
① 역색인 구조
Elastic Search 는 데이터를 빠르게 검색하기 위해서 역색인 구조를 사용합니다.
만약 아래와 같은 데이터가 있다고 했을 떄
| ID | Text |
|---|---|
| 1 | 지금은 공부중 |
| 2 | 지금은 게임중 |
| 3 | 게임중 입니다 |
역색인을 생성하기 위해서 먼저 각 문서의 Text 를 term 으로 분할하고, term 들을 도큐먼트와 매핑시켜줍니다.
역색인 구조로 저장한 데이터는 다음과 같습니다.
| 텀(Term) | ID |
|---|---|
| 지금은 | 1,2 |
| 공부중 | 1 |
| 게임중 | 2,3 |
| 입니다 | 3 |
이렇게 저장하기 때문에 데이터를 찾을 때 매우 쉽게 찾을 수 있습니다.
EX1) 지금은 을 찾는 경우 해당 term 이 document 1, 2에 속하는 걸 쉽게 알 수 있습니다.
EX2) 만약 지금은 게임중 을 찾는다고 하면
지금은 👉 1,2
게임중 👉 2
이기 때문에 1, 2 아이디에 대한 도큐먼트가 모두 검색되지만, 2번의 score 가 더커지게 됩니다.
하지만, 역색인 구조에는 단점이 있습니다.
① 영어의 경우 대소문자를 다른 텍스트로 인지함. (Q, q 를 다른 문자로 검색)
② 복수형과 단수형이 동일하게 검색되지 않음. (fox, foxes 를 다른 문자로 검색)
③ jump, leap 는 같은 의미를 가지고 있으나 다른 텍스트로 인지함.
이러한 단점을 해소하기 위한 방법이 바로 텍스트 분석기를 사용하는 것 입니다.
② 텍스트 분석기
ES 는 문자열 필드가 저장될 때 여러 단계의 처리 과정을 거칩니다.
이 전체 과정을 텍스트 분석(Text Analysis) 이라고 하고, 이 과정을 처리하는 전체 기능을 애널라이저(Analyzer) 라고 합니다.
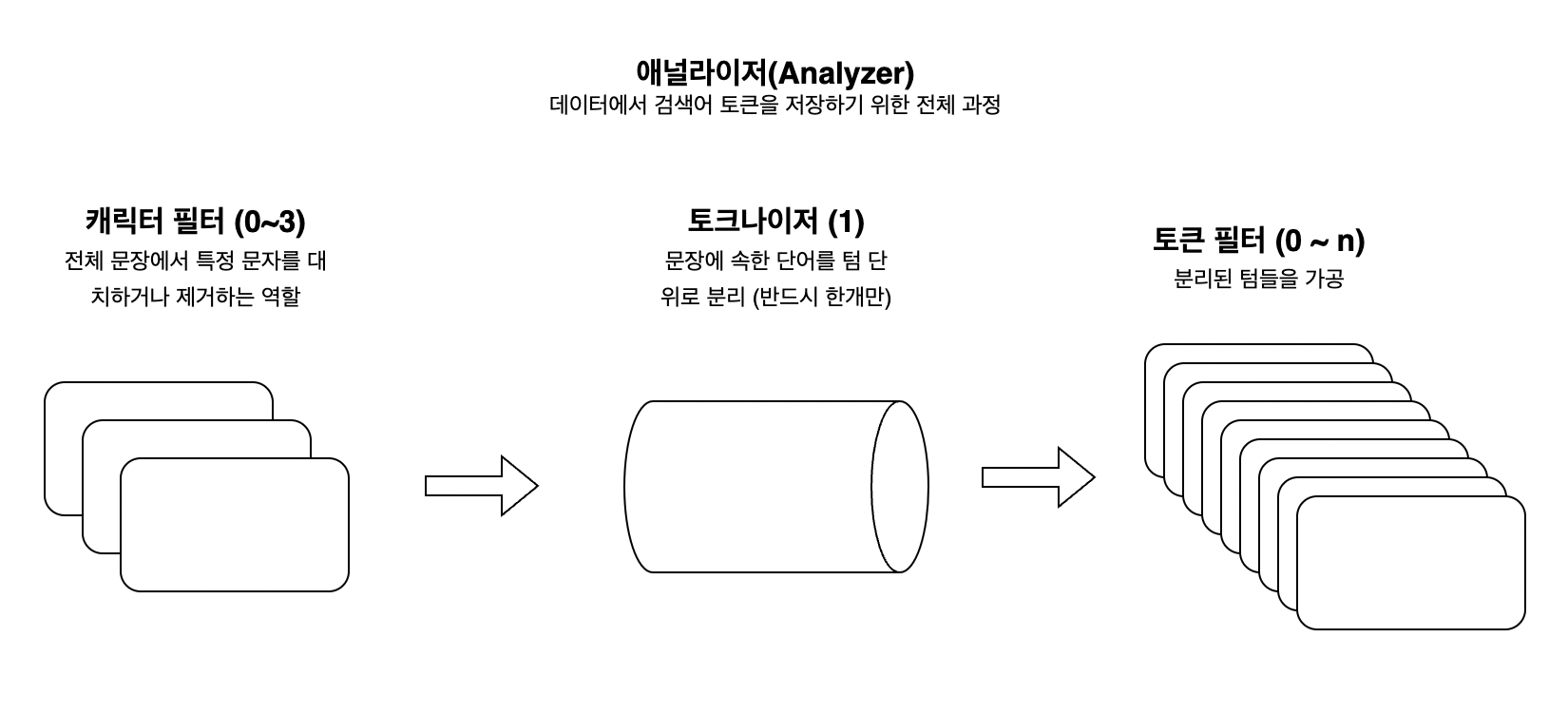
애널라이저는 0~3개의 캐릭터 필터 + 1개의 토크나이저 + 0~n개의 토큰 필터 로 이루어집니다.
③ 캐릭터 필터 (Character Filter)
캐릭터 필터는 애널라이저 중 가장 첫번째 단계이며, 텍스트가 텀으로 분리되기 전에 전처리 하는 역할을 합니다.
ES 내부적으로 총 3가지의 캐릭터 필터(HTML Strip Character Filter, Mapping Character Filter, Pattern Replace Character Filter)가 존재합니다.
HTML Strip Character Filter
이름에 나와 있듯이 HTML 태그를 제거하는 Filter 입니다.
<>로 된 태그를 제거할 뿐 아니라 같은 태그도 함께 제거합니다.
GET /_analyze
{
"tokenizer": "keyword",
"char_filter": [
"html_strip"
],
"text": "<p>I'm so <b>happy</b>!</p>"
}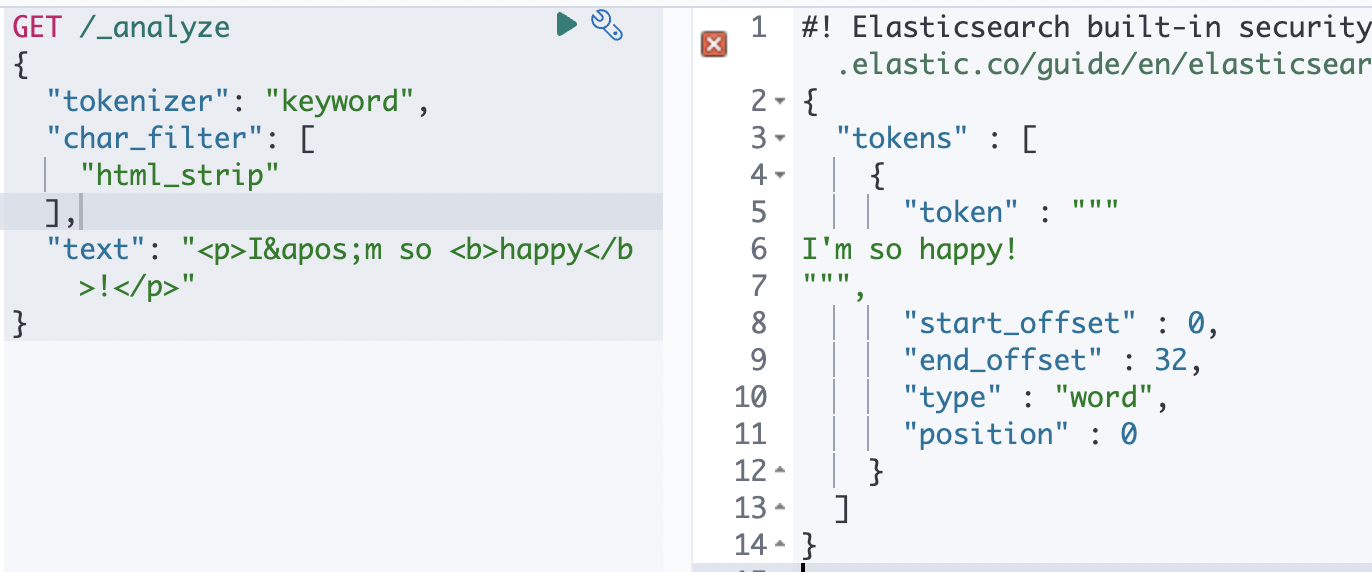
실제로 태스트해봤을 때 <p> <b> 와 같은 HTML 태그들이 사라지고, \nI'm so happy!\n 가 출력되는 것 확인할 수 있습니다.
Mapping Character Filter
지정한 단어를 다른 단어로 치환할 수 있는 Filter 입니다.
GET /_analyze
{
"tokenizer": "keyword",
"char_filter": [
{
"type": "mapping",
"mappings": [
"zero => 0",
"one => 1",
"two => 2"
]
}
],
"text": "zero one two"
}영어로된 숫자를 아라비아 숫자로 바꾸도록 필터를 세팅하면
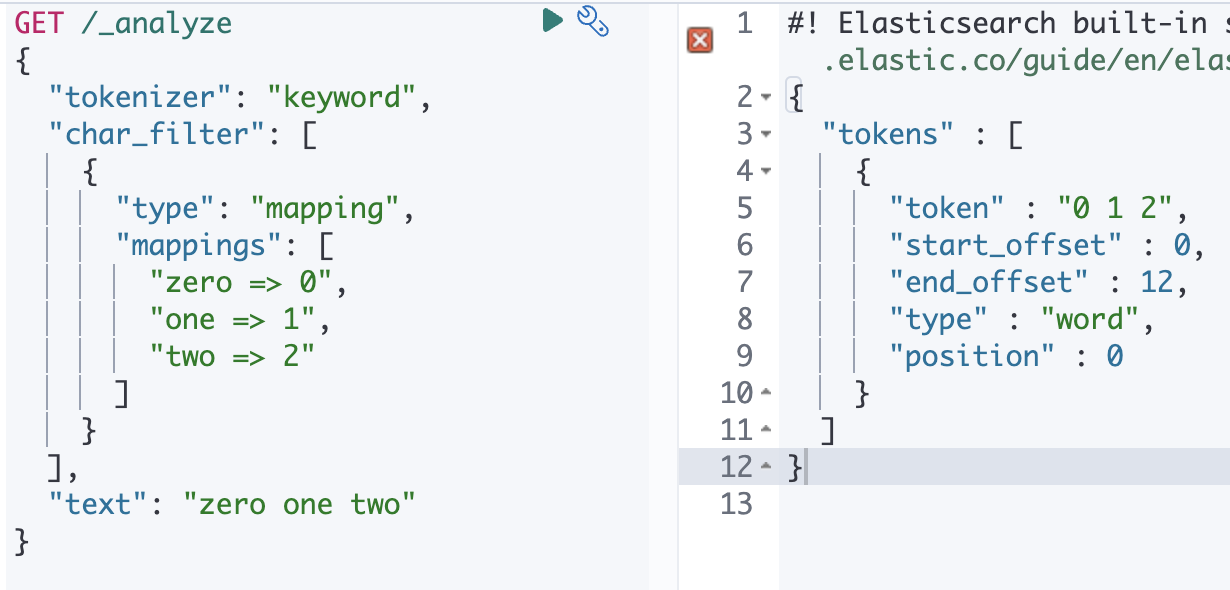
zero one two 를 넣었을 때 0 1 2 가 리턴 되는 걸 확인할 수 있습니다.
Pattern Replace Character Filter
정규식(Regular Expression)을 이용해서 좀더 복잡한 패턴들을 치환할 수 있는 필터입니다.
파라미터
| 이름 | 설명 |
|---|---|
| pattern | 자바의 정규식, required(필수) |
| replacement | 대체 문자열 |
| flags | 자바의 정규식 플래그, 파이프라인으로 구분됨 (CASE_INSENSITIVE or COMMENTS) |
GET /_analyze
{
"tokenizer": "keyword",
"char_filter": [
{
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
],
"text": "My credit card is 123-456-789"
}123-456-789 의 - 를 _ 로 변경해주는 정규식입니다.
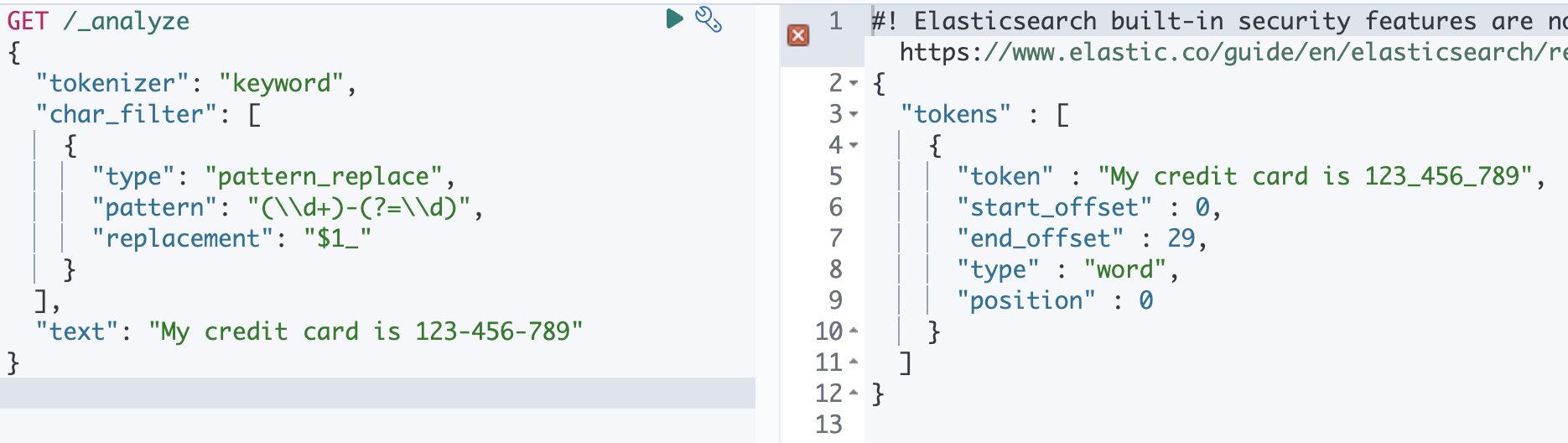
실제로 실행시켜봤을 때 123-456-789 가 123_456_789 로 변경된 걸 확인 할 수 있습니다.
④ 토크나이저 (Tokenizer)
토크나이저는 문장을 텀 단위로 분리하는 역할을 하며, 분석기를 구성하는 가장 핵심 구성요소입니다.
EX) Quick brown fox! ---- 토크나이저 ----> ["Quick", "brown", "fox!"]
하나의 애널라이저에서 반드시 하나의 토크나이저만 사용 가능하며, 중요한 구성요소이기 떄문에 엘라스틱 서치에서도 다양한 특성의 토크나이저를 제공합니다.
토크나이저는 크게 세가지로 나눌 수 있습니다.
① 단어 지향 토크나이저
➡️ 일반적으로 전체 텍스트를 개별 단어로 토큰화하는 데 사용
EX) standard, letter, lowercase 등등
② 부분 단어 토크나이저
➡️ 부분적인 단어 일치를 위해 텍스트 또는 단어를 작은 조각으로 나눔
EX) N-Gram, Edge N-Gram 등등
③ 구조화된 텍스트 토크나이저
➡️ 보통 전체 텍스트보다는 식별자, 이메일 주소, 우편번호 및 경로와 같은 구조화된 텍스트와 함께 사용
EX) Keyword, Pattern, Simple Pattern 등등
단어 지향 토크나이저
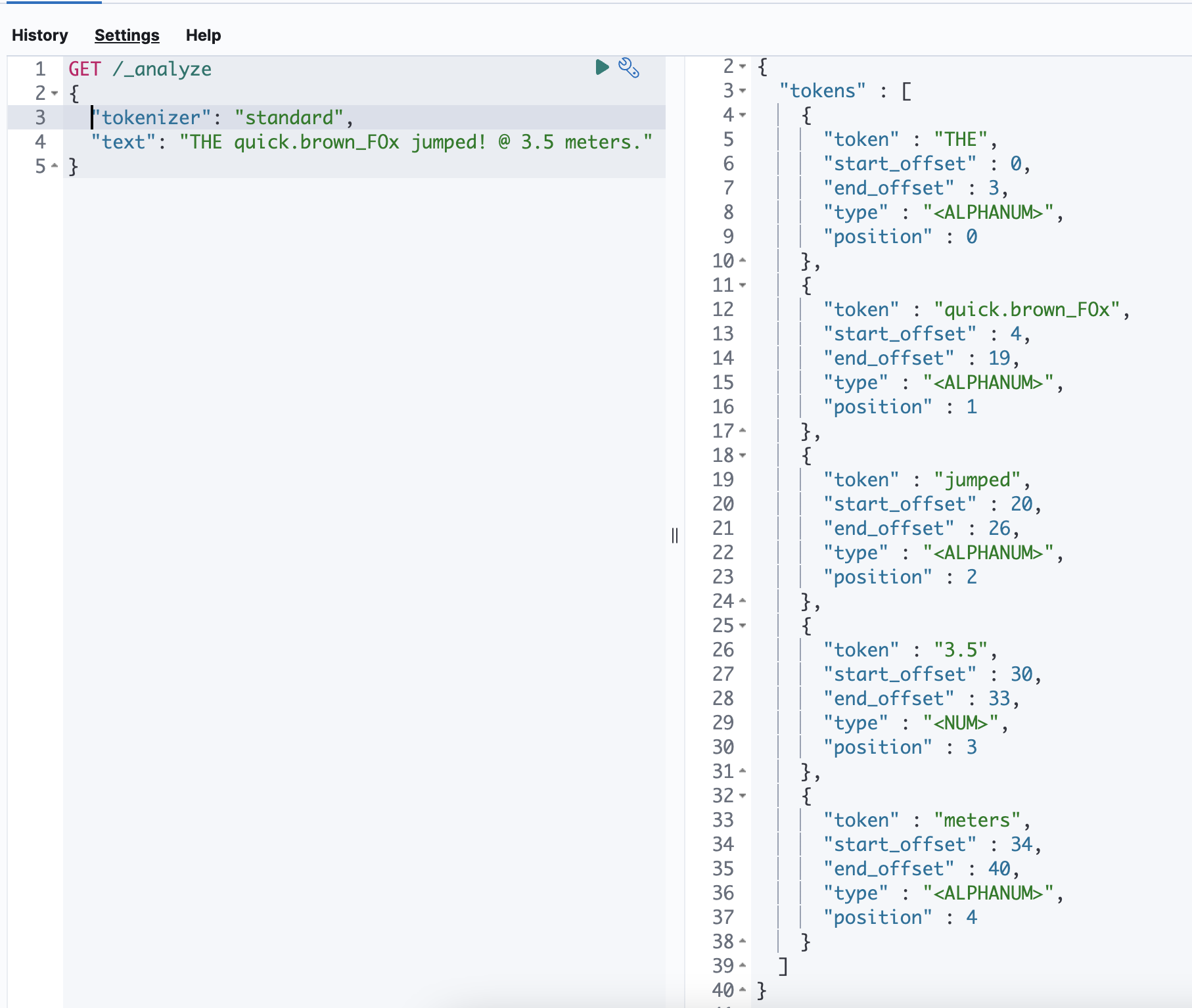
Standard Tokenizer
가장 일반적으로 사용하는 토크나이저로 대부분의 기호를 만나면 토큰으로 나눕니다.
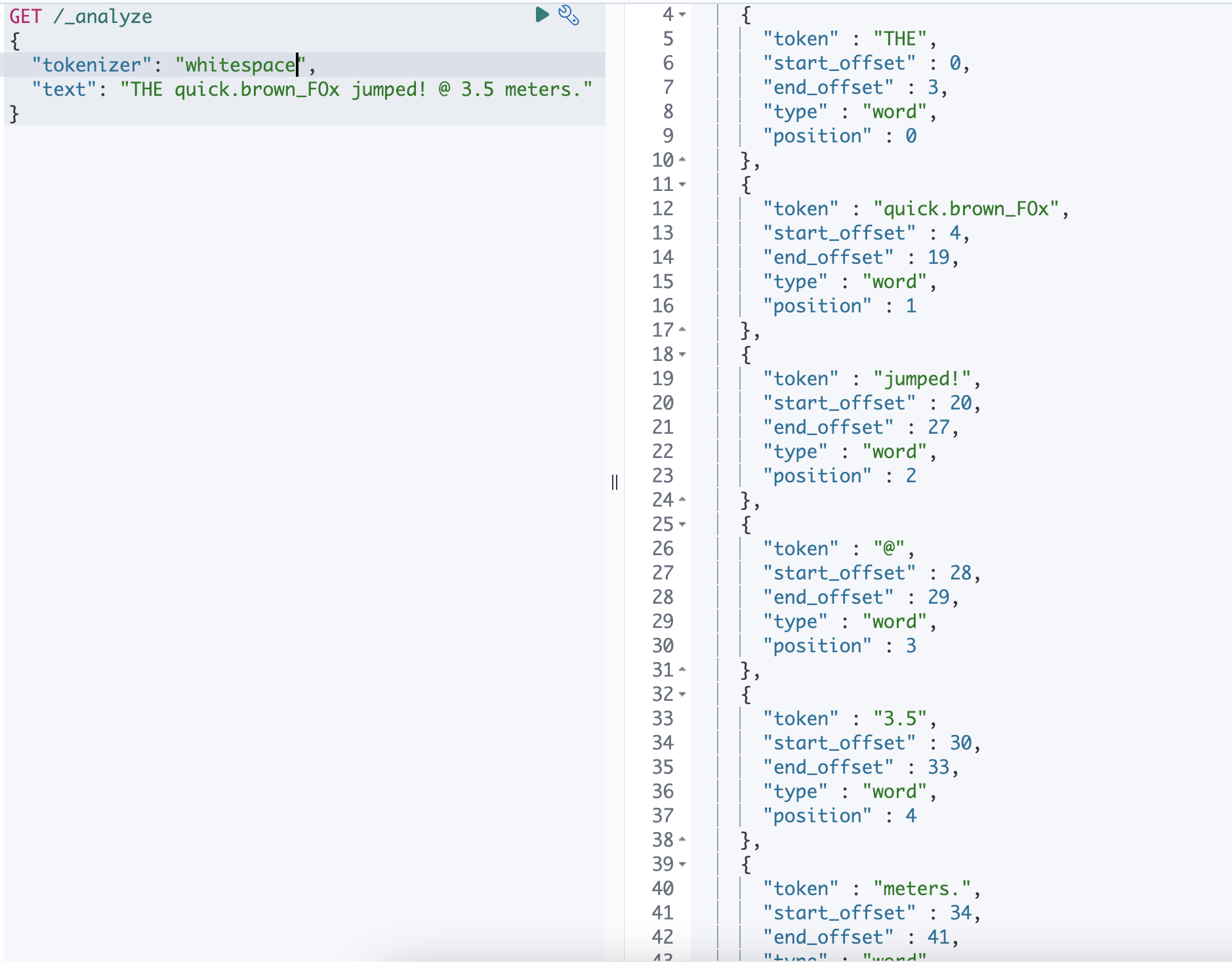
WhitSpace Tokenizer
공백을 만나면 토큰으로 나눕니다.
Letter Tokenizer
문자가 아닌 문자를 만날때마다 토큰으로 나눕니다.
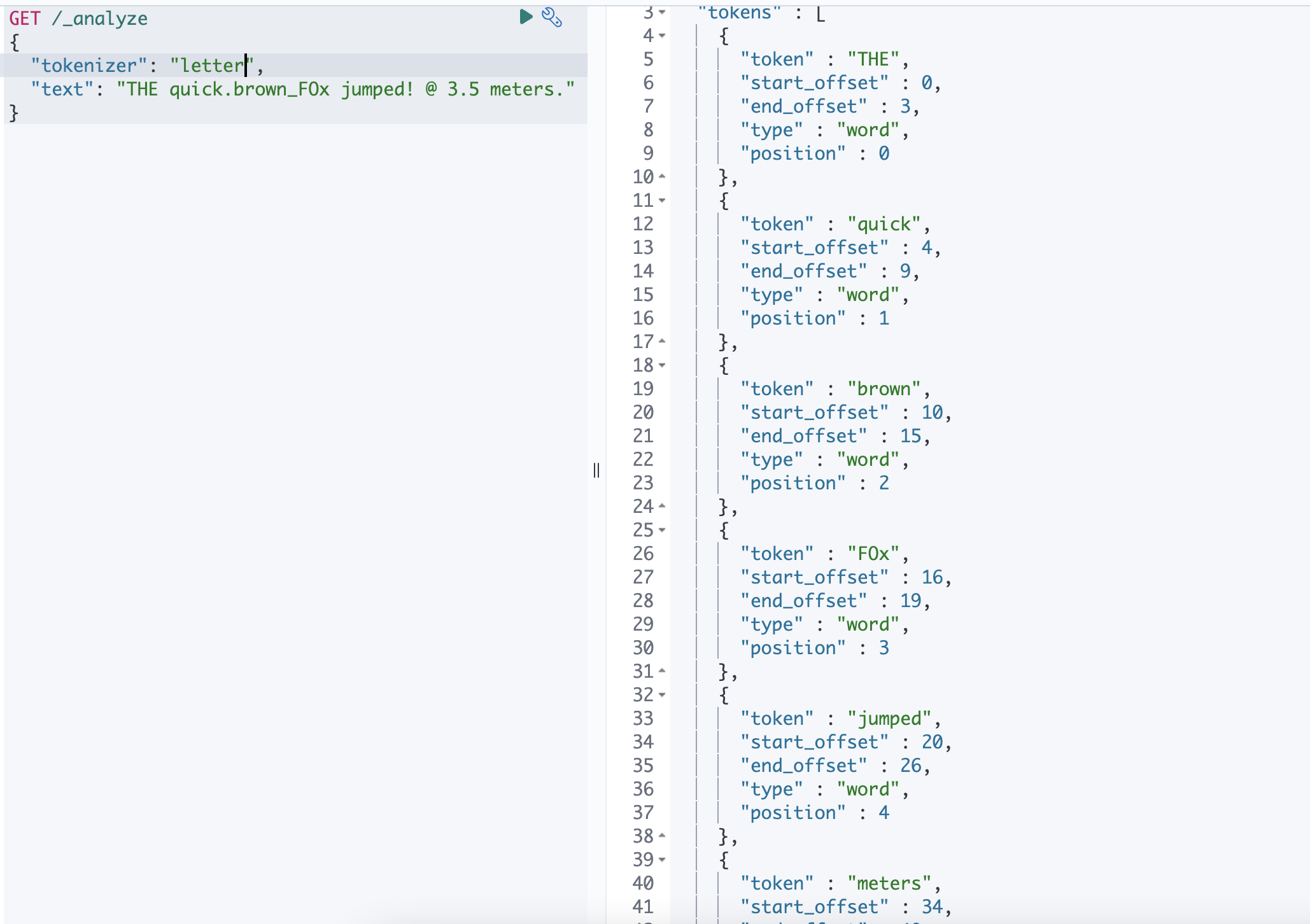
THE quick.brown_FOx jumped! @ 3.5 meters. 를 예시로 들었을 때
| 종류 | 토큰 분리 |
|---|---|
| Standard | THE / quick.brown_F0x / jumped / 3.5 / meters |
| WhiteSpace | THE / quick.brown_F0x / jumped! / @ / 3.5 / meters |
| Letter | THE / quick / brown / F0x / jumped / meters |
위의 표와 같이 토큰이 분리되게 됩니다.
Standard 토크나이저의 경우 공백으로 텀을 구분하면서 @ 와 같은 일부 특수문자를 제거하고,
Letter 토크나이저 같은경우 알파벳을 제외한 모든 공백, 숫자, 기호들을 기준으로 텀을 분리합니다.
Whitespace 토크나이저의 경우 스페이스, 탭 그리고 줄바꿈 같은 공백만을 기준으로 텀을 분리합니다.
Letter 토크나이저의 경우 검색 범위가 넓어져서 원하지 않는 결과가 많이 나올 수 있고, Whitespace 의 경우 특수문자를 거르지 않기 떄문에 정확하게 검색을 하지 않는 이상 검색 결과가 나오지 않을 수도 있기 때문에 보통은 Standard 토크나이저를 많이 사용합니다.
부분 단어 토크나이저
Ngram Tokenizer
기본적으로 한 글자씩 토큰화합니다. 다양한 옵션을 조합해서 사용할 수 있어 자동완성 시에 유용합니다.
옵션
| 파라미터 | 설명 |
|---|---|
| min_gram | Ngram 을 적용할 문자의 최소 길이를 나타냅니다. default = 1 |
| max_gram | Ngram 을 적용할 문자의 최대 길이를 나타냅니다. default = 2 |
| token_chars | 토큰에 포함할 문자열을 지정합니다. letter(문자) / digit(숫자) / whitespace(공백) / punctuation(구두점) / symbol(특수기호) |
GET /_analyze
{
"tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 2
},
"text": "안녕하세요"
}안 / 안녕 / 녕 / 녕하 / 하 / 하세 / 세 / 세요 / 요
Edge Ngram Tokenizer
지정된 문자의 목록 중 하나를 만날 떄마다 시작 부분을 고정시켜 단어를 자르는 방식으로 사용하는 토크나이저
Ngram 같은 경우 시작하는 문자가 정해져 있지 않지만, Edge Ngram 같은 경우에는 시작 부분을 고정시킬 수 있습니다.
옵션 은 Ngram Tokenizer 과 동일
GET /_analyze
{
"tokenizer": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 2,
"token_chars": ["letter"]
},
"text": "안녕하세요 저는"
}안 / 안녕 / 저 / 저는
구조화된 텍스트 토크나이저
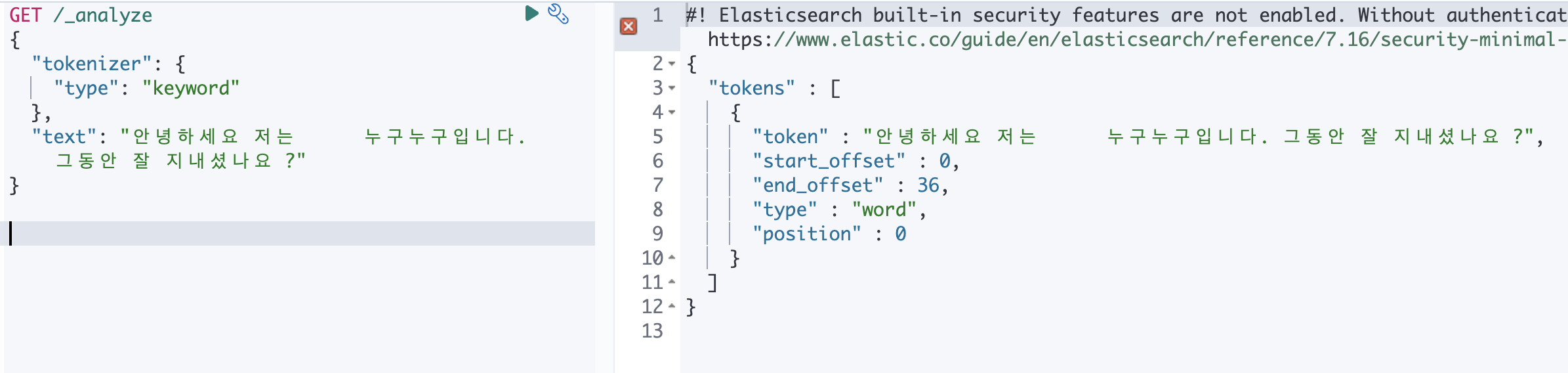
Keyword
전체 텍스트를 하나의 토큰으로 만듭니다.
여러 토큰으로 나누지 않고, 단일 용어와 정확히 동일한 텍스트를 출력합니다.
토큰 필터와 결합하여 출력을 정규화할 수 있습니다.
GET /_analyze
{
"tokenizer": {
"type": "keyword"
},
"text": "안녕하세요 저는 누구누구입니다. 그동안 잘 지내셨나요 ?"
}
Pattern
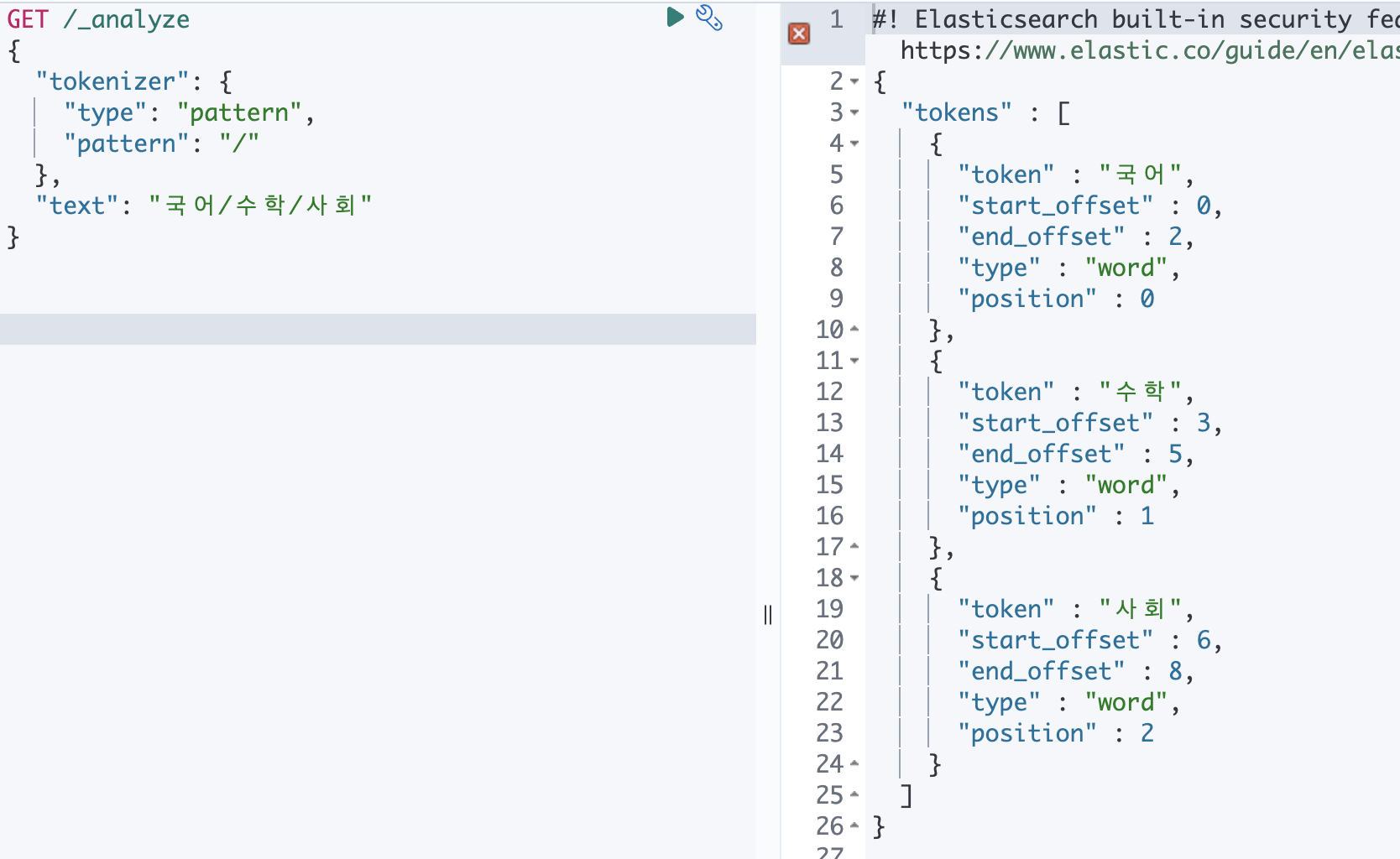
정규식을 사용하여 단어 구분 기호와 일치할 때마다 텍스트를 용어로 분할하거나 일치하는 텍스트를 용어로 캡처합니다.
GET /_analyze
{
"tokenizer": {
"type": "pattern",
"pattern": "/"
},
"text": "국어/수학/사회"
}
⑤ 토큰 필터 (Token Filter)
토크나이저에서 분리된 토큰들을 변형하거나 추가, 삭제할 때 사용하는 필터입니다.
토크나이저에서 토큰이 분리되어야 동작하기 때문에 독립적으로는 사용할 수 없습니다.
Lowercase Token Filter
텀들을 소문자로 변환해서 저장하는 필터입니다.
GET /_analyze
{
"filter": ["lowercase"],
"text": "Hi My name is soyeon."
}hi my name is soyeon.
Uppercase Token Filter
GET /_analyze
{
"filter": ["uppercase"],
"text": "Hi My name is soyeon."
}HI MY NAME IS SOYEON.
Stop Token Filter
불용어로 등록할 사전을 구축해서 사용하는 필터입니다.
인덱스로 만들고 싶지 않거나 검색되지 않게 하고 싶은 단어를 등록해서 불용어 사전을 구축합니다.
옵션
| 파라미터 | 설명 |
|---|---|
| stopwords | 불용어를 매핑에 직접 등록해서 사용 |
| stopwords_path | 불용어 사전이 존재하는 경로를 지정 |
| ignore_case | true로 지정할 경우 모든 단어를 소문자로 변경해서 저장 |
GET /_analyze
{
"tokenizer": "standard",
"filter": {
"type": "stop",
"stopwords": [ "and", "is", "the" ]
},
"text": "Hi My name is soyeon."
}Hi / My / name / soyeon
Synonym Token Filter
동의어를 처리할 수 있는 필터입니다.
용어
| 파라미터 | 설명 |
|---|---|
| synonyms | 동의어로 사용할 단어를 등록 |
| synonyms_path | 파일로 관리할 경우 ES 서버의 config 폴더아래에 생성 |
GET /_analyze
{
"tokenizer": "standard",
"filter": {
"type": "synonym",
"synonyms": [ "soyeon => test" ]
},
"text": "Hi My name is soyeon."
}Hi / My / name / is / test
Trim Token Filter
앞뒤 공백을 제거하는 토큰 필터입니다.
GET /_analyze
{
"tokenizer": "standard",
"filter": ["trim"],
"text": " test "
}test
⑥ 애널라이저 (Analyzer)
_analyze API
ES 는 문장을 _analyzer API 를 통해 어떻게 텀으로 분리될 지 미리 확인해볼 수 있습니다.
다음과 같은 형식으로 사용하면 됩니다.
GET _analyze
{
"text": #{분석하고자 하는 문장},
"tokenizer": #{토크나이저},
"filter": [
#{토큰 필터}
],
"char_filter": #{캐릭터 필터}
}테스트를 위해서 test_index 를 만들고, 해당 애널라이저를 snowball 로 설정하겠습니다.
❓ snowball 애널라이저란 ?
토크나이저 = whitespace
토큰 필터 = lowercase, stop, snowball 을 조합한 것
PUT test_index
{
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "snowball"
}
}
}
}test_index 에다가 id = 1 로 message가 The quick brown fox jumps over the lazy dog 인 도큐먼트를 넣어줍니다.
PUT test_index/_doc/1
{
"message": "The quick brown fox jumps over the lazy dog"
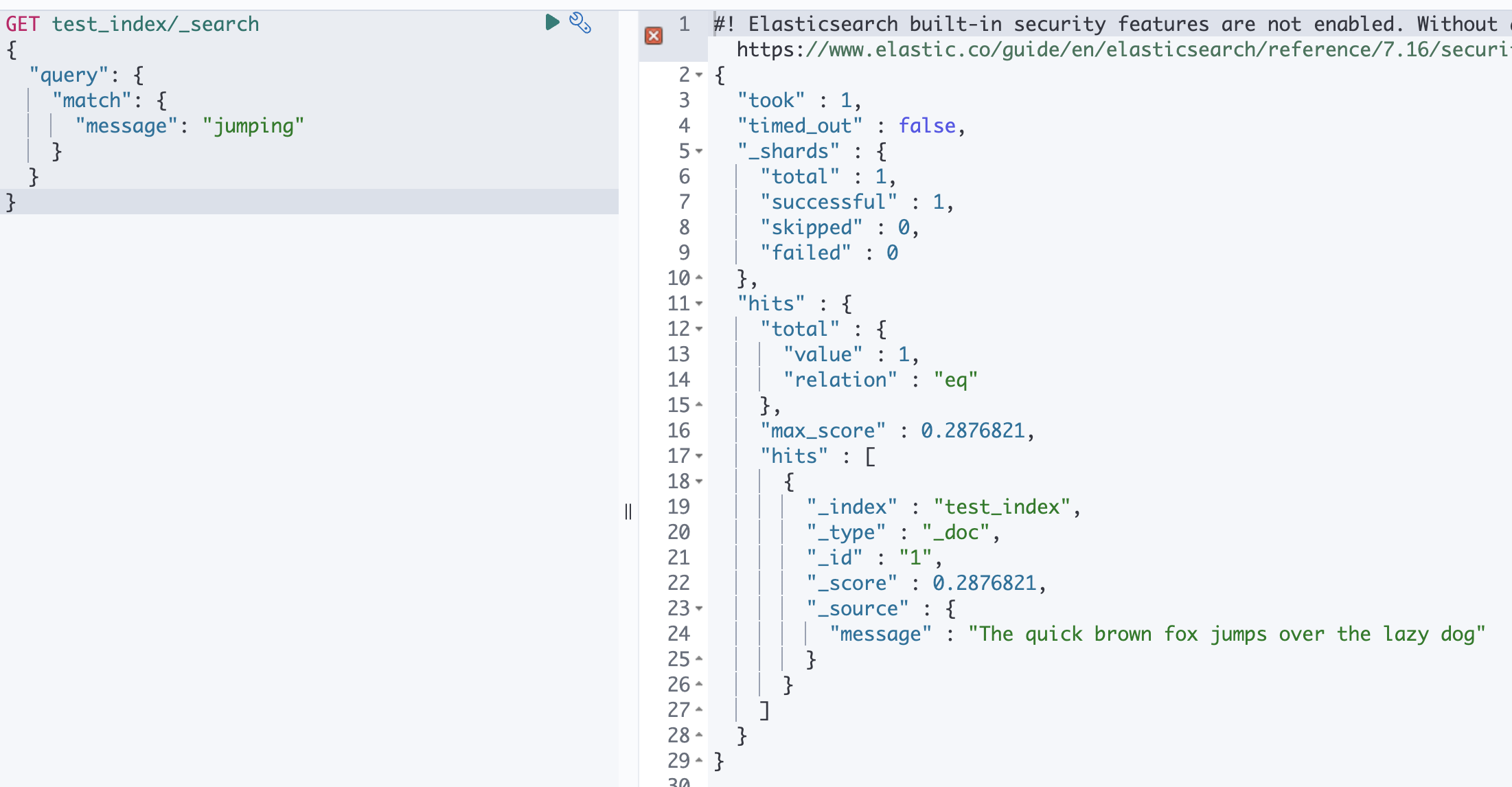
}그리고 jumps 를 조회해보도록 하겠습니다.
이때 jumping 이나 jumps 나 jump 로 검색해도 정상적으로 해당 도큐먼트가 검색되는 걸 알 수 있습니다.
GET test_index/_search
{
"query": {
"match": {
"message": "jumping"
}
}
}
그렇다면 실제 문자열은 jumps 인데 jump, jumping 의 경우에도 검색이 되는 걸까요 ???
바로
바로
바로
검색어가 애널라이저를 거쳐서 실제 검색시에는 jump 로 검색하기 때문입니다.
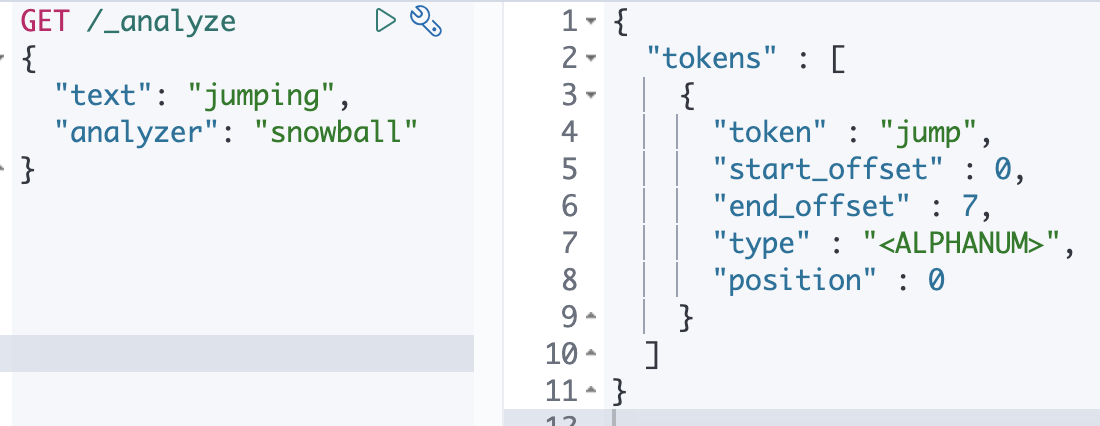
실제로 jumping 이라는 text 를 snowball 애널라이저로 검색했을 때 jump 라는 결과가 노출 되는 걸 확인할 수 있습니다.
🚨 여기서 주의해야할 점 이 있는데요.
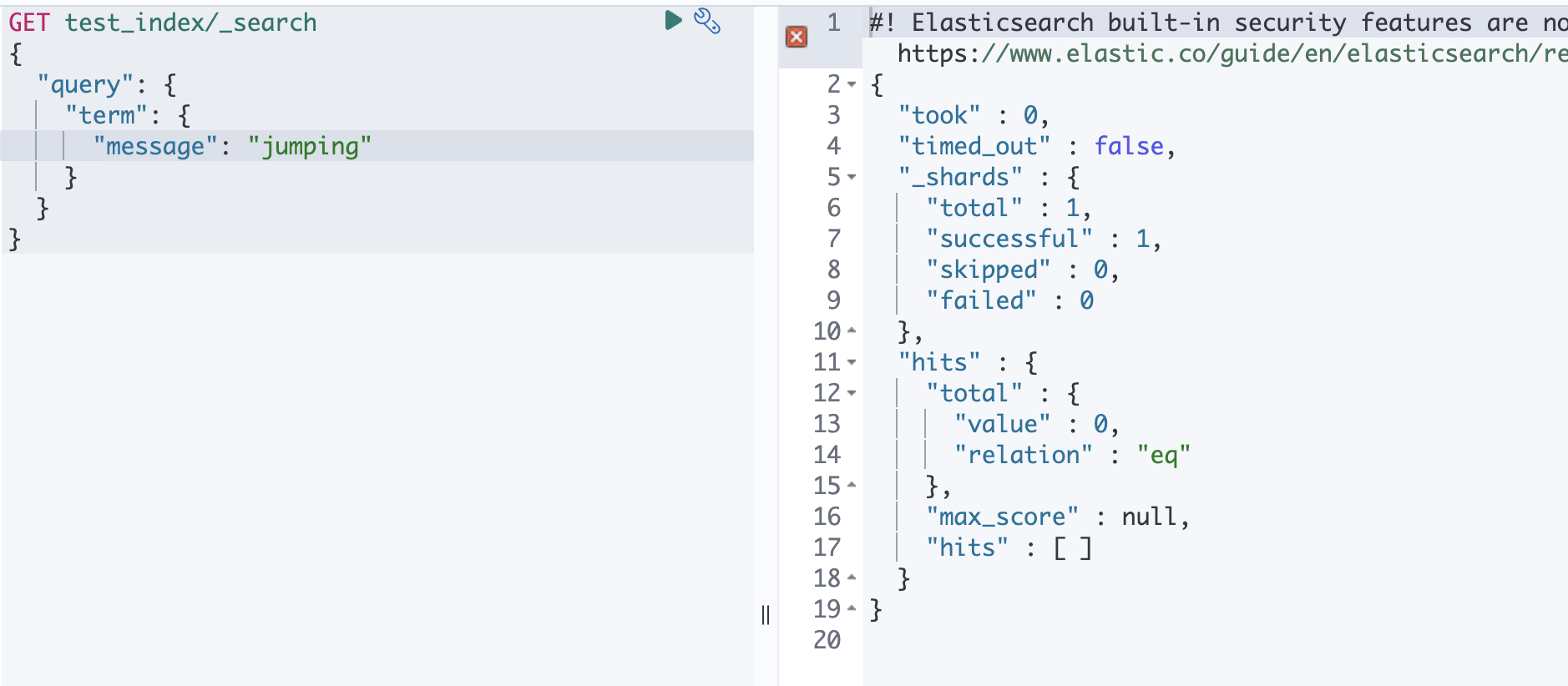
term 쿼리 같은 경우는 검색시에 애널라이저를 사용하지 않기 때문에 jumping, jump 로 검색했을 때에는 결과가 나오지 않고, 원본 텍스트와 동일하게 jumps 라고 검색했을 때에만 결과가 노출됩니다.
‼️ 텍스트 분석(Analysis) 과정은 검색에 사용되는 역 인덱스에만 관여합니다. 원본 데이터는 변하지 않으므로 쿼리 결과의 _source 항목에는 항상 원본 데이터가 나옵니다.
사용자 정의 애널라이저
실제로 인덱스에 저장되는 데이터의 처리에 대한 설정은 애널라이저만 적용할 수 있습니다.
매핑에 아무 설정을 하지 않는 경우 디폴트로 적용되는 애널라이저는 standard 애널라이저 입니다.
만일 사용자가 만든 인덱스에 애널라이저를 설정하고 싶은 경우 인덱스를 만들 때 설정해주면 됩니다.
test_index2 에 애널라이저 설정
PUT test_index2
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"my_stop_filter"
]
}
},
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": ["brown"]
}
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "my_custom_analyzer"
}
}
}
}mappings 를 통해 애널라이저를 설정해주거나, querydsl 사용시 analyzer 를 명시해줘도 됩니다.
GET test_index2/_analyze
{
"analyzer": "my_custom_analyzer",
"text": [
"The quick brown fox jumps over the lazy dog"
]
}텀 벡터 API
색인된 도큐먼트의 역 인덱스 내용을 확인할려면 텀 벡터 API 를 사용하면 됩니다.
사용법은 다음과 같습니다.
GET <인덱스>/_termvectors/<도큐먼트id>?fields=<필드명>🙇🏻♀️ 레퍼런스
6. 데이터 색인과 텍스트 분석
Mapping and Analysis
엘라스틱 서치 실무 가이드
