
05. 트리 알고리즘
주요 학습 내용
- 성능이 좋고 이해하기 쉬운 트리 알고리즘
- 알고리즘의 성능을 최대화하기 위한 하이퍼파라미터 튜닝
- 여러 트리를 합쳐 일반화 성능을 높일 수 있는 앙상블 모델
05-1. 결정 트리
🔈 결정 트리
yes/no 에 대한 질문을 이어나가면서 정답을 찾아 학습하는 알고리즘.
비교적예측 과정을 이해하기 쉽고 성능도 뛰어나다.
🔧 데이터 준비
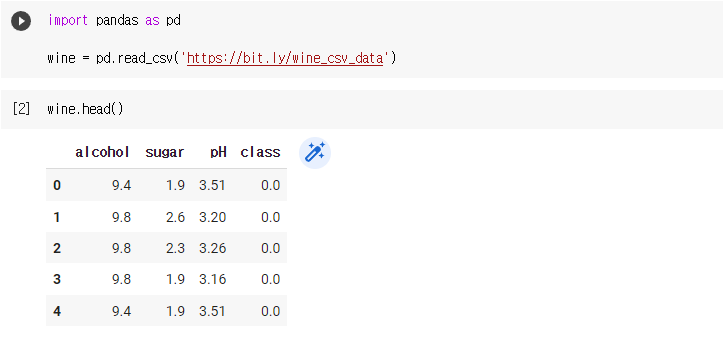
- 화이트 와인과 레드 와인으로 구성된 데이터 준비
- head() 메서드로 처음 5개의 샘플 확인
🔧 데이터프레임의 유용한 메서드 2가지
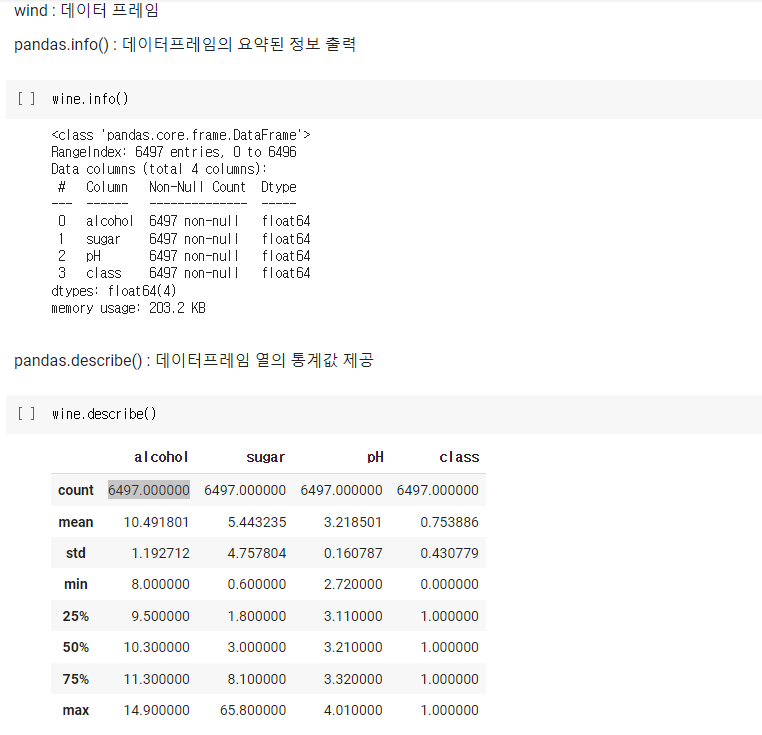
- info() : 데이터프레임의 각 열의 데이터 타입과 누락된 데이터가 있는지 확인하는 데 유용
- describe() : 최소, 최대, 평균값 등 열에 대한 간략한 통계 출력
🔧 결정 트리 통해 정확도 찾기
- 사용법은 로지스틱 회귀와 동일

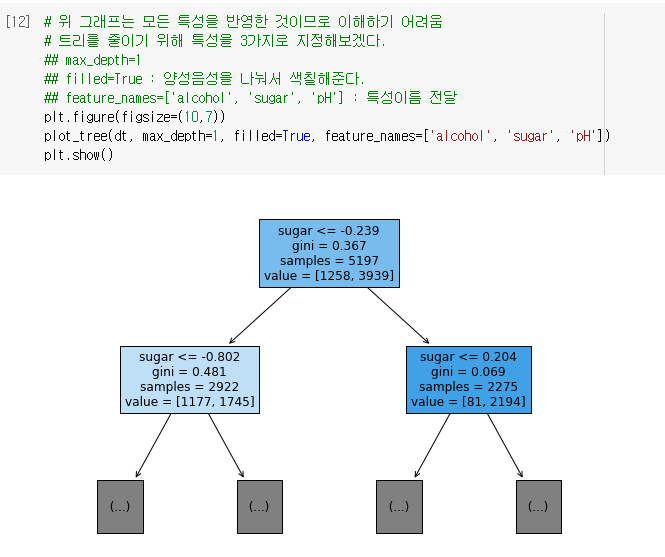
🔧 결정 트리 그리기
- 결정 트리 그려보기

- 더 간단해지도록 트리의 깊이를 제한해보기
🔈 불순도
결정 트리가 최적의 질문을 찾기 위한 기준.
사이킷런은 지니 불순도와 엔트로피 불순도를 제공
🔈 지니 불순도
- DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 'gini' 여서 붙은 이름
- criterion 매개변수의 용도는 노드에서 데이터를 분할할 기준을 정하는 것
- 바로 이 criterion 매개변수에 지정한 지니 불순도를 계산하여 왼쪽과 오른쪽 노드를 나눌 기준을 산출한다.
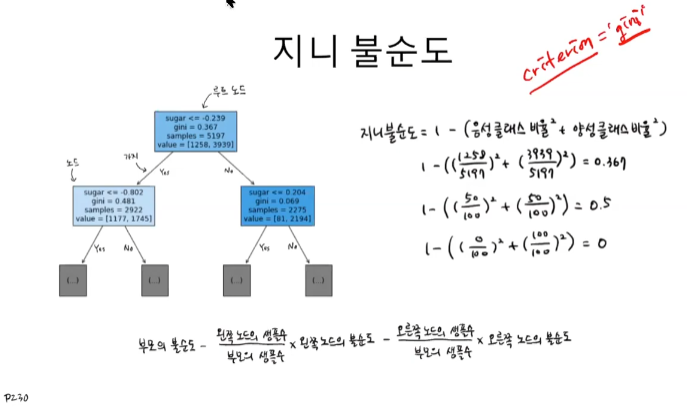
사진출처 : https://www.youtube.com/watch?v=tOzxDGp8rsg&list=PLJN246lAkhQjoU0C4v8FgtbjOIXxSs_4Q&index=11
🔈 정보 이득
부모 노드와 자식 노드의 불순도 차이.
결정 트리 알고리즘은 정보 이득이 최대화되도록 학습한다.
- 따라서 불순도 기준을 사용해 정보 이득이 최대가 되도록 노드를 분할해야 한다.
🔈 가지치기
결정트리는 제한 없이 성장하면 훈련 세트에 과대적합되기 쉽다.
따라서 가지치기 방법을 통해 결정 트리의 성정을 제한한다.
사이킷런의 결정 트리 알고리즘은 여러 가지 가지치기 매개변수를 제공한다.
- 가장 간단한 방법은 자라날 수 있는 트리의 최대 깊이를 지정하는 것
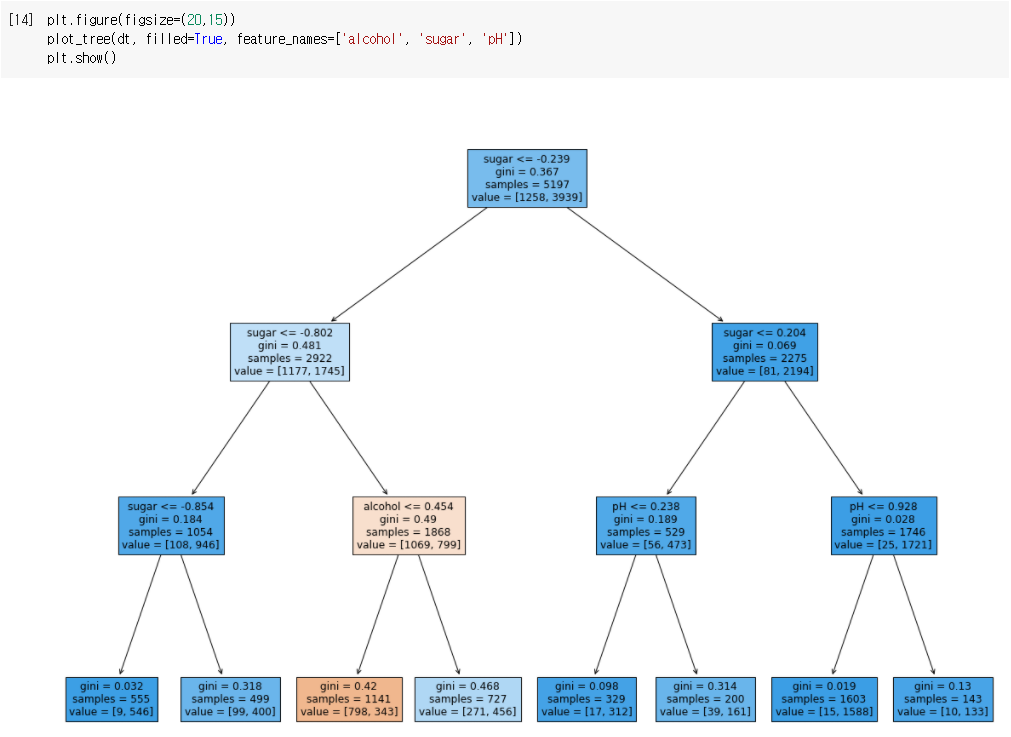
🔧 트리의 최대 깊이를 지정
- DecisionTreeClassifier 클래스의 max_depth 매개변수를 3으로 지정해보자

- 트리 그래프를 그려보자
- 양성클래스-파랑, 음성클래스-주황
🔈 특성 중요도
결정 트레어 사용된 특성이 불순도를 감소하는데 기여한 정도를 나타내는 값
특성 중요도를 계산할 수 있는 것이 결정 트리의 또다른 큰 장점이다.
🔧 featureimportances
feature_importances_: 훈련세트로부터 학습한 값 중 하나로 어떤 특성이 중요하게 사용되었는 가를 판단할 수 있다.- 0.8686으로 suger가 가장 중요하게 사용된 것을 알 수 있다.

05-2. 교차 검증과 그리드 서치
🔈 검증 세트
하이퍼파라미터 튜닝을 위해 모델을 평가할 때, 테스트 세트를 사용하지 않기 위해 훈련 세트에서 다시 떼어 낸 데이터 세트
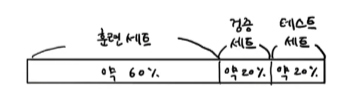
- 지금까지 쉽게 설명하기 위해 훈련세트와 테스트세트 두가지로만 말했지만 사실 데이터는 3분류로 나눈다.
- 테스트 세트로 일반화 성능을 올바르게 예측하려면 가능한 한 테스트 세트를 사용하지 말아야 한다. 모델을 만들고 마지막에 딱 한 번만 사용하는 것이 좋다.
- 때문에 검증 세트가 필요하다.
- 검증 세트는 매개변수 튜닝을 위한 것. 훈련세트를 한번 더 나눠서(20%) 확보한다. 그러나 데이터 자체가 많으면 더 적은 퍼센트를 확보해도 된다.
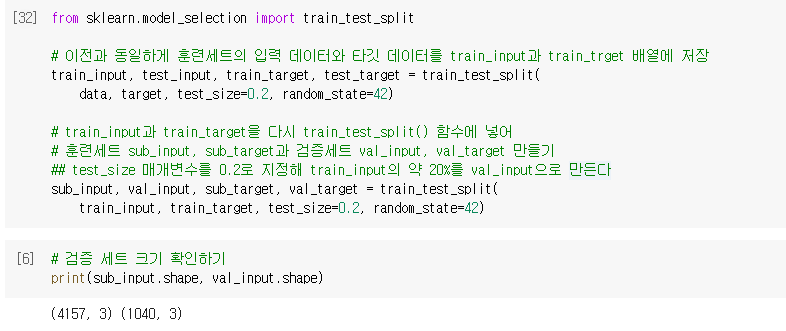
🔧 검증 세트 만들기
- 이전과 동일하게 훈련세트의 입력 데이터와 타깃 데이터를 train_input과 train_trget 배열에 저장
- train_input과 train_target을 다시 train_test_split() 함수에 넣어 훈련세트 sub_input, sub_target과 검증세트 val_input, val_target을 만든다.
- test_size 매개변수를 0.2로 지정해 train_input의 약 20%를 val_input으로 만든다.
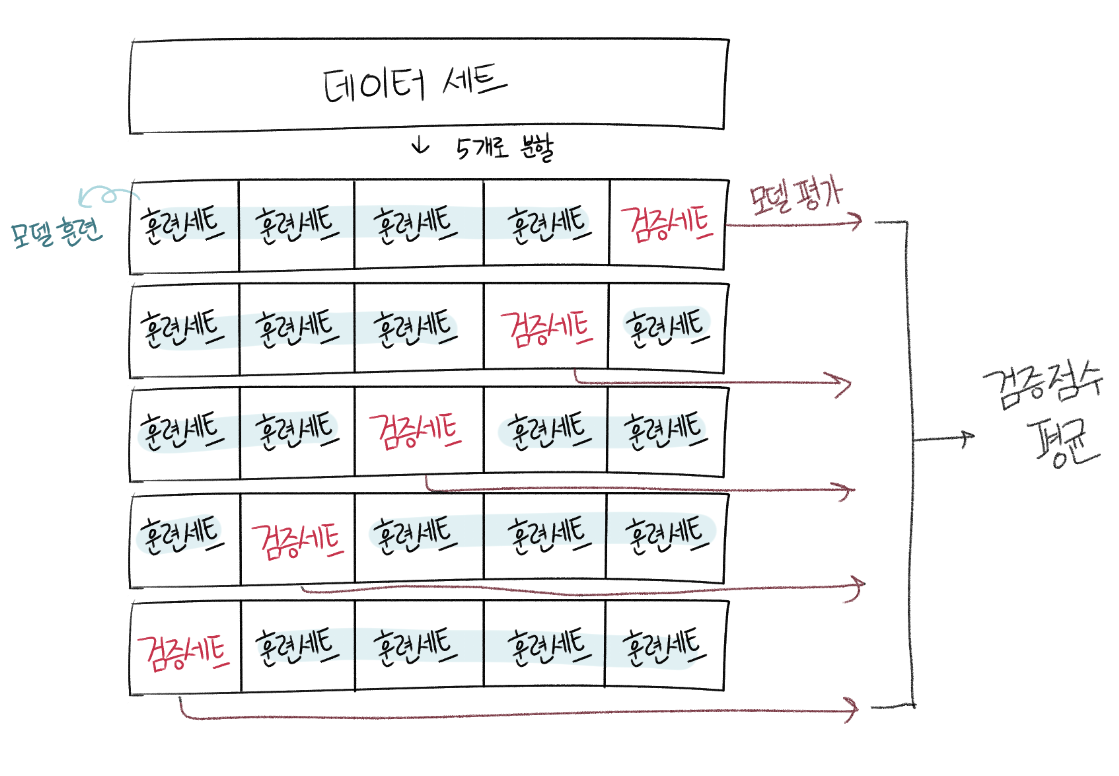
🔈 교차 검증
훈련 세트를 여러 폴드로 나눈 다음 한 폴드가 검증 세트의 역할을 하고 나머지 폴드에서는 모델을 훈련한다.
교차 검증은 이런 식으로 모든 폴드에 대해 검증 점수를 얻어 평균하는 방법
🔧 cross_validate
cross_validate함수에 테스트세트를 분리한 train_input과 train_target을 넣어준다- dt : 매개변수
- 기본으로 데이터를 5개의 모델로 나누는 5폴드

{
'fit_time': array([0.00923681, 0.00792027, 0.00731087, 0.00722575, 0.00701618]),
'score_time': array([0.00079632, 0.00068426, 0.00062895, 0.00060749, 0.00059748]),
'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])
}- 85%정도의 검증평균을 얻을 수 있다.

🔈 하이퍼파라미터 튜닝
모델 파라미터: 머신러닝 모델이 학습하는 파라미터하이퍼파라미터: 모델이 학습할 수 없어서 사용자가 지정해야만 하는 파라미터
🔈 그리드 서치
하이퍼파라미터 탐색을 자동화해 주는 도구
탐색할 매개변수를 나열하면 교차 검증을 수행하여 가장 좋은 검증 점수의 매개변수 조합을 선택한다.
마지막으로 이 매개변수 조합으로 최종 모델을 훈련한다.
🔈 랜덤 서치
연속된 매개변수 값을 탐색할 때 유용하다. 탐색할 값을 직접 나열하는 것이 아니라 탐색 값을 샘플링할 수 있는 확률 분포 객체를 전달한다.
지정된 횟수만큼 샘플링하여 교차 검증을 수행하기 때문에 시스템 자원이 허락하는 만큼 탐색량을 조절할 수 있다.
- 매개변수의 값이 수치일 때 값의 범위나 간격을 미리 정하기 어렵거나 너무 많은 매개변수 조건이 있어 그리드 서치 수행 시간이 오래 걸릴 때 사용한다.
- 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달한다.
🎉 기본 미션
교차 검증을 그림으로 설명하기
05-3. 트리의 앙상블
🎉 선택 미션
앙상블 모델 손코딩 코랩 화면 인증샷
후기
- 이번에도 기본 미션만 겨우 해냈다... 선택미션은 미래의 나에게...
- 무리하기 보다는 아쉽더라도 끝까지 해보는 게 좋다고 생각한다! 여기까지 최선을 다했습니다!
- 마지막까지 화이팅~!
