Abstract
Background
- Regularization algorithm to train model,
in which data at training time is severely biased - If the bias is irrelevant to the categorization,
network is likely to learn the bias
Suggestion
- Iterative algorithm to unlearn the bias information
- Employ an additional network to predict the bias distribution and train the network adversarially
- At the end of learning, bias prediciton network is not able to predict the bias
becuase the feature embedding network successfully unlearns the bias
1. Introduction
-
The most ideal way to robustly train a model is to use a suitable data free of bias
-
If biased data is provided during training,
the machine perceives the biased distribution as meaningful information
- It weakens the robustness of the algorithm -
The key criterion is confidence of the predicitons made by the trained model
-
The unknown unknowns
- Model’s predictions are wrong with high confidence
- Much difficult to detect
-
The known unknowns
- Mispredicted data points with low confidence
- Easy to be detected as the classifier’s confidence is low
-
Data bias we consider has a similar flavor to the unknown unknowns
-
The bias does not represent data points themselves
-
The bias represents some attributes of data points such as color, race or gender
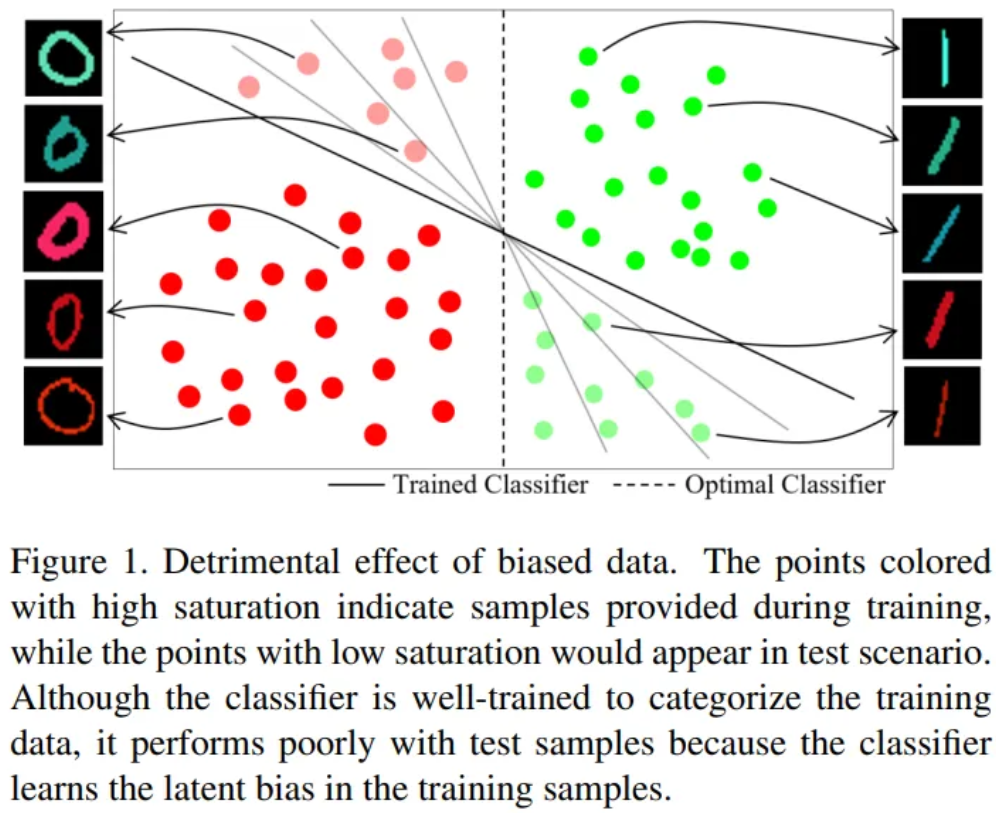
- Propose regularization loss
which prevents learning of a given bias - Regulate a network to minimize the mutual information between
the extracted feature and the bias we want to unlearn - The bias we inted to unlearn is referred to target bias
- e.g. Color in Figure 1
- Assumption
- The existence of data bias is known
- One network is trained to predict the target bias
- The other network is trained to predict the label,
while minimizing the mutual information between the embedded feature and the target bias
Contribution
- Novel regularization term to unlearn target bias
- Propose bias planting protocols
3. Problem Statement
Notation
- Image
- Label
- Set of bias
- every possible target bias that can possess
- e.g. a set of possible colors
- Latent function
- : target bias of
- Feature extractor
- Label prediction network
- Bias prediction network
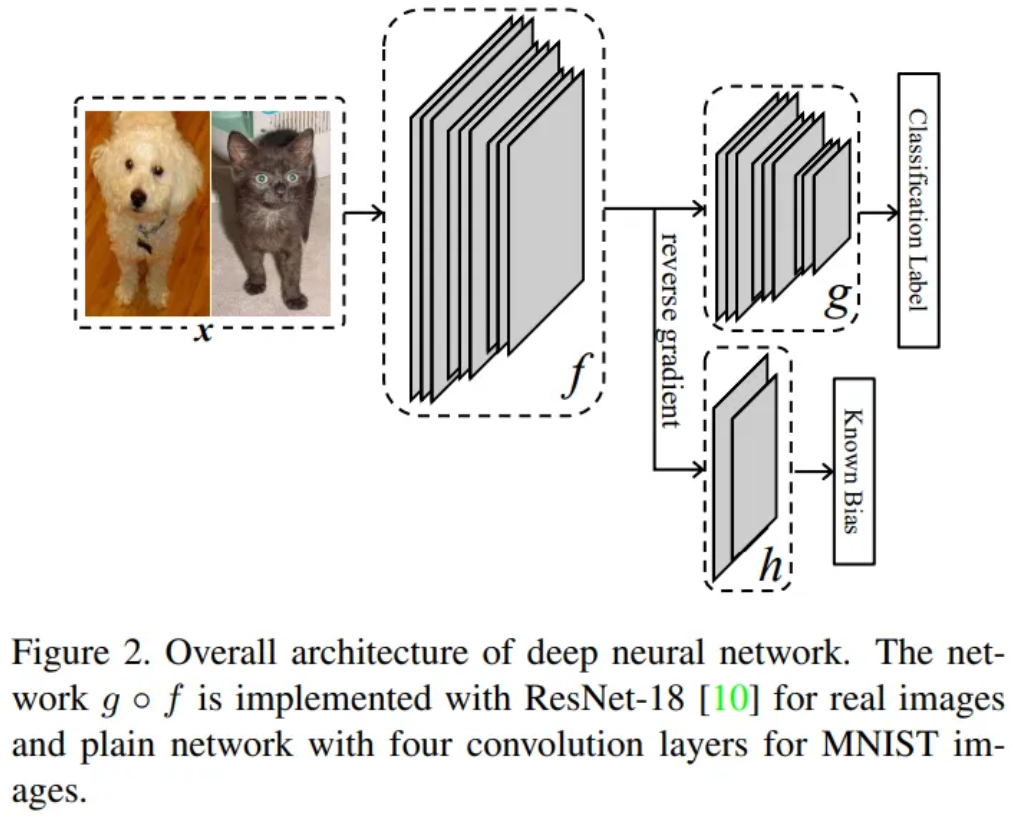
3.1. Formulation
Objective
- Train a network that performs robustly with unbiased data during test time
even though the network is trained with biased data - : mutual information
- Minimize the mutual information , instead of
- Training data is not biased if the network extracts no information of the target bias
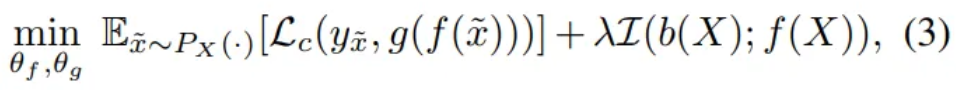
- : Cross entropy loss, : hyper parameter
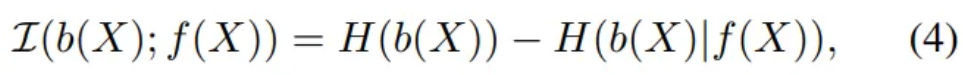
- Marginal and conditional entropy
- Marginal entropy of bias do not depend on model weight
- → Minimize the negative entropy
- = minimizing the expectation of the probability
- Eq. (4) is difficult to minimize as it requires the posterior
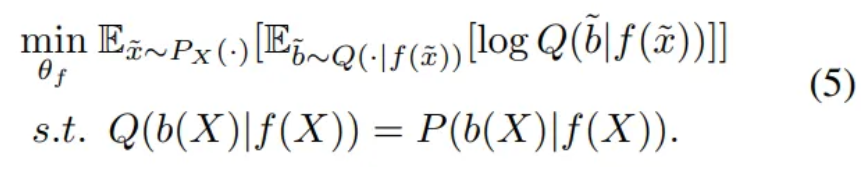
- Use an auxiliary distribution
3.2. Training Procedure
- Eq. (5) is difficult to meet in the beginning of the training process
- Minimize KL divergence between and
→ gets closer to as learning progresses
Relaxed regularization loss
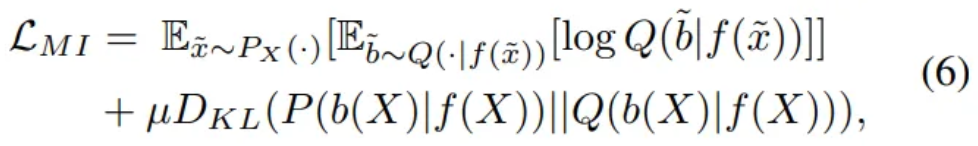
- Parameterize the auxiliary distribution as the bias prediction network
- We will train network , so that the KL-divergence is minimized
→ will converge to - So we only need to train so that the first term in Eq. (6) is minimized
- Bias prediciton network is expected to be trained to approximate with as the label
- Therefore, the expectation of the cross-entropy between and
→ train so that bias prediciton loss is minimized
KL Divergence → Cross entropy
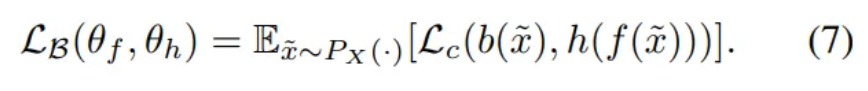
- Also, train to maximize Eq. (7) in an adversarial way
to let the networks and play the minmax game
- is making the bias prediction difficult
Reformulated Eq. (6) using instead of KLD
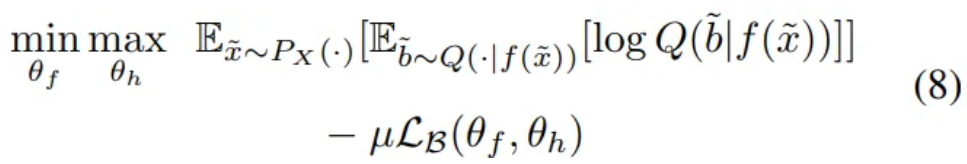
- Train to correctly predict the bias from its feature embedding
- Train to minimize the negative conditional entropy
- is fixed while minimizing the negative conditional entropy
- is also trained to maximize the cross-entropy to restarin
Final formulation
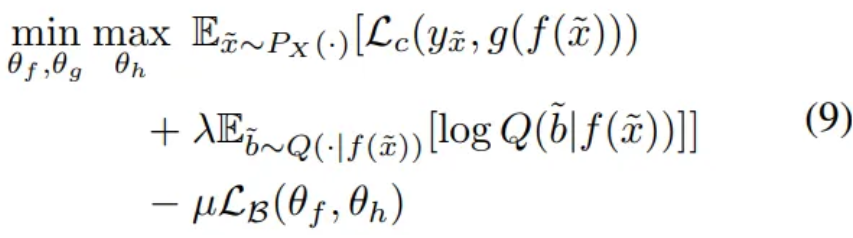
- are trained to classify the label
- learns to predict the bias
begins to learn how to extract feature embedding independent of the bias
4. Dataset
Intentionally plant bias to well balanced public benchmarks to determine whether algorithm could unlearn the bias
4.1. Colored MNIST

Plant a color bias into the MNIST
- Select ten distinct colors and assigned them to each digit category as their mean color
- For each training image, randomly sample a color from the normal distribution for the mean color and provided variance
- For each test image, randomly choose a mean color among the ten colors
- Test sets are unbiased
- Smaller values of indicate more bias in the set
- The color contains
sufficient information to categorize the digits in the training set
insufficient for the images in the test set - Therefore, color information must be removed from the feature embedding
4.2. Dogs and Cats

- Bias set = {dark, bright}
- Test set does not contain color bias
- Ground truth labels for test images are not accessible
- Therefore, we trained an oracle network (ResNet) with all 25K training images
- Persumed that the oracle network could accurately predict the label
4.3. IMDB Face

Public face image dataset
with information regarding age and gender
- The provided label contatins significant noise
→ To filter out misannotated images, we used pretrained networks designed for age and gender classification - Using pretrained networks, estimated the age and gender all the individual label shown in the images
- Collect the image both age and gender labels match with the estimation
- EB1 and EB2 are biased with respect to the age
- EB1 consists of younger female and older male
- EB2 consists of younger male and older female
- When gender is target bias, = {male, female}
- When age is target bias, = {age}
5. Experiments
5.1. Implementation
In the experiments, we removed three target bias
color / age / gender
ResNet for real images / Plain CNN for MNIST
- ResNet was pretrained with Imagenet data except for the last FC layer
- Implement with two convolution layers for color bias and
single fully connected layer for gender and age bias
5.2. Results
Colored MNIST
- Smaller implies severer color bias
- Baseline performance can be used as an indication of training data bias
- Gray represents a network trained with grayscale imges and also tested
- To analyze the effect of the bias and proposed algorithm
re-colored the test images with fixed mean color - In figure 5, baseline show vertical patterns some of which are shared digits 1 and 3
- The mean color of 1 and 3 is similar
- → The baseline network is biased to the color of digit
Dogs and Cats
- Neural nets prefer to categorize images based on shape rather than color
- Table 1 imply that the nets remain biased without regularization
- Unlke the MNIST, conversion would remove a significant amount of information
- Since the original dataset is categorized into bright and dark,
the converted images contain a bias in terms of brightness - GRL itself is able to remove bias
- The prediction of baseline networks don’t change significantly if the colors are similar
- → Baseline networks are biased to color
IMDB Face
- Two experiments
- Classify age independent of gender
- Classify gender independent of age
- Color bias itself is completely independent of the categories
- → Effort to unlearn the bias is purely beneficial for digit categorization
- But, age and gender are not completely independent features
- Deep understanding of the specific data bias must precede the removal of bias
