[CS231n] 16. Detection + Segmentation (EECS 498-007 / 598-005)

이번 강의에선 객체가 어떤 class에 속하는지 detection하고 객체를 분할하는 방법에 대해 알아볼 것입니다.
Slow R-CNN
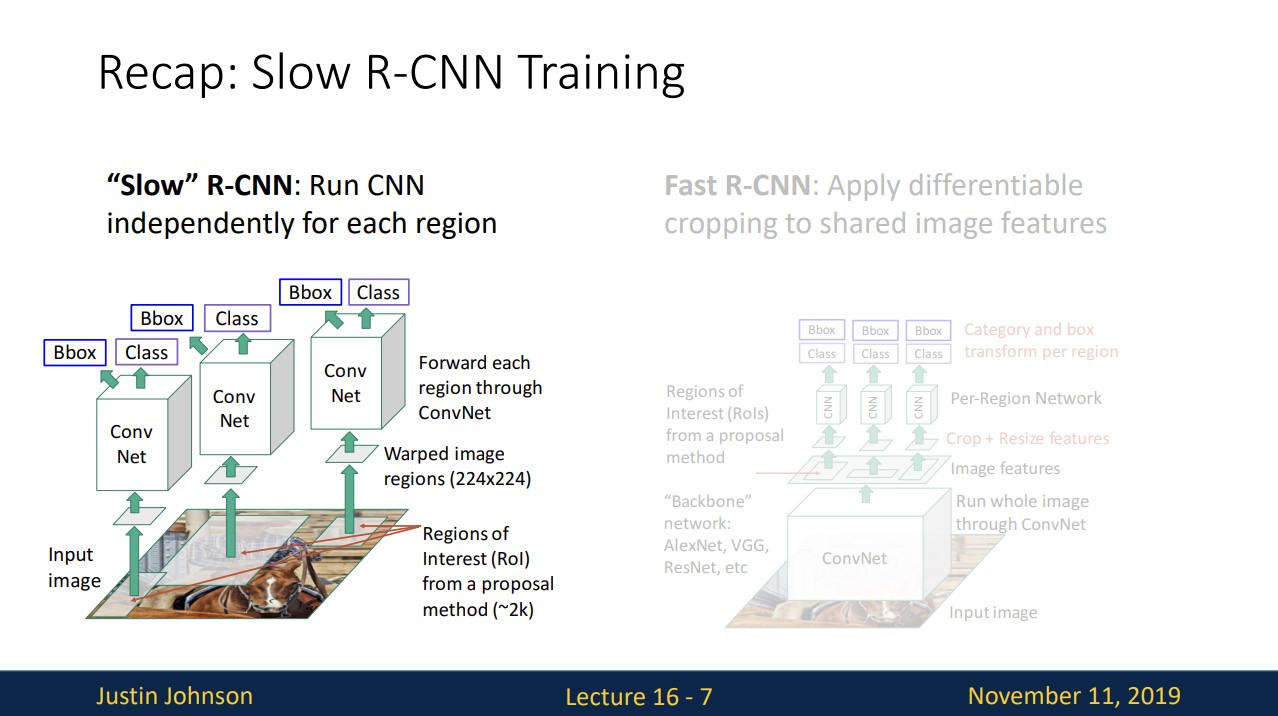
15강에서 배웠던 Slow R-CNN에 대해 복습해보면

selective search와 같은 algorithm을 통해 regions of interest을 구하고 구한 regions of interest와 ground-truth의 IOU를 계산해 positive인지 negative인지 neutral인지 결정합니다.
positive box와 negative box를 224X224로 resize한 뒤에 각각 CNN을 통과해 class와 box offset을 예측합니다. negative box의 경우 class만 예측합니다.
Fast R-CNN

Fast R-CNN에 대해 복습해보면
이미지를 통째로 backbone network에 통과시켜 image의 features를 추출하고
RoI를 구한 다음 positive box인지 negative box인지 구하고 결정한 다음
box를 crop+resize하고 각각 CNN을 통과시켜 class와 box offset을 예측합니다.
Faster R-CNN
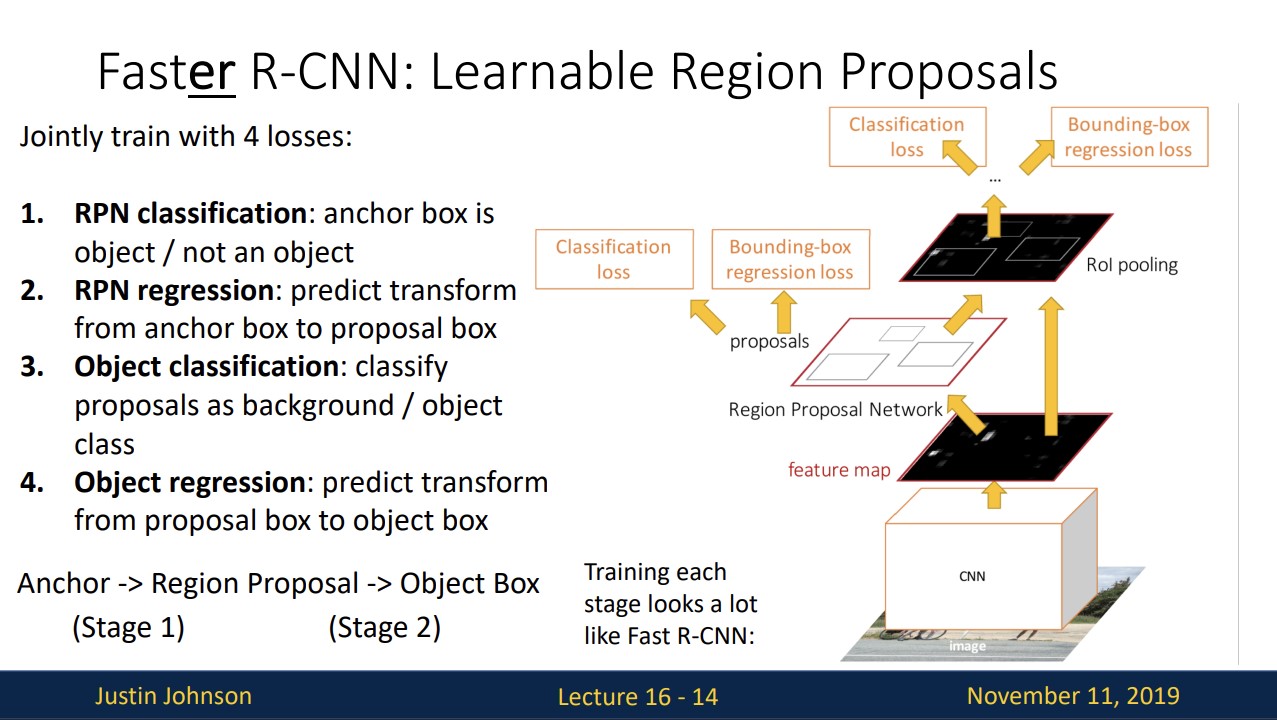
Faster R-CNN은
stage1과 stage2로 나뉘는데
stage1에서 anchor box가 object인지 background인지만 판단, anchor box -> proposal box로 transform
stage2에서는 proposal box를 crop하고 안에 있는 것을 category로 classify, proposal box -> object box로 transform

RPN training과정을 보면 위와 같습니다.

faster R-CNN은 proposal box가 RPN에서 온다는 것만 제외하면 fast R-CNN과 똑같습니다.
Feature Cropping
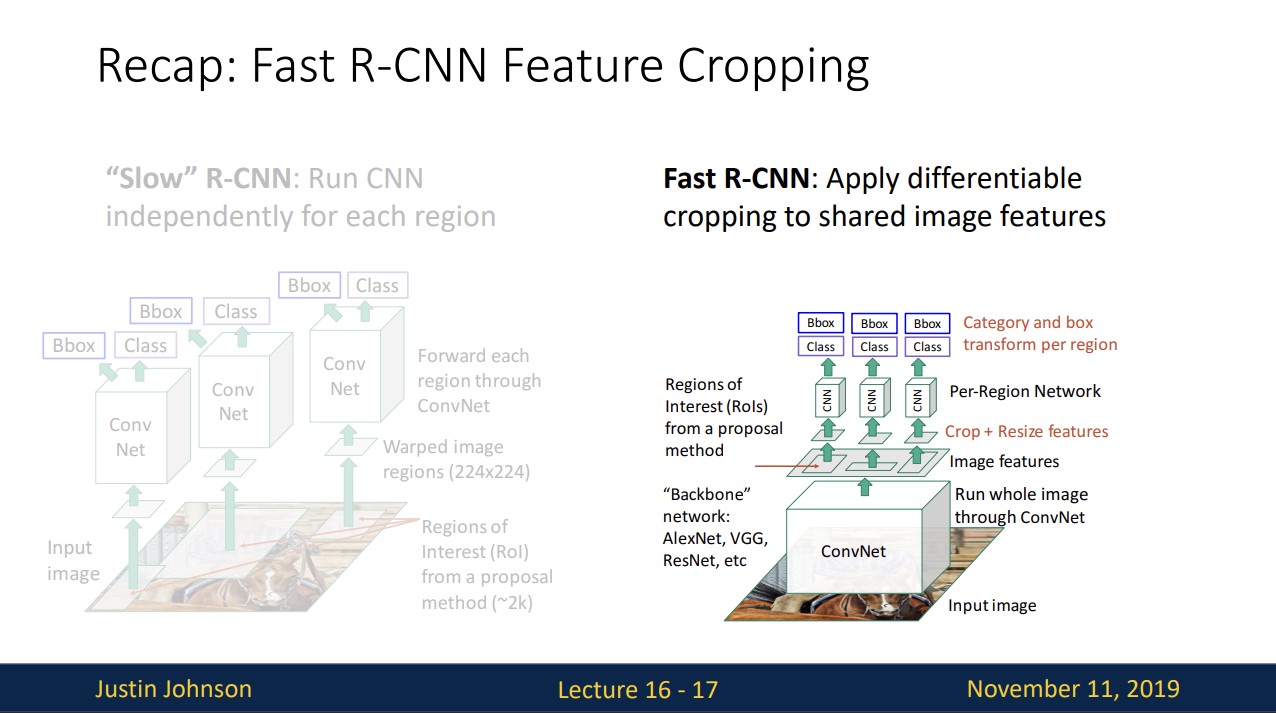
fast R-CNN에서 image의 feature를 crop하는 과정에 대해 보겠습니다.
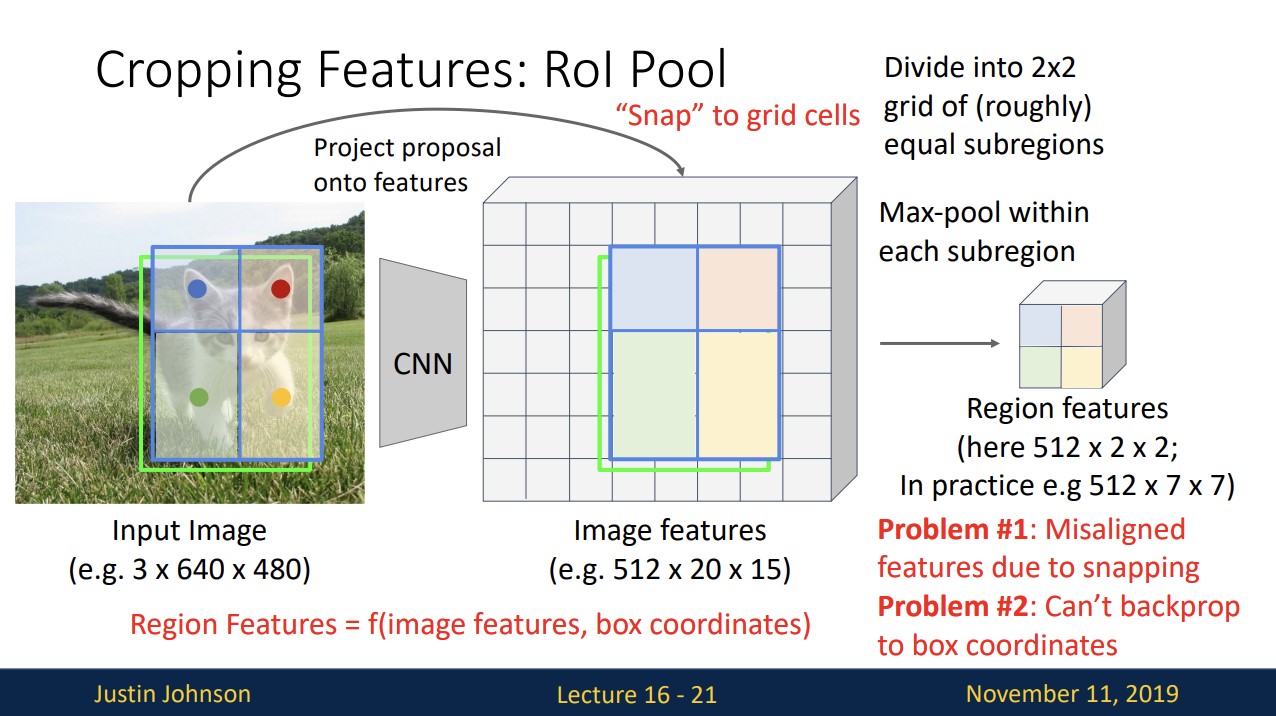
input image를 feature에 project한 후, 그냥 project하면 feature grid에 완벽히 맞지 않기 때문에 feature map에 맞게끔 snap시켜야 합니다. (ex 반올림)
그리고 적당히 2X2로 나눈 다음 각 max pooling을 진행해 2X2의 Region features를 구합니다.
input size가 다르더라도 항상 같은 size의 region features를 얻습니다.
그러나 이 방법엔 문제점이 존재합니다.
snapping을(이동)하면서 기존 box로부터 약간의 misalignment 발생하고
misalignment때문에 backprop이 불가능합니다.
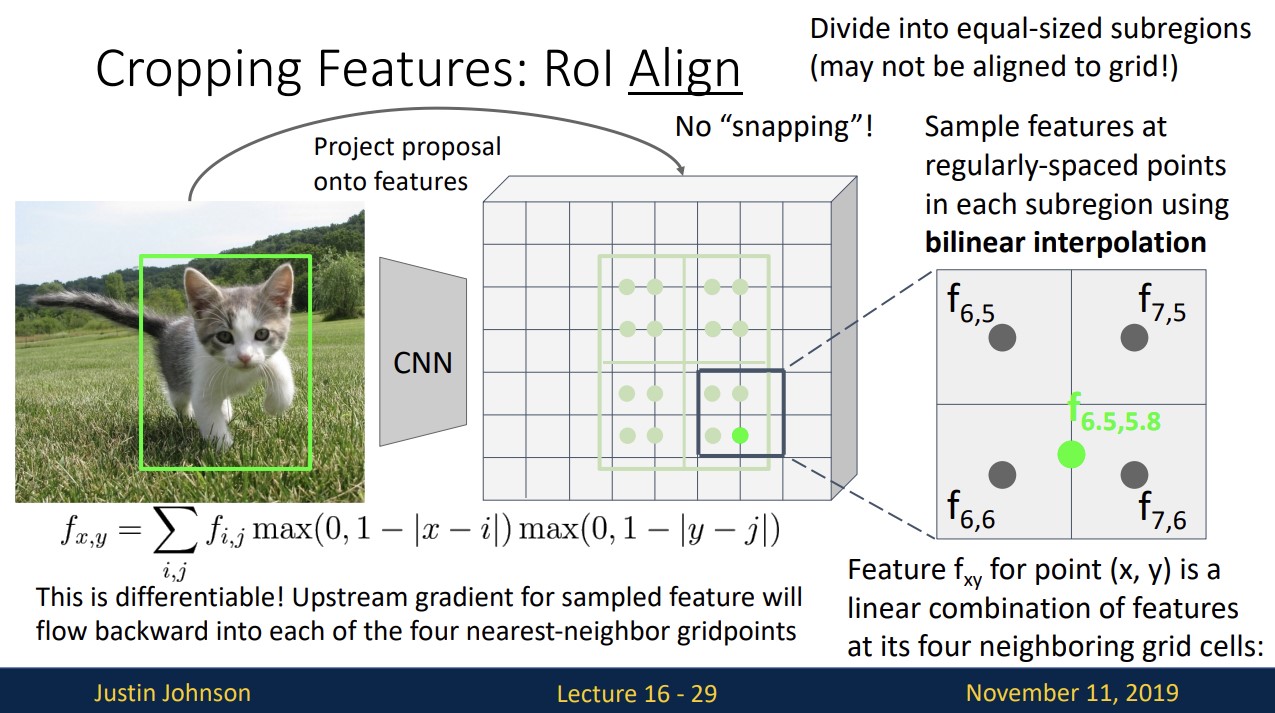
이런 문제점을 해결하고자
가장 가까운 4개의 점으로부터 bilinear interpolation을 사용하여 feature를 추출합니다.
이 방법은 미분이 가능하여 역전파 과정을 가능하게 합니다.
output features의 값 하나가 2X2의 input box의 한 box에 해당합니다.
여태 Object Detection방법은 anchor box에 의존했는데 anchor box에 의존하지 않는 방법은 무엇일까요?
CornerNet

bounding boxes를 왼쪽 위(upper left corner), 오른쪽 아래(lower right corner)의 point pair로 표현합니다.
어떤 pixel이 upper left corner point와 가까운지에 대한 확률,
어떤 pixel이 lower right corner point와 가까운지에 대한 확률을 살핍니다.
Semantic Segmentation

여태 Object Detection에 대해 보았는데, 이제 Semantic Segmentation에 대해 보겠습니다.
Semantic Segmentation은 모든 pixel에 대해 category label을 부여하는 것입니다.
오른쪽 예시를 보면 소 두마리를 각각 독립된 객체로 보지 못하고 소 하나로 분류하는 것을 볼 수 있습니다.
Semantic Segmentation: Sliding Window

각 pixel에 대해 작은 patch를 추출하고 이 patch의 크기만큼 window를 옮기면서 각각 CNN을 통과시켜 classify합니다.
그런데 위 방법은 overlap된 patch끼리 공유된 feature를 사용하지 않기 때문에 연산을 진행하기 때문에 매우 비효율적입니다.
Semantic Segmentation: Fully Convolutional Network
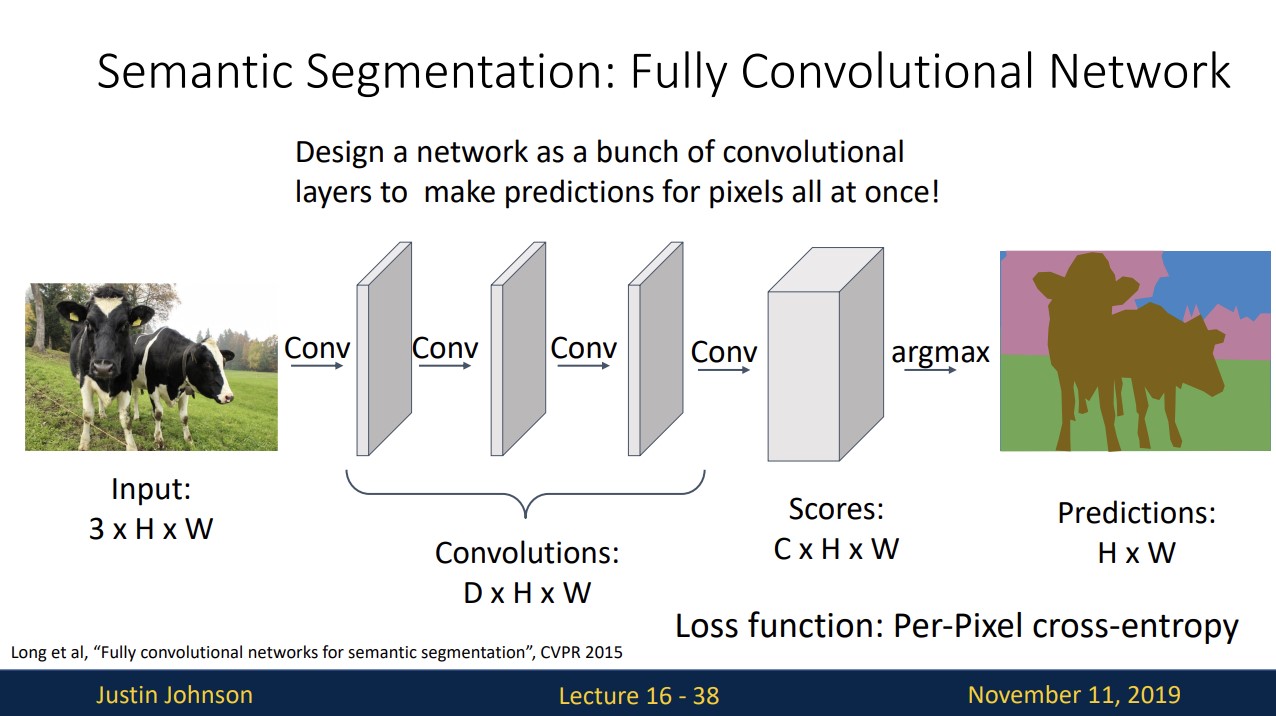
다른 방법으로 conv layer만을 이용하는 것입니다.
input image를 conv layer에 통과시켜 input image와 같은 크기의 output을 도출합니다.
score layer의 C는 category count를 의미하고 각 픽셀별로 category label score을 갖습니다. 각 픽셀에서 softmax를 사용하여 그 픽셀이 어떤 label인지 판단합니다.

그러나 이 방법은 큰 input image일 때 conv layer를 매우 깊게 쌓아야하고
고해상도의 input image를 처리하기 위한 비용이 매우 비쌉니다.
따라서 down sampling이 필요합니다.
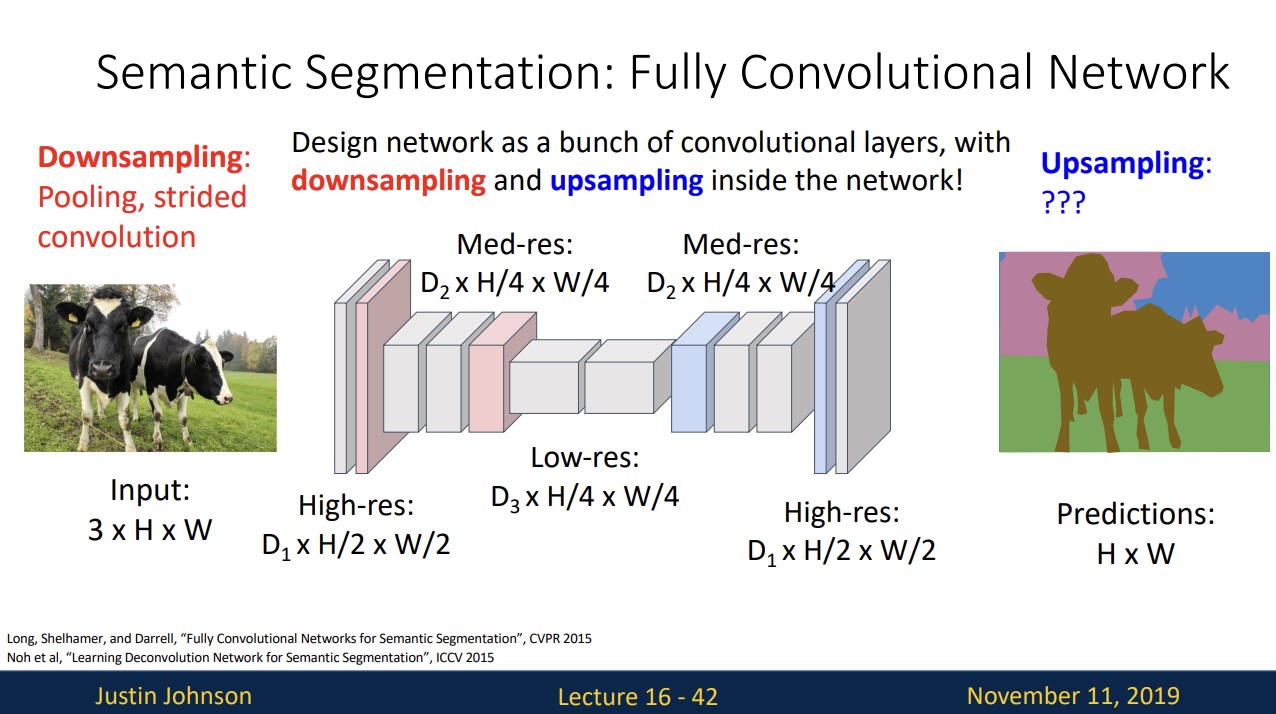
output의 HxW size는 input의 size와 같아야 하기 때문에 downsampling 한다음 upsampling하는 network를 고려할 수 있습니다.
pooling과 stride값을 조절해 downsampling하는 법은 알지만 upsampling은 어떻게 진행할까요?
In-Network Upsampling: Unpooling
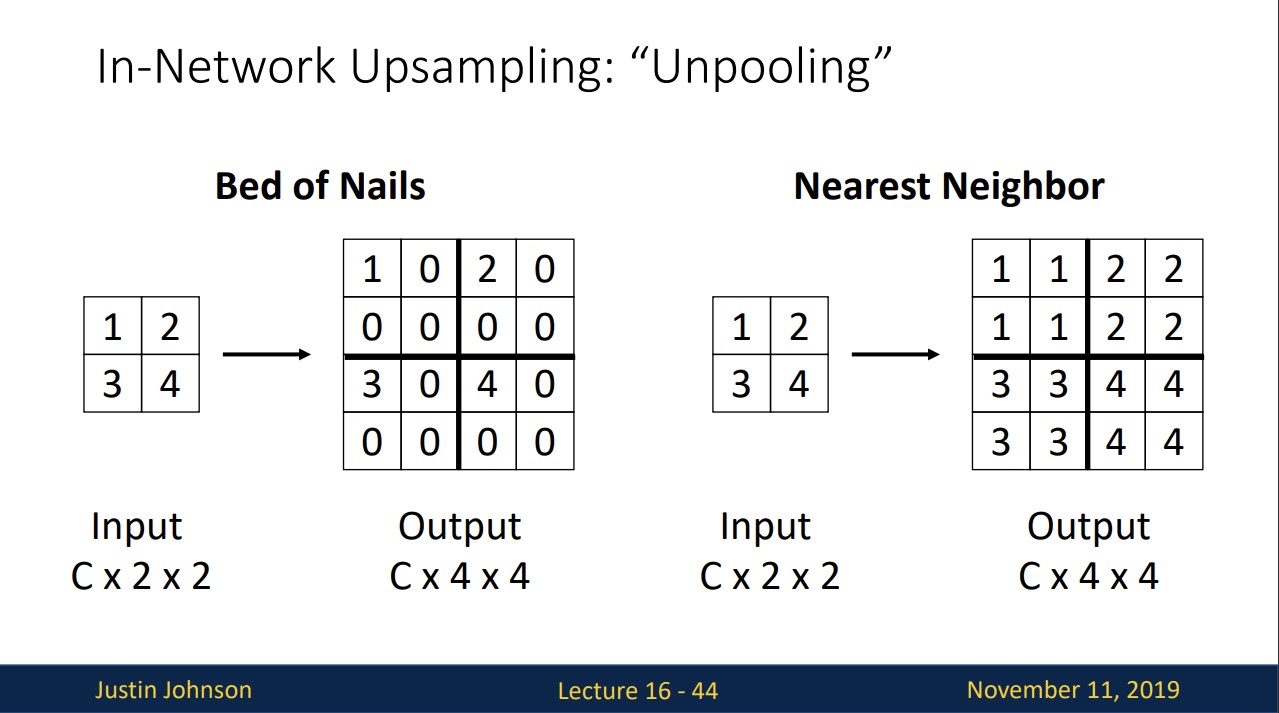
downsampling은 주로 pooling이라고 해서 upsampling은 unpooling이라고 합니다.
Bed of Nails와 Nearest Neighbor은 각각 위와 같은 방법으로 upsamping이 진행됩니다.
Bed of Nails은 해상도의 한계가 나타나고 Nearest Neighbor은 smooth하지 않다는 단점이 있습니다.
In-Network Upsampling: Bilinear Interpolation
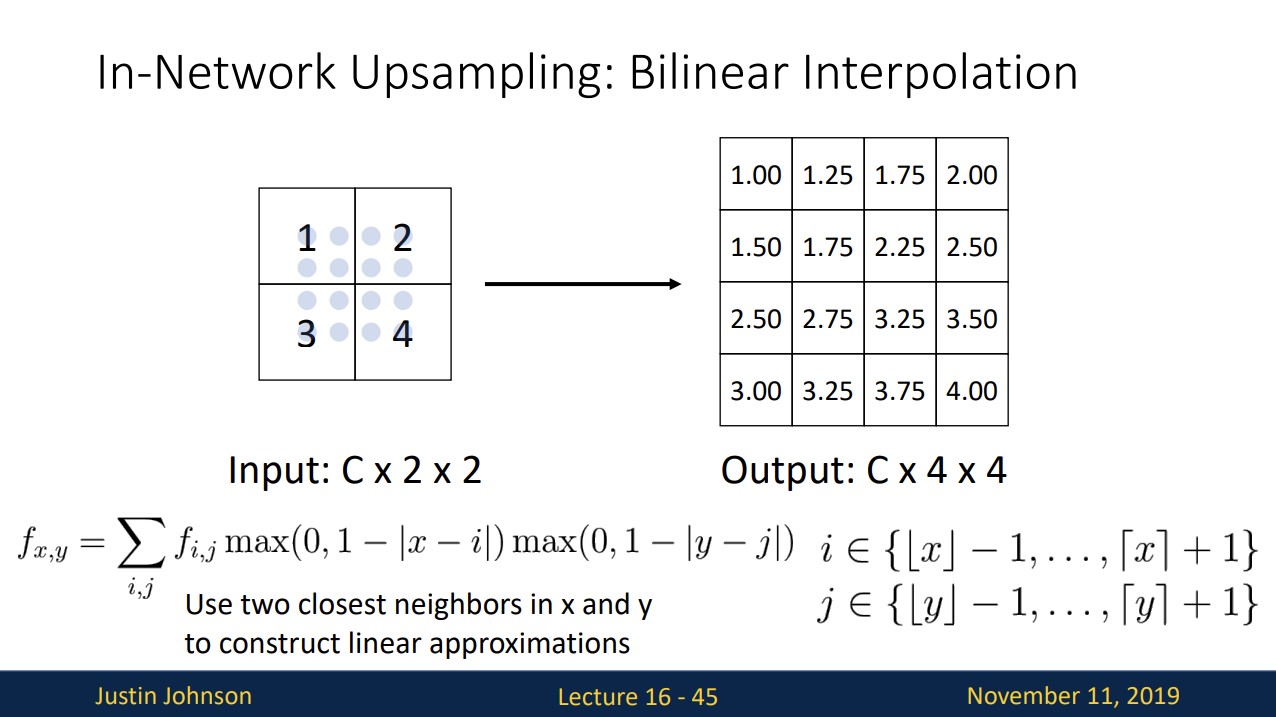
가장 가까운 두 개의 점을 통해 bilinear interpolation을 사용하여 upsampling하는 것이고
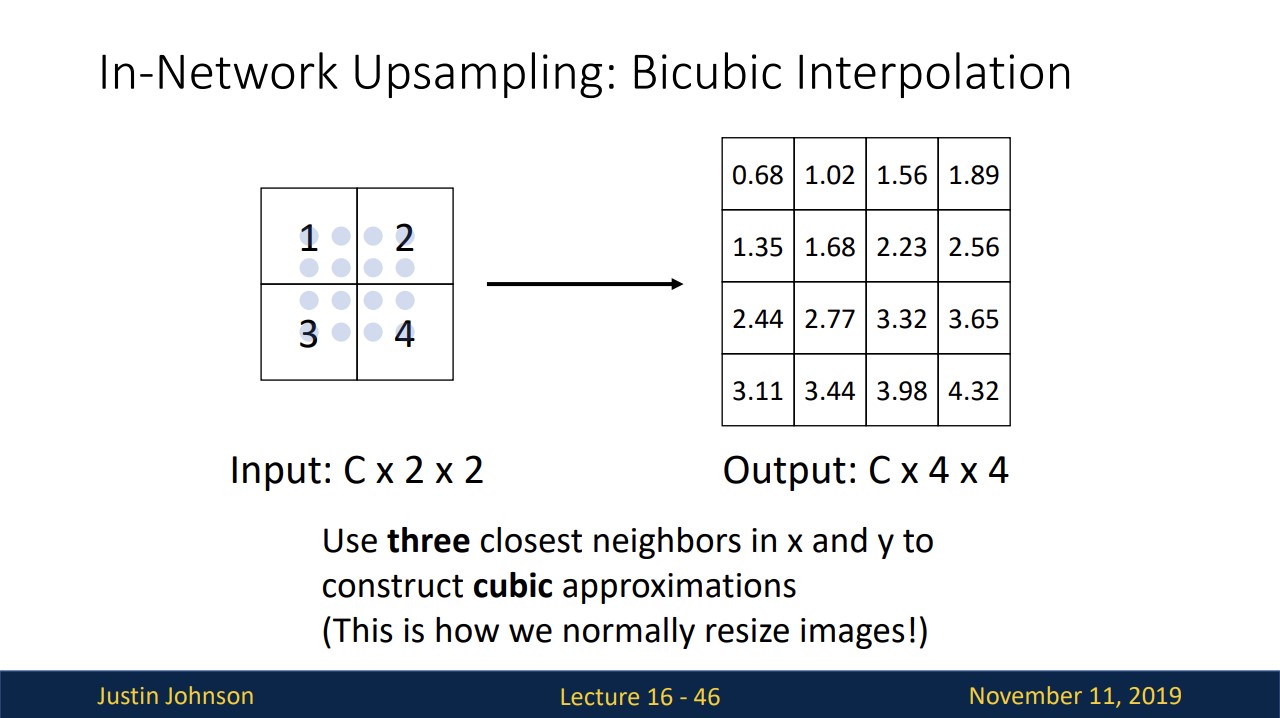
In-Network Upsampling: Bicubic Interpolation
이 방법은 가장 가까운 세 개의 점을 활용해 cubic approximations을 사용하여 upsampling하는 것입니다.
거의 이 방법을 사용한다고 합니다.
In-Network Upsampling: “Max Unpooling”
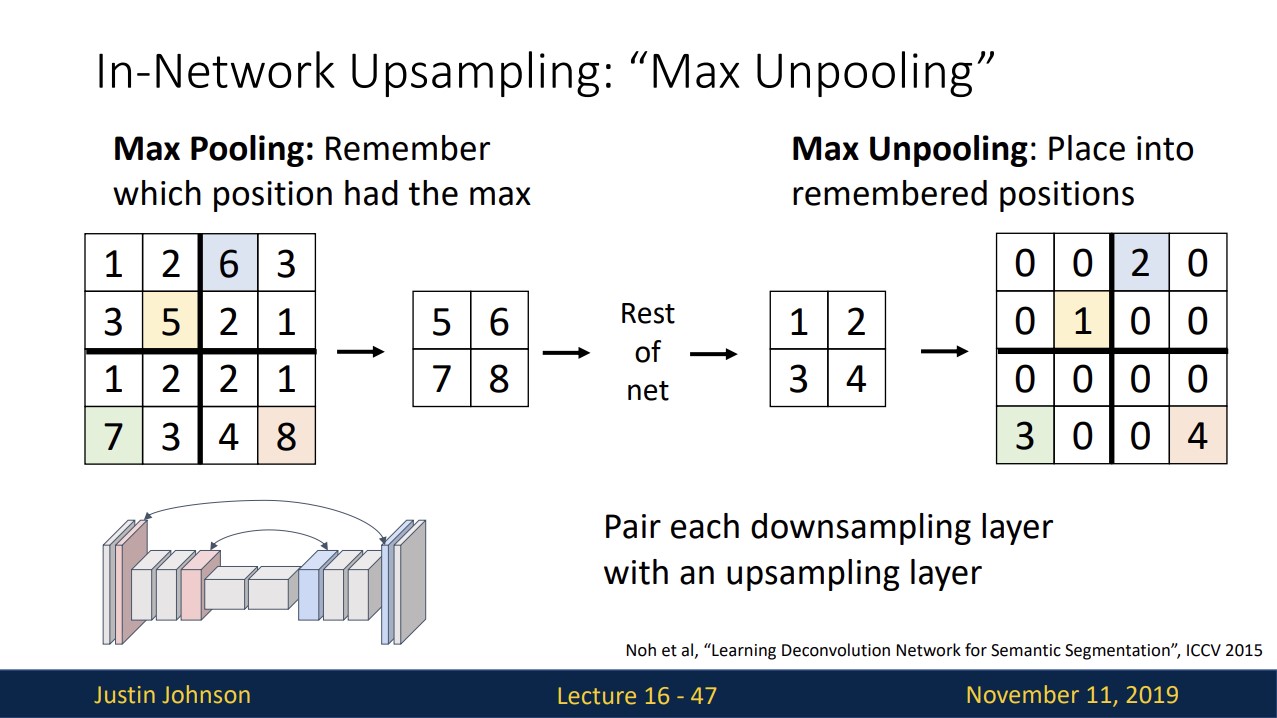
downsampling했던 곳을 기억했다가 upsampling할 때 그 자리에 다시 값을 넣는 방법입니다.
Learnable Upsampling: Transposed Convolution
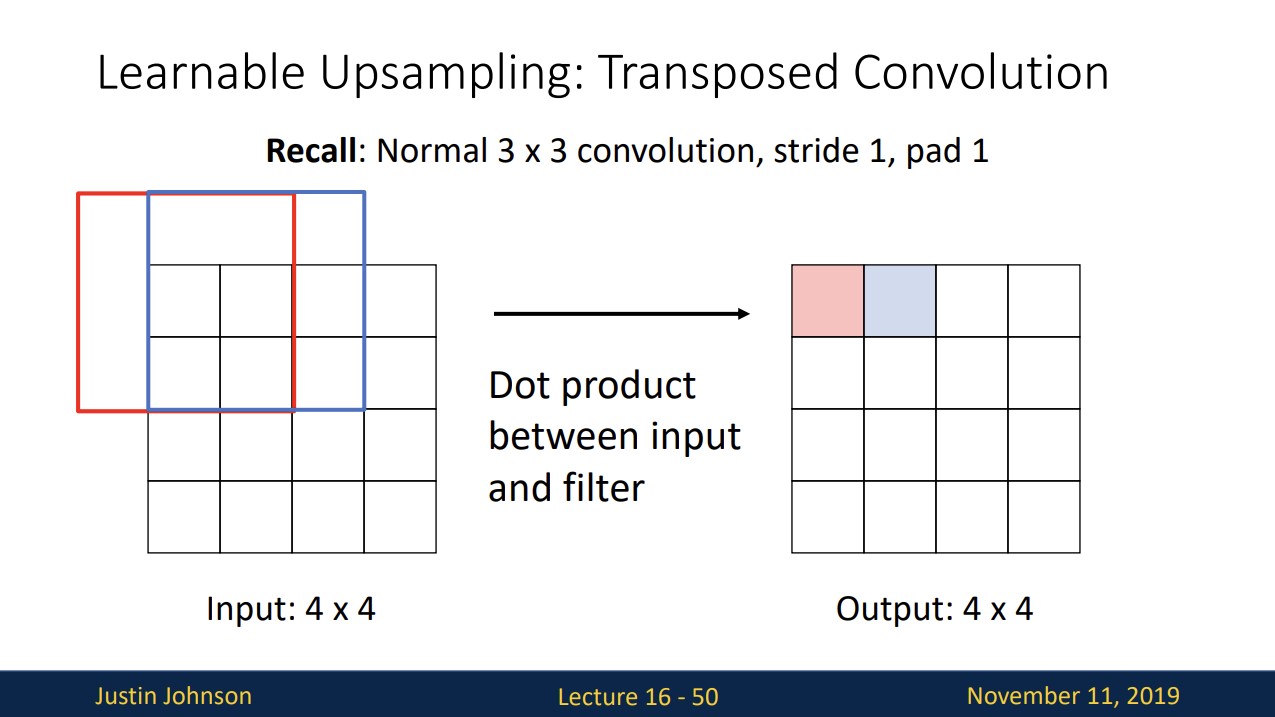
3x3 필터로 stride 1, padding 1을 적용해서 convolution연산을 진행하면 위와 같습니다.
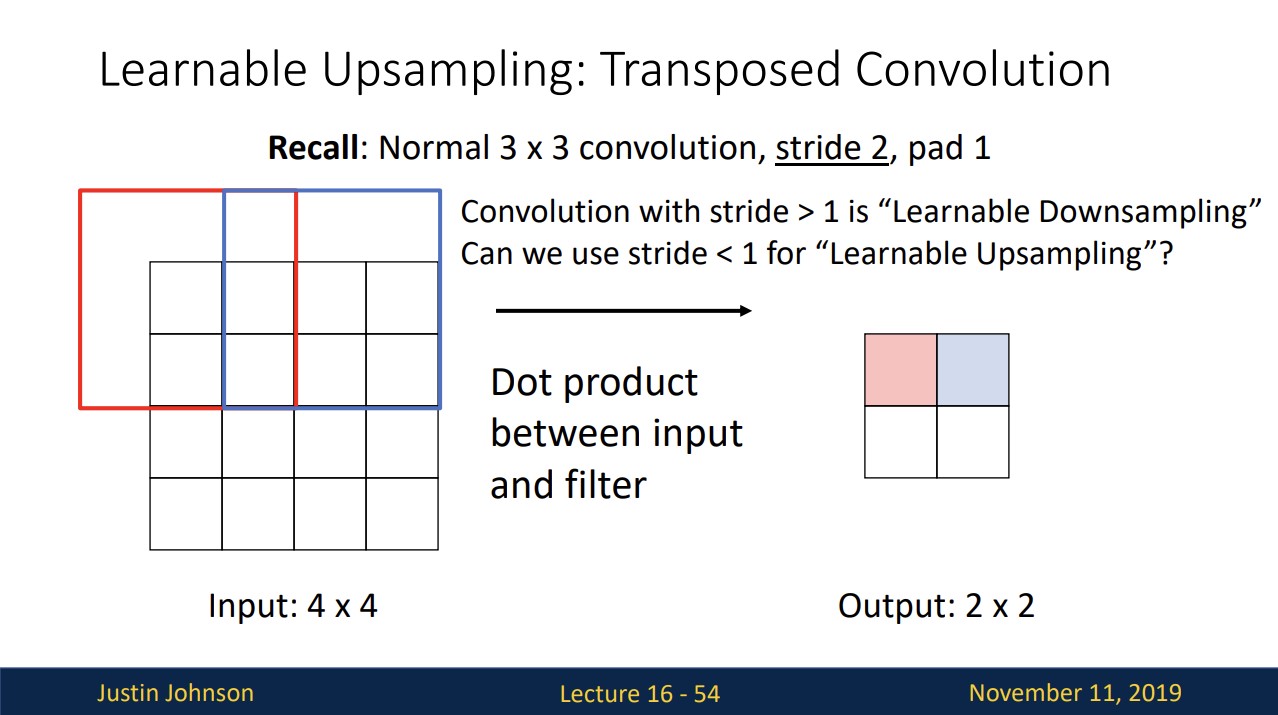
3x3 필터로 stride 2, padding 1을 적용해서 convolution연산을 진행하면 위와 같습니다.
stride>1로 하면 Learnable Downsampling이 됩니다.
그러면 stride<1이면 Learnable Upsampling이 되지 않을까?
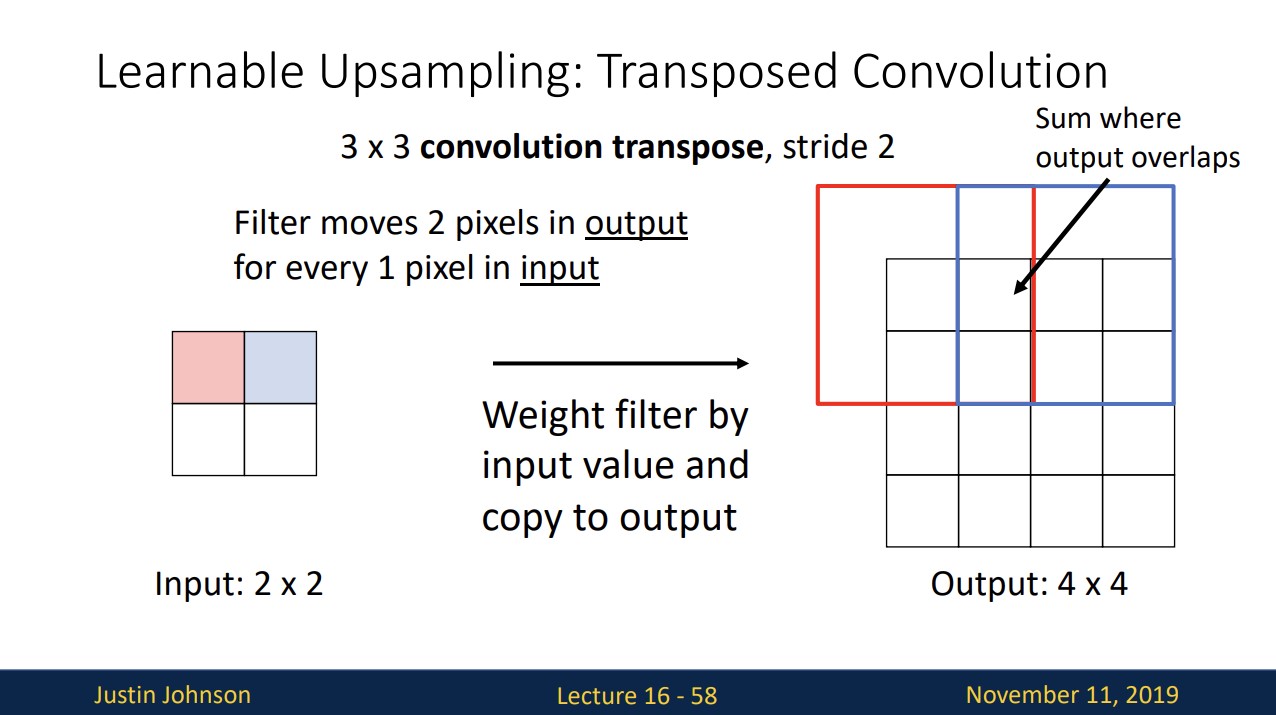
downsample된 input이 주어지면 1pixel씩 이동하면서 input pixel하나와 필터 3x3랑 스칼라곱 연산을 해준다. stride가 2이기 때문에 필터는 2씩 이동하면서 output을 도출해냅니다. 겹치는 부분은 더해줍니다.
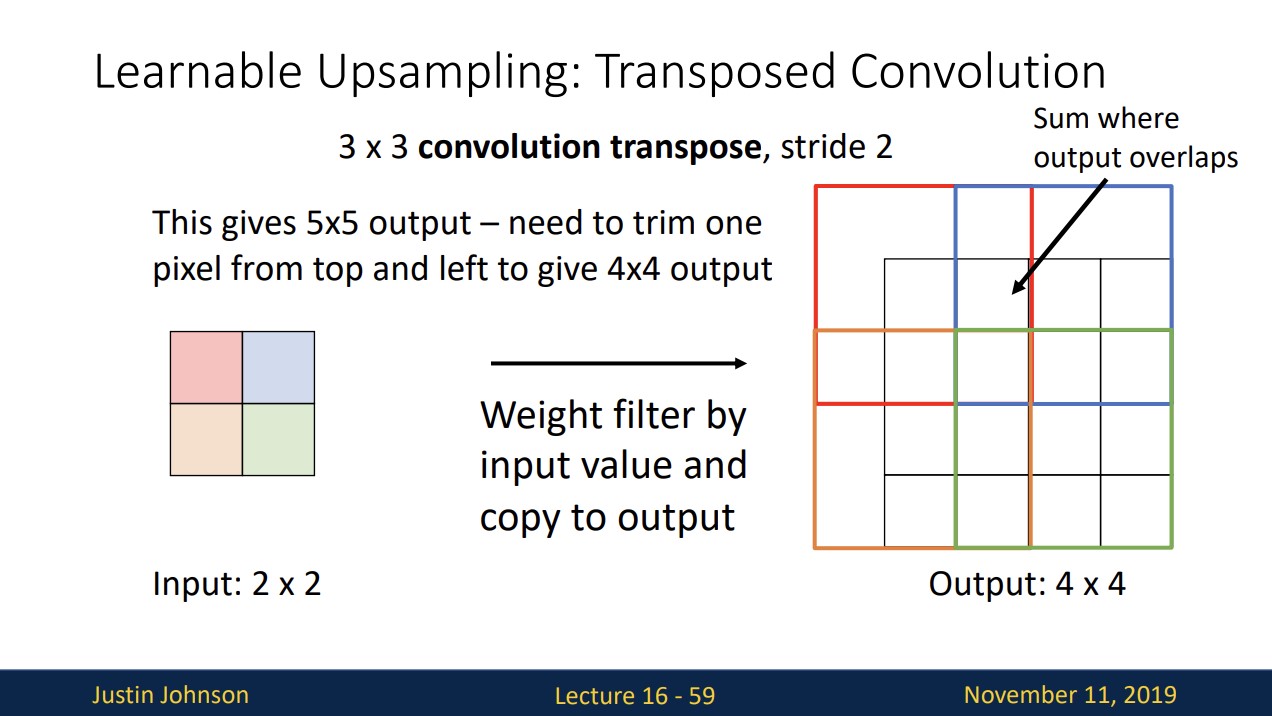
연산을 다 진행하면 위와 같고 넘치는 위쪽과 왼쪽 부분은 잘라줍니다.
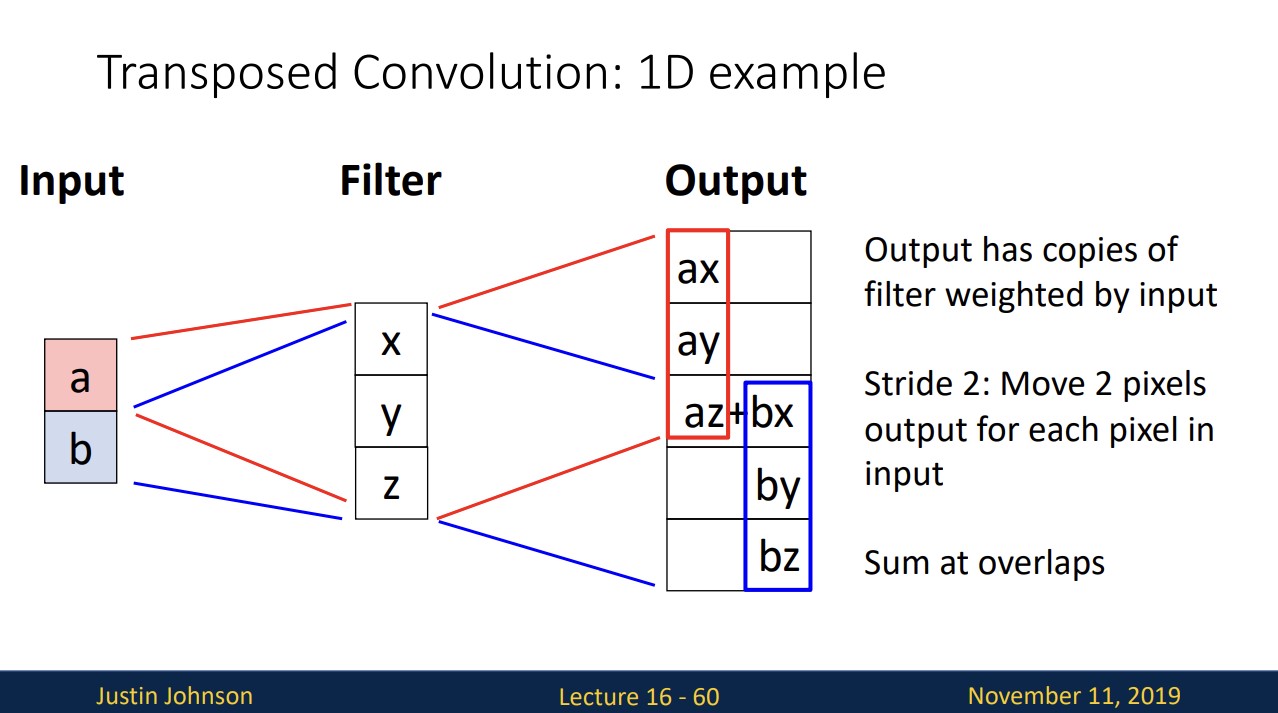
좀 더 쉽게 이해하고자 1D convolution 연산을 수식적으로 표현하면 위와 같습니다.
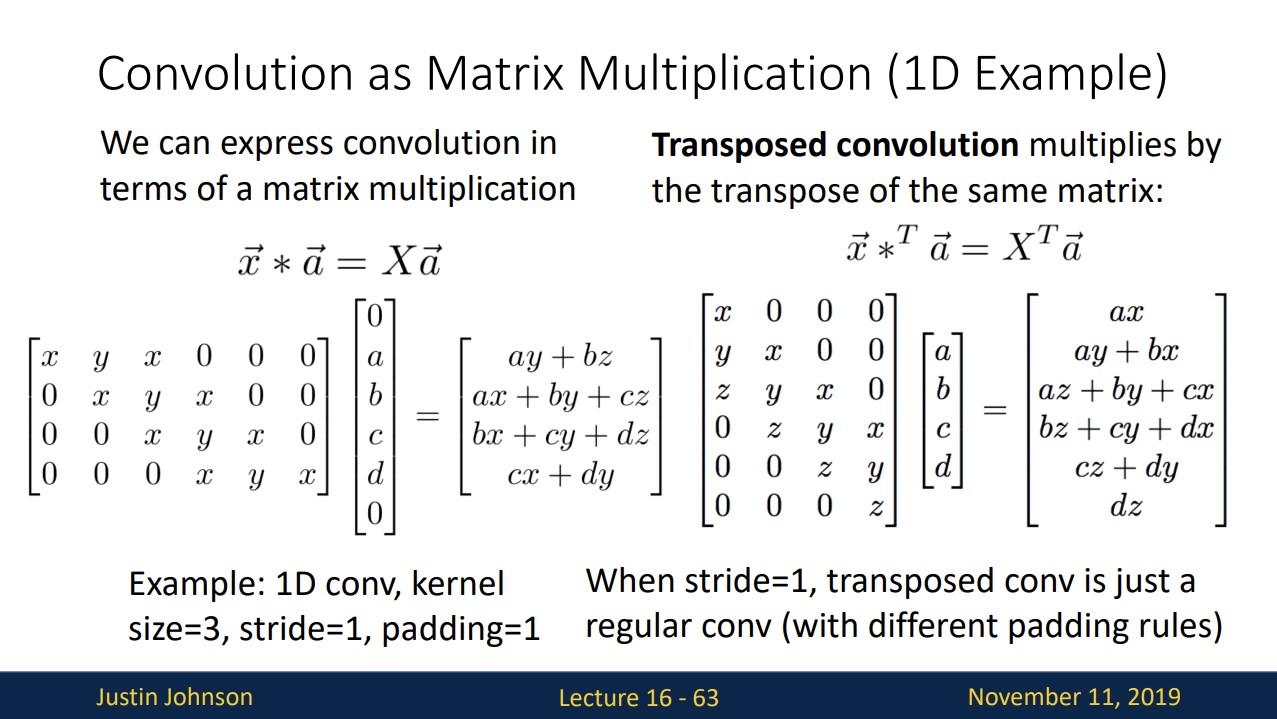
convolution 연산은 위와 같이 matrix multiplication으로 나타낼 수 있습니다.
transposed convolution 연산은 오른쪽과 같이 기존 x를 transpose한 것과 같습니다.

stride>1 인 경우는 위와 같습니다.
위 연산은 forward를 하면 backward과정은 단순히 transpose연산만 해줌으로써 가능합니다.
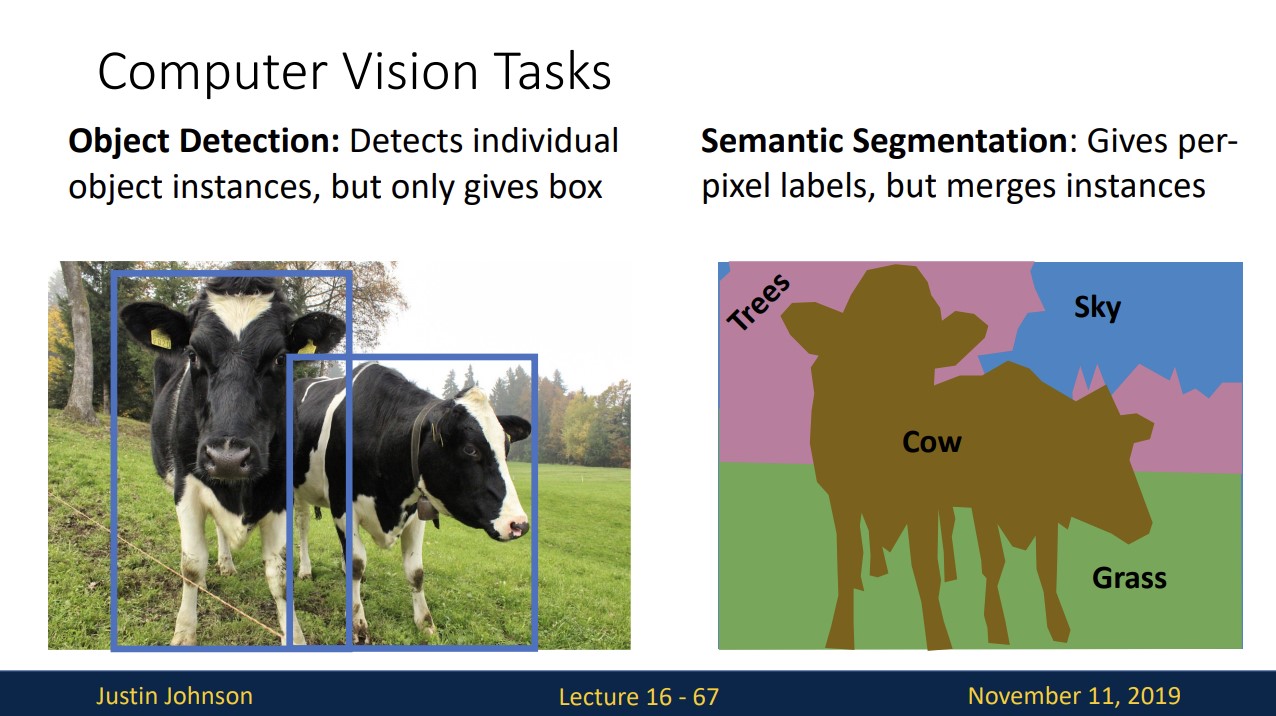
여태 object detection, semantic segmentation 두 가지의 computer vision tasks를 보았습니다.

Things는 cats과 cars처럼 분리될 수 있는 객체를 의미하고
Stuff는 sky와 grass처럼 분리될 수 없는 객체를 의미합니다.
Instance Segmentation
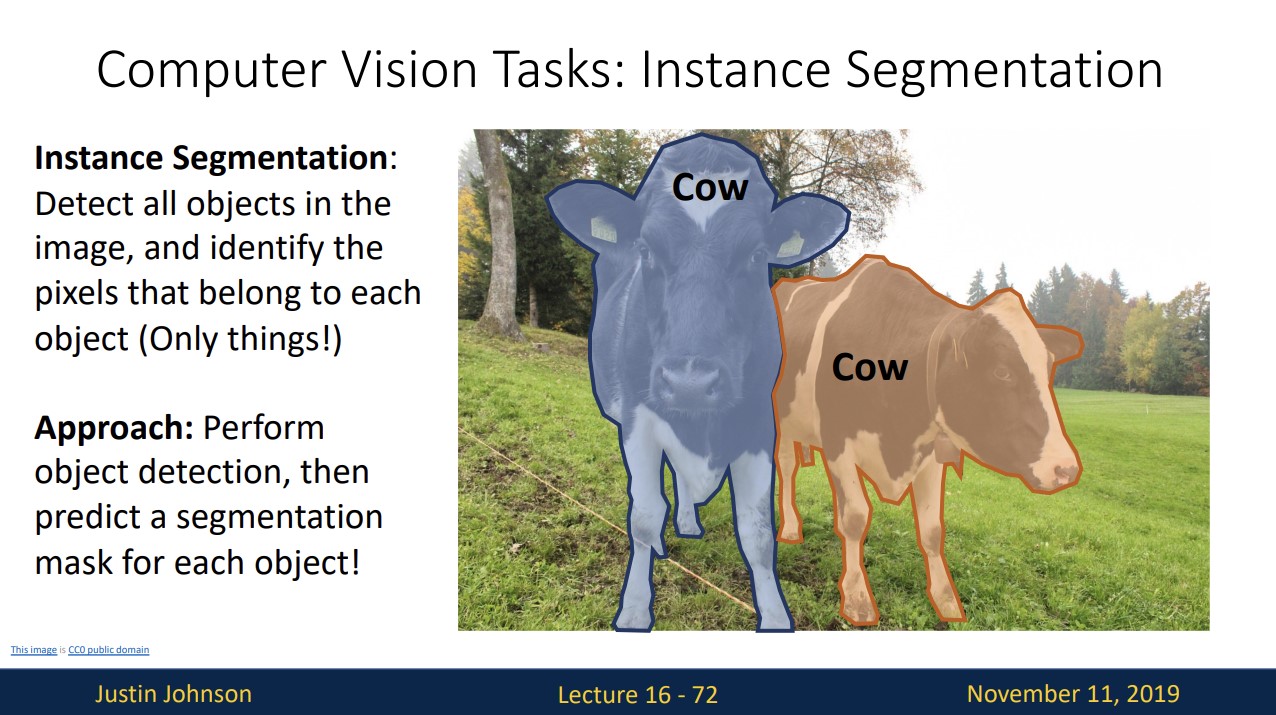
Instance Segmentation은, 이미지 내의 objects(things만)를 감지하고 이들을 pixel별로 segmentation합니다.
즉 object detection을 한다음 detected object에 대해 semantic segmentation을 진행하는 것입니다.
Instance Segmentation: Mask R-CNN
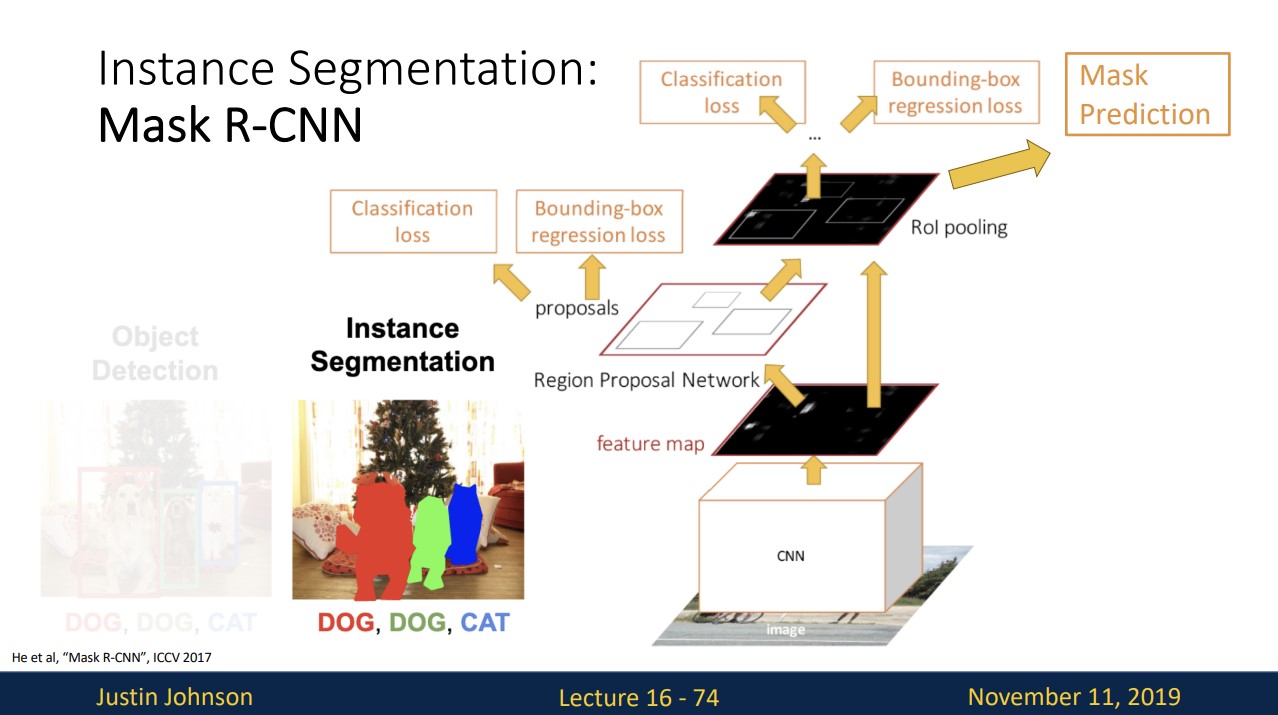
Instance Segmentation은 기존의 faster R-CNN에 Mask Prediction이라는 branch를 추가합니다.
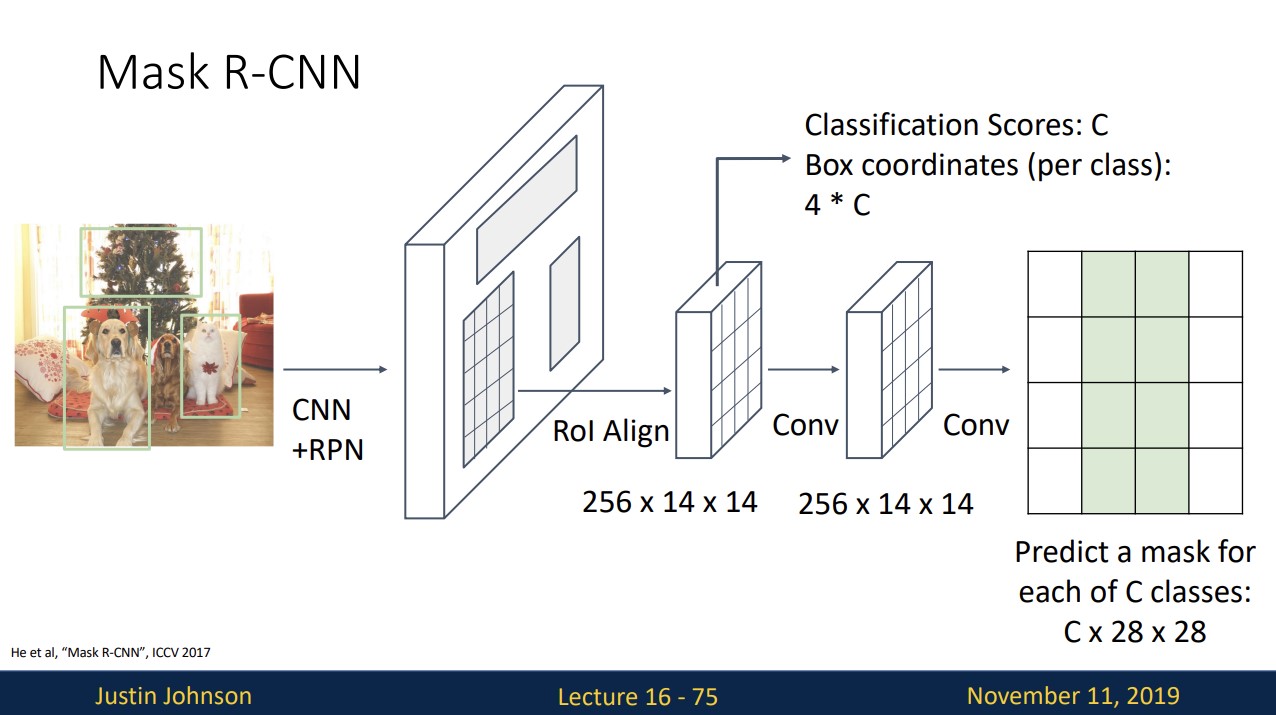
Mask Prediction은 region proposal에 대해 각각 background와 object를 segmentation합니다.
C는 object의 개수를 의미합니다.

위 사진은 segmentation mask가 어떻게 일어나는지에 대한 예시입니다.

Mask R-CNN이 잘 작동하는 것을 볼 수 있습니다.
Panoptic Segmentation
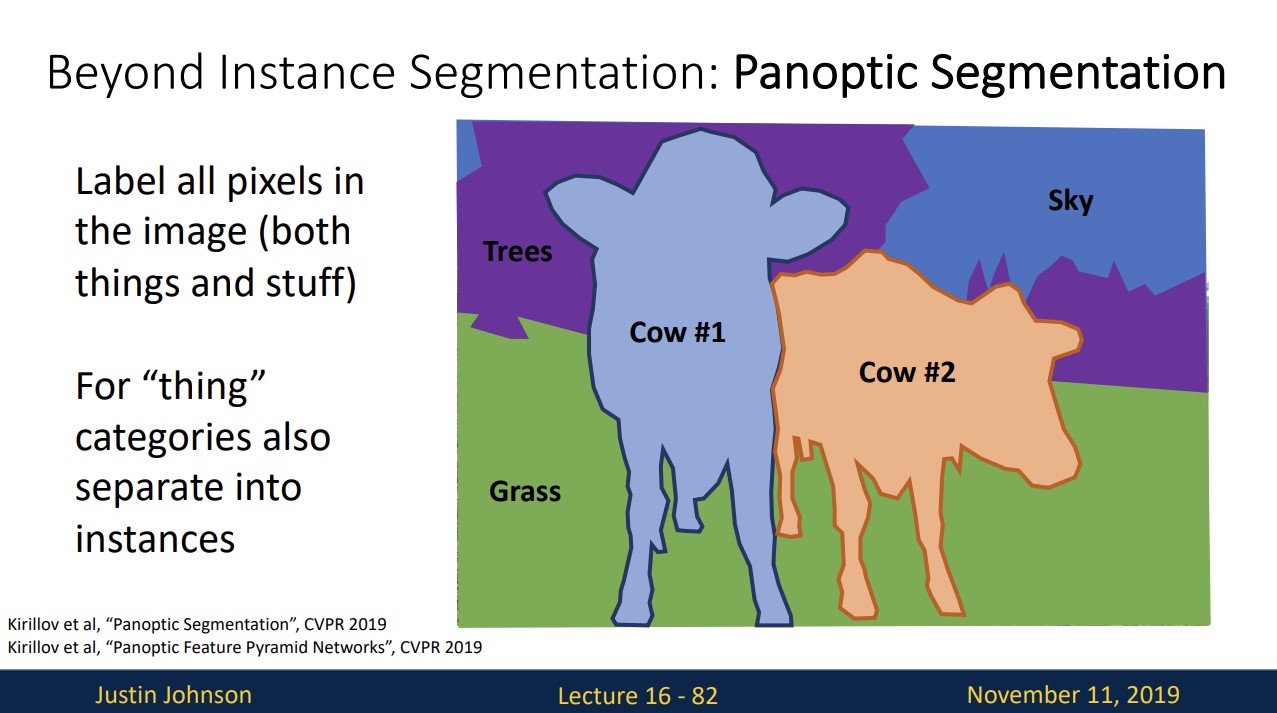
Instance Segmentation은 things에 해당하는 object만 다루지만 Panoptic Segmentation은 stuff에 대해서도 pixel별로 labeling합니다.

위와 같이 잘 작동하는 것을 볼 수 있습니다.
Pose Estimation

사람의 pose를 감지할 수 있는 방법이 존재합니다.
위와 같이 17개의 key point를 두어 감지하는 것입니다.
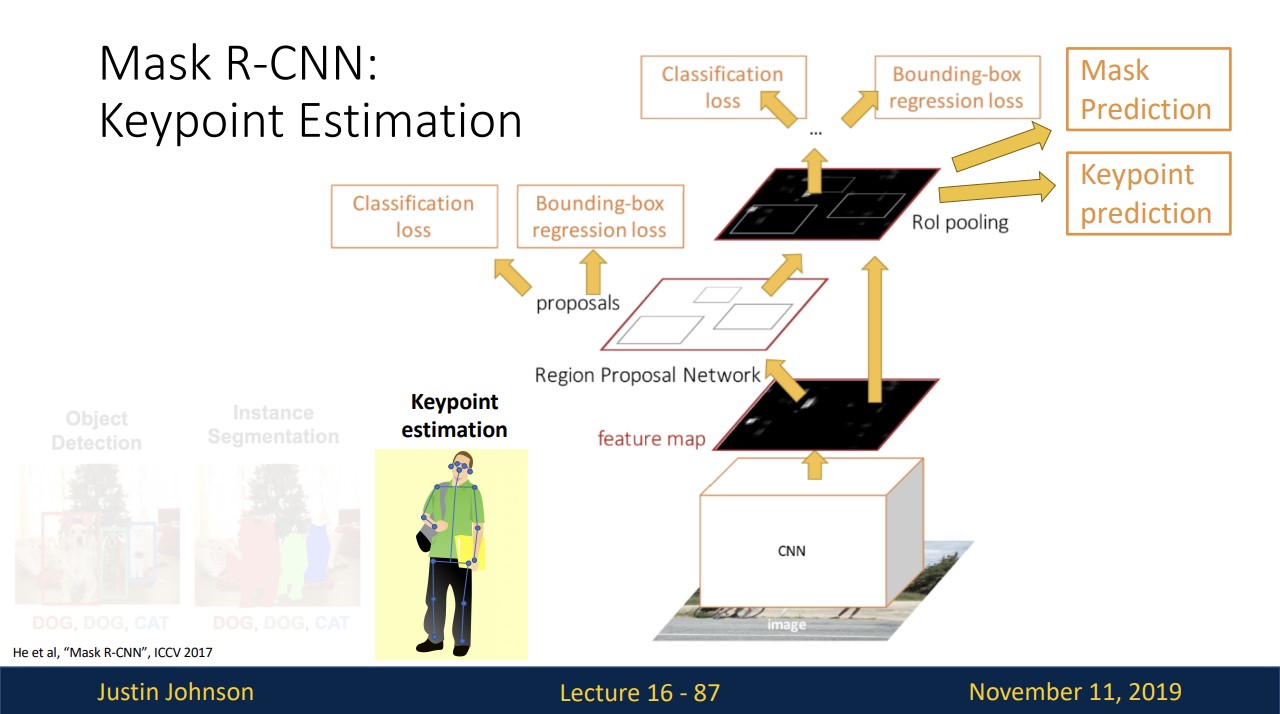
기존의 faster R-CNN에 Keypoint Prediction이라는 branch를 추가합니다.
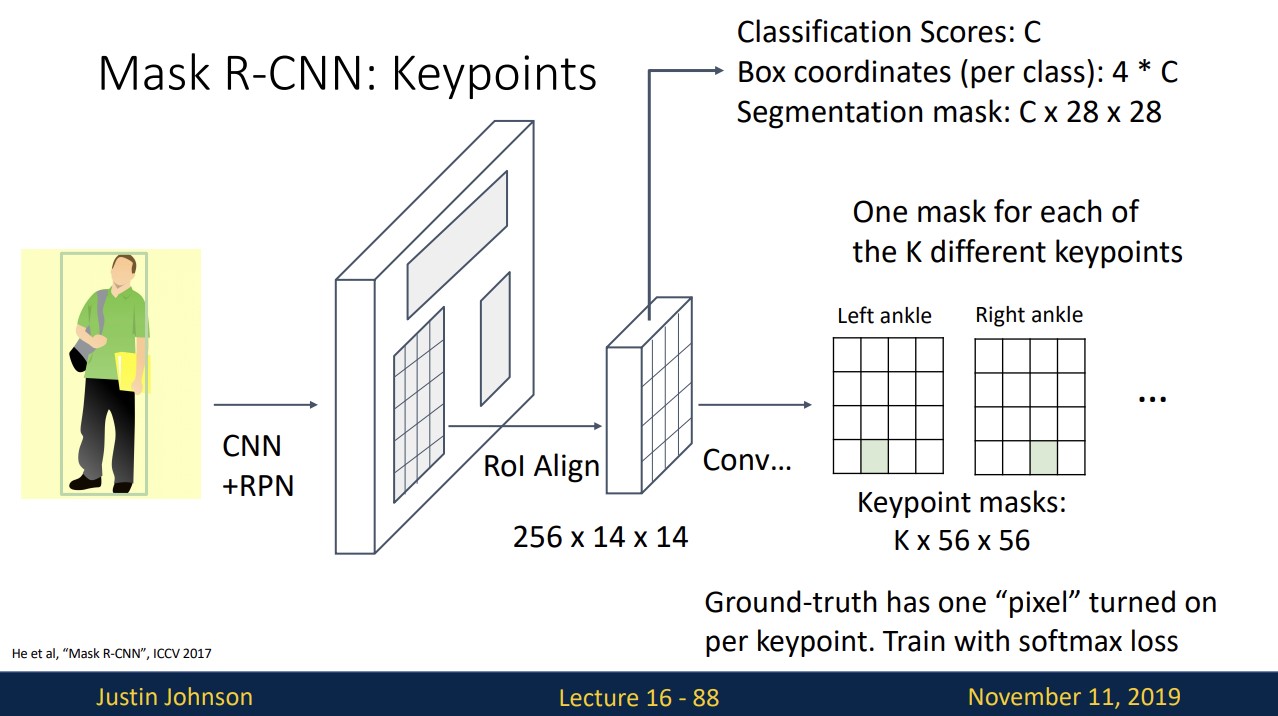
Keypoint Prediction branch에서 k개의 key point를 추정하고 이를 한 개의 pixel을 가진 k개의 Ground-truth와 비교하여 softmax loss를 구해 train한다.

위와 같이 pose estimation이 잘 작동한다.
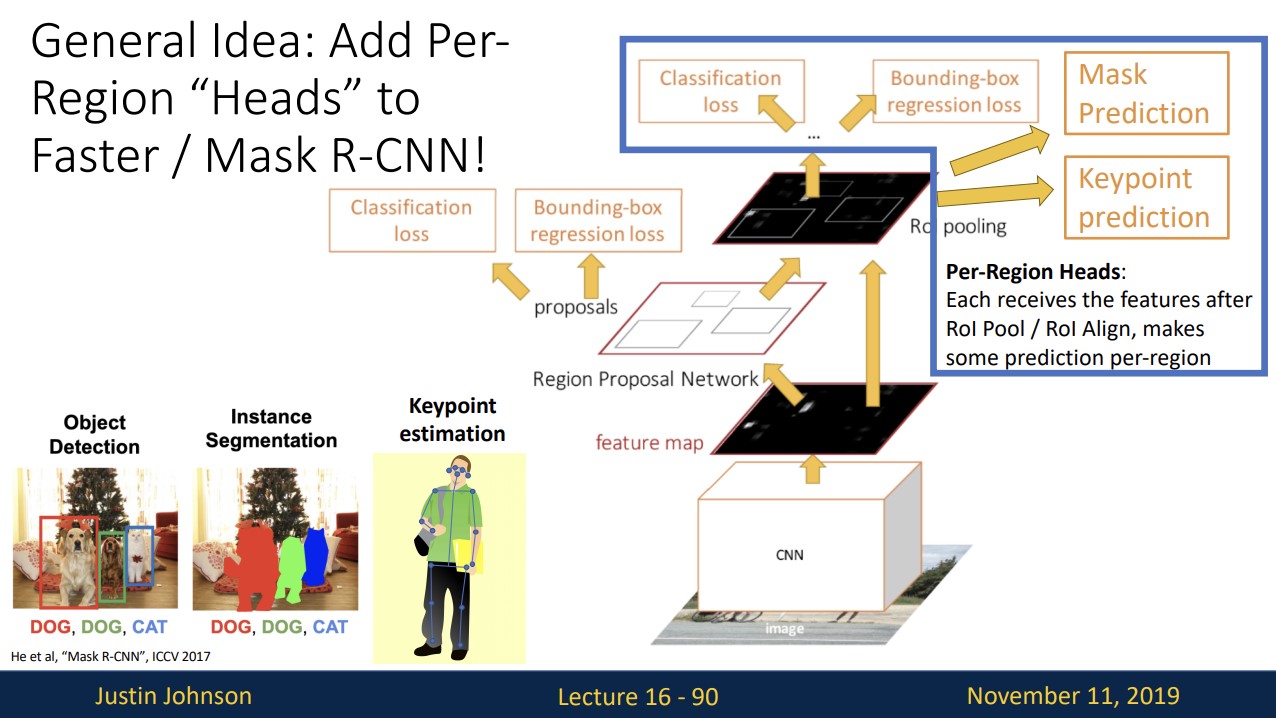
우선 computer vision task는 fater R-CNN기반에 task에 맞는 branch를 추가하여 해결할 수 있습니다.
Dense Captioning
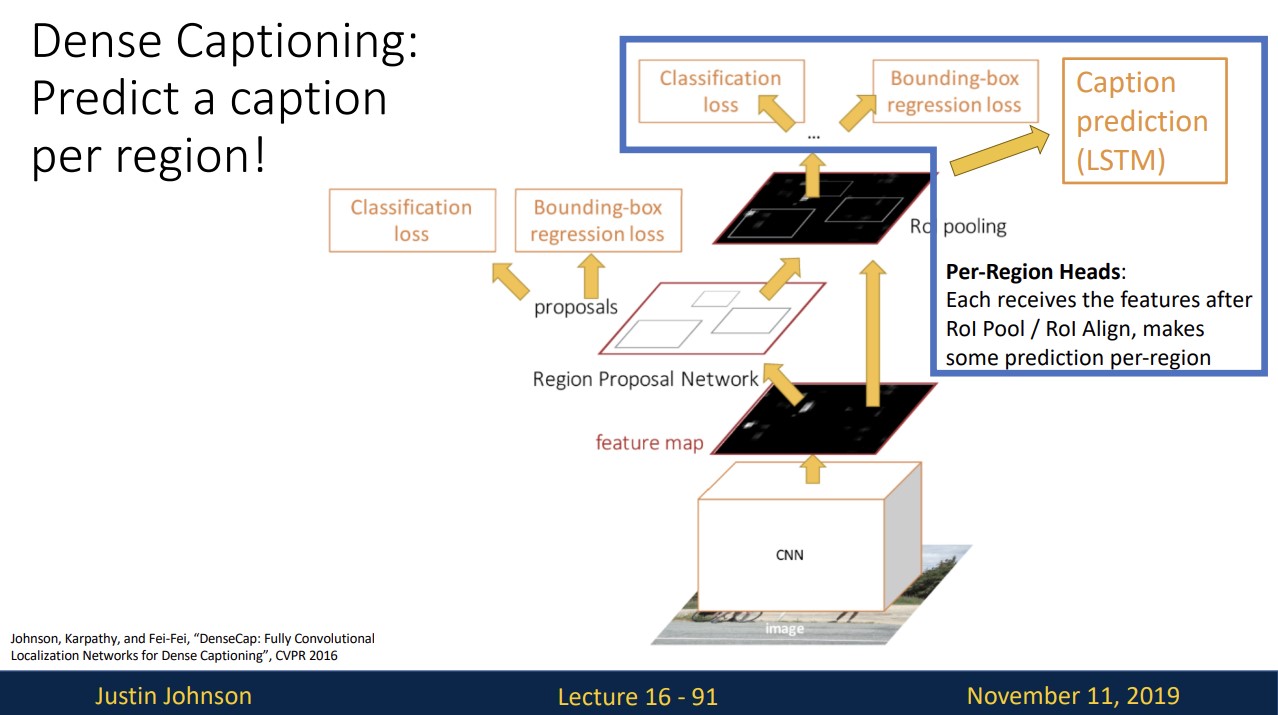
기존 fater R-CNN에 Caption prediction branch를 추가하여 region마다 text를 생성하는 Dense captiong을 진행할 수 있습니다.

잘 동작하는 것을 확인할 수 있습니다.
3D Shape Prediction
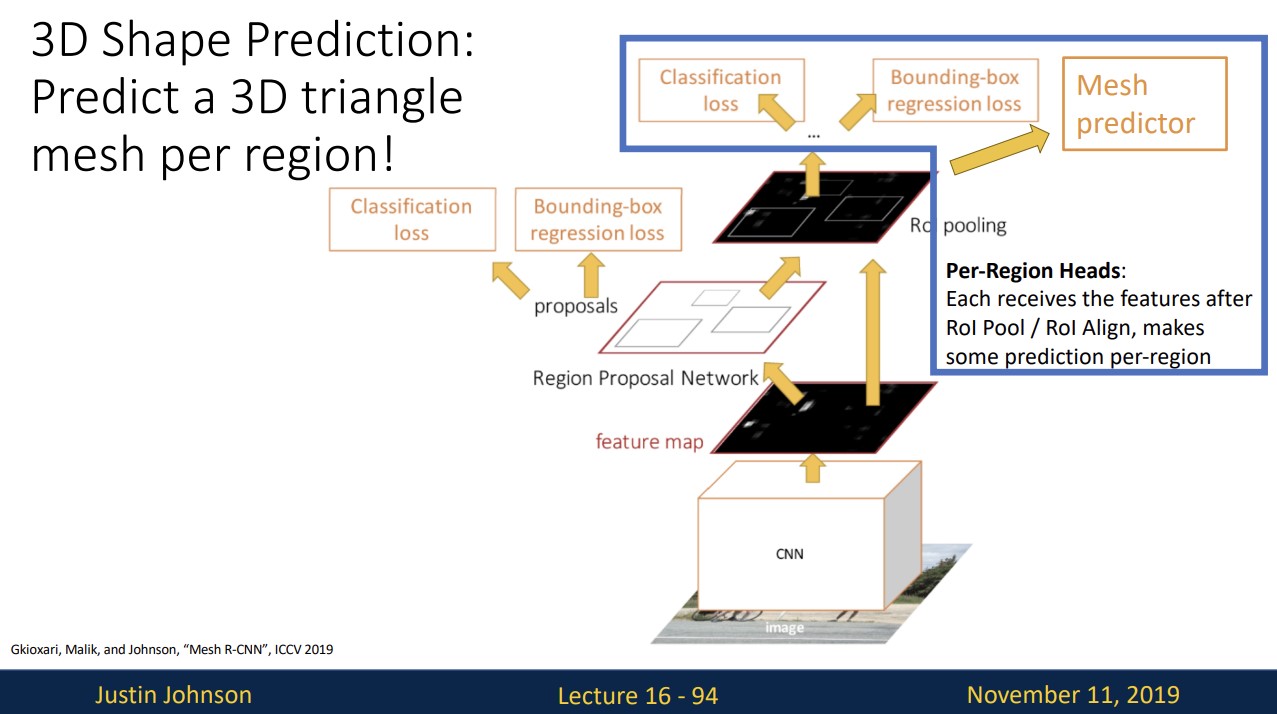
Mask R-CNN에 Mesh predictor branch를 추가하여

detect한 object에 3d shape을 얻을 수 있습니다.
