EleGANt: Exquisite and Locally Editable GAN for Makeup Transfer

제목에서 유추할 수 있듯이 이 논문은 사용자가 임의로 고른 지역적인 부분을 정확하게 Makeup Transfer 해주는 GAN model을 제시합니다.
Abstract
기존의 Makeup Transfer는 단순히 색상의 분포만 transferring하거나 eye shadows and blushes와 같은 makeup detail은 무시하고 미리 정의된 고정된 영역 내에서만 Makeup Transfer가 가능했습니다. 또한 source와 referene사이에 얼굴의 자세나 표정이 많이 다를 경우 제대로 Makeup Transfer 수행되지 않았습니다.
이러한 이슈를 해결하기 위해 이 논문에서 제시하는 방법은 다음과 같습니다.
- detail한 정보를 보존하기 위해 얼굴의 특징을 pyramid 구조의 feature map으로 encoding한다.
- 얼굴의 자세가 다른 경우를 다루기 위해서 QKV-attention을 사용하여
referene에서 makeup feature를 뽑고 픽셀 단위 대응으로 source 얼굴에 적용한다. - Sow-Attention이라는 새로운 방법을 제시한다. Sow는 shifted overlapped windows의 약자로 window를 이동하면서 window내에서 지역적으로 attention을 수행함으로써 계산비용을 낮춘다.
- 새롭게 designed된 pseudo ground truth를 훈련할 때 사용하여 색상과 공간의 정보를 보장한다.
각각 자세히 살펴보겠습니다.
Network Architecture
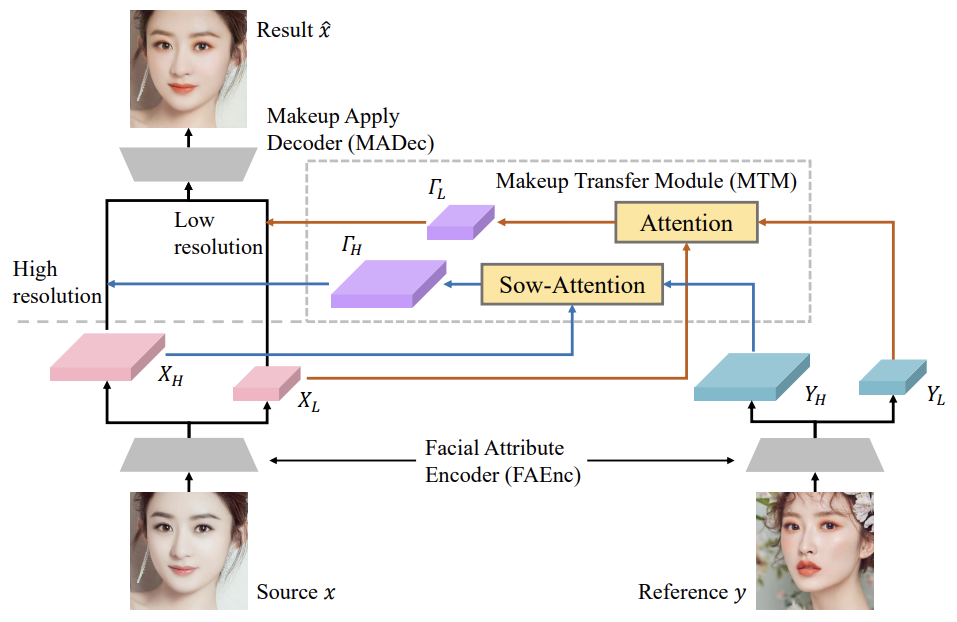
Facial Attribute Encoder(FAEnc)
- 얼굴의 특징을 뽑기 위해 각각 source와 reference 이미지를 피라미드 구조의 feature map으로 인코딩합니다.
- XH, YH은 sharp한 edge나 detail한 정보를 담고있는 high-frequency feature map이고 XL, YL은 색상과 그림자같은 정보를 담고 있는 low-frequency feature map입니다.
- high-frequency feature map은 원본 이미지가 encoder를 거친 후 한 번의 down sampling을 통해 만들어지고 low-frequency feature map은 두 번의 down sampling 통해 만들어집니다.
Makeup Transfer Module(MTM)
-
두 가지의 attention이 사용됩니다.
-
Attention은 low-frequency feature map을 활용하여 low-res makeup feature map인 TL을 생성하고 Sow-Attention은 high-frequency feature map을 사용하여 high-res makeup feature map인 TH를 생성합니다.
-
서로 다른 frequency의 makeup feature를 추출하고 attention을 활용하여 두 얼굴간의 불일치를 해결합니다.
각 attention에 대해 자세히 보겠습니다.
-
Attention
두 개의 얼굴이 pose나 표정이 다르기 때문에 reference의 makeup특징을 source얼굴에 맞게 조정해야하기 때문에 우리가 아는 기존의 QKV-cross-attention을 사용합니다. 이 attention은 두 얼굴 간 픽셀별 대응을 가능하게 해줍니다.
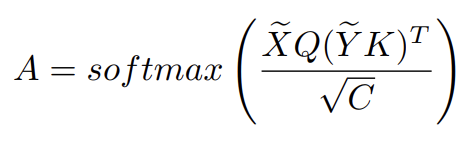
attentive matrix A는 X의 pixel이 Y의 pixel에 얼마만큼의 상관도를 가지는지를 나타냅니다. X~와 Y~는 positional embedding된 feature map입니다. (feature map의 각 pixel과 상대적 위치를 나타내는 벡터를 concat)
makeup 특징은 1X1 conv연산을 통해 뽑히고 이 뽑인 make feature를
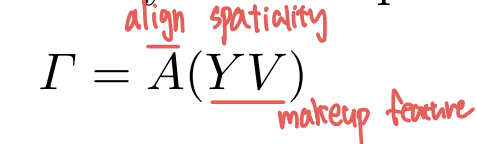
attentive matrix A와 요소별 곱셈을 통해 두 얼굴이 공간적으로 정렬된 makeup feature map T가 뽑힙니다. -
Sow-Attention
high-frequency feature map은 low에 비해 H와 W가 크기 때문에 X의 pixel하나가 Y의 모든 pixel에 대한 attention을 구하기엔 비용적으로 부담이 큽니다. 그래서 이를 해결하기 위해 shifted overlapped windowing attention Sow-Attention을 활용합니다.Sow-Attention은 3가지의 단계로 구성됩니다.
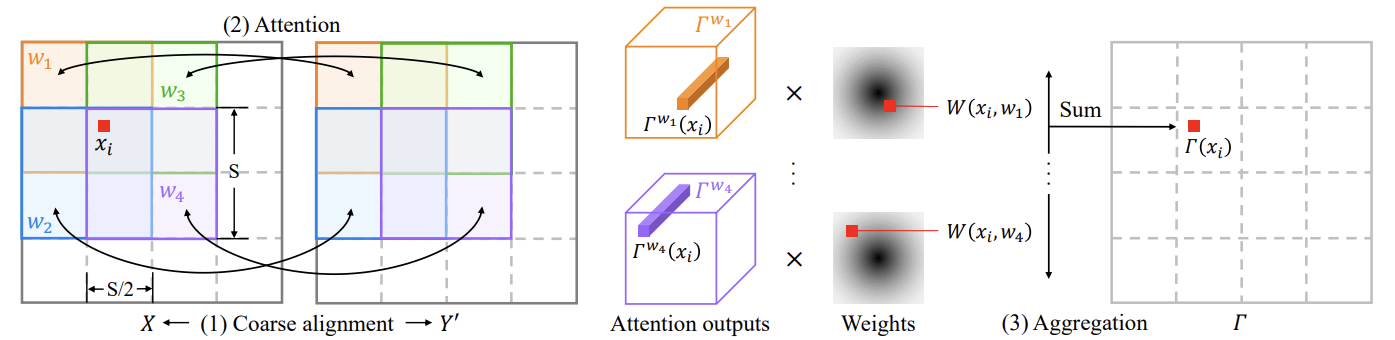
- Coarse alignment
Y를 X에 맞춰 공간적으로 정렬하기 위해 Thin Plate Splines (TPS)를 사용합니다. TPS는 Y의 n개의 점인 C가 X의 n개의 점인 C'에 맞춰 Y가 Y'로 뒤틀립니다. - Attention
X와 Y'가 공간적으로 정렬되었기 때문에 local attention만으로 X의 점이 Y'의 주변만 보고 충분히 makeup feature를 추출할 수 있습니다.
만약에 window를 겹치지 않고 attention을 수행한다면 경계선 부분에서 부자연스러운 결과를 얻을 수 있으므로 겹쳐서 window attention을 수행합니다.
(그림 예시 설명) - Aggregation
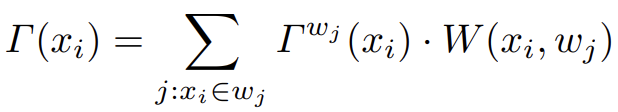
window가 겹쳐지기 때문에 각 pixel인 xi는 4개의 attention output vector를 얻게됩니다. 이 4개의 벡터는 weighted sum을 통해 하나의 벡터로 계산됩니다.
weight인 W는 x의 각 window내에서의 상대적 위치에 의해 결정됩니다. 만약 xi가 wj의 center에 가까우면 Twj는 xi의 주변 지역에 대해 더 많은 정보를 포함 할것이므로 W(xi, wj)은 비교적 큰 값을 갖게 됩니다.
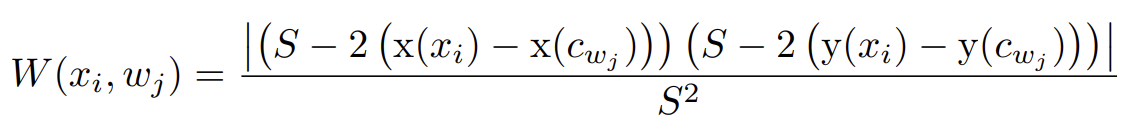
W가 도춝되는 식은 위와 같고 cwj는 window Wj의 center를 의미합니다.
- Coarse alignment
Makeup Apply Decoder (MADec)
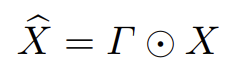
attention을 통해 추출한 makeup feature map T를 source feature map X와 element-wise 곱셈을 통해 X^이 계산되고 이를 upsampling을 통해 output이미지를 생성합니다.
Makeup Loss with Pseudo Ground Truth
training시에 쓰는 total loss term은 다음과 같습니다.
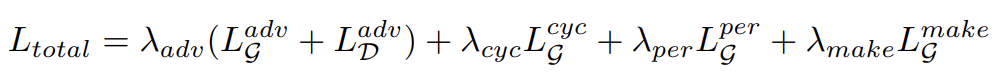
첫 번째 loss term인 Ladv은 generator은 loss를 min하고 discriminator는 max하는 adversarial loss이고 Lcyc는 unpair한 쌍을 훈련하기 위한 cycle consistency loss이고 Lper은 generator가 생성한 이미지와 GT의 feature map끼리 비교하는 loss term인 perceptual loss입니다.
추가로 makeup loss term인 Lmake를 두어 model이 좀 더 makeup transfer에 적합한 목표를 가지도록 합니다.
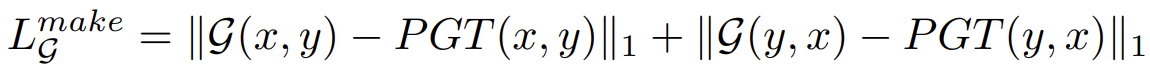
makeup loss는 pseudo ground truth (PGT)에 의해 정의됩니다. PGT는 generator와 별개로 생성되어 훈련 목표로 사용되는 이미지입니다.
위 수식에서 PGT(x, y)는 x의 얼굴의 특징과 y의 makeup 특징을 갖고있는 이미지를 의미합니다.

위 사진은 훈련 목표로 쓰이는 다양한 PGT의 예시를 보여줍니다.
Histogram matching은 공간 정보를 고려하지 않은 채 단순히 reference의 color를 source에 mapping한 것입니다.
TPS warping은 reference의 얼굴을 source face의 shape에 맞춰 변형한 것입니다. 인공적인 느낌이 강한 것을 볼 수 있습니다.
이러한 이슈를 해결하기 위해 새로운 PGT 전략을 제시합니다.
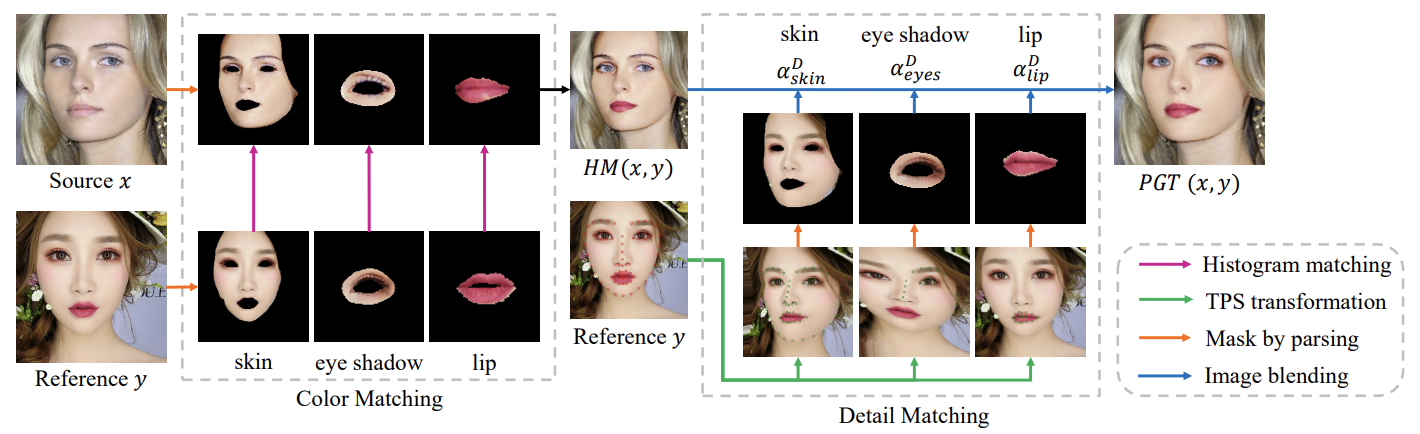
histogram matching을 통해 Color Matching을 합니다. 그리고 좀 더 detail한 정보를 반영하기 위해 y가 x에 맞춰 휘어지고 color matching한 결과인 HM과 섞입니다. 블렌딩 요소인 a skin, a eyes, a lip은 색상을 강조하거나 detail한 부분을 잘 살리기 위해 훈련의 단계마다 변화합니다.
Experiments
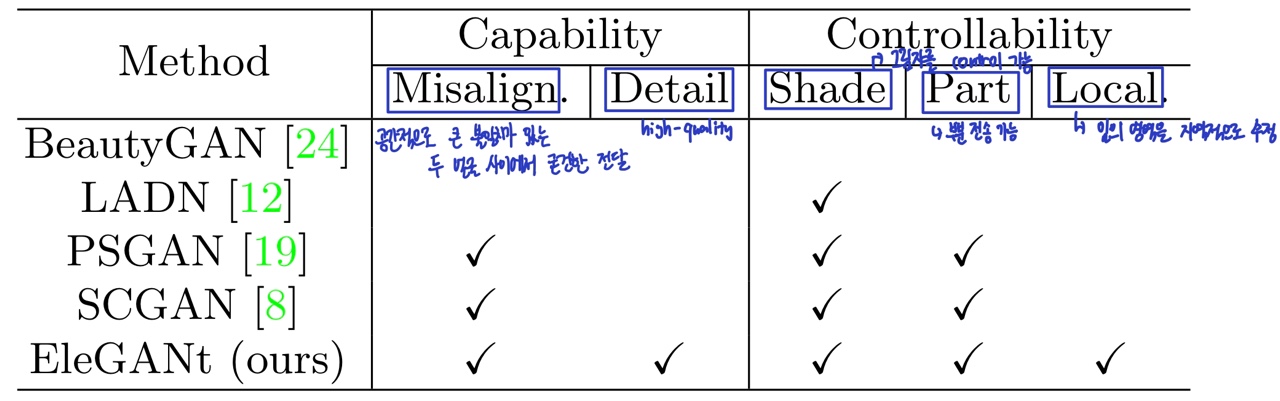


EleGANt는 makeup transfer와 관련된 모든 model 중에서 가장 뛰어난 기능과 유연성을 보여줍니다.
Controllable Makeup Transfer

위 사진처럼 두 개의 makeup feature를 융합 할 수도 있고 부분적인 부분만 transfer 할 수 있습니다.
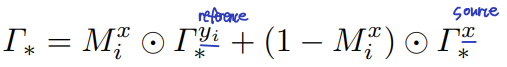
입술이나 아이섀도우 같이 부분적인 부분만 makeup transferring 하는 것은 makeup feature map을 masking함으로써 가능합니다. 위 식에서 y는 reference, x는 source를 나타냅니다. Mi는 우리가 makeup transfer할 부분을 masking한 것입니다. makeup feature map과 같은 size입니다.
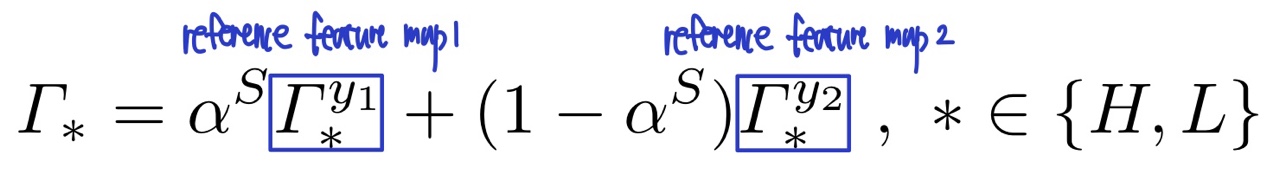
위 식처럼 makeup feature map을 interpolating하는 것은 makeup의 정도나 여러 개의 reference의 makeup feature를 융합할 수 있게 합니다.
만약 하나의 reference에서 makeup transfer가 적용되는 정도만 조절하고 싶다면 y2=x로 두고 진행하면 됩니다. 그러면 알파는 makeup의 강도를 나타내게 됩니다.
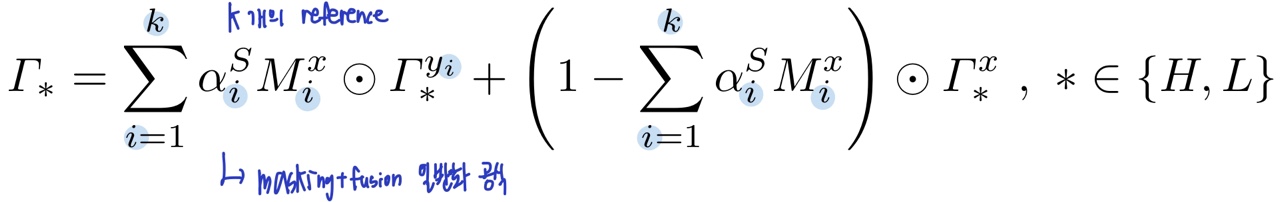
특정 부분만 makeup transfer 하기 위해 masking하고 다양한 reference를 융합하는 공식은 위와 같습니다.
Ablation Study
Ablation study는 이 논문에서 제시한 model의 효율성을 평가하기 위해 한 방법을 제거한채 실행하는 연구입니다.

w/o high-res는 high-res feature map없이 훈련을 진행한 결과입니다.
detail한 정보인 reference의 아이섀도우나 source의 주근깨와 같은 정보가 흐려지거나 없어진 것을 확인할 수 있습니다.
w/o Sow는 window를 이동할 때 겹치지 않고 이동하면서 훈련을 진행한 결과를 나타낸 것입니다. red box를 보면 window의 경계가 부자연스운 것을 확인할 수 있습니다.

우리가 훈련중에 PGT를 사용하지 않는다면 makeup의 정보를 잘 받지 못할 것입니다. 따라서 w/o PGT의 결과를 보면 makeup transfer없이 general한 이미지를 생성한 것을 확인할 수 있습니다.
또한 TPS를 사용하지 않는다면 PGT에 공간적인 정보를 반영하지 못해 makeup의 detail한 정보를 transfer하지 못할 것입니다. 그래서 w/o TPS를 보면 아이섀도우와 같은 detail한 정보가 반영되지 못한 것을 확인할 수 있습니다.
w/o his와 w/o anneal를 보면 TPS Warping과 image blending에 의해 도입된 인공적인 것이 PGT에 남아있는 것을 확인할 수 있습니다.
Conclusion
이 논문에서 makeup transfer는 color transferring 그 이상이라는 것을 강조합니다.
high-res feature maps을 이용해 detail한 정보도 transfer 가능하게 하였고 새로운 Sow-Attention을 제시하여 계산 비용을 감소시켰습니다. 또한 새롭게 고안된 PGT를 제시하여 훈련 중에 color와 공간 정보를 모두 반영할 수 있게 하였습니다. 게다가 부분 및 보간된 makeup transfer로 맞춤형 부분 makeup transfer를 달성한 것은 처음입니다. 그리고 다양한 얼굴 포즈와 복잡한 메이크업 스타일에도 불구하고 정확하게 makeup transfer가 되는 것을 다양한 실험을 통해 확인했습니다.
그러나 이 모델은 과도한 makeup style을 transfer할 때 정확하게 makeup transfer가 작동하지 않는다고 합니다. 그 이유는 dataset이 다양하지 않아서라고 주장하고 이 일은 future work에 맡기겠다고 합니다.
