
Abstract
diffusion model은 높은 품질의 이미지 합성을 가능하게 합니다.
그러나 diffusion 모델은 training과 inference시 computing cost를 많이 필요로 합니다.
따라서 이미지 합성 quality와 flexibility를 유지하면서 computing cost를 낮추기 위해 diffusion model을 pretrained autoencoder의 latent space 에서 훈련 시킴으로써 computing cost를 감소시키고 detail한 정보를 보존하는 것을 가능하게 했습니다.
cross-attention을 모델 architecture에 도입함으로써 diffuson model을 text나 bounding box와 같은 다양한 조건에 따른 이미지 합성을 가능하게 합니다.
Related Work
~
Method

크게 3가지 부분으로 구성되어 있습니다.
text에 대한 embedding을 뽑아내는 clip network, text embedding과 feature map을 input으로 받아서 image를 만들 수 있는 정보인 feature map을 만들어내는 network, feature map으로 부터 이미지화 시키는 decoder로 구성되어 있습니다.
학습 순서는 오토인코더 학습 -> clip학습 -> U-net 학습로 진행됩니다.
AutoEncoder
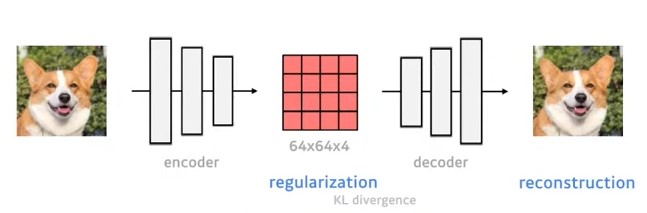
image를 encoder를 통해 latent feature map으로 encoding합니다.
latent feature map이 Gaussian distribution을 따르도록, KL divergence loss를 이용해 regularization합니다. 이때 reconstruction이 잘 되는 것이 목적이기 때문에 reconstruction에 집중할 수 있도록, regularization은 약하게 진행됩니다.
latent feature map에서 decoder를 통해 reconstruction을 진행합니다.
decoder에서 나온 output이 input이랑 같은지에 대한 reconstruction loss는 perceptual loss와 patch based adversarial objective를 사용합니다.
perceptual loss는 feature map끼리 거리계산을 하여 그 차이를 최소화 하는 것이고 patch based adversarial objective는 전체적인 이미지를 한번에 T/F를 통해서 score를 측정하는 게 아니라 patch 단위로 T/F를 판별하는 방식입니다. 이 방식을 사용하게 되면 지역적인 사실성을 살릴 수 있고 L1이나 L2 loss처럼 전체 pixel 단위 loss를 사용했을 때 나타날 수 있는 blurriness 현상을 많이 완화하고 있다고 합니다.
Clip
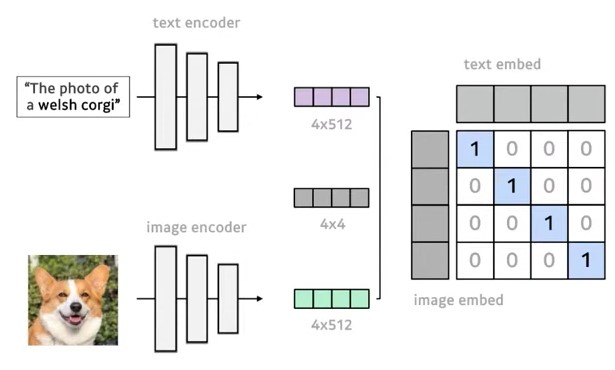
text와 image간의 관계성을 표현할 수 있는 network입니다.
간단히 설명하자면 image와 이에 대응하는 text를 각각 encoder에 넣어 embedding한 다음, 각각을 행렬 곱 하여 대각선에 해당하는 것의 값이 1 나머지가 0이 되게 학습을 하여 text와 image간의 관계성을 학습 하는 network입니다.
U-net
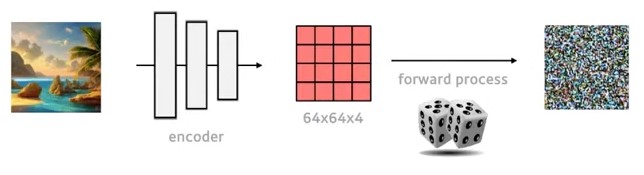
input image를 앞서 학습된 autoencoder의 encoder를 통해 latent feature map으로 encoding한 후 diffusion의 forward process를 거쳐 노이즈화 합니다.
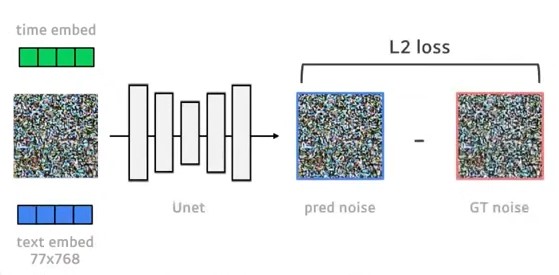
U-Net에 노이즈화된 feature map과 time embedding값, 그리고 이미지에 대응되는 text를 clip에 넣어 얻은 text embedding을 input으로 넣습니다.
U-Net을 거치면 output으로 예측한 noise가 나오고 이를 GT noise와 L2 loss를 통해 학습을 진행합니다.
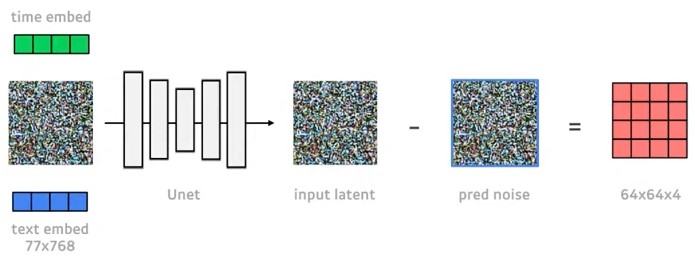
학습이 잘 진행되었다면 input latent에서 예측한 noise를 빼면 앞서 encoder를 통해 나온 latent feature map 거의 일치할 것입니다.
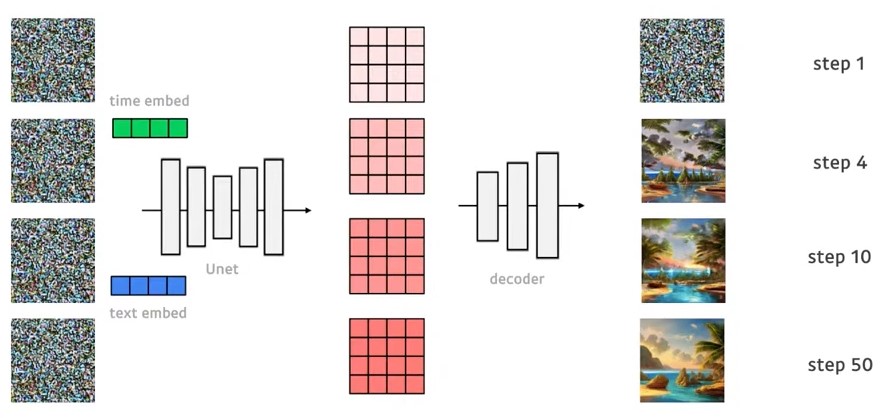
학습을 진행한 step수가 적을 때는 예측한 feature map을 decoder로 복원하였을 때 noise형태와 비슷할 것이고 step수가 많을 때는 decoder로 복원하였을 때 input 이미지와 비슷할 것입니다.
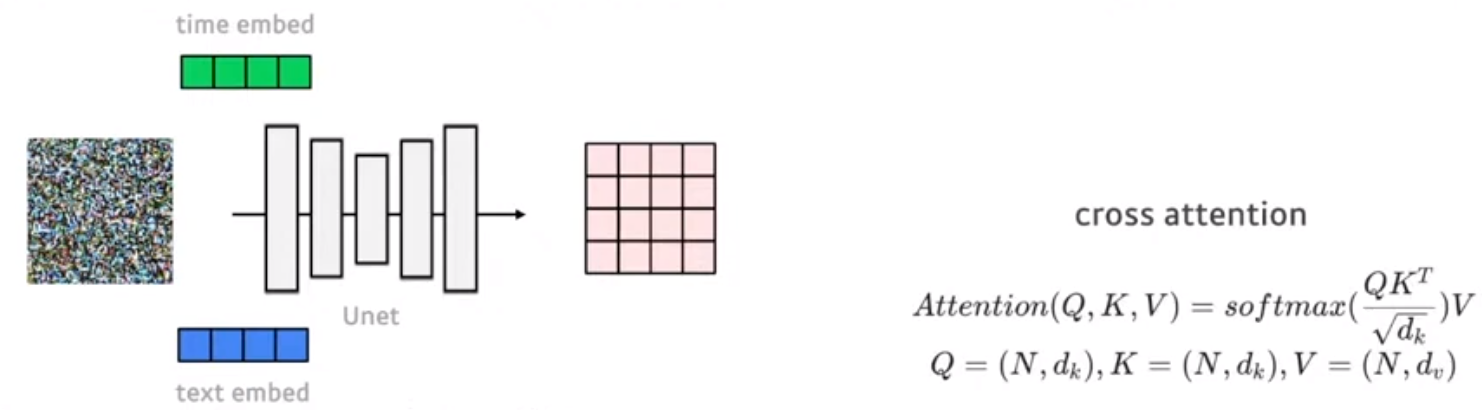
time embedding이 residual connection으로 들어가고 text embedding은 cross-attention을 사용하여 들어갑니다.
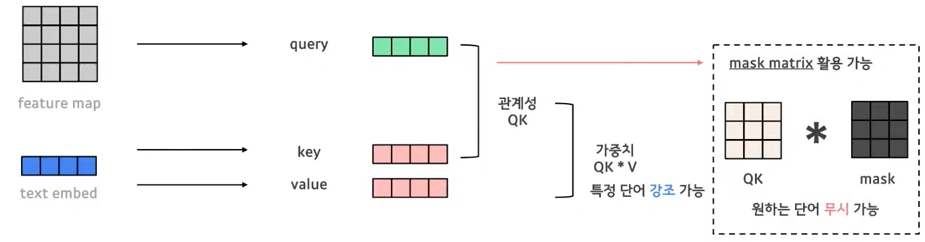
conv layer로 G, K, V를 뽑아내는데 input으로 들어간 noise를 U-Net 거친 feature map으로 부터 쿼리를 구하고 text embedding으로 부터 K, V를 구해 cross attention을 진행합니다.
Q, K를 곱한 것은 Q와 K가 얼만큼의 관계성을 가지는 지를 나타내고 거기에 V를 곱해줌으로써 가중치를 나타냅니다. 예를 들어 I love a cat에서 cat에 대한 가중치를 높이면 cat이 강조되는 이미지가 생성될 것입니다. 이렇게 가중치를 통해 특정 단어를 강조하는 것이 가능하고 mask를 통해 원하는 단어를 무시할 수 있습니다. 예를 들어 cat에 해당하는 것을 mask

cross attention을 진행할 때 text에서 예를 들어 bicycle -> car로 바꾸어 진행하면 위와 같이 사진의 원하는 부분만 바꿀 수 있습니다.
또한 특정 단어에 해당하는 가중치를 높임으로써 원하는 단어를 오른쪽 그림처럼 강조할 수 있습니다.
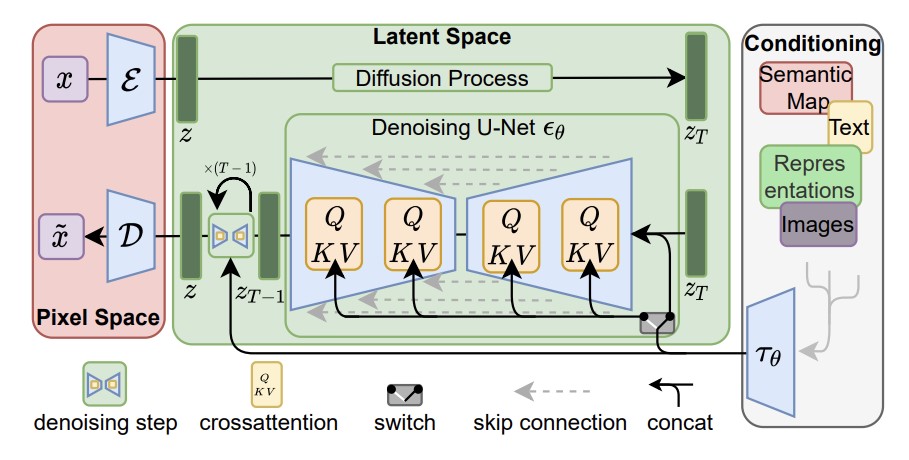
모델의 전체 구조를 보면 input image가 encoder를 통해 latent feature map z로
encoding되고 diffusion process를 거쳐 노이즈화 합니다.
그런 다음 노이즈화된 feature map과 condition으로 주는 text와 time을 embedding하여 U-Net에 input으로 넣어주면 U-Net이 노이즈를 예측하면서 학습이 진행됩니다.

학습 시 사용하는 loss는 위와 같습니다.
그 이후 denoising과정을 거쳐 feature map을 denoising하고 이 feature map을 decoder를 통해 이미지로 변환합니다.
Experiments

학습시 사용한 dataset은 다음과 같습니다.
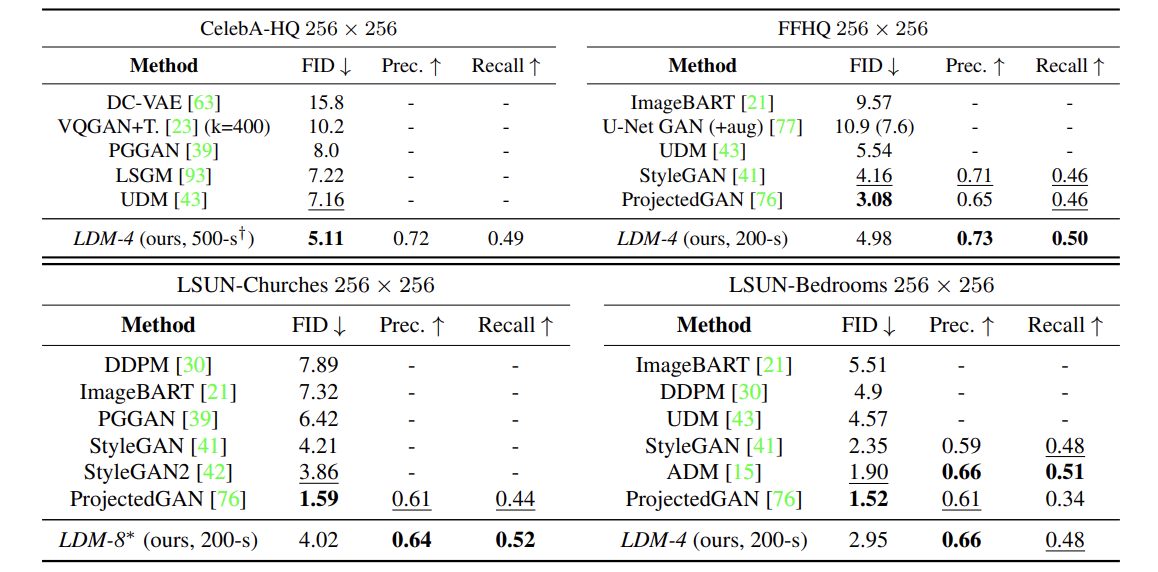
CelebAHQ은 고해상도 이미지 사진 샘플로 많이 쓰이는 사진입니.
이것들을 복원 task에 적용하였을 때, FID 기준으로 SOTA를 달성했습니다.
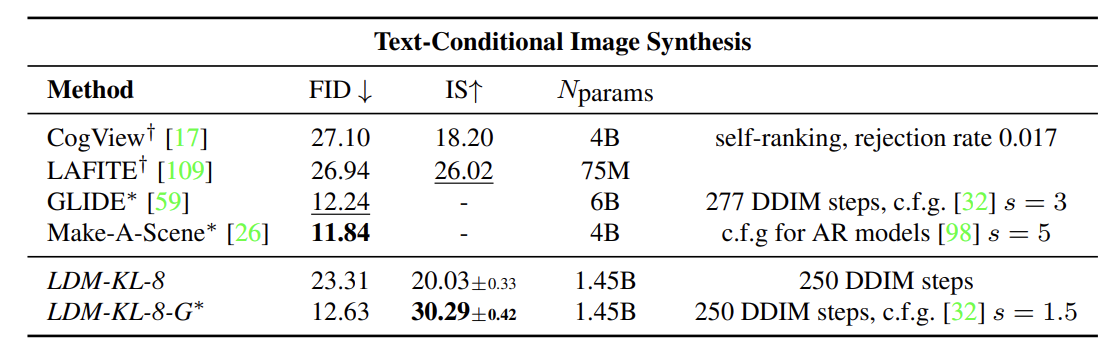
text-to-image 생성에 대해 FID상으로도 LDM 모델이 괜찮은 score를 보여주고 있는데, 포인트는 결국 파라미터 개수이다. 60억개에 달하는 파라미터 수를 14억개로 줄였다는 점입니다.


text-to-image 결과 사진입니다.
Conclusion
pixel-level에서 진행되는 diffusion model과 다르게 autoencoder를 사용하여latent space에서 diffusion process를 적용하는데 high-frequency, imperceptible detail이 추상화되었기 때문에 diffusion process가 더 중요한 semantic bits에 집중할 수 있으며 저차원에서 Diffusion을 하기 때문에 pixel-level diffusion의 퀄리티를 유지한 채로 연산량, 메모리 효율을 개선한 LDM을 제시하였습니다.
아키텍처 상에 cross-attention을 사용함으로써 다양한 conditioned tasks 적용이 가능합니다. ex) text-to-image, super-resolution, inpainting
그러나 LDM도 여전히 GAN보다는 샘플링이 느리다는 단점이 존재합니다.
https://www.youtube.com/watch?v=Z8WWriIh1PU&t=1691s 동영상 강의와 논문을 보며 정리했습니다.
