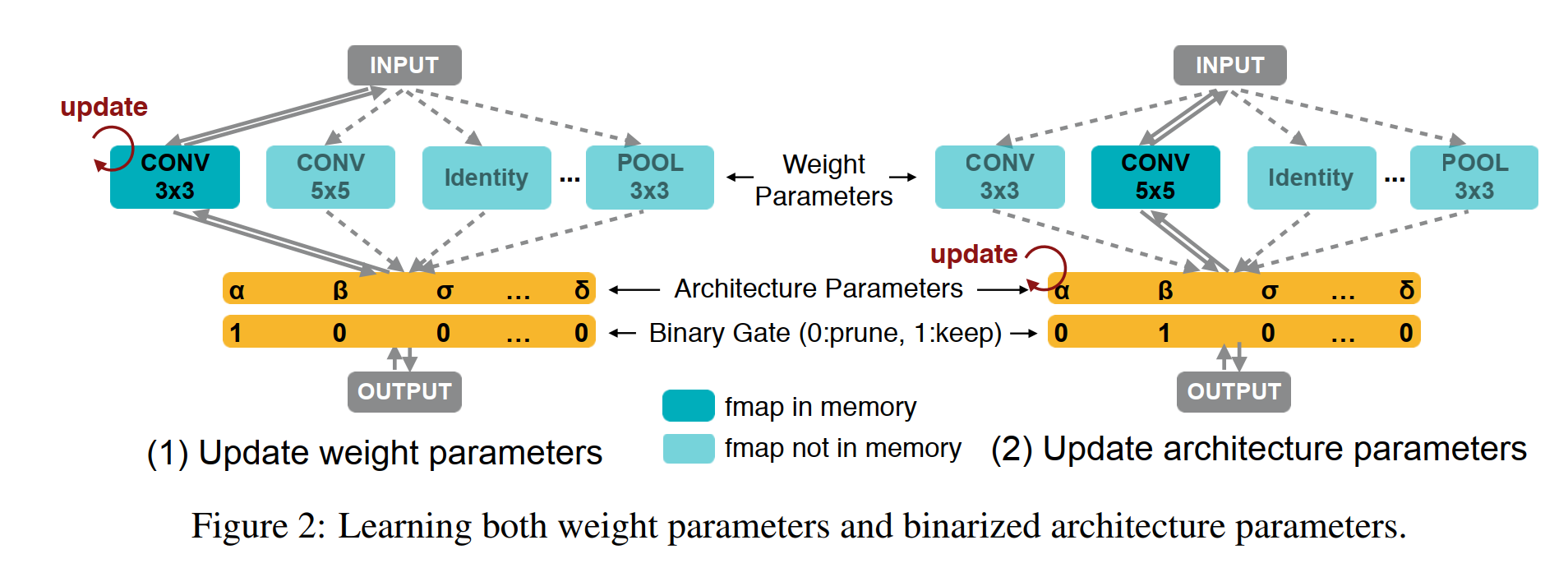
그림을 다시 살펴보자. proxyless에선 supernet의 층, 즉 깊이(depth) 별로 모든 operation을 포함해서 weight를 초기화한다.
그냥 층별로 나올 수 있는 모든 operation의 weight를 초기화해놓는다고 생각하자.
논문에선 "we set each edge to be a mixed operation that has N parallel paths (Figure 2), denoted as mO" 라고 표현하고 있다.
그럼 one-shot이나 DARTS에서 weight shared가 문제가 되는 이유를 보자.
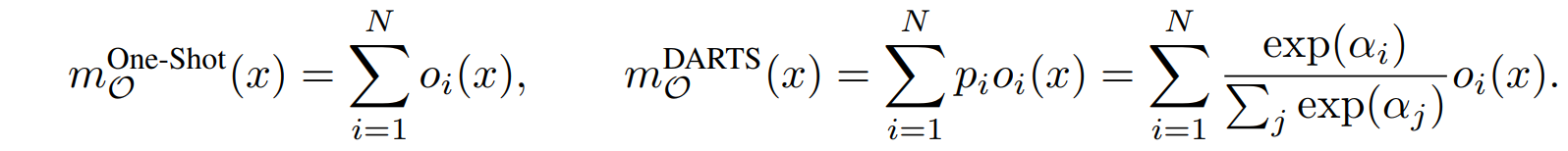
위 식을 살펴보면 one-shot과 DARTS는 층별로 모든 weight를 한 번에 메모리에 올려놓는다. 그럼 메모리는 펑
반면 proxyless는 binarize entire paths를 적용한다.
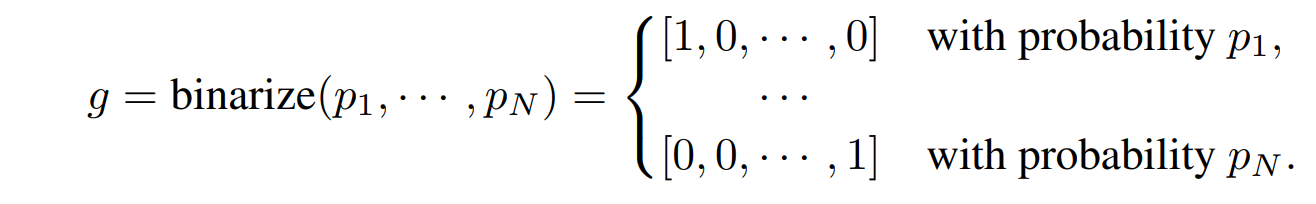
위와 같은 binary gates를 이용하는 거다.
그리고 weight를 어떻게 초기화하면 아래와 같이한다.
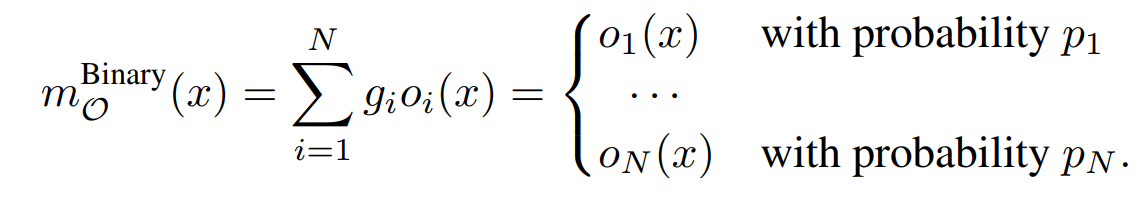
one-shot이나 DARTS와 별 차이가 없어보이지만 자세히 살펴보자.
우선 binary gates가 확률적으로 뽑는 것이고 선택된 binary gates는 자신에게 할당된 (i가 같은) operation을 제외하곤 모든 operation에 0을 곱해 제외시킨다.
결국 proxyless는 학습할 때 각 층마다 하나의 operation의 weight만 메모리에 올린다.
TRAINING BINARIZED ARCHITECTURE PARAMETERS
weight를 학습하는 걸 봤으니 이제 아키텍처를 뽑는 파라미터를 학습하는걸 보자.
우선 기본적으로 weight, architecture parameter는 번갈아 학습한다. 즉 하나는 학습하며 변화하고 하나는 고정하고 이런식으로 번갈아 학습함
weight parameter의 경우엔 supernet에서 노드를 선택해서 직접적으로 학습하지만 architecture parameters의 경우는 그래프에 연관된게 없어서 확률적인 학습을 하지 목한다.
노드랑 직접적인 연관이 없어서 그런 것
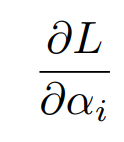
우리가 architecture parameter를 학습한다는 것은 위의 기울기를 이용한다는 뜻이다.
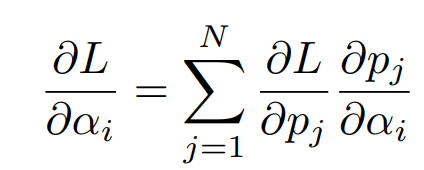
architecture를 뽑는 확률 자체를 학습하는게 architecture parameter를 학습하는 것이기 때문에 위와 같이 확률로 기울기를 나타낼 수 있다.
이때 architecture를 뽑을 확률은 뭐냐? binary gates의 확률이다.
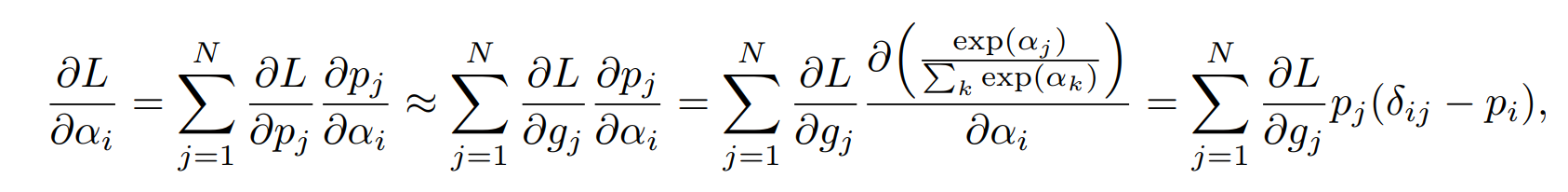
따라서 위와 같은 근사식을 활용할 수 있다.
하지만 위 근사식을 사용하는건 DARTS랑 똑같은 메모리 문제를 가진다.
모든 경우의 수를 한 번에 메모리에 올려놔서 메모리가 펑
그래서 대신에 2가지 경로만 전체 경로에서 선택하는 것이다.
위와 같은 조합으로 뽑는다고 생각하자.
뽑은 2가지를 제외하곤 나머지를 지웠다고 생각하는 거다.
경로를 선택하는 확률은 아키텍처를 선택하는 확률이다.
뽑은 2가지의 경로만 back propagation을 이용해서 학습한 뒤 softmax를 적용해서 둘 중 하나는 확률을 올리고 하나는 떨어트리는 거다. 물론 안 뽑힌 다른 확률들은 고정시키고
proxyless의 latency 학습
요즘 Nas는 Nas를 실행하는 하드웨어에 따라서 최적의 학습을 하는게 당연하다.
따라서 현재 하드웨어로 학습하는 중 latency를 직접 측정하여 학습에 반영한다.
학습이란건 Loss의 기울기를 back-propagation해서 하는건데 latency의 측정은 이산적이라 연속적이 아니다.
고등학교에 연속이 아니면 미분 불가능하다란건 알죠?
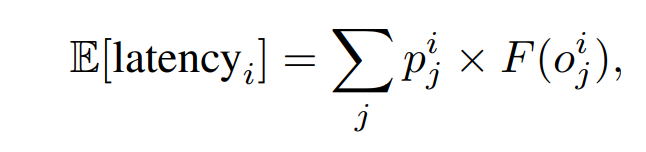
그래서 latency의 expectation함수를 대신 쓴다. 이건 연속이라 back-propergation을 쓸 수 있걸랑
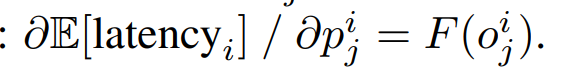
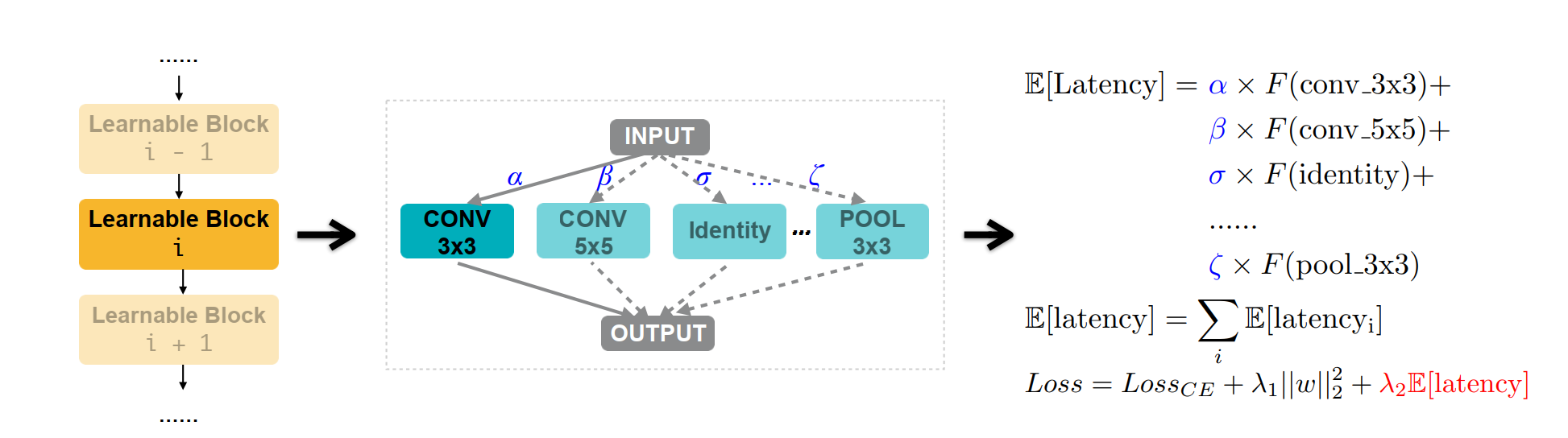
위와 같이 층별로 E 함수를 쓰고 흔히 쓰는 regulation 테크닉을 써서 학습한다.
최선의 아키텍처는 RL을 이용함
그럼 latency도 학습가능하게 만들었고 weight도 학습하고, 아키텍처도 뽑는 확률을 학습하는 데 가장 중요한게 빠졌옹
3개를 이용하는데 그래서 최선의 아키텍처를 뽑는 기준이 뭐임?
최선의 아키텍처를 뽑는 기준이 바로 Reinforce Learning이다.
정확하게 표현하면 Reinforce Learning에서 Reward.
reward는 보통 (accuracy/latency)를 잘 변형해서 정한다.
보통은 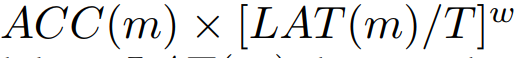
위와 같이 T(Target latency), latency, Accuracy의 비율을 이용해서 Reward를 표현함.
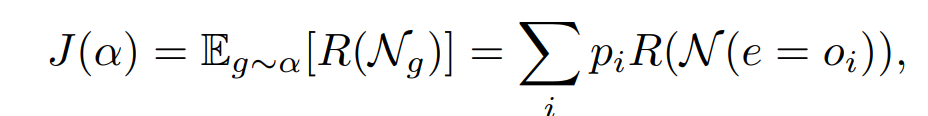
아무튼 Proxyless Nas에선 이 Reward 기대값이 가장 높은 아키텍처를 최선의 아키텍처로 삼아서 뽑는다.
즉, 가장 높은 Reward를 가진 아키텍처 하나를 계속해서 저장하고 갱신하는 방식으로 최선의 아키텍처를 뽑고 저장한다.
후기
자세한 Proxyless 코드를 보여주지 않았는데 이 proxyless보다 후기에 나온 Once-for-all Nas를 이용 할 거기 때문에 그냥 개념만 짚었다.
