ES 에서 검색하기
ES 는 검색에 용이하기 위해 다양한 기능을 제공합니다.
검색에 사용하기 위한 데이터를 저장할 때 텀(Term) 으로 분석 과정을 거쳐 저장하기 때문에 검색 시 대소문자, 단수나 복수, 원형 여부와 상관 없이 검색이 가능한데 이러한 특징을 풀 텍스트 검색(Full Text Search) 라고 하며 한국어로는 전문 검색이라고 합니다.
Query DSL
검색 API를 사용하여 Elastic 검색 데이터 스트림 또는 인덱스에 저장된 데이터를 검색하고 집계할 수 있는데, API의 쿼리 요청 본문 매개 변수는 Query DSL로 작성된 쿼리를 사용합니다.
Query DSL 은 2개의 절로 구분할 수 있습니다.
① 리프 쿼리 절
리프 쿼리 절은 'match', 'term' 또는 'range' 쿼리와 같은 특정 필드에서 특정 값을 찾습니다. 이러한 쿼리는 스스로 사용할 수 있습니다.
② 복합 쿼리 절
복합 쿼리 절은 다른 리프 또는 복합 쿼리를 감싸며 논리적인 방식으로 여러 쿼리를 결합하거나(예: 'bool' 또는 'dis_max' 쿼리) 동작을 변경하는 데 사용됩니다.
관련성 점수
ES 는 검색을 했을 때 검색 결과에 대해서 일치하는 정도를 측정하는 점수를 가지고 있고, 해당 점수에 따라 검색 결과를 정렬합니다.
관련성 점수는 검색 API 를 호출했을 때 _score 필드의 값입니다.
- 점수가 높은 수록 문서의 관련성이 높아지고,
- 각 쿼리 유형은 관련성 점수를 다르게 계산할 수 있으며
- 점수 계산은 쿼리 절이 쿼리 컨텍스트에서 실행되는지, 필터 컨텍스트에서 실행되는지에 따라 달라집니다.
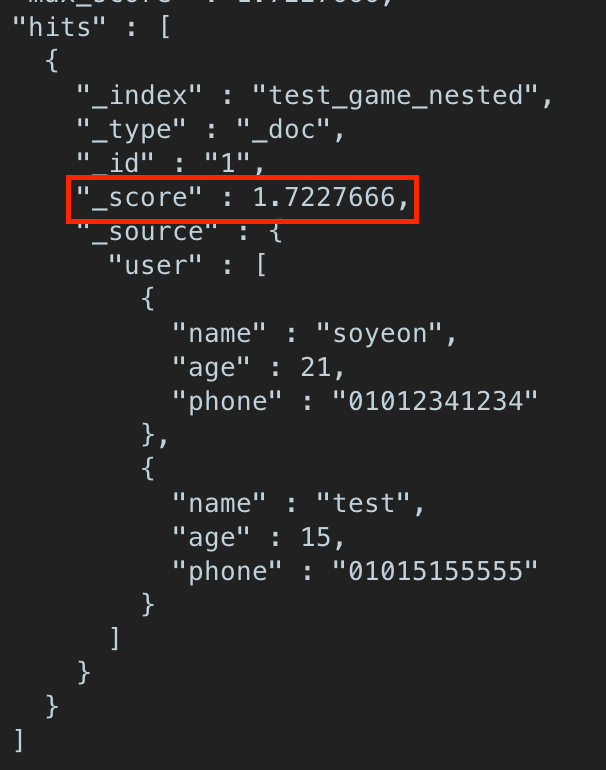
해당 결과에서 _score 이 정렬 점수입니다. 지금은 하나의 데이터밖에 보이지 않지만 여러 데이터가 조회되면 각 데이터 마다 _source 필드가 존재하고, 높은 순서대로 정렬됩니다.
쿼리 컨텍스트 vs 필터 컨텍스트
쿼리 컨텍스트
- "이 문서가 이 쿼리 절과 얼마나 잘 일치합니까?"
- 문서 일치 여부 외에
_score점수도 함께 계산 - 검색 API 의 쿼리 매개 변수와 같은 쿼리 매개 변수로 전달될 때마다 적용
필터 컨텍스트
- "이 문서가 이 쿼리 절과 일치합니까?"
- 점수는 계산되지 않고, 구조화된 데이터를 필터링 하는데 사용
- 쿼리 절이 bool 쿼리의 filter 또는 must_not 매개 변수, constant_score 쿼리의 filter 매개 변수 또는 필터 집계와 같은 필터 매개 변수로 전달될 때마다 적용
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}일 때 bool 쿼리는 쿼리 컨텍스트 이며, 점수에도 영향을 미치지만,
filter 같은 경우 일치하지 않는 문서는 필터링하지만 일치하는 문서의 점수에 영향을 미치지 않습니다.
실습하기 전 index 세팅
실습 및 본격적으로 ES 에 데이터 검색 쿼리를 실행하기 전 students 라는 인덱스를 만들어주도록 하겠습니다.
students 인덱스에는 name(이름, text), age(나이, integer), score(점수, integer), class(반, keyword) 이 매핑되어 있고, 값이 아래와 같이 세팅되어 있습니다.
| 이름 | 나이 | 점수 | 반 |
|---|---|---|---|
| 학생1 | 1 | 90 | A |
| 학생23 | 10 | 90 | A |
| 학생3 | 15 | 80 | B |
| 학생4 | 16 | 74 | B |
| 학생43 | 17 | 50 | A |
PUT /students
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"score": {
"type": "integer"
},
"class": {
"type": "keyword"
}
}
}
}
POST _bulk
{"index":{"_index":"students", "_id":"1"}}
{"name":"학생1", "age": 1, "score": 90, "class": "A"}
{"index":{"_index":"students", "_id":"2"}}
{"name":"학생23", "age": 10, "score": 90, "class": "A"}
{"index":{"_index":"students", "_id":"3"}}
{"name":"학생3", "age": 15, "score": 80, "class": "B"}
{"index":{"_index":"students", "_id":"4"}}
{"name":"학생4", "age": 16, "score": 74, "class": "B"}
{"index":{"_index":"students", "_id":"5"}}
{"name":"학생43", "age": 17, "score": 50, "class": "A"}bool 복합 쿼리
- Lucene BooleanQuery에 매핑
- 여러 쿼리를 조합하기 위해서는 상위에 bool 쿼리를 사용하고 그 안에 다른 쿼리들을 넣는 식으로 사용
| 명명 | 설명 |
|---|---|
| must | 쿼리가 참인 도큐먼트들을 검색, 쿼리 컨텍스트 |
| must_not | 쿼리가 거짓인 도큐먼트들을 검색, 쿼리 컨텍스트 |
| filter | 쿼리가 참인 도큐먼트를 검색하지만 스코어를 계산하지 않음. must 보다 검색 속도가 빠르고 캐싱이 가능, 필터 컨텍스트 |
| should | 검색 결과 중 이 쿼리에 해당하는 도큐먼트의 점수를 높임, 쿼리 컨텍스트 여러 조건 중 하나 이상을 만족하는 문서가 검색 |
실제로 사용해보겠습니다.
① must
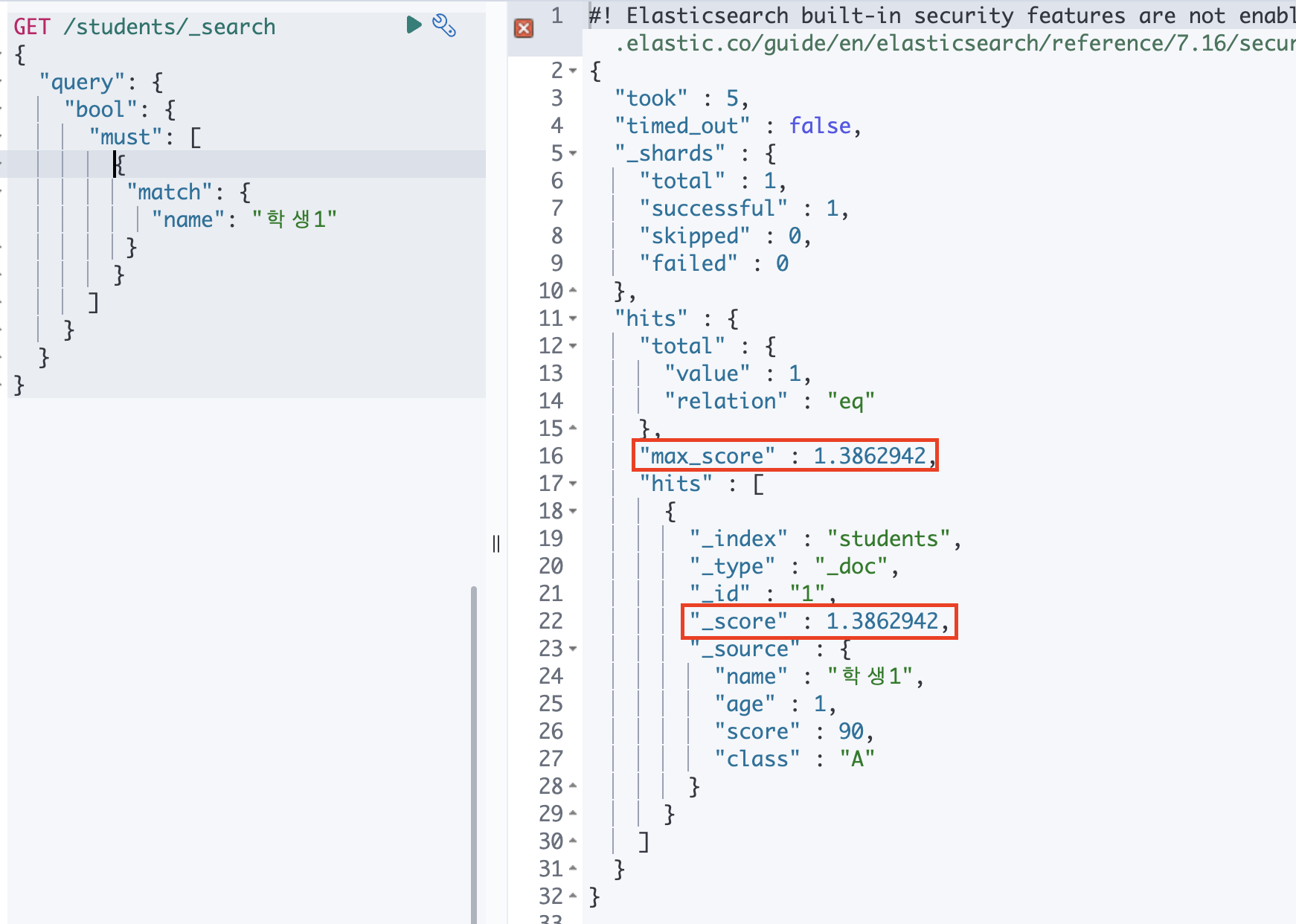
학생1에 속하는 값이 정상적으로 잘 출력 되는 걸 확인 할 수 있습니다.
must 는 쿼리 컨텍스트이기 때문에 _score 점수까지 노출되고 있습니다.
그렇다면 필터 컨텍스트인 filter 같은 경우는 같은 쿼리에서 어떻게 결과가 나타나는지 봐보도록 하겠습니다.
위와 동일한 쿼리에서 must -> filter 로만 변경 후 쿼리를 실행한 결과입니다.
② filter
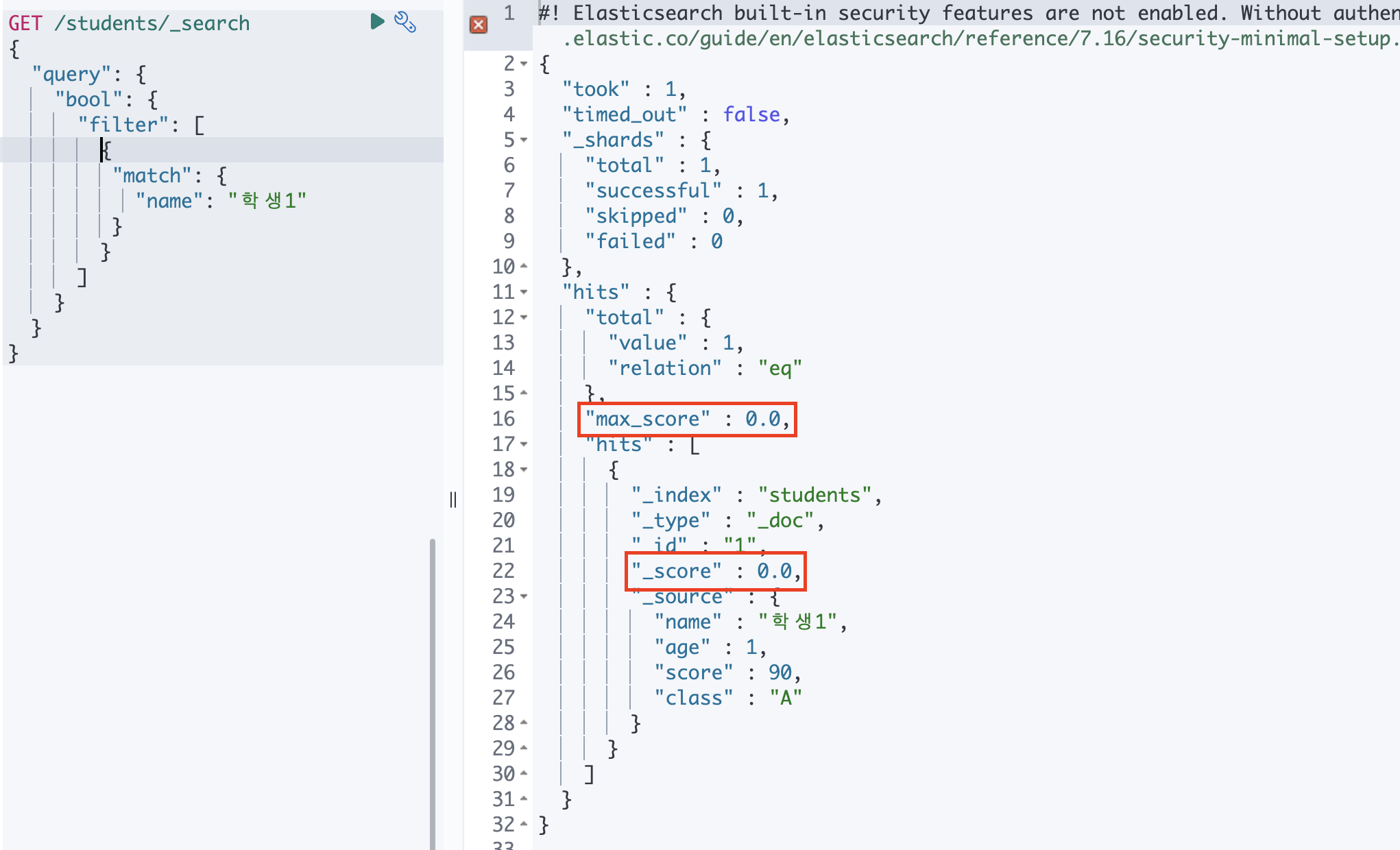
학생1에 대한 정보가 나오는 건 동일하지만 max_score, _score 에 대한 점수는 노출되지 않고 있습니다.
③ should
그럼 다음으로 should 를 사용해보도록 하겠습니다.
should 는 단독으로 사용할 때, 다른 쿼리와 복합적으로 사용할 때 총 두가지의 경우로 나뉩니다.
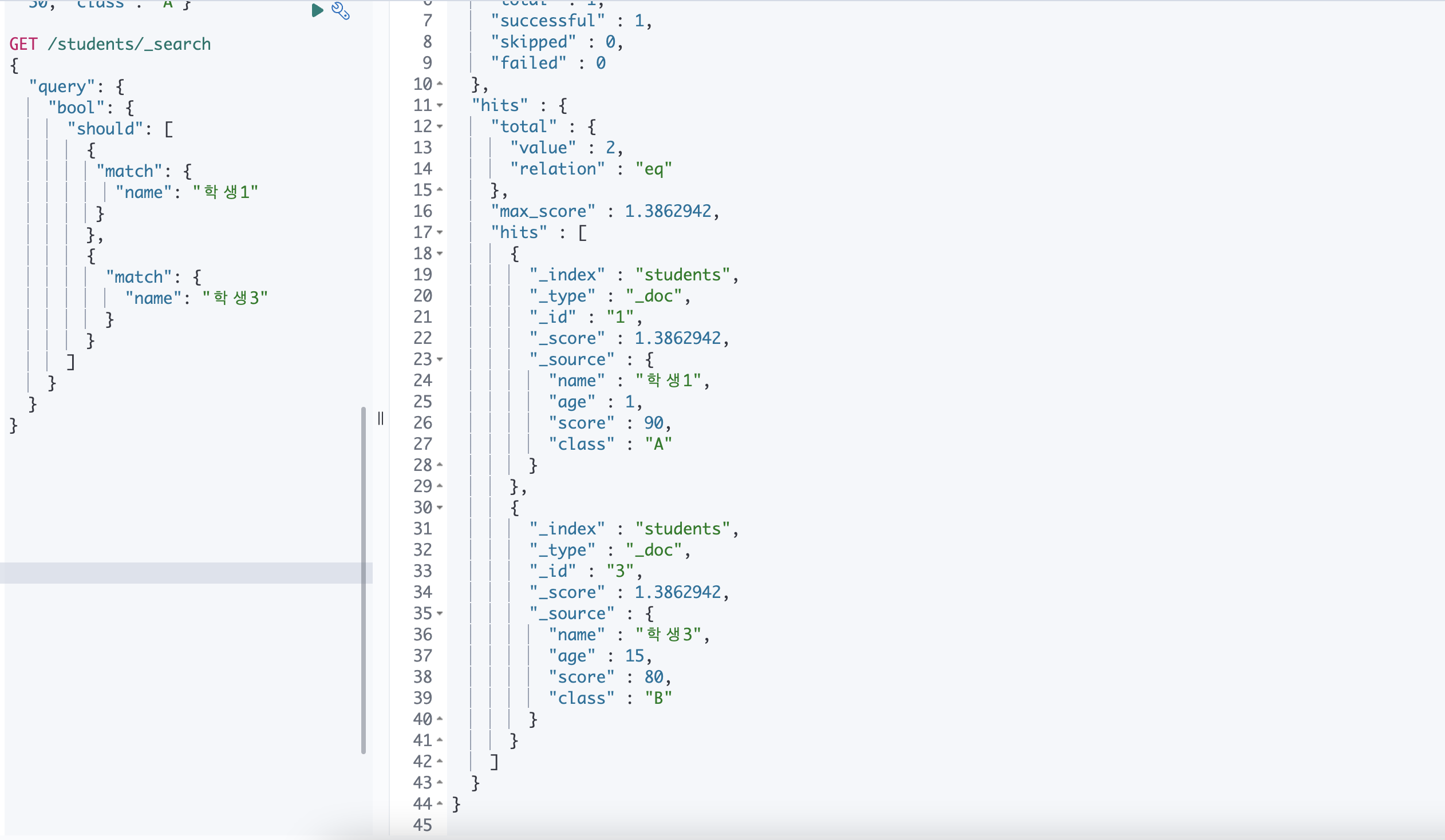
첫번째로 단독으로 사용하는 경우 : OR 로 적용
👉 학생1, 학생2 조건에 속한 문서가 검색된다.
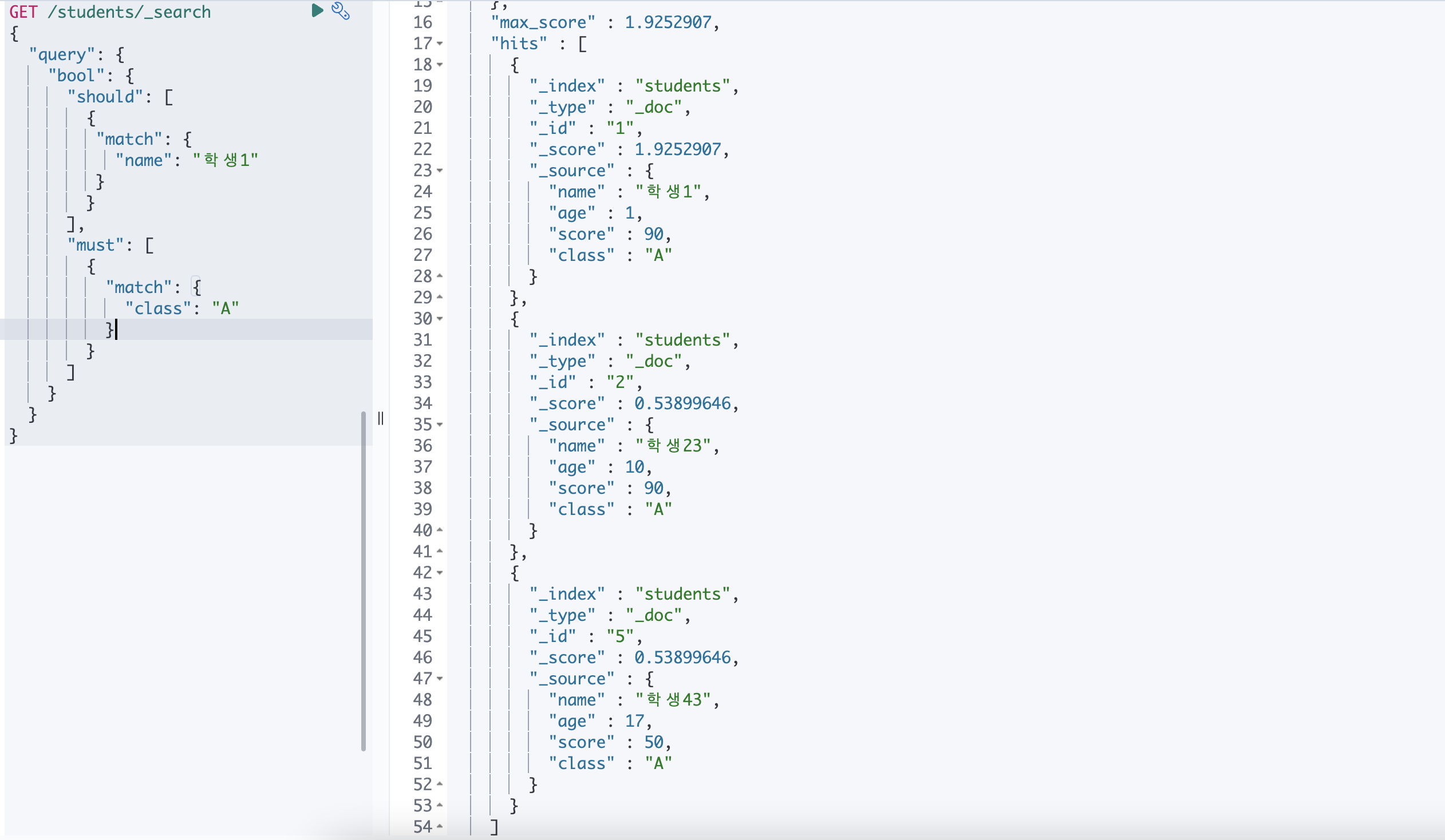
두번재 다른 쿼리와 복합적으로 사용하는 경우 : score 로 적용
👉 다른 쿼리에 속한 값이 노출되지만, should 에 있는 조건인 경우 더 높은 score 을 부여합니다.
풀 텍스트 쿼리
- 분석된 텍스트 필드를 검색
- 인덱싱 중에 필드에 적용된 분석기와 동일한 분석기를 사용하여 처리
| 명명 | 설명 |
|---|---|
| match | - 전체 텍스트 검색을 수행하기 위한 표준 쿼리 - 주어진 텍스트는 검색하기 전 분석됨 - 띄워쓰기가 포함되서 값이 주어지는 경우 OR 로 조회 |
| match_all | 별다른 조건 없이 해당 인덱스의 모든 도큐먼트를 검색하는 쿼리 |
| match_phrase | 입력된 검색어를 순서까지 고려하여 검색을 수행하는 쿼리 |
| query_string | - URL검색에 사용하는 루씬의 검색 문법을 본문 검색에 이용하고 싶을 때 사용하는 쿼리 - 구문을 사용하여 AND 또는 NOT와 같은 연산자를 기반으로 제공된 쿼리 문자열을 구문 분석 및 분할 - 그런 다음 쿼리는 일치하는 문서를 반환하기 전에 분할된 각 텍스트를 독립적으로 분석 |
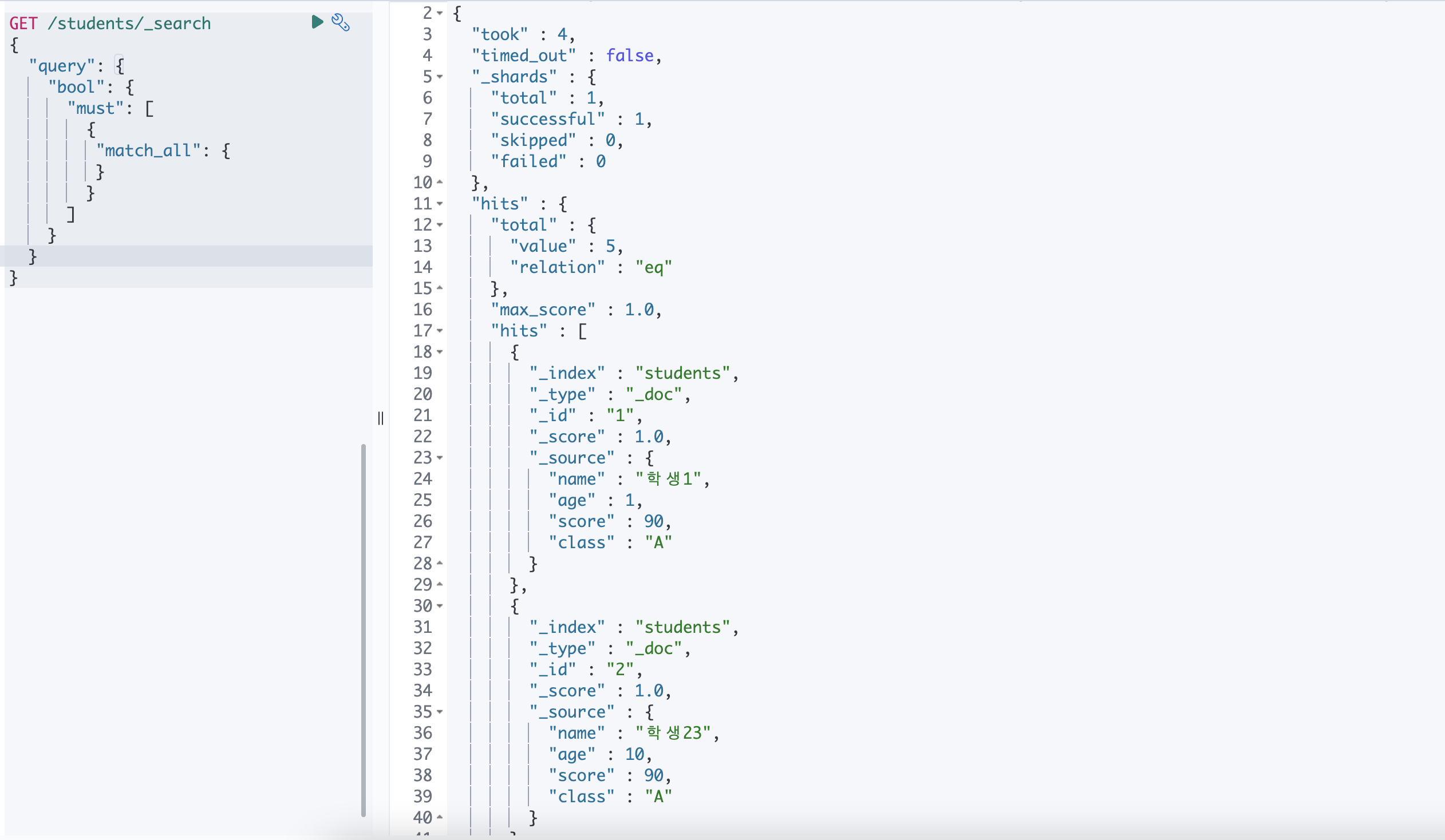
① match_all
students 인덱스에 있는 모든 데이터가 노출 됩니다.
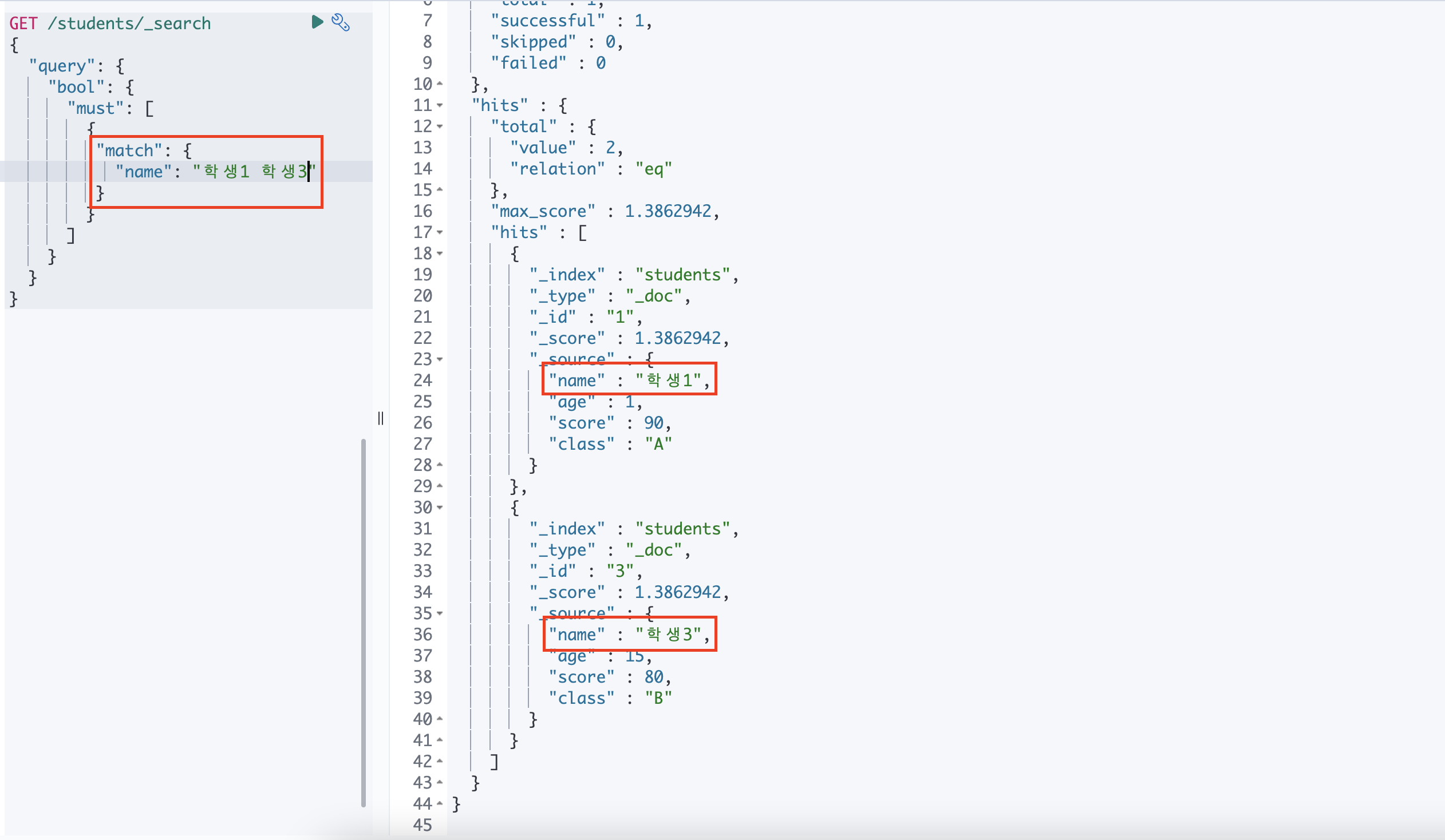
② match
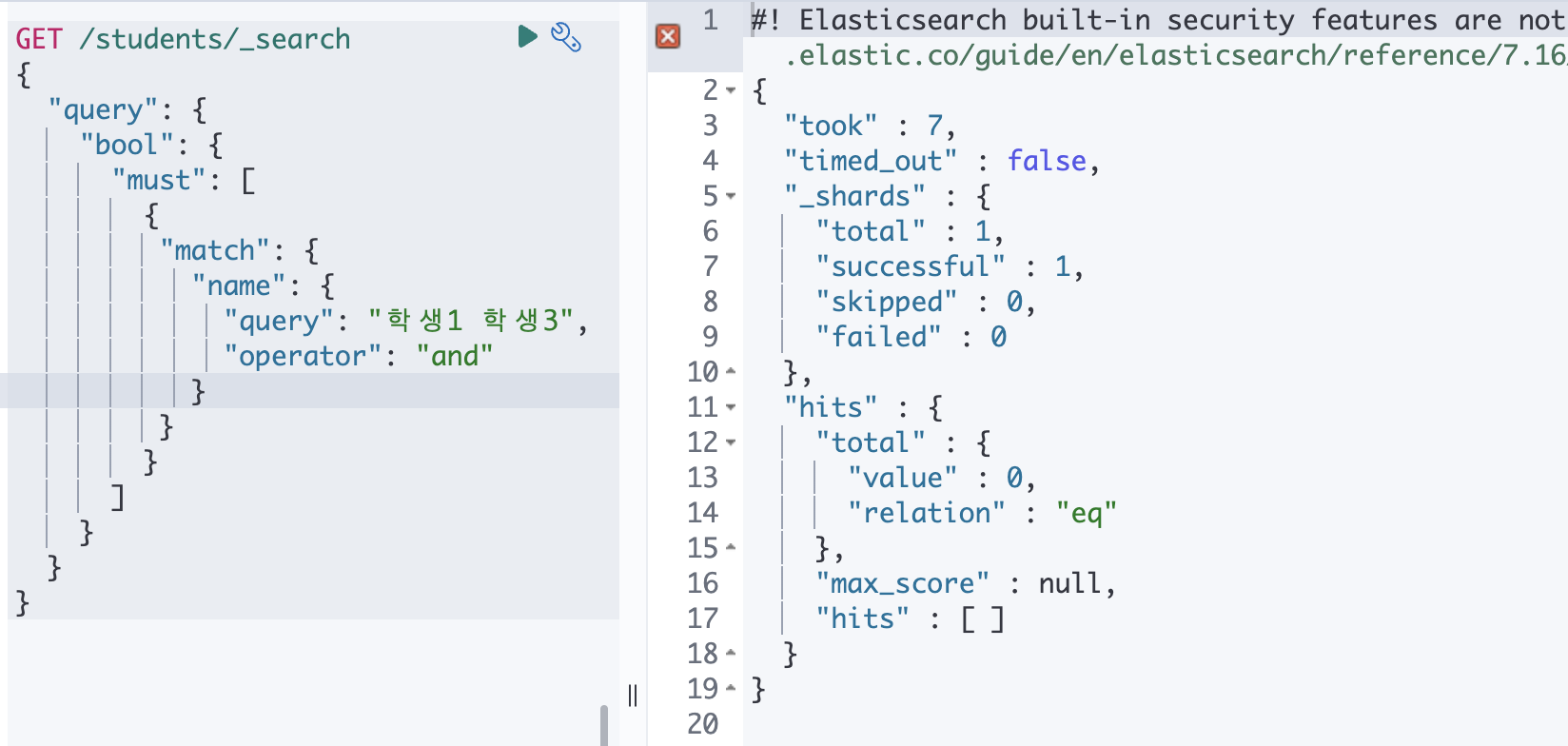
공백이 OR 연산자로 작동합니다. 그렇기 때문에 학생1 학생3 으로 검색하는 경우 학생1 OR 학생3 으로 검색됩니다.
이걸 OR 가 아니라 AND 로 바꾸고 싶다면 operator 을 명시해주면 됩니다
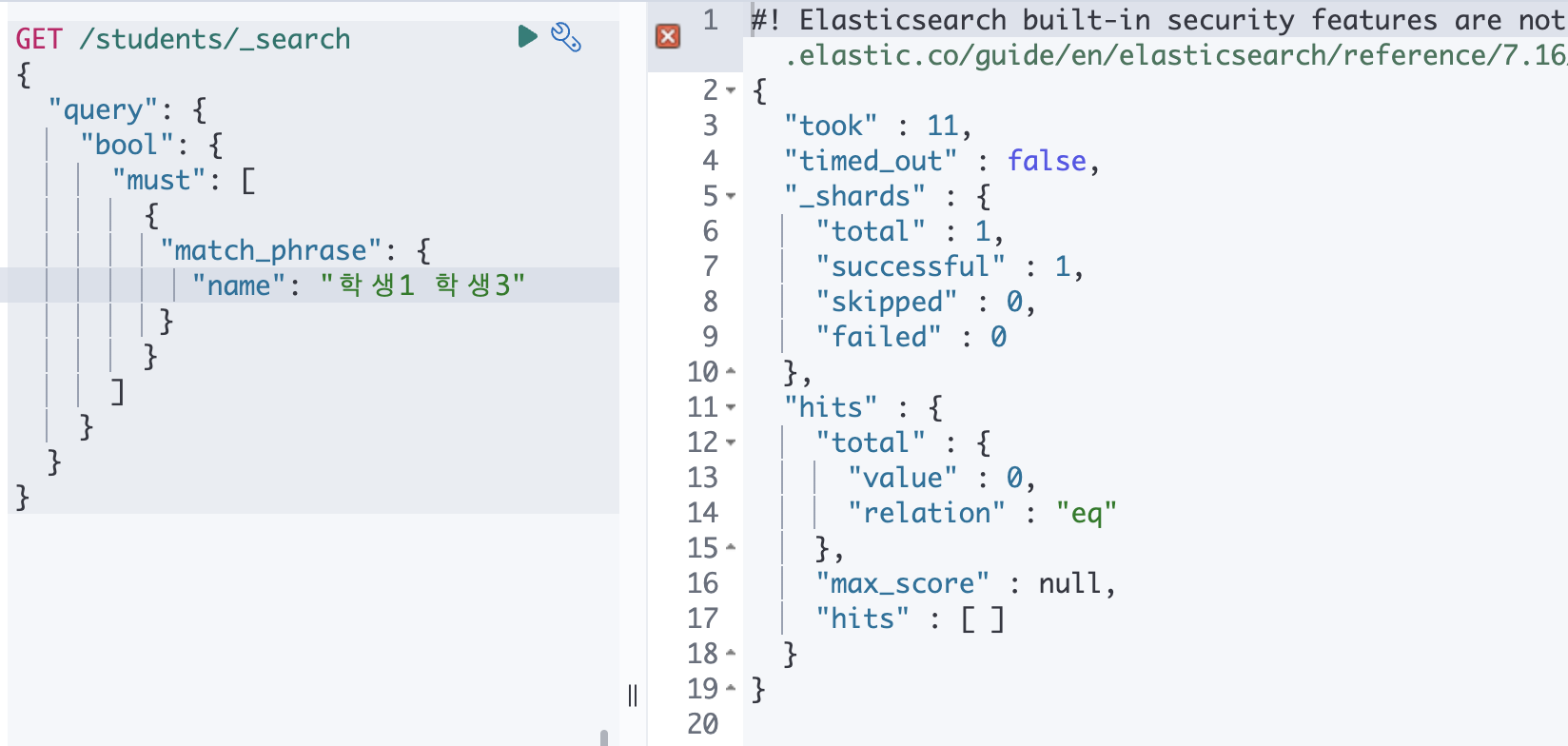
③ match_phrase
match 쿼리와 거의 동일하게 작동하지만 순서까지 필터링합니다.
EX) 안녕 hi 라는 값이 있을 때 안녕 hi 하고 검색해야 값이 나옴. hi 안녕으로 검색하는 경우에는 값 노출 X
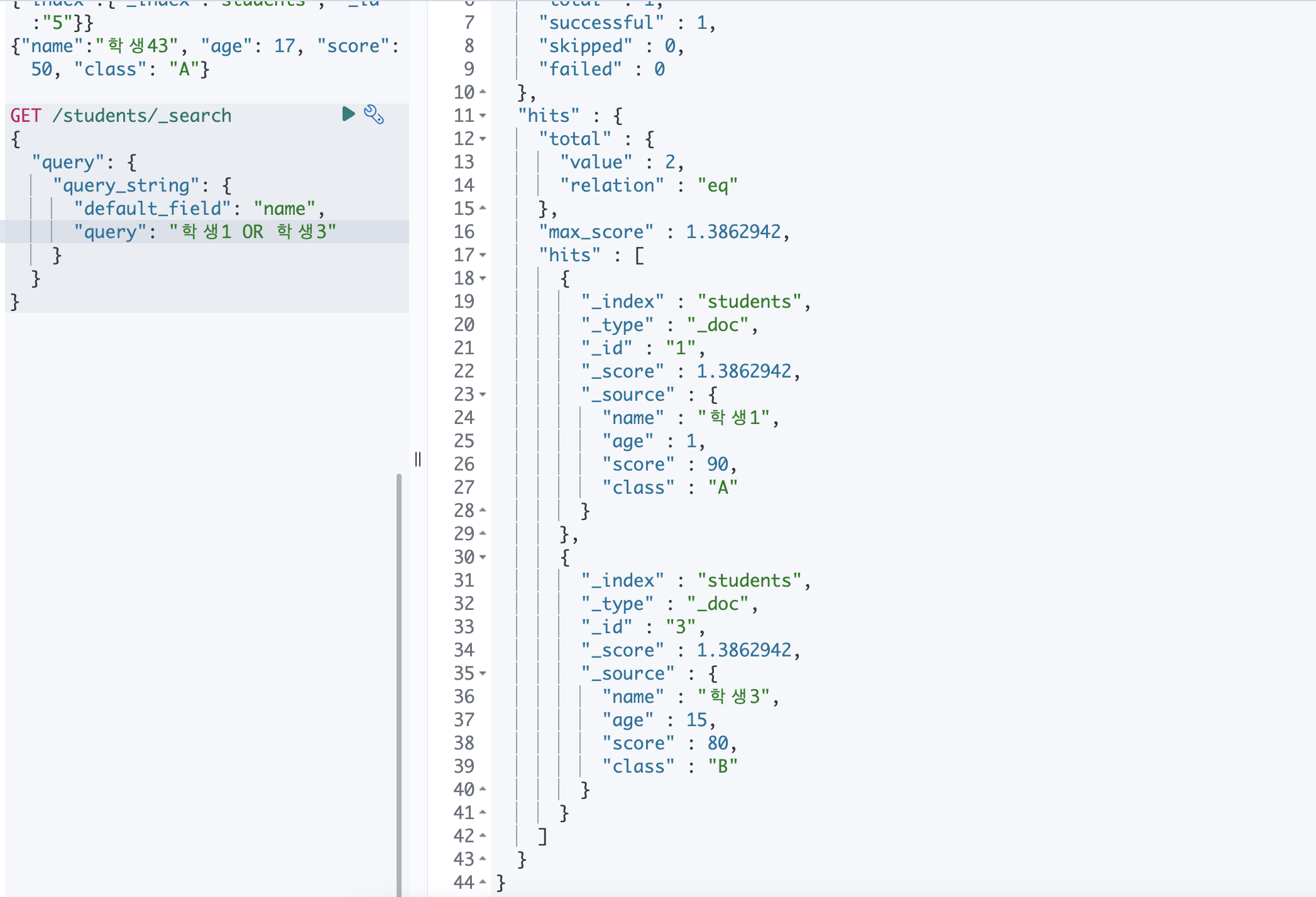
④ query_string
내장된 쿼리 분석기를 이용하는 질의를 작성할 수 있습니다.
Term-level 쿼리
- Analyer 를 사용하지 않고 정확한 값을 조회하는 쿼리
- 검색어를 분석하지 않음.
- keyword 타입을 대상으로 함
| 명명 | 설명 |
|---|---|
| exists | 실제 값이 존재하는 문서만 반환 |
| fuzzy | Levenshtein 편집 거리로 측정한 검색어와 유사한 용어를 포함하는 문서를 반환 |
| range | 범위 내 데이터를 리턴하는 쿼리 |
| term | 제공된 필드에 정확한 용어가 포함된 문서를 반환 |
| terms | 제공된 필드에 하나 이상의 정확한 용어가 포함된 문서를 반환 |
| wildcard | 와일드카드 패턴과 일치하는 용어를 포함하는 문서를 반환 |
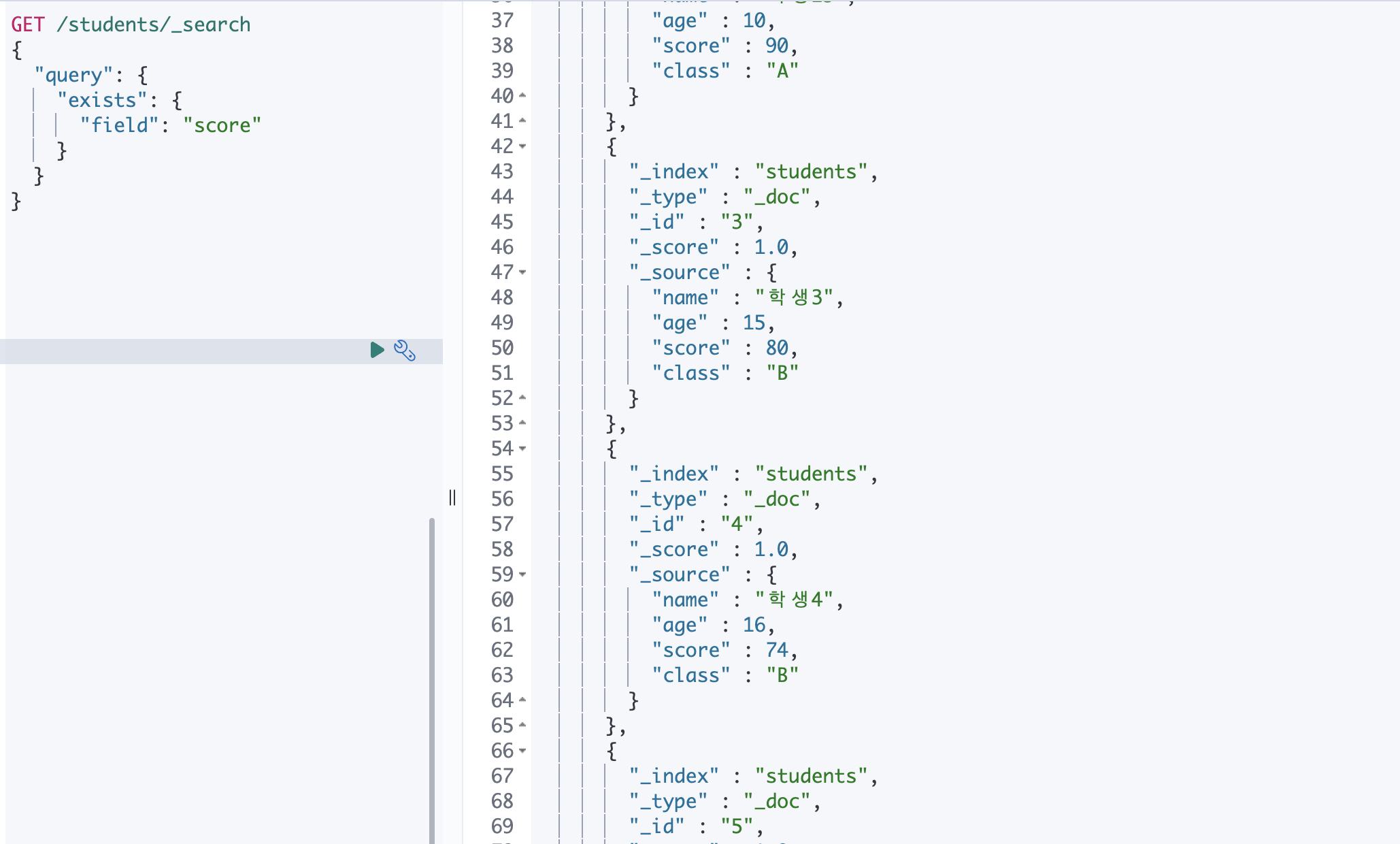
① exists
score 에 값이 있는 도큐먼트만 노출
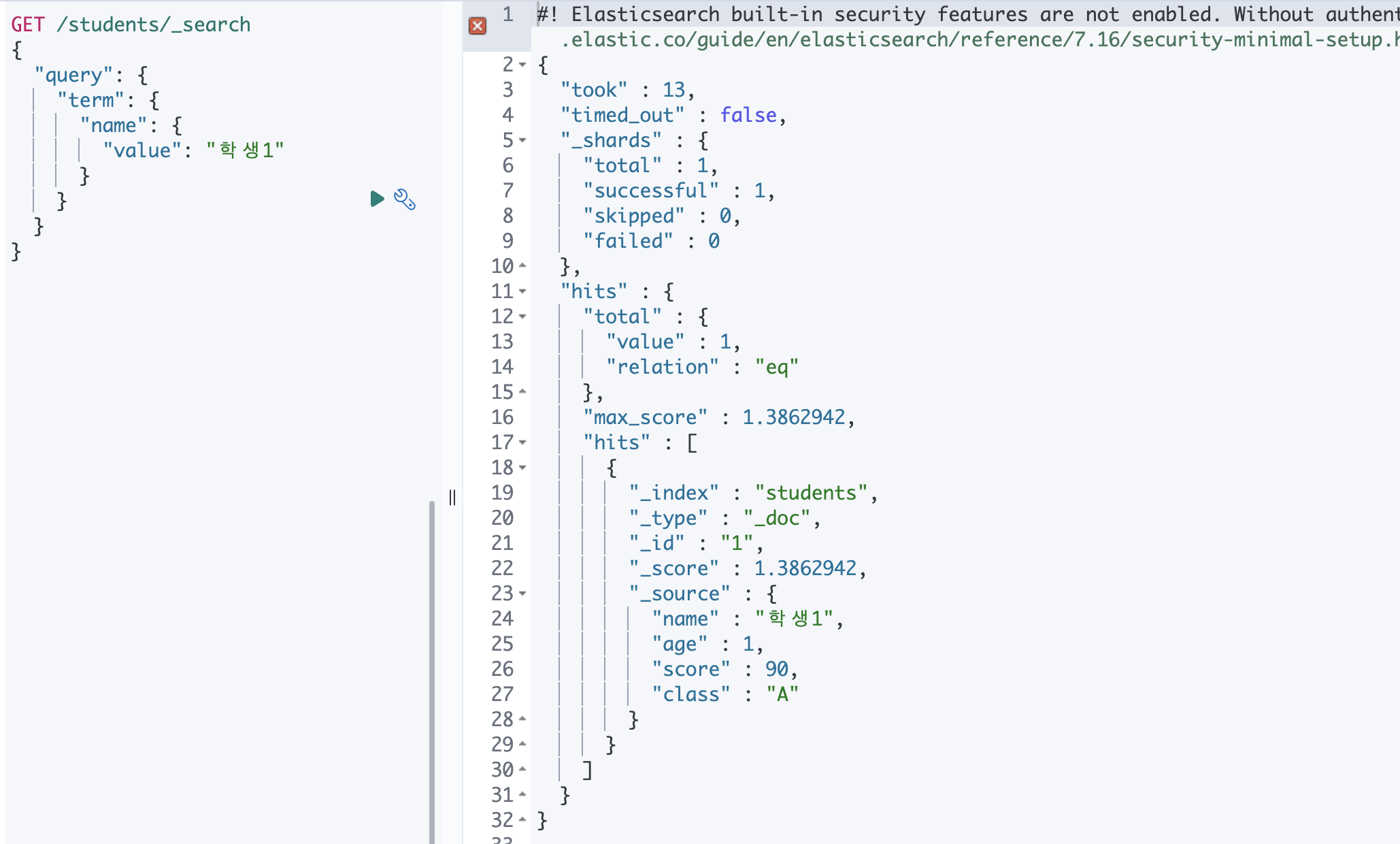
② term
별도의 분석 작업을 수행하지 않고 입력된 텍스트가 존재하는 문서를 찾음.
여기에서의 경우 학생1에 속하는 도큐먼트를 찾습니다.
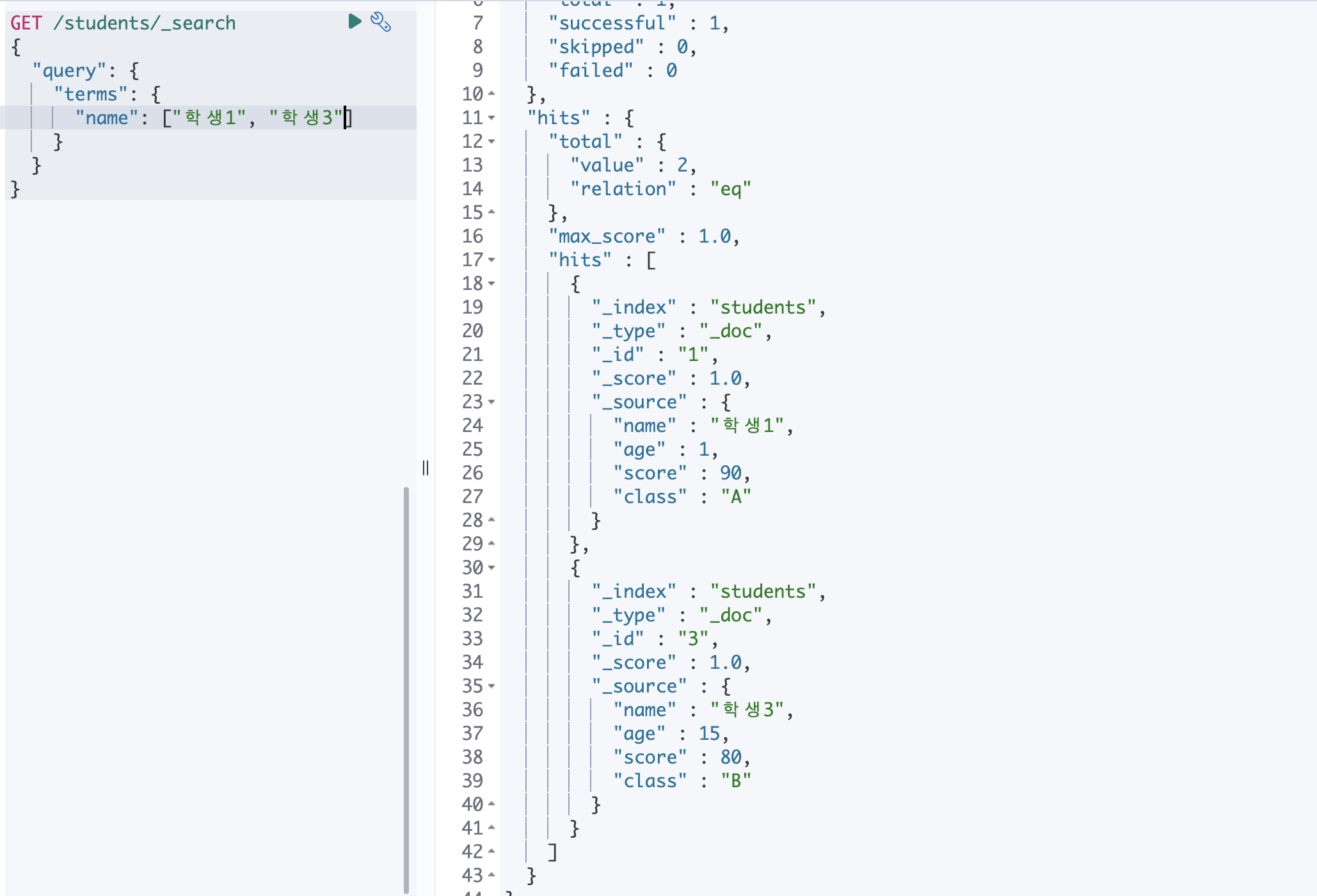
③ terms
term 과 동일하게 작동하지만, 여러개의 검색어를 한번에 찾을 수 있음.
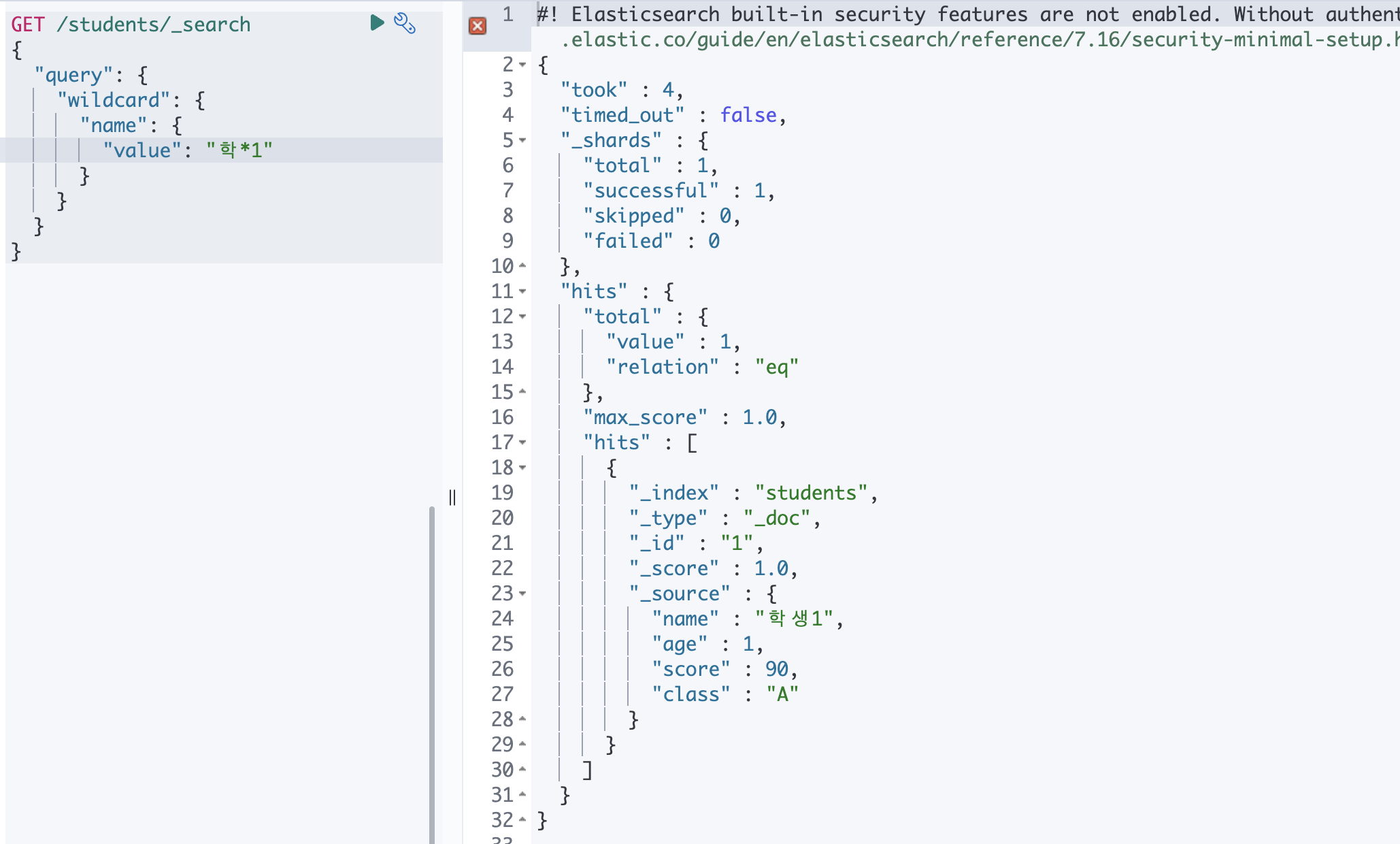
④ whildcard
검색어가 와일드카드와 일치하는 구문을 찾고, 입력된 검색어는 형태소 분석이 이루어 지지 않음
| 옵션 | 설명 |
|---|---|
| * | 문자의 길이와 상관없이 와일드카드와 일치하는 모든 문서를 찾음 |
| ? | 지정된 위치의 한 글자가 다른 경우의 문서를 찾음 |
아래에선 학....1 인 document 를 찾음