GAN은 노이즈에서 이미지를 바로 생성해내지만, diffusion model의 경우 노이즈로 부터 조금씩 노이즈를 제거해 이미지를 생성한다.
DDPM
여기서 DDPM은 Markov chain을 가정하고 있는데 Markov 성질은 과거와 현재 상태가 주어졌을 때의 미래 상태의 조건부 확률 분포가 과거 상태와는 독립적으로 현재 상태에 의해서만 결정된다는 것을 뜻한다.
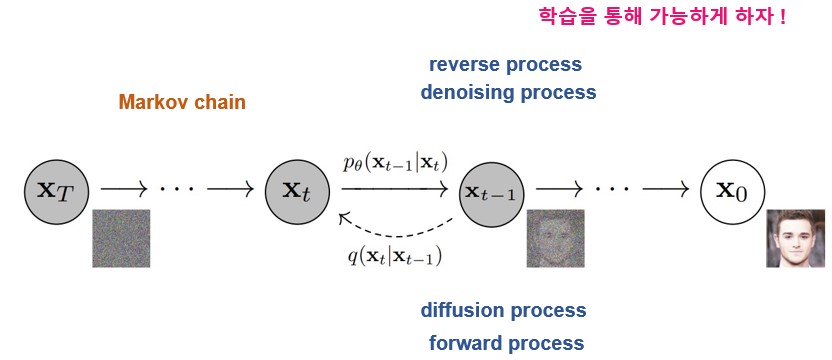
Diffusion model은 두 가지 process로 나뉘는데, 노이즈를 점차 더해 나가는 diffusion process, 조금씩 noise를 제거해 이미지를 생성하는 denoising process로 나뉜다.
각각 forward process, reverse process라고도 한다.
forward process는 수학적으로 바로 계산이 가능하기 때문에 reverse process, 즉 denoising process를 학습을 통해 최적화 하는 것이 목적이다.
forward process
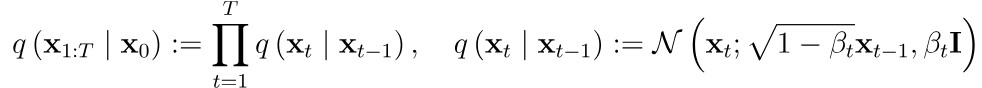
forward process는 이미지에서 조금씩 noise를 더해 완전한 Gaussian noise로 만드는 과정이다.
이를 Xt-1이 주어졌을 때 Xt가 나오는 조건부 확률로 표현할 수 있다. 이를 분포 형식으로 표현하면 Xt의 분포는 Xt-1의 평균과 분산으로 나타낼 수 있고,
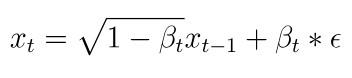
이를 수식적으로 정의하면, 이전 이미지 Xt-1에 루트 1-B만큼 곱하고 어떤 노이즈를 루트 B만큼 더한 것이 Xt라 볼 수 있다.
앞에 곱하는 상수를 위와 같이 정한 이유는 분산을 1로 만들어 분산이 발산하는 것을 막기 위함이다.
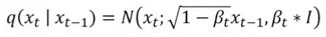
방금 그 수식을 위와 같은 분포로 위와 같이 표현할 수 있고
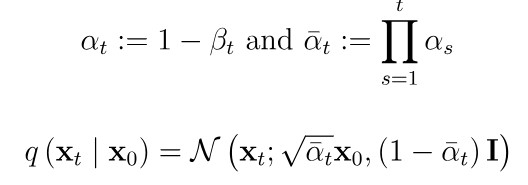
X0에서 Xt로 가는 과정을 위와 같이 일반화 할 수 있다.
이렇게 forward process는 수학적으로 x0에서 한 번에 xt로 진행할 수 있다.
reverse process
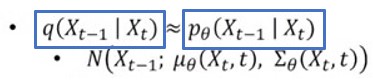
그러면 결국 network가 학습해야 하는 것은 reverse process인데, 이를 Xt가 주어졌을 때 Xt-1을 구하는 것으로 표현할 수 있다.
여기서 q는 real data의 분포이고 p 쎄타는 네트워크 분포인데 real data 분포인 왼쪽 박스, 이를 직접적으로 아는 것은 불가능하기 때문에, 이와 유사한 오른쪽 박스의 파라미터 쎄타를 학습 및 예측한다.
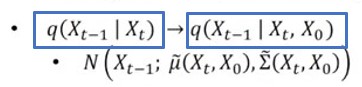
하지만 여기서 Xt가 주어졌을 때 Xt-1를 바로 알 수는 없지만, Xt와 X0이 주어졌을 때 Xt-1은
바로
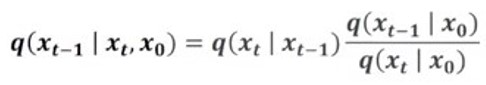
베이지안 정리를 통해 다음과 같이 표현할 수 있다.
오른쪽에 해당하는 3가지 항을
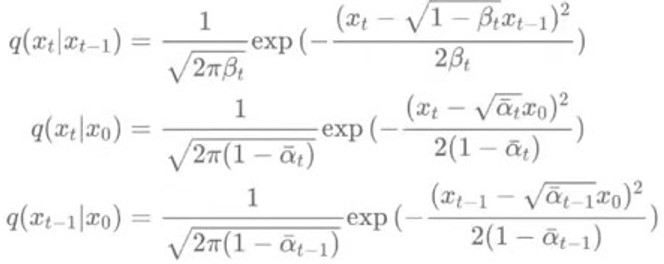
다음과 같이 표현할 수 있고

이 3가지 항을 위의 공식에 대입해 계산하면 Xt와 X0이 주어졌을 때 Xt-1의 분포를 평균이 a이고 분산이 b인 분포로 표현할 수 있다.

여기서 파란 박스 안에 있는 Xt를
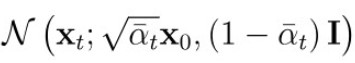
X0으로 표현할 수 있고,
이를 대입하면 파란 박스를 아래와 같이 간단하게 표현할 수 있다.
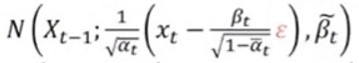
이를 해석하면 Xt에서 Xt-1을 구하기 위해 Xt에서 어떤 noise를 빼면 Xt-1가 된다는 의미이다. (빨간색 부분은 noise를 의미)
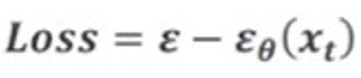
결국에는 어떤 noise를 빼야 노이즈가 덜 낀 이전 시점으로 돌아가는지를 예측해야 하는데
이에 대한 Loss term은 t시점의 노이즈가 들어갔을 때 예측한 noise와 정답 noise 간의 차이를 최소화하는 식으로 학습이 진행된다.

DDIM

감사합니다. 이런 정보를 나눠주셔서 좋아요.