대부분의 회원 가입이 필요한 서비스는 비밀번호 설정 시 특정 조건에 맞추어 입력하라고 요구한다
비밀번호 설정에 특정 조건을 요구하는 것은 보안 때문이지만, 그렇다면 해당 서비스의 관리자는 어떻게 비밀번호의 입력 조건을 설정하고 관리할까?
다양한 방법이 있겠지만 문자열 관리를 간단하게 하는 방법으로 정규표현식이 있다
정규표현식을 한 문장으로 정의하면 문자열에서 특정한 문자를 찾아내는 도구다
이를 이용하면 수십 줄이 필요한 코딩 작업을 간단하게 한두 줄로 끝낼 수 있다
정규표현식은 특정한 규칙을 갖는 문자열로 이루어진 표현식이며, 정규표현식에서 특수 문자는 각각의 고유한 규칙을 갖고 있다
우리는 이러한 규칙들을 조합하여 원하는 패턴을 만들고, 특정 문자열에서 해당 패턴과 대응하는 문자를 찾을 수 있다
이러한 정규표현식을 사용한 예시를 보면,
아래의 코드는 사용자가 입력한 이메일이나 휴대전화 번호가 유효한지 확인하고자 할 때 사용하는 정규표현식이다
정규표현식을 사용한다면, 한 줄의 코드만으로 이메일이나 휴대전화 번호의 유효성을 검사할 수 있지만, 만약 그렇지 않았다면 같은 결과를 얻기 위해서는 굉장히 긴 코드가 필요했을 것이다
이메일 유효성 검사
let regExp = /^[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_.]?[0-9a-zA-Z])*.[a-zA-Z]{2,3}$/i;
휴대전화 번호 유효성 검사
let regExp = /^01([0|1|6|7|8|9]?)-?([0-9]{3,4})-?([0-9]{4})$/;
이러한 정규표현식은 알고리즘 문제를 풀 때에도 적용할 수 있다
예시 문제를 통해 정규표현식을 알고리즘 문제에 적용했을 때의 이점을 확인해 보자
문제
문자열 str 이 주어질 때, str의 길이가 5 또는 7이면서 숫자로만 구성되어 있는지를 확인해 주는 함수를 작성하세요. 결과는 Boolean으로 리턴됩니다. 예를 들어 str가 c2021이면 false, 20212이면 true를 리턴합니다.
정규표현식을 사용하지 않고 이 문제를 해결하기 위한 코드를 작성한다면, 보통은 조건문을 통해 문자열 str의 길이와 문자의 포함 여부를 확인하는 방식으로 문제 풀이 코드를 작성했을 것이다
하지만 정규표현식을 이용하면 이 과정을 아래와 같이 한 줄로 줄일 수 있다
function solution(str) {
return /^\d{5}$|^\d{7}$/.test(str);
}이처럼 정규표현식을 알아두면 문자열을 다룰 때 코드를 간결하게 줄일 수 있는 유리한 상황이 있다
정규표현식 사용하기
정규표현식은 두 가지 방법으로 사용할 수 있다
리터럴 패턴
정규표현식 규칙을 슬래시(/)로 감싸 사용한다
슬래시 안에 들어온 문자열이 찾고자 하는 문자열이며, 컴퓨터에게 '슬래시 사이에 있는 문자열을 찾고 싶어!'라고 명령을 내리는 것이다
let pattern = /c/;
// 'c 를 찾을 거야!' 라고 컴퓨터에게 명령을 내리는 것입니다.
// 찾고 싶은 c를 pattern 이라는 변수에 담아놨기 때문에 이 변수를 이용하여 c 를 찾을 수 있습니다.생성자 함수 호출 패턴
RegExp 객체의 생성자 함수를 호출하여 사용한다
let pattern = new RegExp('c');
// new 를 이용해서 정규 표현식 객체를 생성하고,
// 리터럴 패턴과 동일하게 'c 를 찾을 거야!' 라는 명령입니다.정규표현식 내장 메소드
RegExp 객체의 메소드
exec()
exec 는 execution 의 줄임말로, 원하는 정보를 뽑아내고자 할 때 사용한다
검색의 대상이 찾고자 하는 문자열에 대한 정보를 가지고 있다면 이를 배열로 반환하며, 찾는 문자열이 없다면 null을 반환한다
let pattern = /c/; // 찾고자 하는 문자열
pattern.exec('code') // 검색하려는 대상을 exec 메소드의 첫 번째 인자로 전달합니다.
// 즉, 'code' 가 'c' 를 포함하고 있는지를 확인합니다.
// 이 경우 'c' 가 포함되어 있으므로, ['c'] 를 반환합니다.test()
찾고자 하는 문자열이 대상 안에 있는지의 여부를 boolean 으로 리턴한다
let pattern = /c/;
pattern.test('code');
// 이 경우는 'code'가 'c'를 포함하고 있으므로 true 를 리턴합니다.String 객체의 메소드
match()
RegExp.exec() 와 비슷한 기능을 하며, 정규 표현식을 인자로 받아 주어진 문자열과 일치된 결과를 배열로 반환한다
일치되는 결과가 없으면 nulㅣ 을 리턴한다
let pattern = /c/;
let str = 'code';
str.match(pattern);
// str 안에 pattern 이 포함되어 있으므로, ['c'] 를 반환합니다.replace()
'검색 후 바꾸기'를 수행한다
첫 번째 인자로는 정규표현식을 받고, 두 번째 인자로는 치환하려는 문자열을 받는다
문자열에서 찾고자 하는 대상을 검색해서 이를 치환하려는 문자열로 변경 후 변경된 값을 리턴한다
let pattern = /c/;
let str = 'code';
str.replace(pattern, 'C');
// str 안에서 pattern 을 검색한 후 'C' 로 변경하여 그 결과를 리턴합니다.
// 여기서는 'Code'가 반환됩니다.split()
주어진 인자를 구분자로 삼아, 문자열을 부분 문자열로 나누어 그 결과를 배열로 반환한다
"123,456,789".split(",") // ["123", "456", "789"]
"12304560789".split("0") // ["123", "456", "789"]search()
정규표현식을 인자로 받아 가장 처음 매칭되는 부분 문자열의 위치를 반환한다
매칭되는 문자열이 없으면 -1을 반환합니다.
"JavaScript".search(/script/); // -1 대소문자를 구분합니다
"JavaScript".search(/Script/); // 4
"code".search(/ode/); // 1flag
정규표현식은 플래그를 설정해 줄 수 있으며, 플래그는 추가적인 검색 옵션의 역할을 해 준다
이 플래그들은 각자 혹은 함께 사용하는 것이 모두 가능하며, 순서에 구분이 없다
i
i를 붙이면 대소문자를 구분하지 않는다
let withi = /c/i;
let withouti = /c/;
"Codestates".match(withi); // ['C']
"Code".match(withouti); // nullg
global 의 약자로, g 를 붙이면 검색된 모든 결과를 리턴한다
let withg = /c/g;
let withoutg = /c/;
"coolcode".match(withg); // ['c', 'c']
"coolcode".match(withoutg); // ['c'] g 가 없으면 첫 번째 검색 결과만 반환합니다m
m을 붙이면 다중행을 검색한다
let str = `1st : cool
2nd : code
3rd : study`;
str.match(/c/gm)
// 3개의 행을 검색하여 모든 c 를 반환합니다.
// ['c', 'c']
str.match(/c/m)
// m은 다중행을 검색하게 해 주지만, g 를 빼고 검색하면 검색 대상을 찾는 순간 검색을 멈추기 때문에
// 첫 행의 ['c'] 만 리턴합니다.정규식 패턴(표현식)
정규표현식에 다양한 특수기호를 함께 사용하면 문자열을 다룰 때에 더 많은 옵션을 설정할 수 있다
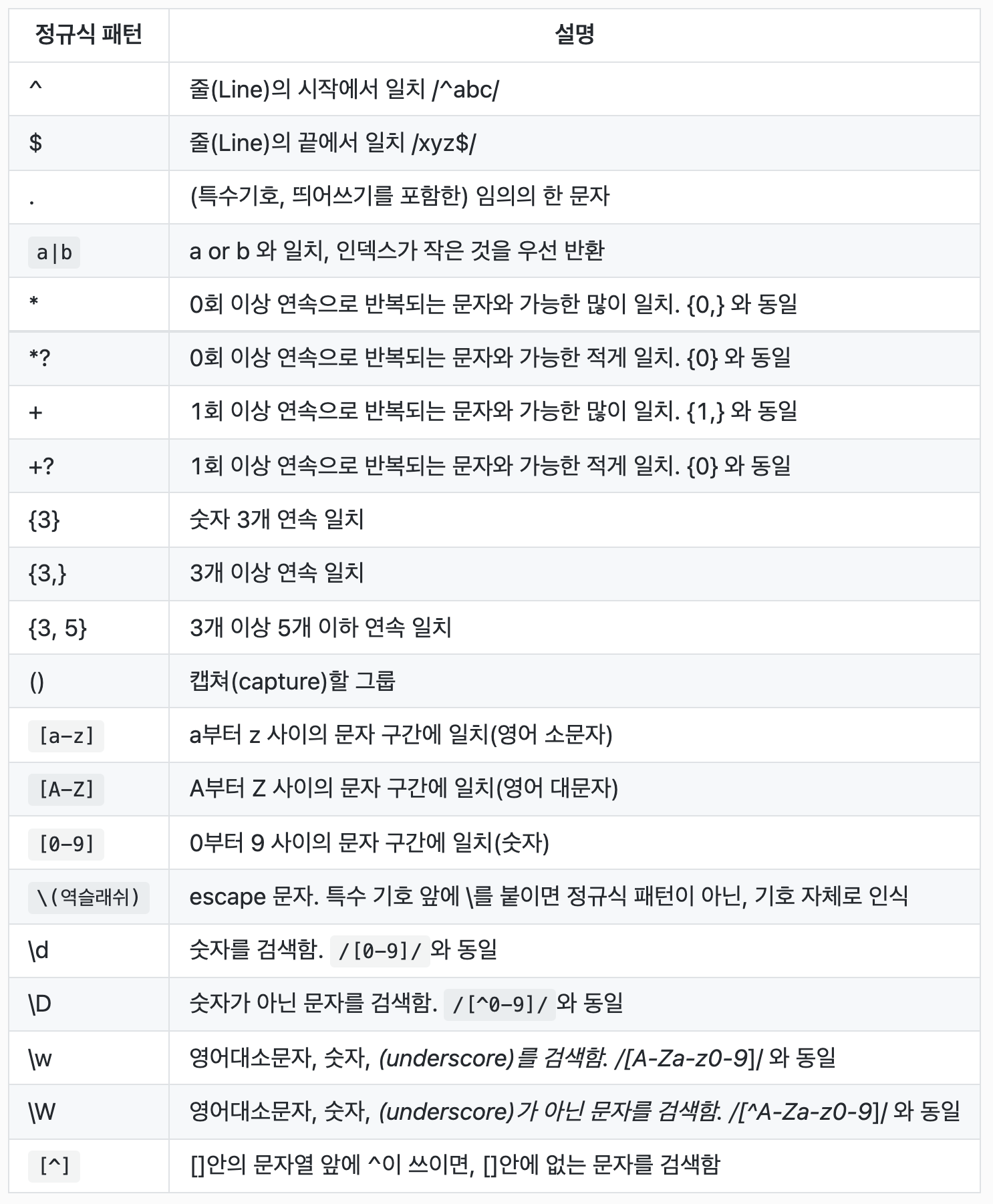
Anchors - ^ and $
^
^ 는 문자열의 처음을 의미하며, 문자열에서 ^뒤에 붙은 단어로 시작하는 부분을 찾는다
일치하는 부분이 있더라도, 그 부분이 문자열의 시작 부분이 아니면 null 을 리턴한다
"coding is fun".match(/^co/); // ['co']
"coding is fun".match(/^fun/); // null$
$는 문자열의 끝을 의미하며, 문자열에서 $앞의 표현식으로 끝나는 부분을 찾는다
^와 비슷하지만 ^는 문자열의 시작을 찾는 반면, $는 문자열의 마지막 부분을 찾는다
마찬가지로 일치하는 부분이 있더라도, 그 부분이 문자열의 끝부분이 아니면 null 을 리턴한다
"coding is fun".match(/un$/); // ['un']
"coding is fun".match(/is$/); // null
"coding is fun".match(/^coding is fun$/);
// 문자열을 ^ 와 $ 로 감싸주면 그 사이에 들어간 문자열과 정확하게 일치하는 부분을 찾습니다
// ["coding is fun"]Quantifiers — *, +, ? and {}
*
*는 *바로 앞의 문자가 0번 이상 나타나는 경우를 검색한다
아래와 같은 문자열이 있을 때에 /ode*/g 을 사용하게 되면 "od" 가 들어가면서 그 뒤에 "e"가 0번 이상 포함된 모든 문자열을 리턴합니다.
"co cod code codee coding codeeeeee codingding".match(/ode*/g);
// ["od", "ode", "odee", "od", "odeeeeee", "od"]
+
+ 도 * 와 같은 방식으로 작동하며, 다만 + 바로 앞의 문자가 1번 이상 나타나는 경우를 검색한다는 점이 *과 다를 뿐이다
"co cod code codee coding codeeeeee codingding".match(/ode*/g);
// ["ode", "odee", "odeeeeee"]?
? 는 * 또는 + 와 비슷하지만, ? 앞의 문자가 0번 혹은 1번 나타나는 경우만 검색한다
*? 또는 +? 와 같이 ?는 * 혹은 + 와 함께 쓰는 것도 가능하며, 함께 사용하였을 경우 검색 결과가 어떻게 달라지는지 아래 예시를 통해 비교해 보세요.
"co cod code codee coding codeeeeee codingding".match(/ode?/g);
// ["od", "ode", "ode", "od", "ode", "od"]
"co cod code codee coding codeeeeee codingding".match(/ode*?/g);
// ["od", "od", "od", "od", "od", "od"]
"co cod code codee coding codeeeeee codingding".match(/ode+?/g);
// ["ode", "ode", "ode"]{}
{}는 *, *?, +, +? 의 확장판으로 생각할 수 있다
*, *?, +, +? 가 '0개 이상' 또는 '1개 이상' 검색이 전부였던 반면, {}는 직접 숫자를 넣어서 연속되는 개수를 설정할 수 있다
아래 예시와 함께 위 표에서 {}와 *, *?, +, +? 의 차이를 다시 한 번 비교해 보자
"co cod code codee coding codeeeeee codingding".match(/ode{2}/g);
// 2개의 "e"를 포함한 문자열을 검색합니다.
// ["odee", "odee"]
"co cod code codee coding codeeeeee codingding".match(/ode{2,}/g);
// 2개 이상의 "e"를 포함한 문자열을 검색합니다.
// ["odee", "odeeeeee"]
"co cod code codee coding codeeeeee codingding".match(/ode{2,5}/g);
// 2개 이상 5개 이하의 "e"를 포함한 문자열을 검색합니다.
// ["odee", "odeeeee"]OR operator
| 는 or 조건으로 검색하여 | 의 왼쪽 또는 오른쪽의 검색 결과를 반환한다
"Cc Oo Dd Ee".match(/O|D/g); // ["O", "D"]
"Cc Oo Dd Ee".match(/c|e/g); // ["c", "e"]
"Cc Oo Dd Ee".match(/D|e/g); // ["D", "e"]
"Ccc Ooo DDd EEeee".match(/D+|e+/g); // + 는 1번 이상 반복을 의미하기 때문에
// ["DD", "eee"] 를 반환합니다.Bracket Operator - []
대괄호 [] 안에 명시된 값을 검색한다
[abc] // a or b or c 를 검색합니다. or(|) Operator 로 작성한 a|b|c 와 동일하게 작동합니다.
[a-c] // [abc] 와 동일합니다. - 로 검색 구간을 설정할 수 있습니다.
"Ccc Ooo DDd EEeee".match(/[CD]+/g); // [] 에 + 등의 기호를 함께 사용할 수도 있습니다.
// C or D 가 한 번 이상 반복된 문자열을 반복 검색하기 때문에
// ["C", "DD"] 가 반환됩니다.
"Ccc Ooo DDd EEeee".match(/[co]+/g); // ["cc", "oo"]
"Ccc Ooo DDd EEeee".match(/[c-o]+/g); // - 때문에 c ~ o 구간을 검색하여
// ["cc", "oo", "d", "eee"] 가 반환됩니다.
"AA 12 ZZ Ad %% Az !# dd 54 zz".match(/[A-Za-z]+/g);
// a~z 또는 A~Z 에서 한 번 이상 반복되는 문자열을 반복 검색하기 때문에
// ["AA", "ZZ", "Ad", "Az", "dd", "zz"] 를 반환합니다.
"AA 12 ZZ Ad %% Az !# dd 54 zz".match(/[A-Z]+/gi);
// flag i 는 대소문자를 구분하지 않기 때문에 위와 동일한 결과를 반환합니다.
// ["AA", "ZZ", "Ad", "Az", "dd", "zz"]
"AA 12 ZZ Ad %% Az !# dd 54 zz".match(/[0-9]+/g);
// 숫자도 검색 가능합니다.
// ["12", "54"]
"aAbB$#67Xz@9".match(/[^a-zA-Z]+/g);
// [] 안에 ^ 를 사용하면 anchor 로서의 문자열의 처음을 찾는것이 아닌
// 부정을 나타내기 때문에 [] 안에 없는 값을 검색합니다.
// ["$#67", "@9"]Character classes
\d & \D
\d 의 d 는 digit 을 의미하며 0 ~ 9 사이의 숫자 하나를 검색한다
[0-9] 와 동일하다
\D 는 not Digit 을 의미하며, 숫자가 아닌 문자 하나를 검색한다
[^0-9] 와 동일하다
"abc34".match(/\d/); // ["3"]
"abc34".match(/[0-9]/) // ["3"]
"abc34".match(/\d/g); // ["3", "4"]
"abc34".match(/[0-9]/g) // ["3", "4"]
"abc34".match(/\D/); // ["a"]
"abc34".match(/[^0-9]/); // ["a"]
"abc34".match(/\D/g); // ["a", "b", "c"]
"abc34".match(/[^0-9]/g); // ["a", "b", "c"]\w & \W
\w 는 알파벳 대소문자, 숫자, (underbar) 중 하나를 검색한다
[a-zA-Z0-9]와 동일하다
\W 는 알파벳 대소문자, 숫자, (underbar)가 아닌 문자 하나를 검색한다 [^a-zA-Z0-9]와 동일하다
"ab3_@A.Kr".match(/\w/); //["a"]
"ab3_@A.Kr".match(/[a-zA-Z0-9_]/) // ["a"]
"ab3_@A.Kr".match(/\w/g); //["a", "b", "3", "_", "A", "K", "r"]
"ab3_@A.Kr".match(/[a-zA-Z0-9_]/g) // ["a", "b", "3", "_", "A", "K", "r"]
"ab3_@A.Kr".match(/\W/); // ["@"]
"ab3_@A.Kr".match(/[^a-zA-Z0-9_]/); // ["@"]
"ab3_@A.Kr".match(/\W/g); // ["@", "."]
"ab3_@A.Kr".match(/[^a-zA-Z0-9_]/g); // ["@", "."]Grouping and capturing
()
()는 그룹으로 묶는다는 의미 이외에도 다른 몇 가지 의미가 더 있다
그룹화
표현식의 일부를 ()로 묶어주면 그 안의 내용을 하나로 그룹화할 수 있다
아래 예시를 통해 그룹화와 그렇지 않은 결과의 차이를 비교해 보자
let co = 'coco';
let cooo = 'cooocooo';
co.match(/co+/); // ["co", index: 0, input: "coco", groups: undefined]
cooo.match(/co+/); // ["cooo", index: 0, input: "cooocooo", groups: undefined]
co.match(/(co)+/); // ["coco", "co", index: 0, input: "coco", groups: undefined]
cooo.match(/(co)+/); // ["co", "co", index: 0, input: "cooocooo", groups: undefined]co+ 는 "c"를 검색하고 + 가 "o"를 1회 이상 연속으로 반복되는 문자를 검색해 주기 때문에 "cooo"가 반환되었다
하지만 (co)+ 는 "c" 와 "o" 를 그룹화하여 "co"를 단위로 1회 이상 반복을 검색하기 때문에 "coco"가 반환되었다
여기서 특이한 점은 일치하는 문자열로 반환된 결과가 2개다
이제 이 이유에 대해 알아보자
캡처
() 로 그룹화한다고 하였고, 이를 캡처한다 라고 한다
그럼 아래 예시를 통해 캡처했을 경우의 작동방식을 확인한다
co.match(/(co)+/); // ["coco", "co", index: 0, input: "coco", groups: undefined]- () 로 "co"를 캡처
- 캡처한 "co" 는 일단 당장 사용하지 않고, + 가 "co"의 1회 이상 연속 반복을 검색
- 이렇게 캡처 이외 표현식이 모두 작동하고 나면, 캡처해 두었던 "co"를 검색
따라서 2번 과정에 의해 "coco" 가 반환되고, 3번에 의해 "co"가 반환되는 것이다
한가지 예시를 더 살펴보자
아래 예시 코드의 검색 및 결과 반환 순서는 다음과 같다
"2021code".match(/(\d+)(\w)/);
// ["2021c", "2021", "c", index: 0, input: "2021code", groups: undefined]()안의 표현식을 순서대로 캡처 ⇒\d+와\w- 캡처 후 남은 표현식으로 검색 ⇒ 이번 예시에는 남은 표현식은 없다
\d로 숫자를 검색하되 + 로 1개 이상 연속되는 숫자를 검색 ⇒ 2021\w로 문자를 검색 ⇒c- 3번과 4번이 조합되어 "2020c" 가 반환
- 첫 번째 캡처한
(\d+)로 인해 2021 이 반환 - 두 번째 캡처한
(\w)로 인해"c"가 반환
문자열 대체 시 캡처된 값 참조
캡처된 값은 replace() 메소드를 사용하여 문자 치환 시 참조 패턴으로 사용될 수 있다
아래 예시를 살펴보자
우선 첫 번째 (\w+) 가 code 를 캡처하고, 두 번째 (\w+) 가 study 를 캡처한다
(/(\w+)\ 와 (\w+)/\사이의 . 은 . 앞에 역슬래시가 사용되었기 때문에 '임의의 한 문자'가 아닌 기호로서의 온점 . 을 의미한다)
각 캡처된 값은 첫 번째는 $1 이 참조, 두 번째는 $2 이 참조하기 때문에 이 참조된 값을 "$2.$1" 이 대체하게 되어 code 와 study 가 뒤바뀐 "study.code" 가 반환된다
"code.study".replace(/(\w+)\.(\w+)/, "$2.$1"); //study.codenon-capturing
() 를 사용하면 그룹화와 캡처를 한다고 하였다
하지만 (?:)로 사용하면 그룹은 만들지만 캡처는 하지 않는다
let co = 'coco';
co.match(/(co)+/); // ["coco", "co", index: 0, input: "coco", groups: undefined]
co.match(/(?:co)+/);
// ["coco", index: 0, input: "coco", groups: undefined]
// 위 "캡처" 예시의 결괏값과 비교해 보시기 바랍니다.lookahead
(?=) 는 검색하려는 문자열에 (?=여기) 에 일치하는 문자가 있어야 (?=여기) 앞의 문자열을 반환한다
"abcde".match(/ab(?=c)/);
// ab 가 c 앞에 있기 때문에 ["ab"] 를 반환합니다.
"abcde".match(/ab(?=d)/);
// d 의 앞은 "abc" 이기 때문에 null 을 반환합니다.negated lookahead
(?!) 는 (?=) 의 부정이다
"abcde".match(/ab(?!c)/); // null
"abcde".match(/ab(?!d)/); // ["ab"]정규표현식은 응용을 통해 유효성 검사뿐 아니라 데이터 스크래핑, 문자열 파싱 등과 같은 다양한 상황에서 사용할 수 있다
더불어 사용법을 숙지해 놓으면 알고리즘 문제에서 더욱 다양한 해결 아이디어를 얻을 수 있다
