1. Introduction
Challenge
- Lack of the large amount of data to train a foundation model for time series analysis
- To address this challenge, propose to leverage pre-trained language models for general time series analysis
Approach
- Unified framework for diverse time series tasks
Extensive empirical studies
- Investigate why a transformer model pre-trained from the language domain can be adapted to time series analysis with almost no change
- Indicates that the self-attention modules acquire the ability to perform certatin non-data-dependent operations through training
- Investigate the resemblance in model behaviors when self-attention is substitued with PCA
Key Contributions
- Unfied framework that uses a frozen pre-trained language model
- Self-attention performs a function similar to PCA, which helps explain the universality of transformer models
- Demonstrate the universality of a pre-trained transformer model from another backbone model (BERT)
3. Methodology
3.1. Model Structure
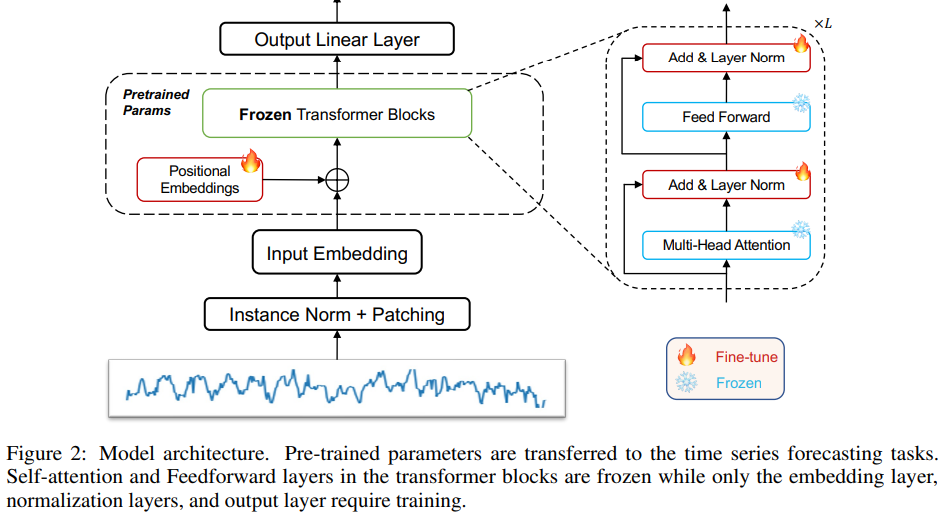
Positional Embeddings and Layer Norm
- Fine-tune the positional embeddings and layer normalization layer
Input Embedding
- Project the time series data to the required dimensions of the specific pre-trained model
Normalization
- RevIN
- This normalization block simply normalizes the input time series using mean and variance, and then adds them back to the output
Patching
- Patching maintain the same token length and reduce information redundancy for transformer models
- Apply patching after instance normalization
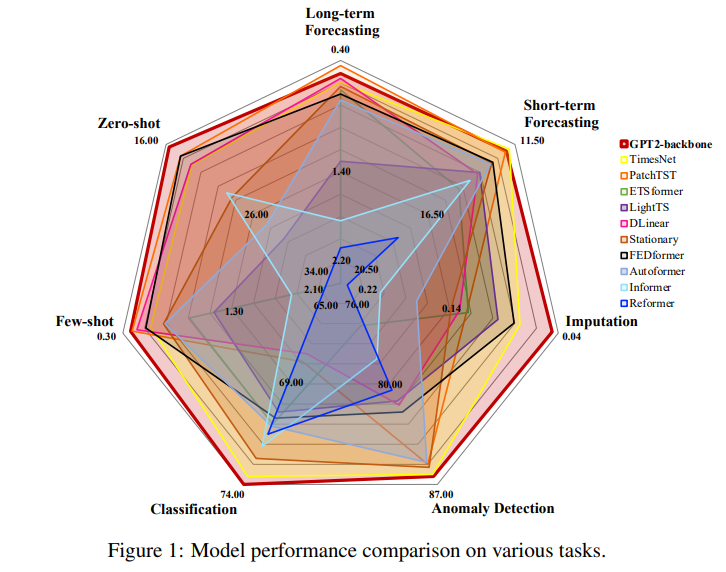
4. Results
8. Towards Understanding the Universality of Transformer: Conneting Self-Attention with PCA
Motivation
- Using a trained LM for time series forecasting without having to modify its model makes us believe that model is generic and independent from texts despite it being trained from text data
Demonstration
- Statistical analysis of the pairwise token similarity values
- Calculate the cosine similarity and result pairwise similiarity matrix of shape
- Count the number of occurrences of similarity values
Analysis
- Within-layer token similarity increases with deeper layers in transformer
Observation
- In randomly intialed GPT2 model, the token similarity is low among all layers
- In gradually switched to the pretrained GPT2 model, the token similarity significantly increases in the deep layers
Explanation for the increasing token similarity
- All token vectors are projected to the low-dimensional top eigenvector space of input patterns
Even though we replace the self-attention module with PCA and find token similarity patterns remain unchanged
