Introduction
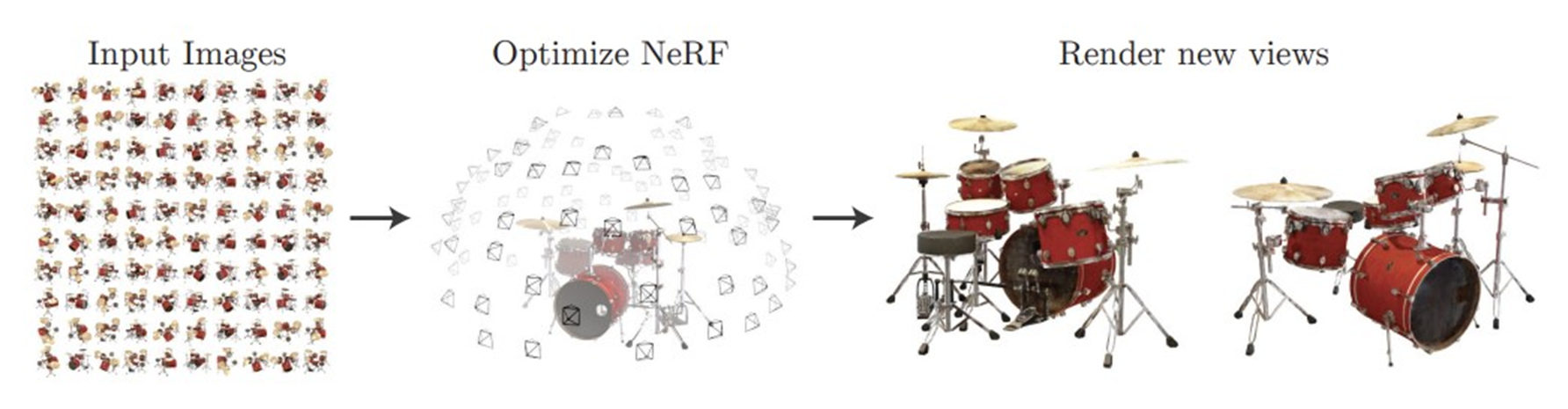
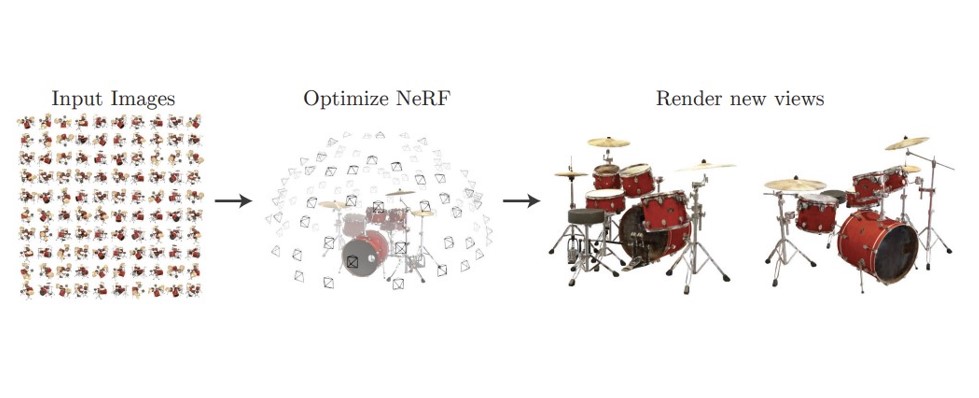
input은 sparse한 이미지와 그에 해당하는 camera의 pose가 주어지면 NerF 모델이 학습을 통해 매개변수를 최적화 하게 되고 그 결과 새로운 camera 포즈에 대해서 그 시점에 해당하는 View가 오른쪽 그림처럼 생성됩니다.
진한 꼬깔콘은 input으로 주어지는 카메라의 시점을 의미하고 연하거나 빈 공간은 우리가 예측할 카메라 시점입니다.
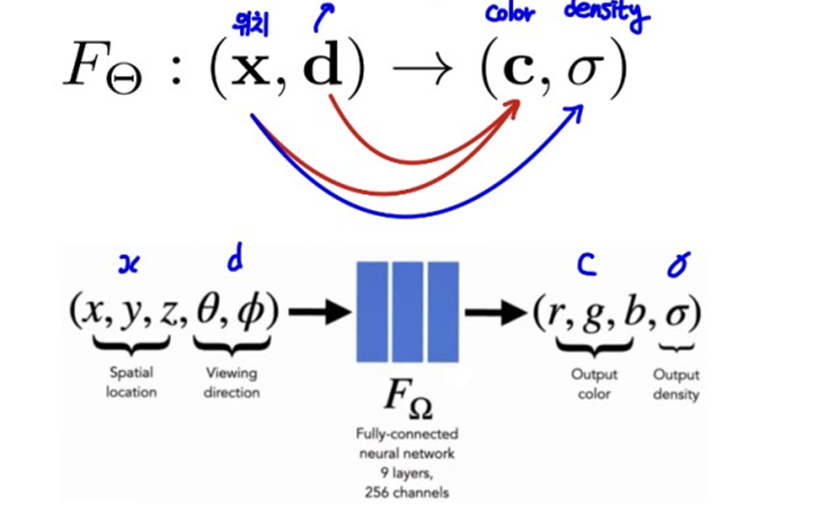
새로운 view를 렌더링하기 위해서 카메라의 위치 x,y,z와 이에 해당하는 방향 정보인 파이와 세타를 input으로 네트워크에 넣어주면 output인 color와 밀도가 나오게 됩니다.
그런 다음, 볼륨 렌더링 기술을 사용하여 이러한 색상과 밀도를 축적하여 2D 이미지를 나타낼 수 있습니다.
볼륨 렌더링에 대해서는 related work에서 설명하겠습니다.
그리고 좀 더 네트워크가 효율적으로 고해상도의 표현을 학습하기 위해 positional encoding과 계층화된 sampling을 사용합니다. 이 두가지 방법은 뒤에서 좀 더 자세히 설명하겠습니다.
이 두 가지 방법을 사용한 결과 고해상도의 사실적인 새로운 view를 렌더링할 수 있는 최초의 continuous neural scene 표현 방법을 제시하였습니다.
Related work
Neural volume
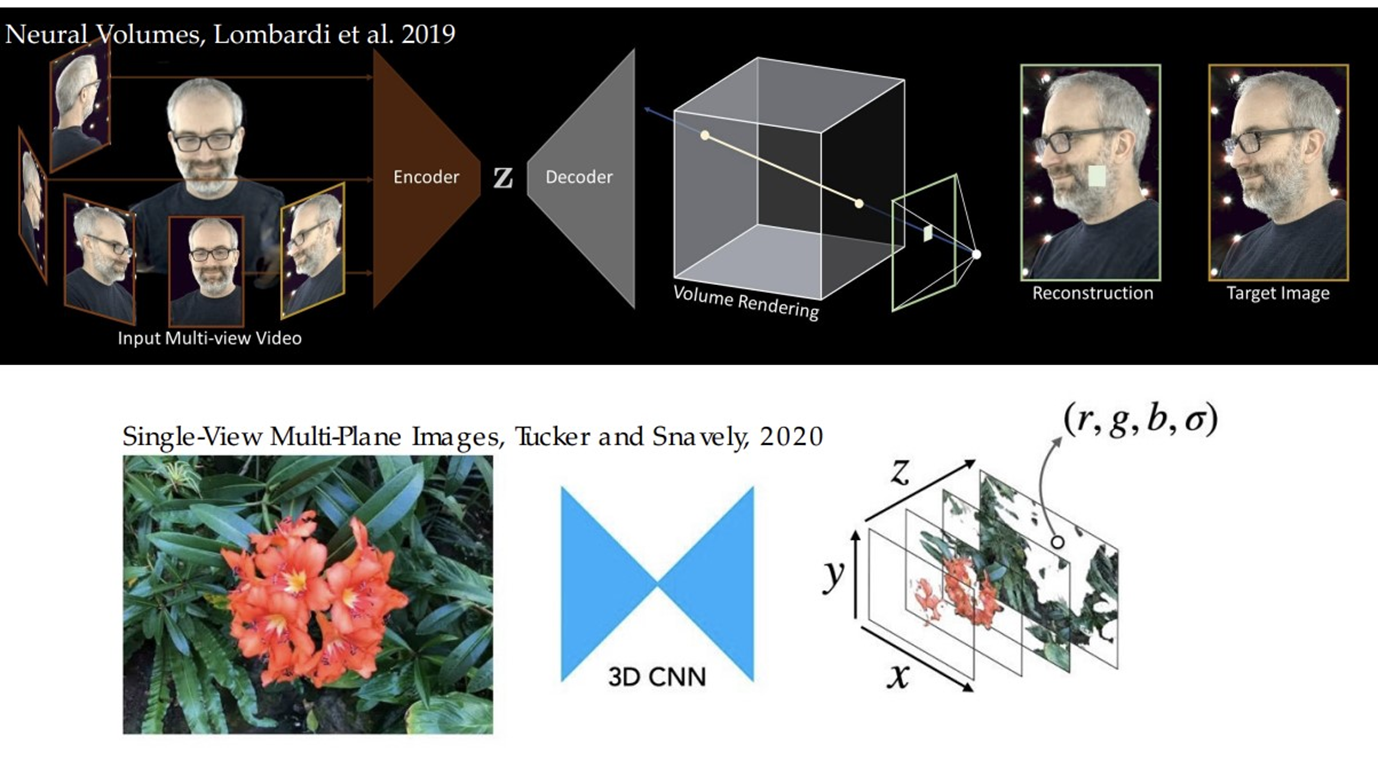
Neural volume 논문이 나오기 전에는 불투명한 물체에 대해서만 recon가능, 내부에 대한 정보 recon X 때문에 반투명, 투명한 물체에 대해 recon X
Neural volume논문에서 내부에 대한 정보도 복원하자는 취지로 Deep neural net을 이용해서 volume rendering 통해 다양한 광학적 특성을 가진 물체에 대해서 recon 가능해졌습니다.
volume rendering
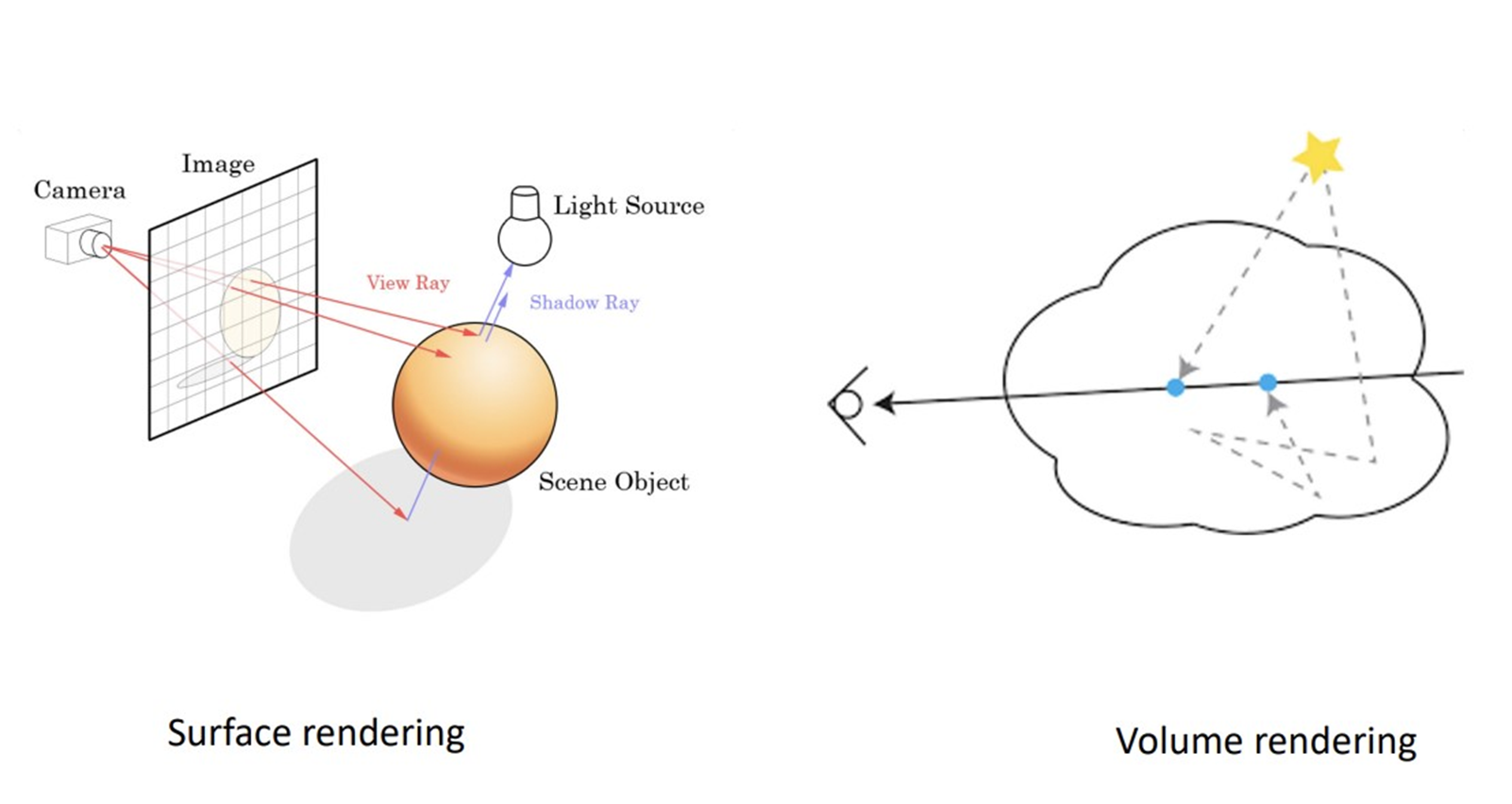
볼륨 렌더링에 대해 설명하기 위해 surface rendering에 대해 간단히 언급하면, 만약 불투명한 물체를 렌더링한다 가정하면 surface에 해당하는 color정보만 알면 렌더링이 가능합니다.
하지만 반투명한 물체를 렌더링하기 위해서는 surface에 대한 color정보만 가지고 렌더링 할 수 없습니다.
그러면 어떤 것을 더 고려해야 하냐면, 한 ray를 따라가서 그 surface안에 해당하는 점의 color와 밀도 정보까지 다 고려해서 그 ray에 해당하는 점들의 색상과 밀도 정보를 다 더해야 한 점의 정확한 색상을 표현할 수 있습니다.
이를 volume rendering이라 합니다.
Method
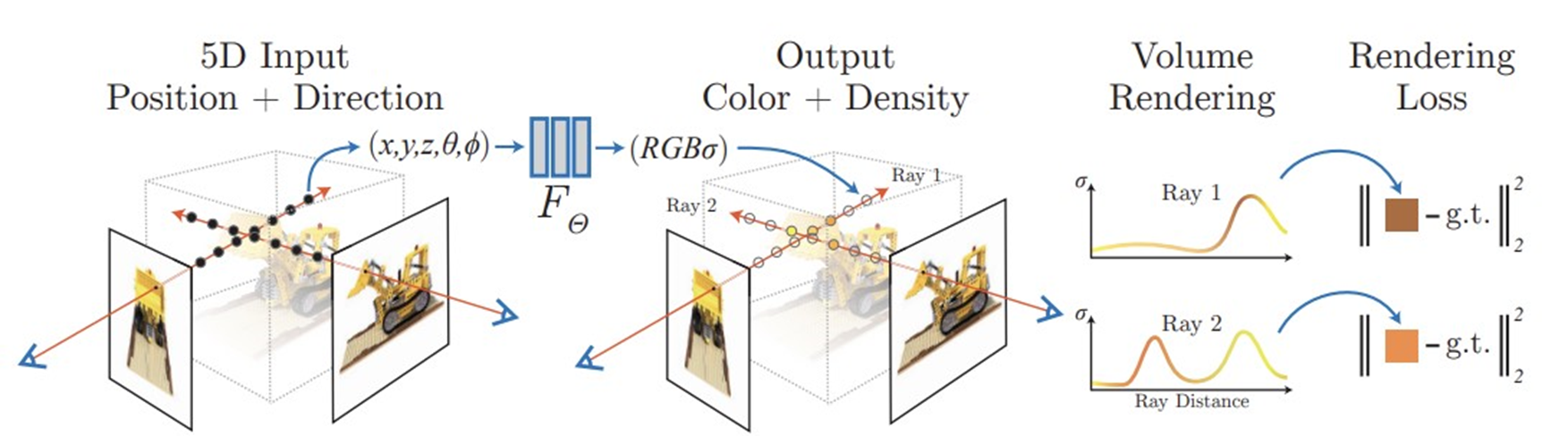
input으로 카메라의 위치인 x,y,z와 방향인 파이와 쎄타가 주어지면 output으로 색상과 밀도의 정보가 나오도록 네트워크를 훈련시킵니다.
네트워크는 MLP layer와 skip connection으로 구성되어 있습니다.
잘 훈련되었다면 ray에 해당하는 각 점들의 색상과 밀도정보를 다 더했을 때 이미지와 같은 색상이 나와야합니다.
이를 수식적으로 보면 아래의 식과 같습니다.

또한 잘 훈련되었다면 각 ray가 교차하는 점의 색상과 밀도 정보는 일치 해야합니다.
오른쪽 그래프는 한 레이에 해당하는 밀도 정보를 시각화 한 것이고 Loss는 g.t의 색상과 네트워크가 출력한 색상의 차이입니다. 그 차이를 최소화 시켜 네트워크를 최적화합니다.
positional encoding
네트워크가 좀 더 효율적으로 고해상도의 영상을 표현할 수 있게 하기위해 positional encoding 기법을 사용합니다.
왜냐하면,
- input만으로 high-frequency 특징을 렌더링하기엔 한계가 있음
- deep network가 학습이 되는 동안 low-frequency 특징으로 편향되는 특징이 있음
- input을 high frequency function을 사용하여 더 높은 차원에 맵핑한 후 네트워크에 입력으로 전달하면 네트워크가 high-frequency특징을 더 잘 표현할 수 있음
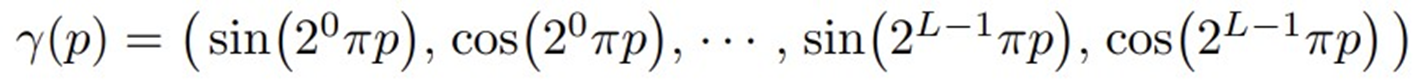
input인 위치 좌표와 방향 정보를 각 sin, cos에 맵핑함으로써 input을 더 높은 차원에 매핑
NerF에선 3D (x : x,y,z) data: L=10, Viewing Direction(d): L=4 사용
Hierarchical volume sampling
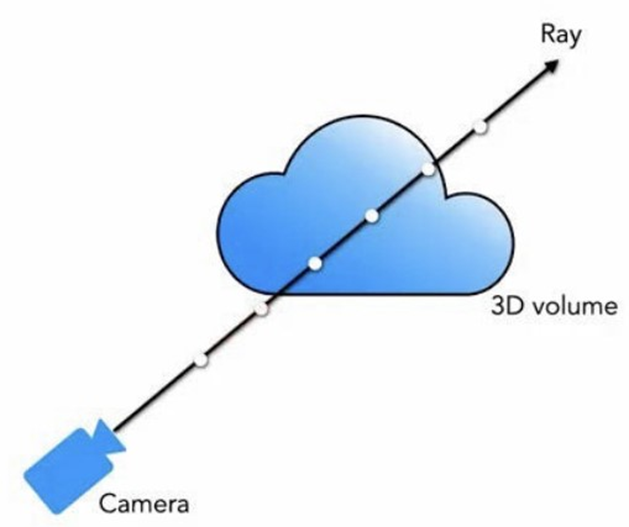
위 사진처럼 ray를 따라 균일하게 샘플링 하는 것은 비효율적입니다. 왜냐하면
-> 렌더링에 기여하지 않는 빈 공간과 닫힌 영역이 존재하기 때문
그래서 두 단계에 걸쳐 효율적으로 샘플링 진행합니다.
Two pass rendering
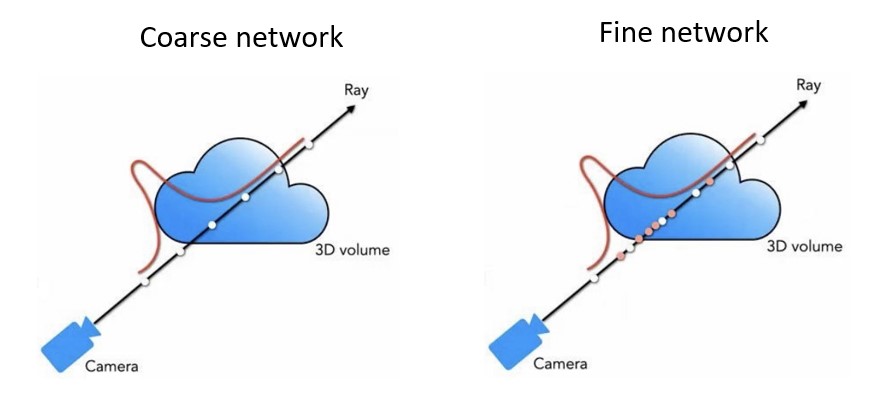
먼저 coarse network는 uniform하게 sampling하여 각 밀도를 구하고 이렇게 구한 밀도를 토대로 높은 밀도를 나타내는 부분에 집중적으로 fine network에서 sampling을 진행하여 nerf model이 좀 더 집중해야할 부분에 sampling을 진행하도록 합니다.
Experiment

실험 결과는 위와 같습니다.


NerF와 다른 모델들을 비교한 사진입니다.
Conclusion
NeRF는 이전의 model보다 더 나은 품질의 렌더링 결과를 제공합니다.
-> high-frequency 특징을 더 잘 살린다던가, 카메라 포즈가 바껴도 consistent한 특징을 유지한다던가
하지만 여러 단점들이 존재합니다.
- traing, inference 속도가 느림
- static한 물체에 대해서만 ..
- 필요한 입력 이미지 수가 많음
- camera parameter 필요
- 조명이 변화면 렌더링 X
따라서 이런 단점들을 개선하는 후속 연구들이 존재합니다.
