
06. 비지도 학습
주요 학습 내용
- 타깃이 없는 뎅터를 사용하는 비지도 학습과 대표적인 알고리즘
- 대표적인 군집 알고리즘인 k-평균과 DBSCAN
- 대표적인 차원 축소 알고리즘인 주성분 분석(PCA)
06-1. 군집 알고리즘
🔈 비지도 학습
머신러닝의 한 종류로 훈련 데이터에 타깃이 없다. 타깃이 없기 때문에 외부의 도움 없이 스스로 유용한 무언가를 학습해야 한다. 대표적인 비지도 학습 작업은 군집, 차원 축소 등이다.
🔧 데이터 준비
- 과일 사진 데이터 준비
- 샘플을 숫자로 확인해보자

- 샘플을 이미지로 확인해보자

🔧 픽셀값 분석하기

🔈 히스토그램
구간별로 값이 발생한 빈도를 그래프로 표시한 것이다. 보통 x축이 값의 구간(계급)이고 y축은 발생 빈도(도수)이다.
🔧 무엇을 기준으로 평균을 낼 것인가
- 축을 지정해서 평균을 낼 때
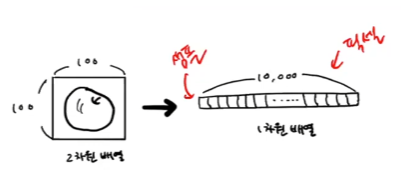
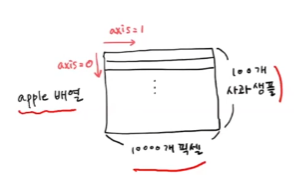
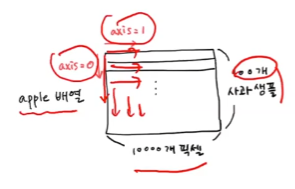
axis =0로 하면 행을 따라서 평균을 내어 10000 개의 값이 나온다.axis =1로 하면 열을 따라서 평균을 내어 100개의 평균 값이 나온다.
🔧 샘플 평균의 히스토그램
- 여기서는 각 샘플별로 평균을 낼 것이므로
axis=1로 지정 - 총 100개의 샘플 평균값
- x축은 구간(픽셀 평균), y축은 빈도
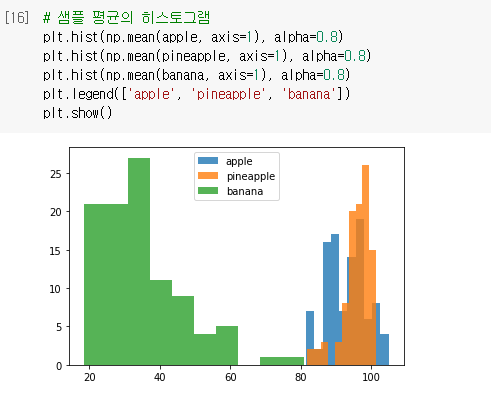
- 사과와 파인애플이 유사하게 나온다.
🔧 픽셀 평균의 히스토그램
- 여기서는 각 픽셀별로 평균을 낼 것이므로
axis=0으로 지정 - 총 10,000개의 픽셀 평균값
- x축은 픽셀, y축은 평균
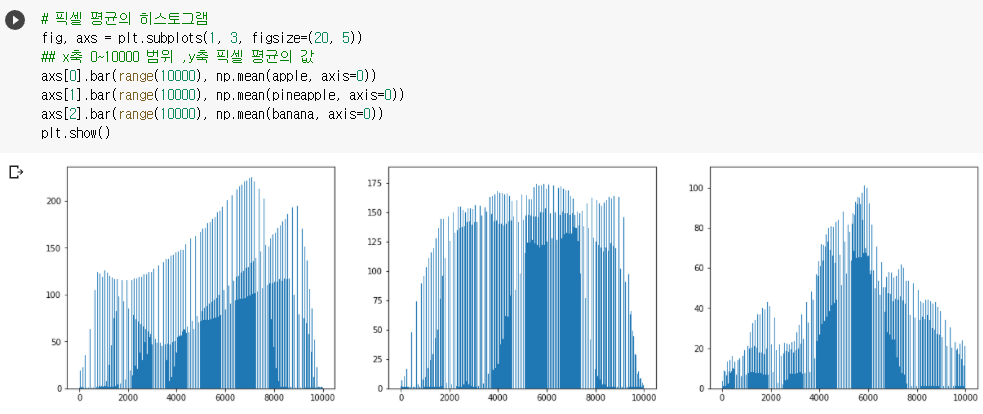
- 사과, 파인애플, 바나나 순
- 사과는 오른쪽 아래가 어둡게, 파인애플은 고르게, 바나나는 중앙부분이 어둡게 나온 것을 알 수 있다.

🔧 평균 이미지 그리기
- 평균을 뽑아내서 새로운 이미지와 비교해볼 수 있을 것이다.

🔧 평균과 가까운 사진 고르기
- 절댓값을 사용하여 평균과 샘플의 차이를 구해낸다.

- 차이가 적은 순으로 정렬하고 그중 100개를 이미지로 보여보니 전부 사과인 것을 확인할 수 있다.
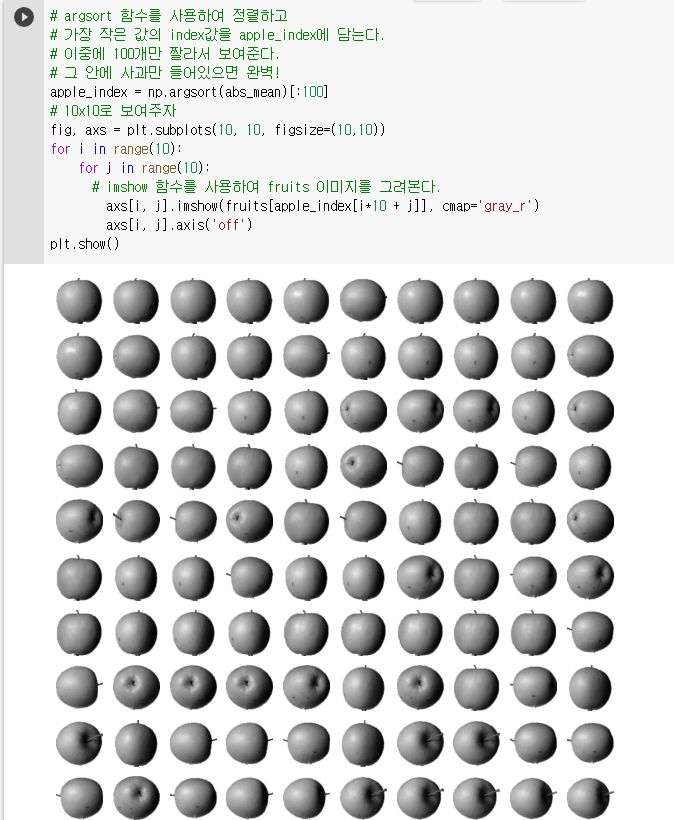
🔈 군집
비슷한 샘플끼리 하나의 그룹으로 모으는 대표적인 비지도 학습 작업이다. 군집 알고리즘(클러스터링 알고리즘)으로 모은 샘플 그룹을 클러스터라고 부른다.
- 위와 같이 골라낸 10x10 사과 샘플 그룹과 같은 것을 군집이라고 한다.
06-2. k-평균
🔈 k-평균
k-평균 알고리즘은 처음에 랜덤하게 클러스터 중심을 정하고 클러스터를 만든다.
그다음 클러스터의 중심을 이동하고 다시 클러스터를 만드는 식으로 반복해서 최적의 클러스터를 구성하는 알고리즘이다.
- 사과는 사과, 바나나는 바나나의 중심값을 찾고 클러스터를 만든다.
- k=3 : 하이퍼 파라미터
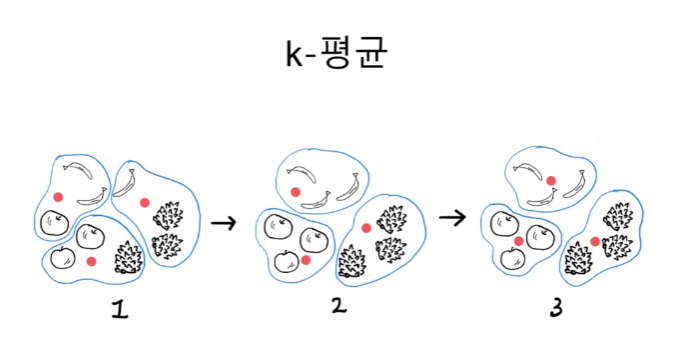
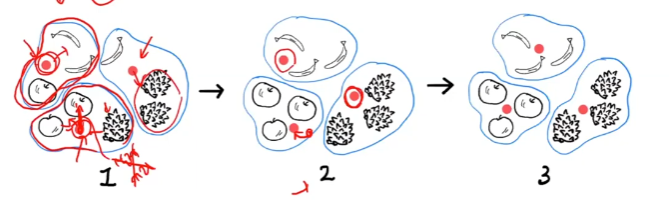
k-평균으로 중심점을 찾는 과정
- 3개의 중심을 랜덤으로 정해 빨간 점으로 표시했다.
- 그리고 가장 가까운 샘플 3개를 하나의 군집으로 모은다.
- 일단 묶은 후 클러스터의 중심을 다시 계산한다.
- 만약 사과가 두개, 파인애플이 하나 있는 클러스터라면 중심점이 사과쪽으로 이동하게 된다.
🎉 기본 미션
k-평균 알고리즘 작동 방식 설명하기!
- 무작위로 k개의 클러스터 중심을 정한다.
- 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정한다.
- 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경한다. (클러스터 재구성)
- 클러스터 중심에 변화가 없을 때까지 3번으로 돌아가 반복한다.
즉, 처음에는 랜덤하게 클러스터 중심을 선택하고 점차 가장 가까운 샘플의 중심으로 이동하는 알고리즘이다.
🔧 모델훈련
- KMeans 알고리즘으로 학습해보자
- 군집으로 나누는 것이 목표이기 때문에 타깃 없이
fruits_2d를 통째로 전달한다.

- 훈련 결과인 km.labels_ 속성에 저장된 것을 출력해본다.

np.unique함수를 통해 결과 확인해보기return_counts=True로 지정하면 0,1,2로 된 값이 몇개 있는지 수를 세준다.- 91개, 98개, 111개로 이루어져 있음
- 제대로 확인해보는 방법은 다 열어봐야하지만 이런 식으로 군집이 가진 샘플수를 통해 짐작할 수 있다.

🔧 첫 번째 클러스터
- 클러스터 내부를 확인해보자.

- index가 임의로 붙기 떄문에 직접 보기 전까지 어떤 과일이 0번일지 알 수 없다.
- 파인애플

- 파인애플
- 바나나

- 바나나
- 사과

- 사과
🔈 클러스터 중심
클러스터 중심은 k-평균 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값이다.
센트로이드(centroid)라고도 부른다.
가장 가까운 클러스터 중심을 샘플의 또 다른 특성으로 사용하거나 새로운 샘플에 대한 예측으로 활용할 수 있다.
🔧 클러스터 중심을 확인하기
- 클러스터 중심인
센트로이드(centroid)가 clustercenters 속성에 들어가 있다.

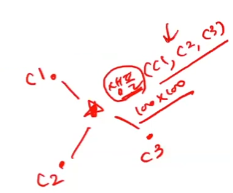
- 샘플 하나를 확인해보자
- 첫 번째 클러스터와의 거리가 가장 짧으므로 첫 번째 클러스터에 속할 확률이 높다.

- 실제로 확인해보니 첫 번째 클러스터에 속해 있다.

- 샘플확인

- 클러스터링을 몇번 했는지 확인
- 이거 책에는 3번이고, 직접 돌렸을 때 처음엔 4, 다시하니까 7이다... 어째서지?

최적의 k 찾기
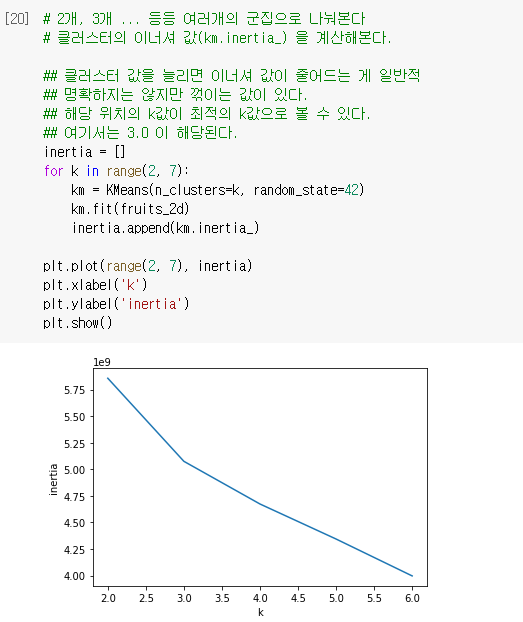
🔈 엘보우 방법
최적의 클러스터 개수를 정하는 방법 중 하나.
이너셔는 클러스터 중심과 샘플 사이 거리의 제곱 합이다.
클러스터 개수에 따라 이너셔 감소가 꺾이는 지점이 적절한 클러스터 개수 k가 될 수 있다. 이 그래프의 모양을 따서 엘보우 방법이라고 부른다.
이너셔
k-평균 알고리즘을 통해 구한 클러스터 중심과 클러스터에 속한 샘플 사이의 거리의 제곱 합
🔧 엘보우 메소드
- 아래 결과에서 최적의 k값은 3.0 이다.
06-3. 주성분 분석
🔈 차원 축소
원본 데이터의 특성을 적은 수의 새로운 특성으로 변환하는 비지도 학습의 한 종류. 차원 축소는 저장 공간을 줄ㄹ이고 시각화하기 쉽다. 또한 다른 알고리즘의 성능을 높일 수도 있다.
🔈 주성분 분석
차원 축소 알고리즘의 하나로 데이터에서 가장 분산이 큰 방향을 찾는 방법이다. 이런 방향을 주성분이라고 부른다. 원본 ㅔ이터를 주성분에 투영하여 새로운 특성을 만들 수 있다. 일반적으로 주성분은 원본 데이터에 있는 특성 개수보다 작다.
🔈 설명된 분산
주성분 분석에서 주성분이 얼마나 원본 데이터의 분산을 잘 나타내는지 기록한 것이다. 사이킷런의 PCA 클래스는 주성분 개수나 설명된 분산의 비율을 지정하여 주성분 분성을 수행할 수 있다.
🔧
🎉 선택 미션
Ch.06(06-3) 확인 문제 풀고, 풀이 과정 정리하기
1. 특성이 20개인 대량의 데이터셋이 있습니다. 이 데이터셋에서 찾을 수 있는 주성분 개수는 몇 개 일까요?
10, 20, 50, 100
2. 샘플 개수가 1,000개이고 특성 개수는 100개인 데이터셋이 있습니다. 즉 이 데이터셋의 크기는 (1000, 100)입니다. 이 데이터를 사이킷런의 PCA 클래스를 사용해 10개의 주성분을 찾아 변환했습니다. 변환된 데이터셋의 크기는 얼마일까요?
(1000,10) (10,1000) (10, 10) (1000, 1000)
3. 2번 문제에서 설명된 분산이 가장 큰 주성분은 몇 번째인가요?
첫 번째 주성분 다섯 번째 주성분 열 번째 주성분 알 수 없음
후기
- 오늘도 기본 미션까지 알차게 하고 갑니다.
- 그림이 나와서 그나마 재밌었어요...
- 혼공머신 하는 여러분들 끝까지 화이팅~!
