알고리즘 문제를 푼다는 것은, 내가 생각한 문제 해결 과정을 컴퓨팅 사고로 변환하여 코드로 구현한다는 것과 같다
수많은 문제 해결 과정은 대부분 여러 개의 카테고리로 묶여진다
예시로, N 개의 숫자들을 특정한 기준에 맞게 순서를 조정하는 것을 정렬이라고 부르고,
그래프 탐색의 경우 탐색 방식에 따라 DFS와 BFS라고 부른다
각 카테고리는 원하는 의도가 분명하게 있고, 그것을 해결하는 것이 목표다
- 데이터를 정렬할 수 있는가?
- 데이터를 효율적으로 탐색할 수 있는가?
- 데이터를 조합할 수 있는가? ...etc
카테고리를 분류한다고 해도 내가 생각한 로직을 '코드로 구현'한다는 건 전부 공통적인 속성이다
구현 능력을 보는 대표적인 사례에는 완전 탐색(brute force) 과 시뮬레이션(simulation) 이 있다
완전 탐색이란 가능한 모든 경우의 수를 전부 확인하여 문제를 푸는 방식을 뜻하고,
시뮬레이션은 문제에서 요구하는 복잡한 구현 요구 사항을 하나도 빠트리지 않고 코드로 옮겨, 마치 시뮬레이션을 하는 것과 동일한 모습을 그린다
완전 탐색
모든 문제는 완전 탐색으로 풀 수 있다
이 방법은 굉장히 단순하고 무식하지만 "답이 무조건 있다"는 강력함이 있다
예를 들어, 양의 정수 1부터 100까지의 임의의 요소가 오름차순으로 하나씩 담긴 배열 중, 원하는 값 N을 찾기 위해서는 배열의 첫 요소부터 마지막 요소까지 전부 확인을 한다면 최대 100 번의 탐색 끝에 원하는 값을 찾을 수 있다
그렇지만, 문제 해결을 할 때엔 기본적으로 두 가지 규칙이 붙는다
- 문제를 해결할 수 있는가?
- 효율적으로 동작하는가?
완전 탐색은 첫 번째 규칙을 만족시킬 수 있는 강력한 무기이지만 두 번째 규칙은 만족할 수 없는 경우가 있다
양의 정수 1부터 100까지의 임의의 요소가 오름차순으로 하나씩 담긴 배열 중, 원하는 값 N을 찾으시오. 단, 시간 복잡도가 O(N)보다 낮아야 합니다.
이러한 문제가 나왔을 때, 최악의 경우 100 번을 시도해야 하는 완전 탐색은 두 번째 규칙을 만족할 수 없다
배열을 작은 수에서 큰 수, 혹은 그 반대로 정렬한 후 이분 탐색을 사용하는 방법 등 다른 알고리즘을 사용해야 한다
그렇기 때문에, 문제를 풀 수 있는 가능한 모든 방법을 고려한 후 효율적으로 동작하는 알고리즘이 전부 탐색할 수밖에 없다고 판단될 때 적용할 수 있다
완전 탐색은 단순히 모든 경우의 수를 탐색하는 모든 경우를 통칭한다
완전히 탐색하는 방법에는 brute Force(조건/반복을 사용하여 해결), 재귀, 순열, DFS/BFS 등 여러 가지가 있다
그중, Brute Froce(무차별 대입)에 대해 예시를 보자
문제
우리 집에는 세 명의 아이들이 있습니다. 아이들의 식성은 까다로워, 먹기 싫은 음식과 좋아하는 음식을 철저하게 구분합니다. 먹기 싫은 음식이 식탁에 올라왔을 땐 음식 냄새가 난다며 그 주변의 음식까지 전부 먹지 않고, 좋아하는 음식이 올라왔을 땐 해당 음식을 먹어야 합니다. 세 아이의 식성은 이렇습니다.첫째: (싫어하는 음식 - 미역국, 카레) (좋아하는 음식 - 소고기, 된장국, 사과)
둘째: (싫어하는 음식 - 참치, 카레) (좋아하는 음식 - 미역국, 된장국, 바나나)
셋째: (싫어하는 음식 - 소고기) (좋아하는 음식 - 돼지고기, 된장국, 참치)
100 개의 반찬이 일렬로 랜덤하게 담긴 상이 차려지고, 한 명씩 전부 먹을 수 있다고 할 때, 가장 많이 먹게 되는 아이와 가장 적게 먹게 되는 아이는 누구일까요? (단, 그 주변의 음식은 반찬의 앞, 뒤로 한정합니다.)
이 문제는 단순히 100 개의 반찬을 첫째, 둘째, 셋째의 식성에 맞게 하나씩 대입하여 풀 수 있습니다.
for(let i = 0; i < 100; i++) {
if(첫째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
if(둘째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
if(셋째 식성) {
if(싫어하는 음식이 앞뒤로 있는가) {
그냥 넘어가자;
}
좋아하는 음식 카운트;
}
}
return 많이 먹은 아이;각각 몇 가지 음식을 얼마나 먹을 수 있는지 각각 계산한 후, 제일 많이 먹는 아이와 제일 적게 먹는 아이를 파악할 수 있다
문제를 풀 때, 반복문이 아닌 배열을 전부 순회하는 메서드를 사용한다거나 간결한 코드를 위한 문법을 사용한다고 하더라도 배열을 전부 탐색하여 세 명의 값을 도출한다는 것엔 변함이 없다
시뮬레이션
시뮬레이션은 모든 과정과 조건이 제시되어, 그 과정을 거친 결과가 무엇인지 확인하는 유형이다
보통 문제에서 설명해 준 로직 그대로 코드로 작성하면 되어서 문제 해결을 떠올리는 것 자체는 쉬울 수 있으나 길고 자세하여 코드로 옮기는 작업이 까다로울 수 있다
예시
무엇을 위한 조직인지는 모르겠지만, 비밀스러운 비밀 조직 '시크릿 에이전시'는 소통의 흔적을 남기지 않기 위해 3 일에 한 번씩 사라지는 메신저 앱을 사용했습니다. 그러나 내부 스파이의 대화 유출로 인해 대화를 할 때 조건을 여러 개 붙이기로 했습니다. 해당 조건은 이렇습니다.
캐릭터는 아이디, 닉네임, 소속이 영문으로 담긴 배열로 구분합니다.
소속은 'true', 'false', 'null' 중 하나입니다.
소속이 셋 중 하나가 아니라면 아이디, 닉네임, 소속, 대화 내용의 문자열을 전부 X로 바꿉니다.
아이디와 닉네임은, 길이를 2진수로 바꾼 뒤, 바뀐 숫자를 더합니다.
캐릭터와 대화 내용을 구분할 땐 공백:공백으로 구분합니다: ['Blue', 'Green', 'null'] : hello.
띄어쓰기 포함, 대화 내용이 10 글자가 넘을 때, 내용에 .,-+ 이 있다면 삭제합니다.
띄어쓰기 포함, 대화 내용이 10 글자가 넘지 않을 때, 내용에 .,-+@#$%^&*?! 이 있다면 삭제합니다.
띄어쓰기를 기준으로 문자열을 반전합니다: 'abc' -> 'cba'
띄어쓰기를 기준으로 소문자와 대문자를 반전합니다: 'Abc' -> 'aBC'
시크릿 에이전시의 바뀌기 전 대화를 받아, 해당 조건들을 전부 수렴하여 수정한 대화를 객체에 키와 값으로 담아 반환하세요. 같은 캐릭터가 두 번 말했다면, 공백을 한 칸 둔 채로 대화 내용에 추가되어야 합니다. 대화는 문자열로 제공되며, 하이픈- 으로 구분됩니다.문자열은 전부 싱글 쿼터로 제공되며, 전체를 감싸는 문자열은 더블 쿼터로 제공됩니다.
예: "['Blue', 'Green', 'null'] : 'hello. im G.' - ['Black', 'red', 'true']: '? what? who are you?'"
문제는 대화 내용이 담긴 문자열을 입력받아, 문자열을 파싱하여 재구성을 하려고 합니다.
예시를 이용하여 순차적으로 작성
-
"['Blue', 'Green', 'null'] : 'hello. im G.' - ['Black', 'red', 'true']: '? what? who are you?'" 입력값으로 받은 문자열을 각 캐릭터와 대화에 맞게 문자열로 파싱을 하고, 파싱한 문자열을 상대로 캐릭터와 대화를 구분합니다.
-
첫 번째 파싱은
-을 기준으로 ['Blue', 'Green', 'null'] : 'hello. im G.', ['Black', 'red', 'true']: '? what? who are you?' 두 부분으로 나눕니다. -
두 번째 파싱은
:을 기준으로 ['Blue', 'Green', 'null'] 배열과 'hello. im G.' 문자열로 나눕니다.
-
-
배열과 문자열을 사용해, 조건에 맞게 변형합니다.
- 소속이 셋 중 하나인가 판별합니다.
- ['Blue', 'Green', 'null'] 아이디와 닉네임의 길이를 2진수로 바꾼 뒤, 숫자를 더합니다: [1, 2, 'null']
- 'hello. im G.' 10 글자가 넘기 때문에, .,-+@#$%^&* 를 삭제합니다: 'hello im G'
- 'hello im G' 띄어쓰기를 기준으로 문자열을 반전합니다: 'olleh mi G'
- 'olleh mi G' 소문자와 대문자를 반전합니다: 'OLLEH MI g'
-
변형한 배열과 문자열을 키와 값으로 받아 객체에 넣습니다.
- { "[1, 2, 'null']": 'OLLEH MI g' }
이렇듯, 문제에 대한 이해를 바탕으로 제시하는 조건을 하나도 빠짐없이 처리해야 정답을 받을 수 있다
하나라도 놓친다면 통과할 수 없게 되고, 길어진 코드 때문에 헷갈릴 수도 있으니 주의해야 한다
Dynamic Programming
탐욕 알고리즘과 함께 언급하는 알고리즘으로, Dynamic Programming(DP; 동적 계획법) 이 있다
줄임말로는 DP라고 하는 이 알고리즘은, 탐욕 알고리즘과 같이 작은 문제에서부터 출발한다는 점은 같다, 그러나 탐욕 알고리즘이 매 순간 최적의 선택을 찾는 방식이라면, Dynamic Programming은 모든 경우의 수를 조합해 최적의 해법을 찾는 방식이다
Dynamic Programming의 원리는 간단하다
주어진 문제를 여러 개의 하위 문제로 나누어 풀고, 하위 문제들의 해결 방법을 결합하여 최종 문제를 해결하는 문제 해결 방식이다
하위 문제를 계산한 뒤 그 해결책을 저장하고, 나중에 동일한 하위 문제를 만날 경우 저장된 해결책을 적용해 계산 횟수를 줄인다
다시 말해, 하나의 문제는 단 한 번만 풀도록 하는 알고리즘이 바로 이 다이내믹 프로그래밍이다
다이내믹 프로그래밍은 다음 두 가지 가정이 만족하는 조건에서 사용할 수 있다
- 큰 문제를 작은 문제로 나눌 수 있고, 이 작은 문제가 중복해서 발견된다(Overlapping Sub-problems)
- 작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 같다. 즉, 작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다 (Optimal Substructure)
그렇다면 이 두 가지 조건이 의미하는 바를 조금 더 깊이 확인해 보자
첫 번째 조건인 큰 문제를 작은 문제로 나눌 수 있고, 이 작은 문제가 중복해서 발견된다 (Overlapping Sub-problems) 는 큰 문제로부터 나누어진 작은 문제는 큰 문제를 해결할 때 여러 번 반복해서 사용될 수 있어야 한다 는 말과 같다
이를 확인하기 위해, 피보나치 수열을 예로 살펴보자
피보나치 수열은 첫째와 둘째 항이 1이며, 그 뒤의 모든 항은 바로 앞 두 항의 합과 같은 수열이다
피보나치 수열을 재귀 함수로 구현해 보면, 다음과 같이 작성할 수 있다
function fib(n) {
if(n <= 2) return 1;
return fib(n - 1) + fib(n - 2);
}
// 1, 1, 2, 3, 5, 8...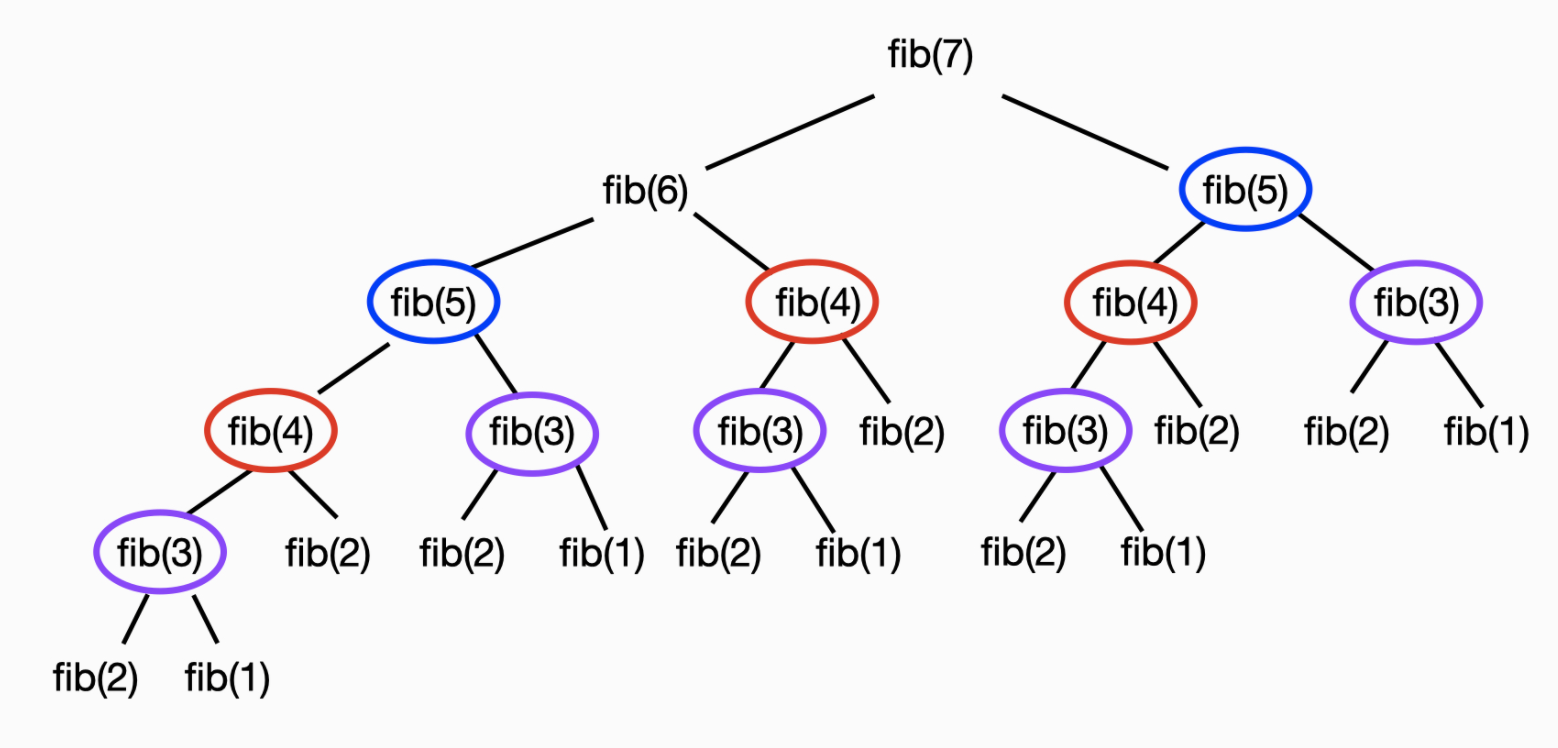
7번째 피보나치 수 fib(7) 를 구하는 과정은 다음과 같다
fib(7) = fib(6) + fib(5)
fib(7) = (fib(5) + fib(4)) + fib(5) // fib(6) = fib(5) + fib(4)
fib(7) = ((fib(4) + fib(3)) + fib(4)) + (fib(4) + fib(3)) // fib(5) = fib(4) + fib(3)
.....피보나치 수열은 위 예시처럼 동일한 계산을 반복적으로 수행해야 한다
이 과정에서 fib(5) 는 두 번, fib(4) 는 세 번, fib(3) 은 다섯 번의 동일한 계산을 반복한다
이렇게 작은 문제의 결과를 큰 문제를 해결하기 위해 여러 번 반복하여 사용할 수 있을 때, 부분 문제의 반복(Overlapping Sub-problems)이라는 조건을 만족한다
그러나 이 조건을 만족하는지 확인하기 전에, 한 가지 주의해야 할 점이 있다
주어진 문제를 단순히 반복 계산하여 해결하는 것이 아니라, 작은 문제의 결과가 큰 문제를 해결하는 데에 여러 번 사용될 수 있어야 한다
두 번째 조건인 작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 동일하다
즉, 작은 문제에서 구한 정답을 큰 문제에서도 사용할 수 있다(Optimal Substructure). 에 대해 살펴보자
이 조건에서 말하는 정답은 최적의 해결 방법(Optimal solution)을 의미한다
따라서 두 번째 조건을 달리 표현하면, 주어진 문제에 대한 최적의 해법을 구할 때, 주어진 문제의 작은 문제들의 최적의 해법(Optimal solution of Sub-problems)을 찾아야 한다 그리고 작은 문제들의 최적의 해법을 결합하면, 결국 전체 문제의 최적의 해법(Optimal solution)을 구할 수 있다
최단 경로를 찾는 문제를 통해 이 조건을 살펴보자
A에서 D로 가는 최단 경로를 찾아야 한다
다음과 같이 각 지점이 있고, 한 지점에서 다른 지점으로 갈 수 있는 경로와 해당 경로의 거리는 다음과 같습니다.
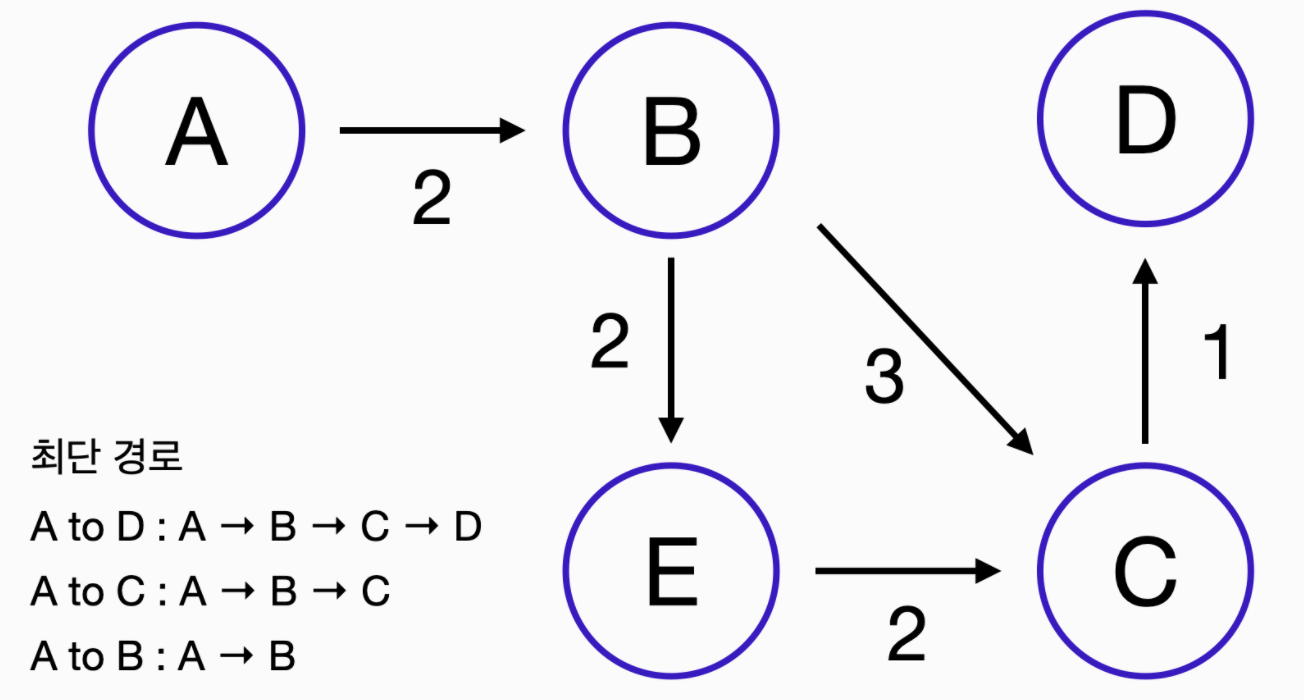
A에서 D로 가는 최단 경로는 A → B → C → D 다
그렇다면 A에서 C로 가는 최단 경로는 어떨까요? A → B → E → C가 아닌 A → B → C 다
마지막으로 A에서 B로 가는 최단 경로는? 당연히 A → B 다
정리해보면 A에서 D로 가는 최단 경로는 그것의 작은 문제인 A에서 C로 가는 최단 경로, 그리고 한번 더 작은 문제인 A에서 B로 가는 최단 경로의 파악할 수 있다
이렇게 다이내믹 프로그래밍을 적용하기 위해서는, 작은 문제의 최적 해법을 결합하여 최종 문제의 최적 해법을 구할 수 있어야 한다
이어지는 콘텐츠에서는 다이내믹 프로그래밍을 이용하여 피보나치 수열 문제를 해결해보자
Recursion + Memoization
다이내믹 프로그래밍은 하위 문제의 해결책을 저장한 뒤, 동일한 하위 문제가 나왔을 경우 저장해 놓은 해결책을 이용한다
이때 결과를 저장하는 방법을 Memoization이라고 한다
Memoization의 정의는 컴퓨터 프로그램이 동일한 계산을 반복해야 할 때, 이전에 계산한 값을 메모리에 저장함으로써 동일한 계산의 반복 수행을 제거하여 프로그램 실행 속도를 빠르게 하는 기술 이다
재귀 함수에 Memorization을 어떻게 적용할지 다음의 예시를 통해 확인하자
function fibMemo(n, memo = []) {
// 이미 해결한 하위 문제인지 찾아본다
if(memo[n] !== undefined) return memo[n];
if(n <= 2) return 1;
// 없다면 재귀로 결괏값을 도출하여 res 에 할당
let res = fibMemo(n-1, memo) + fibMemo(n-2, memo);
// 추후 동일한 문제를 만났을 때 사용하기 위해 리턴 전에 memo 에 저장
memo[n] = res;
return res;
}-
먼저 fibMemo 함수의 파라미터로 n 과 빈 배열을 전달한다, 이 빈 배열은 하위 문제의 결괏값을 저장하는 데에 사용한다
-
memo 라는 빈 배열의 n번째 인덱스가 undefined 이 아니라면, 다시 말해 n 번째 인덱스에 어떤 값이 저장되어 있다면, 저장되어 있는 값을 그대로 사용한다
-
undefined라면, 즉 처음 계산하는 수라면 fibMemo(n-1, memo) + fibMemo(n-2, memo)를 이용하여 값을 계산하고, 그 결괏값을 res 라는 변수에 할당한다
-
마지막으로 res 를 리턴하기 전에 memo 의 n 번째 인덱스에 res 값을 저장한다
이렇게 하면 (n+1)번째의 값을 구하고 싶을 때, n번째 값을 memo 에서 확인해 사용할 수 있다
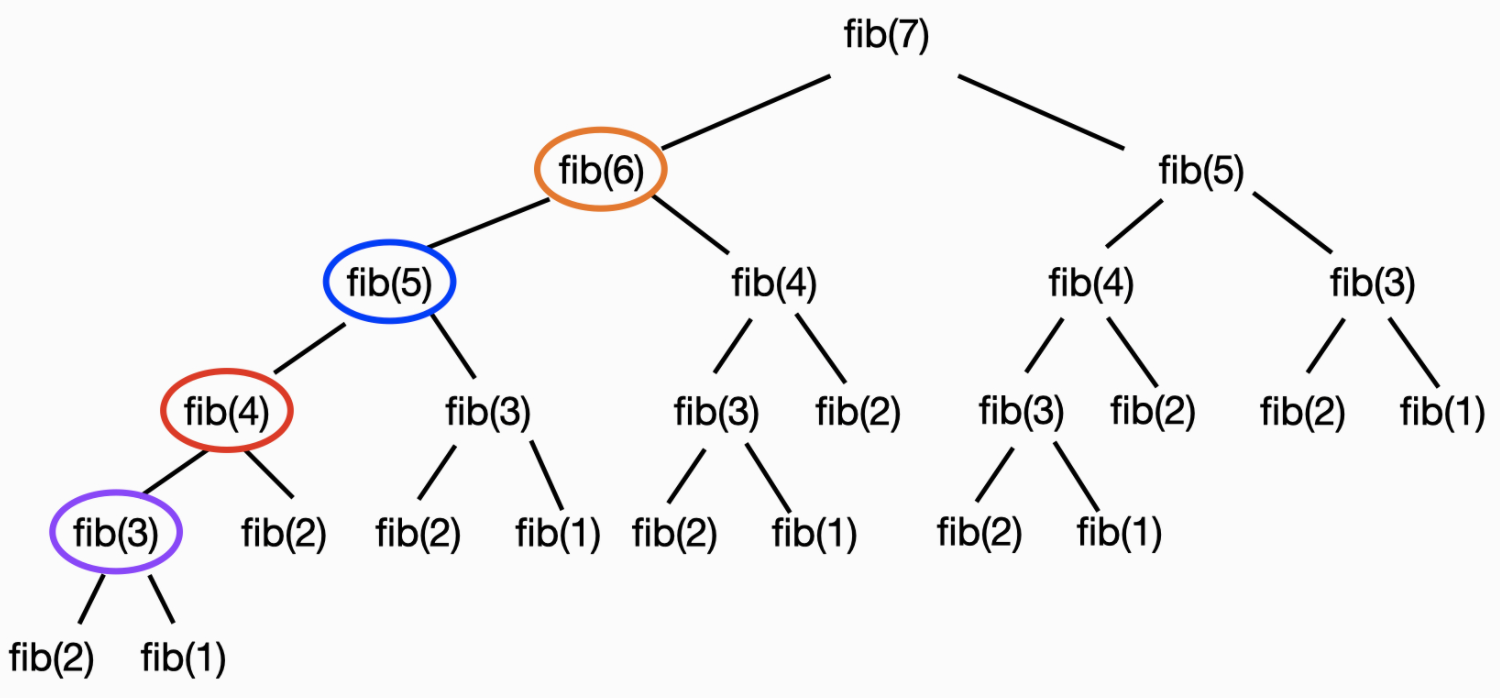
fib(7) 을 구하기 위해서는 이전의 작업으로 저장해 놓은 하위 문제의 결괏값을 사용한다
n이 커질수록 계산해야 할 과정은 선형으로 늘어나기 때문에 시간 복잡도는 O(N) 이 된다
Memorization을 사용하지 않고 재귀 함수로만 문제를 풀 경우, n이 커질수록 계산해야 할 과정이 두 배씩 늘어나 시간 복잡도가 O(2^N)에 되는 것과 비교하였을 때, 다이내믹 프로그래밍의 강점을 확인할 수 있다
다이내믹 프로그래밍을 적용한 피보나치 수열에서 fib(7)을 구하기 위해 fib(6)을, fib(6)을 구하기 위해 fib(5)을 호출한다
이런 풀이 과정이 마치, 위에서 아래로 내려가는 것과 같다
큰 문제를 해결하기 위해 작은 문제를 호출한다고 하여, 이 방식을 Top-down 방식이라 부르기도 한다
Iteration + Tabulation
이번에는 반복문을 이용하여 다이내믹 프로그래밍을 구현한다
하위 문제의 결괏값을 배열에 저장하고, 필요할 때 조회하여 사용하는 것은 재귀 함수를 이용한 방법과 같다
그러나 재귀 함수를 이용한 방법이 문제를 해결하기 위해 큰 문제부터 시작하여 작은 문제로 옮아가며 문제를 해결하였다면,
반복문을 이용한 방법은 작은 문제에서부터 시작하여 큰 문제를 해결해 나가는 방법이다 따라서 이 방식을 Bottom-up 방식 이라 부르기도 한다
function fibTab(n) {
if(n <= 2) return 1;
let fibNum = [0, 1, 1];
// n 이 1 & 2일 때의 값을 미리 배열에 저장해 놓는다
for(let i = 3; i <= n; i++) {
fibNum[i] = fibNum[i-1] + fibNum[i-2];
// n >= 3 부터는 앞서 배열에 저장해 놓은 값들을 이용하여
// n번째 피보나치 수를 구한 뒤 배열에 저장 후 리턴한다
}
return fibNum[n];
}피보나치 수열을 3가지 방법으로 구현했다
이렇게 구현한 3가지 방법이 시간 복잡도를 얼마나 효과적으로 개선하였는지 눈으로 직접 확인해야 한다
위 3가지 코드들을 크롬 개발자 도구에 복사한 뒤 동일한 수를 입력하였을 때 결괏값을 얻기까지 과연 얼마의 시간이 소요되는지 확인해보고,
시간을 측정하는 방법은 이 콘텐츠의 하단의 "크롬 개발자 도구에서 함수 실행 시간 측정 방법"을 참고하고,
특히 Top-down과 Bottom-up이 과연 동일한 소요 시간을 갖는지 확인해보자
직접 코드를 실행하며 결과에 대한 원인을 분석해보자
크롬 개발자 도구에서 함수 실행 시간 측정 방법
함수의 실행 시간을 측정하는 방법은 여러 가지가 있다
그중에서 다음의 방법으로 간단하게 함수의 실행 시간을 확인할 수 있다
var t0 = performance.now();
fib(50); // 여기에서 함수 실행을 시켜주세요
var t1 = performance.now();
console.log("runtime: " + (t1 - t0) + 'ms')