WEEK 9
User mode vs kernel mode
유저모드 : 접근할 수 있는 영역이 제한되어 있다. 코드를 작성하거나 프로세스를 실행하는 등의 행동이 가능하다.
커널모드: 모든 영역으로의 접근이 가능하다.
유저모드 -> 커널모드로의 전환은 system call을 통해 이루어진다.
ex) 유저모드에서 malloc과 같은 시스템 라이브러리 함수를 호출해 커널모드로 전달 -> 커널모드 전환 후 요청한 일 수행해서 리턴-> 다시 유저모드로 전환
PEB(Process Environment Block)
- 프로세스 환경 정보를 담고 있는 굉장히 큰 구조체
PEB는 커널 모드 구조체가 아니다. 사용자 모드에 사용되기 위해 디자인 되었기 때문에 사용자 모드 주소 공간에 위치한다. PEB 주소를 구하려면 TEB(Thread Environment Block)의 주소를 먼저 구해야한다.
PIB(Process Identifier)
프로세스 식별자는 유닉스 운영체제 커널이 사용하는 번호이다. PID를 통해 프로세스를 일시적으로 식별할 수 있으며 프로세스의 우선순위를 조정하거나 종료하는 등의 다양한 함수 호출에 사용된다.
유닉스 운영체제에서 새로운 프로세스는 fork() 호출을 통해 이루어지는데, 이때 부모 프로세스가 추후에 자식 프로세스들을 가리킬 수 있도록 새로 만들어진 자식 프로세스의 PID를 반환한다. 이렇게 반환된 PID를 통해 부모 프로세스는 자식 프로세스를 기다리거나 종료시킬 수 있다.
Calling Convention(함수 호출 규약)
함수 호출 규약이란 함수의 호출 및 반환에 대한 약속이다. 한 함수에서 다른 함수를 호출할 때, 프로그램은 다른 함수로 이동한다. 그리고 호출한 함수가 리턴하면 다시 원래 함수로 돌아와서 기존의 실행 흐름을 이어나간다.
그러므로 함수를 호출할 때는 반환된 이후를 위해 호출자의 상태 및 반환 주소를 저장해야한다. 또한 호출자는 피호출자가 요구하는 인자를 전달해야하며 피호출자의 실행이 종료될 때는 리턴값을 전달 받아야한다.
함수 호출 규약은 일반적으로 컴파일러가 적용하지만 컴파일러의 도움 없이 어셈블리 코드를 작성하려 하거나 읽고자 한다면 함수 호출 규약을 알아야할 필요가 있다.
X86_64 호출 규약
대부분의 인자는 rdi, rsi, rdx, rcx, r8, r9과 같은 범용 레지스터를 사용한다. 6개보다 많은 인자 전달시 스택에 차례로 push하고 피호출자의 첫번째 instruction으로 점프한다. 이때, 인자의 역순으로 (right to left) 저장하기 때문에 가장 마지막 인자가 먼저 push된다.
그 이후에는 피호출자가 실행되고, 피호출자가 return값을 가지고 있다면 리턴 값은 레지스터 RAX에 저장한다. 피호출자는 ret(return)를 사용해서 스택에 받았던 리턴 주소를 pop하고 그 주소가 가리키는 곳으로 점프함으로서 리턴된다.
floating-point의 경우에는 8개의 SSE 레지스터를 사용한다.
xmm0, xmm1, xmm2, xmm3, xmm4, xmm5, xmm6, xmm7
그보다 많은 인자는 메모리(stack)를 이용한다.
함수의 반환 값은 보통 RAX를 통해 전달되며 float이나 double일 경우에만 XMM0을 통해 전달된다.
모든 매개 변수에는 스택에 예약된 공간이 있으며, caller는 callee의 매개 변수를 위한 공간을 할당해야하기 때문에 매개 변수가 전달되지 않더라도 호출자는 항상 4개의 매개 변수를 위한 공간을 할당해야 한다.
Register vs Memory
사용자가 코드를 입력하면 레지스터에서 데이터를 읽어온 다음 메인 메모리로 저장한다. 그리고 디스크에서 직접 메모리 접근을 통해 기계어 인스트럭션을 메모리로 바로 전달하고, 메모리가 레지스터로 그것을 보내면 레지스터가 파일을 복사하여 디스플레이에 내보낸다.

레지스터는 메인메모리에 저장되어 있는 정보를 실행하는 장치이고 메인 메모리는 프로세서가 프로그램을 실행하는 동안 정보를 저장하는 장치이다. 또한 레지스터는 저장할 수 있는 용량이 작고 빠르지만, 메인 메모리는 저장할 수 있는 용량이 큰 대신 레지스터에 비해 매우 느리다.
Argc, Argv
main(int argc, char *argv[])
여기에서 argc는 프로그램을 실행할 때 지정해 준 명령 옵션의 개수가 저장되고 argv는 프로그램을 실행할 때 지정해 준 명령 옵션의 문자열들이 실제로 저장되는 배열이다.
ELF(Excutable Linkable Format)
리눅스에서 실행 가능하고 링크가 가능한 파일의 format
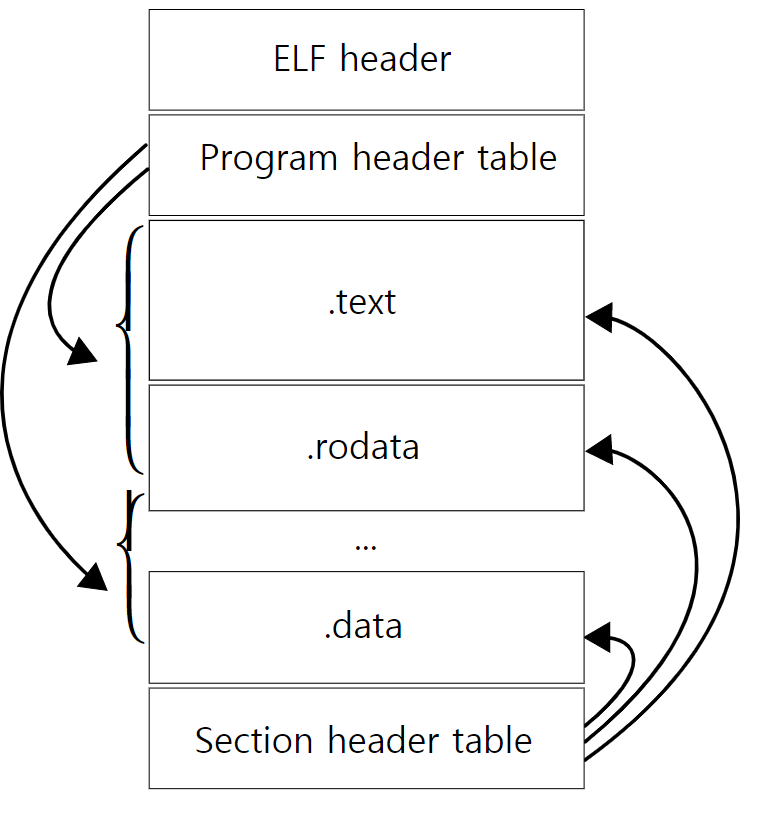
1) ELF Format으로 정의 가능한 파일들
(1) 일반 실행 파일 (normal executable files)
(2) 재배치 가능 오브젝트 파일 (relocatable object files)
(3) 코어 파일 (core files)
(4) 공유 라이브러리(shared libraries)2) ELF Format 형식을 사용하는 실행 파일의 구성
(1) ELF header + program header table
(2) ELF header + section header table
(3) ELF header + program header table + section header tableExecutable Header
모든 ELF 파일은 excutable header로 시작한다.
Section Header
ELF 코드와 데이터는 섹션으로 나누어져 있는데, 섹션의 구조는 각각 내용이 구성된 방식에 따라 다르다. 섹션 헤더에서 그 속성을 찾을 수 있으며, 모든 섹션에 대한 헤더 정보는 섹션 헤더 테이블에서 찾을 수 있다.
섹션은 링커가 바이너리를 해석할 때 편리한 단위로 나눈 것이며, 링킹이 없다면 섹션 헤더 테이블은 불필요하므로 e_shoff 필드는 0이 된다.
Program Headers
바이너리를 실행할 때 바이너리 내부의 코드와 데이터를 세그먼트라는 영역으로 구분하는데, 프로그램 헤더 테이블은 바이너리를 세그먼트의 관점에서 볼 수 있게 해준다.
바이너리를 섹션 관점에서 본다는 것은 정적 링킹의 목적으로 한정한다는 것이며 세그먼트의 관점으로 본다는 것은 운영체제와 링킹 과정을 통해 바이너리가 프로세스의 형태가 되고, 그와 관련된 코드와 데이터를 어떻게 처리할 것인지 다룬다는 의미이다.
출처 글
https://turtleneck.tistory.com/42
https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4_%ED%99%98%EA%B2%BD_%EB%B8%94%EB%A1%9D
https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4_%EC%8B%9D%EB%B3%84%EC%9E%90
https://myreversing.tistory.com/84
https://velog.io/@ohwy0723/Calling-Convention%ED%95%A8%EC%88%98-%ED%98%B8%EC%B6%9C-%EA%B7%9C%EC%95%BD
https://namhyung.github.io/blog/x86_64-calling-convention