음악 분류 딥러닝을 만들자(41) - Predicting Neural Network Accuracy from Weights 논문 리뷰, accuracy, latency predictor
음악 딥러닝과 mel-spectrogram
CNN 모델의 성능 평가
학습된 CNN의 모델 평가는 다양한 지표로 이루어지며 가장 직관적으로 사용되는 지표는 accuracy다.
딥러닝을 처음 배울 땐 accuracy, f1 score, precision, recall 이 4개를 평가지표로 배우고 accuracy를 보완한다는 느낌으로 다른 지표를 배우니 자칫 accuracy가 덜 떨어진 지표로 생각될 수 있다(내가 그랬음...)
papers with code의 benchmark도 그렇고 논문들을 읽어봐도 대부분 지표를 top-1 accuracy를 대표적으로 사용한다.
Nas 역시 마찬가지다. 진화적 알고리즘이던 강화학습을 이용하던 지표를 accuracy로 정하고 들어간다.
따라서 CNN 모델이 accuracy를 어떻게 평가하는지에 대한 이해와 이 accuracy를 어떻게 효율적으로 할 것 인지 연구하는게 중요하다고 생각된다.
전통적인 CNN의 학습 방법과 성능 평가 방법
이 시리즈는 기본적인 CNN의 지식이 있는 상태를 전제로 쓰여져서 자세하게 설명하진 않겠다.
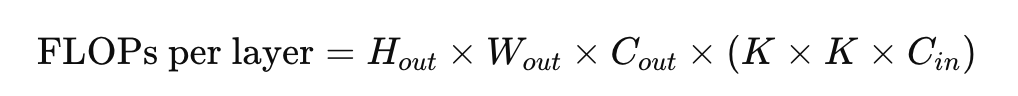
대략적으로 layer 한 개당 위와 같은 연산을 치룬다. 학습은 forward, back이 한 사이클로 이루어져 약 2배의 FLOPS를 가진다.
다루고 있는 논문의 목적은 meta값을 분석해 딥러닝의 본질적인 이해를 하는 것이다.
논문에선 paramter, weight, distillation, cnn zoo 등 여러 가지를 강조하고 있지만 우리가 Nas에서 주목할 부분은 weight를 이용해 accuracy를 추정하는 방법이다.
후에 다루겠지만 weight를 이용해 accuracy를 추정하는 방법은 입력 데이터에서 accuracy를 추정하는 방법보단 훨씬 효율적이다.
파라미터, 가중치, 결과값의 관계
딥러닝 과정을 최대한 간단하게 뭉게면 그냥 매핑, 다변수 함수로 생각할 수 있다.
딥러닝 정의역은 paramter, weight라면 공역은 그냥 accuracy와 같은 성능지표라고 뭉갤수 있다.
정확하게 설명해보자.
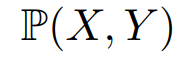
p는 X, Y의 곱집합에서 정의되는 분포라고 정하자.
X는 input, Y는 output이라고 했을 때 우리가 P분포에서 뽑을 수 있는(sample) 경우의 수는 다음과 같이 정의할 수 있다.
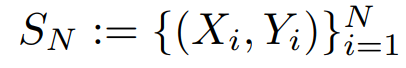
X, Y의 관계를 분류 문제로 생각해보면 X를 넣으면 결과값인 label, 즉 Y가 나오게 된다.
우리는 샘플링을 통해 Sn을 뽑고 CNN의 input 데이터로 사용한다.
Sn과 hyperparameter(λ)를 초기화해서 학습을 한 뒤 결과로 W vector를 얻는다.
이를 간단하게 함수로 표현하면 다음과 같다.
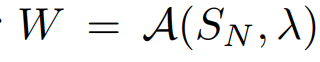
여기서 A는 학습 과정을 나타낸다.
학습을 마친 뒤 다시 input data를 넣어서 forward 해주면 결과값 Y를 얻는게 딥러닝 과정인데 다음과 같이 표현한다.
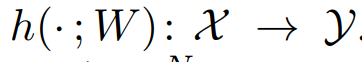
이때 Y의 라벨이 실제 데이터의 라벨과 얼마나 맞는 지 따져 전체적인 비율을 구하면 accuracy를 얻는다.
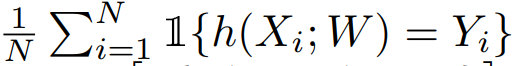
함수 1은 y끼리 일치하면 결과값이 1인 함수다.
accuracy의 기댓값은 W, Sn의 함수로 정해진다.
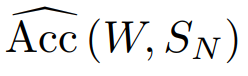
CNN의 데이터 전처리에서 우리는 이미 데이터의 분포, 즉 입력 데이터와 출력 데이터의 라벨을 정해놓고 모든 걸 진행한다. 따라서 Sn은 정해진 값으로 accuracy는 단순히 W에 대한 매핑이 된다.
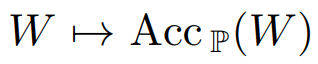
앞선 사실을 통해 acuuracy는 W에 대한 함수로써 우리의 목표는 accuracy predictor를 사용하여 weight를 이용해 accuracy를 측정하는 것이다.
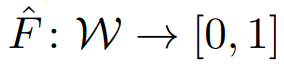
F의 학습법
논문에서 3가지 predictor의 학습을 비교하여 유용한 학습법을 뽑았다.
logit-linear model (L-Linear), gradient boosting machine
using regression trees (GBM), and a fully-connected DNN
이 3가지를 비교하였지만 나는 여기에 Bayesian Neural Network, Gaussian Process (GP) Regression을 추가하여 비교할 것이다.
자세한 학습 환경과 가정, 구현은 다음 시간에 살펴보겠다
