Image-to-Image Translation with Conditional Adversarial Networks 논문 리뷰 (Pix2Pix)
Abstract
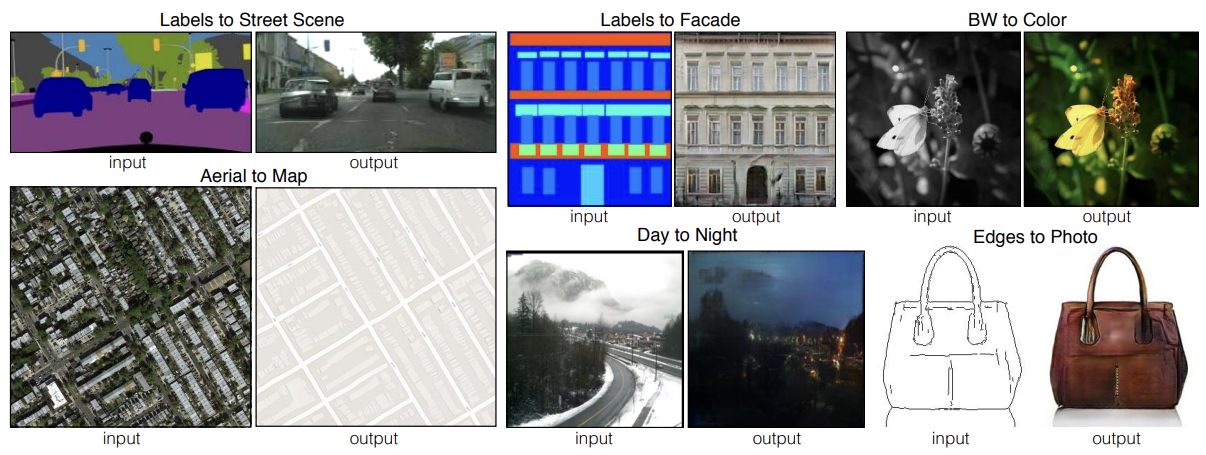
Pix2Pix는 대표적인 image-to-image translation model이다.
image-to-image translation은 위 사진과 같이 주어진 이미지의 특징을 다른 특징으로 바꾸는 것을 의미한다.
Pix2Pix는 conditional GAN의 일종으로 condition을 image로 준다.
Pix2Pix는 pixel들을 입력으로 받아 pixel들을 예측한다는 의미를 가진다.
Architecture
U-Net 기반의 architecture 사용
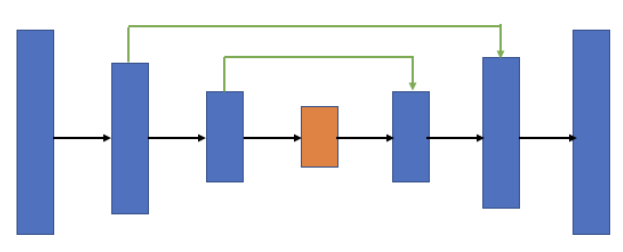
skip connection으로 encoder part의 출력 정보를 bottle neck 이후의 layer에 concat으로 넣어줌으로써 decoder part에서 encoder part의 출력 정보를 사용할 수 있으므로 학습의 난이도가 줄어들고 성능이 향상됐다.
Pix2Pix architecture
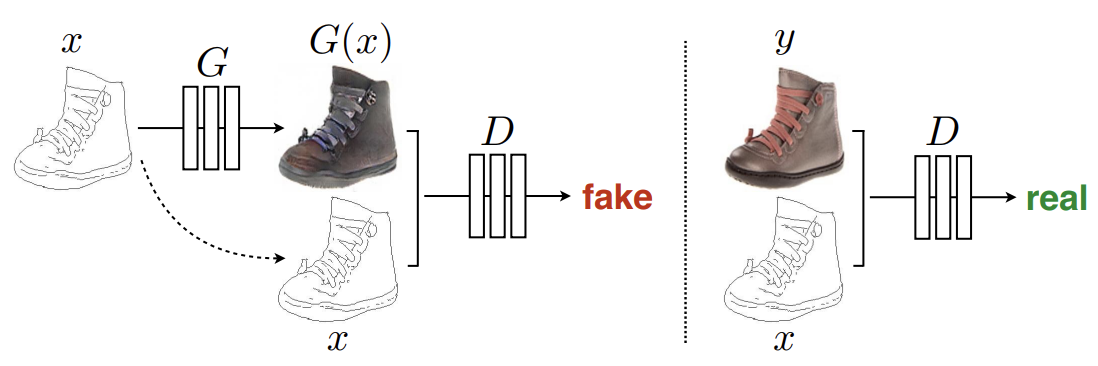
조건 x를 Generator에 넣어주면 G(x)가 출력 이미지를 생성함
G(x)가 생성한 이미지와 조건 x의 정보를 같이 Discriminator에 주어서 T/F를 판별
Loss
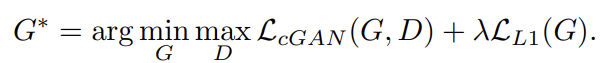
L2 loss를 사용할 때보다 L1 loss를 사용할 때 blurry한 현상이 덜함, why? L2 loss는 모든 매개변수를 평균적으로 minimize하는 효과 -> blurry
따라서 본 논문에선 L1 loss를 함께 사용
Pix2Pix discriminator는 convolutional PatchGAN 분류 방법을 사용
convolutional PatchGAN은 high-frequencies 특징을 잘 표현하기 위해 특정크기의 patch 단위로 T/F 판별
Experiments

L1 loss와 conditional GAN loss를 함께 사용시 가장 성능이 좋은 것을 확인할 수 있다.
