Aggregations (집계)
ES 는 집계를 세가지로 나눕니다.
① 메트릭 집계
: 필드 값에서 합계 또는 평균과 같은 메트릭을 계산하는 집계
: EX) min, max, sum, avg, stats, cardinality 등등
② 버킷 집계
: 필드 값, 범위 또는 기타 기준에 따라 문서를 버킷(빈이라고도 함)으로 그룹화 하는 집계
: EX) range, histogram, date_range, date_histogram, terms 등등
③ 파이프라인 집계
: 문서 또는 필드 대신 다른 집합에서 입력을 가져오는 집계
: EX) min_bucket, max_bucket, avg_bucket, sum_bucket, stas_bucket 등등
ES 에서 사용하기
_search API 의 매개변수를 지정하여 _search 의 일부로 집계를 실행할 수 있습니다.
사용하는 형식은 다음과 같습니다.
GET <인덱스명>/_search
{
"aggs": {
"<aggregation 이름 >": {
"<aggregation 종류>": {
… <aggreagation 구문> …
}
}
}
}EX)
GET /students/_search
{
"aggs": {
"test_agg": {
"terms": {
"field": "class"
}
}
}
}🌟 참고사항
아래에서 진행되는 실습은 아래 인덱스 및 도큐먼트를 바탕으로 진행합니다.
인덱스명 : students
도큐먼트 ⬇️
| 이름 | 나이 | 점수 | 반 |
|---|---|---|---|
| 학생1 | 1 | 90 | A |
| 학생23 | 10 | 90 | A |
| 학생3 | 15 | 80 | B |
| 학생4 | 16 | 74 | B |
| 학생43 | 17 | 50 | A |
인덱스 생성 및 도큐먼트 추가 쿼리는 [ES] 5. 데이터 검색하기 포스팅을 확인해주세요.
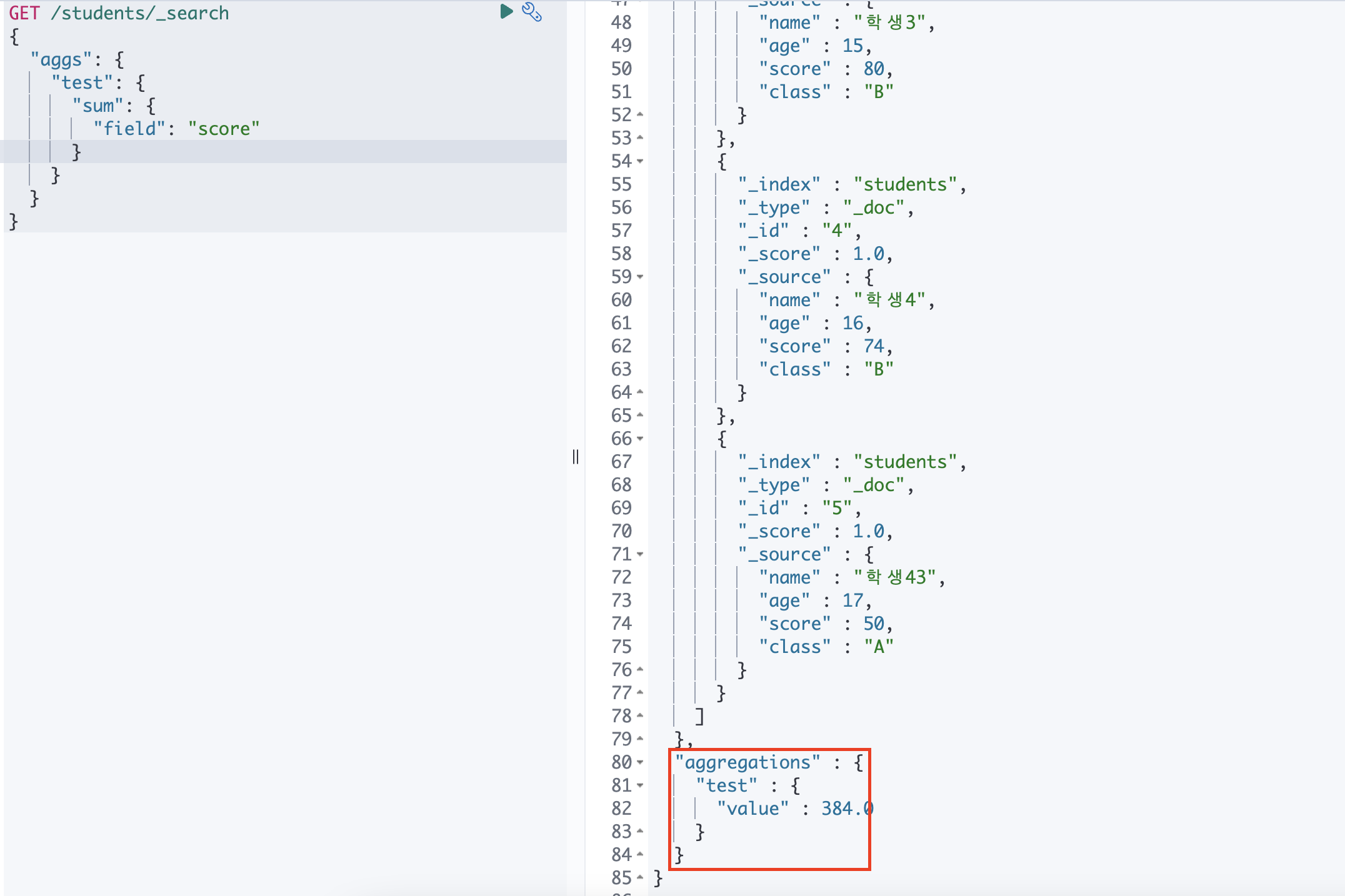
메트릭 집계 (Metrics)
필드 값에서 합계 또는 평균과 같은 메트릭을 계산하는 집계
min, max, sum, avg
최소, 최대, 합, 평균 값을 가져오는 aggregation
가장 흔하게 사용되는 metrics aggregation 입니다.
EX) 학생들의 점수를 모두 합한 결과를 얻고 싶은 경우
sum 대신 min, max, avg 를 사용하면 해당하는 데이터가 노출됩니다 🙃
🍯 aggregation 결과만 보고 싶을 때
기본적으로 집계를 포함하는 검색은 aggregation 및 검색 결과를 모두 반환합니다. aggregation 결과만 보고 싶을 때에는"size": 0을 추가해주면 됩니다.GET /students/_search { "size": 0, "aggs": ... }
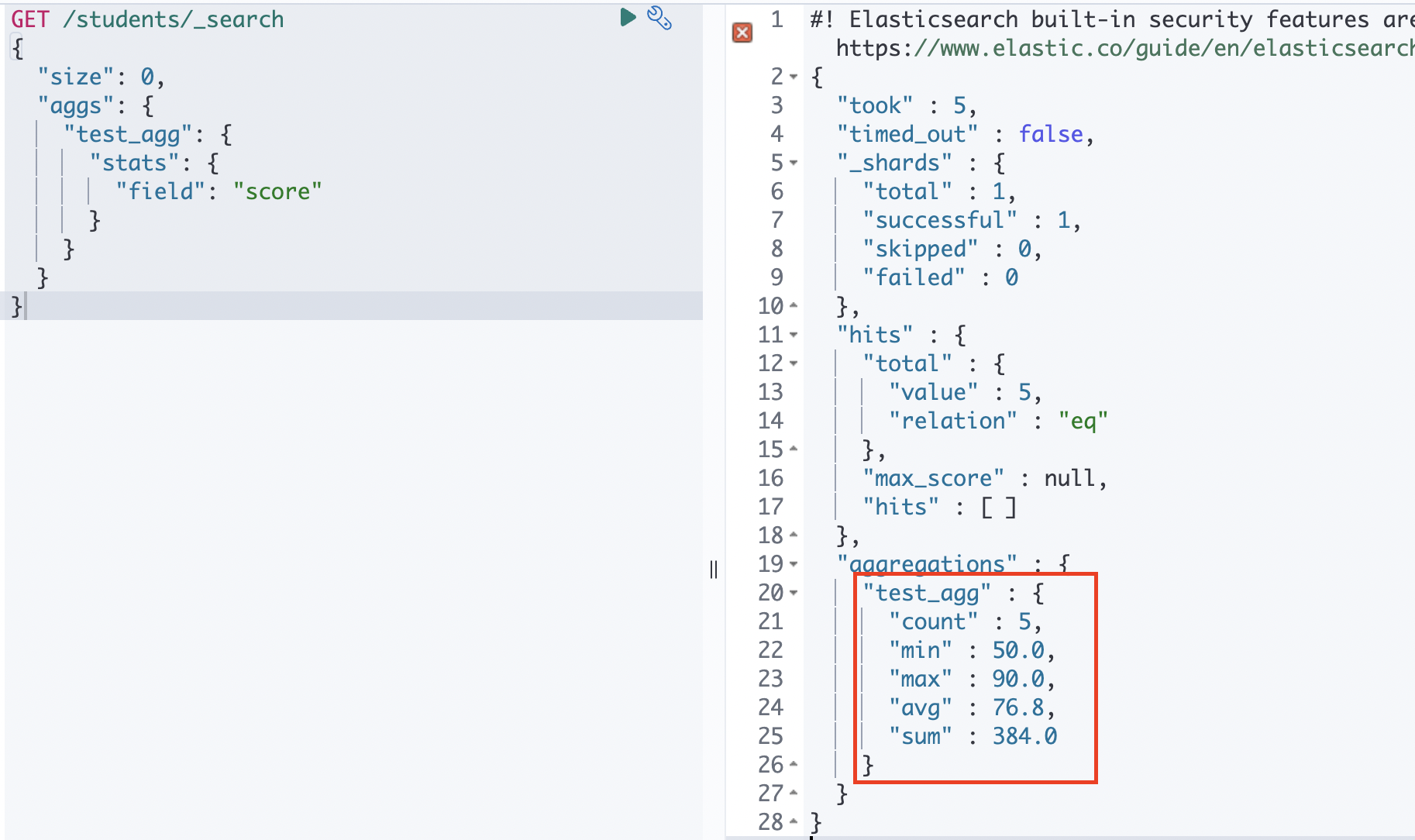
stats
min, max, sum, avg 값을 모두 한번에 가져와야하는 경우 사용되는 aggregation
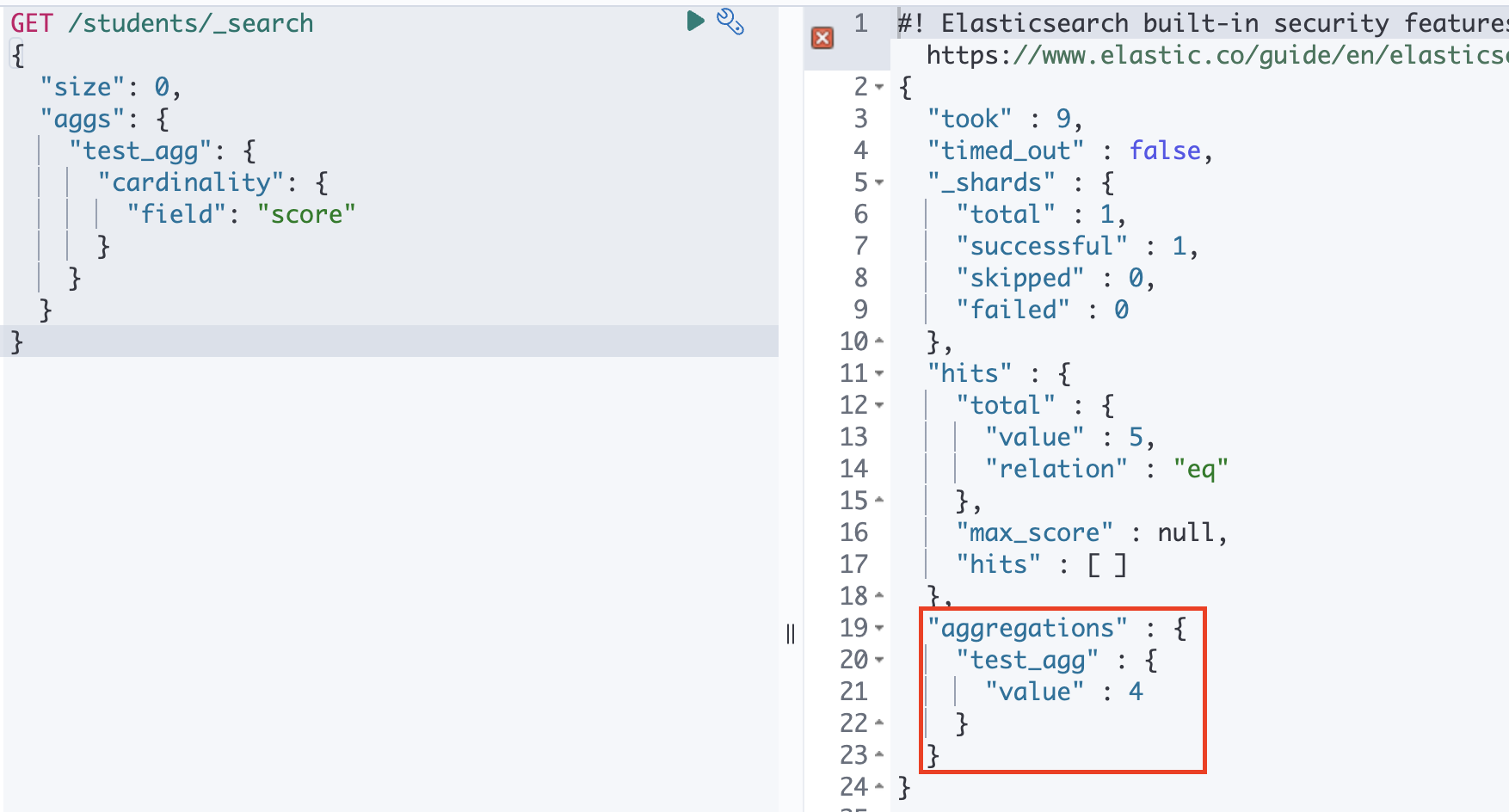
cardinality
개수를 리턴하는 aggregation
text 필드에서는 사용할 수 없으며 숫자 필드나 keyword, ip 필드 등에만 사용 가능 합니다.
주로, 사용자 접속 로그에서 IP 주소 필드를 가지고 실제로 접속한 사용자가 몇명인지 파악하는 등의 용도로 주로 사용 합니다.
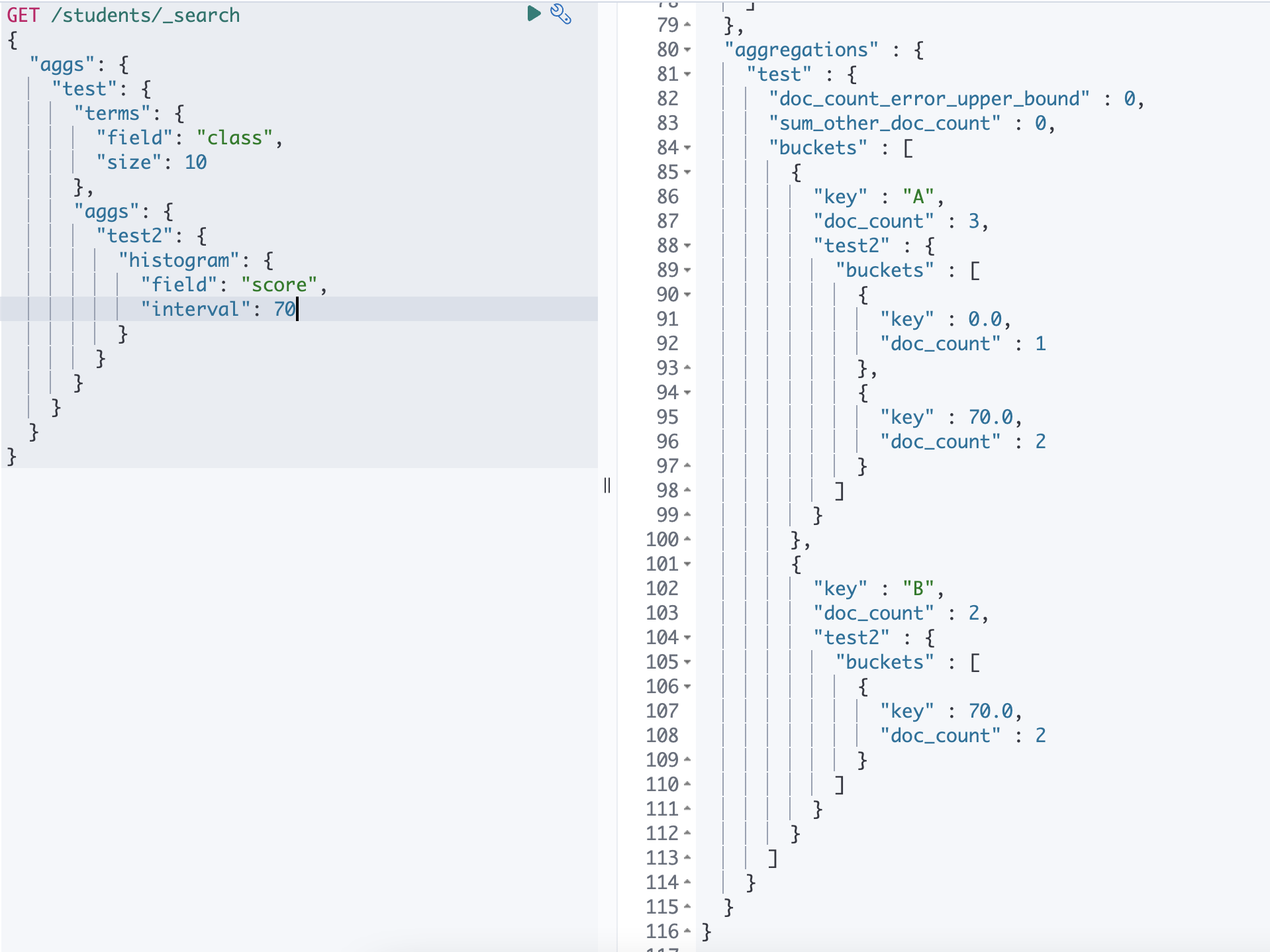
버킷 집계 (Bucket)
주어진 조건으로 분류된 버킷 들을 만들고, 각 버킷에 소속된 도큐먼트들을 모아 그룹으로 구분합니다.
각 버킷 별로 포함되는 도큐먼트의 개수를 doc_count 값에 기본적으로 표시 되며 각 버킷 안에 metrics aggregation 을 이용해서 다른 계산도 가능합니다.
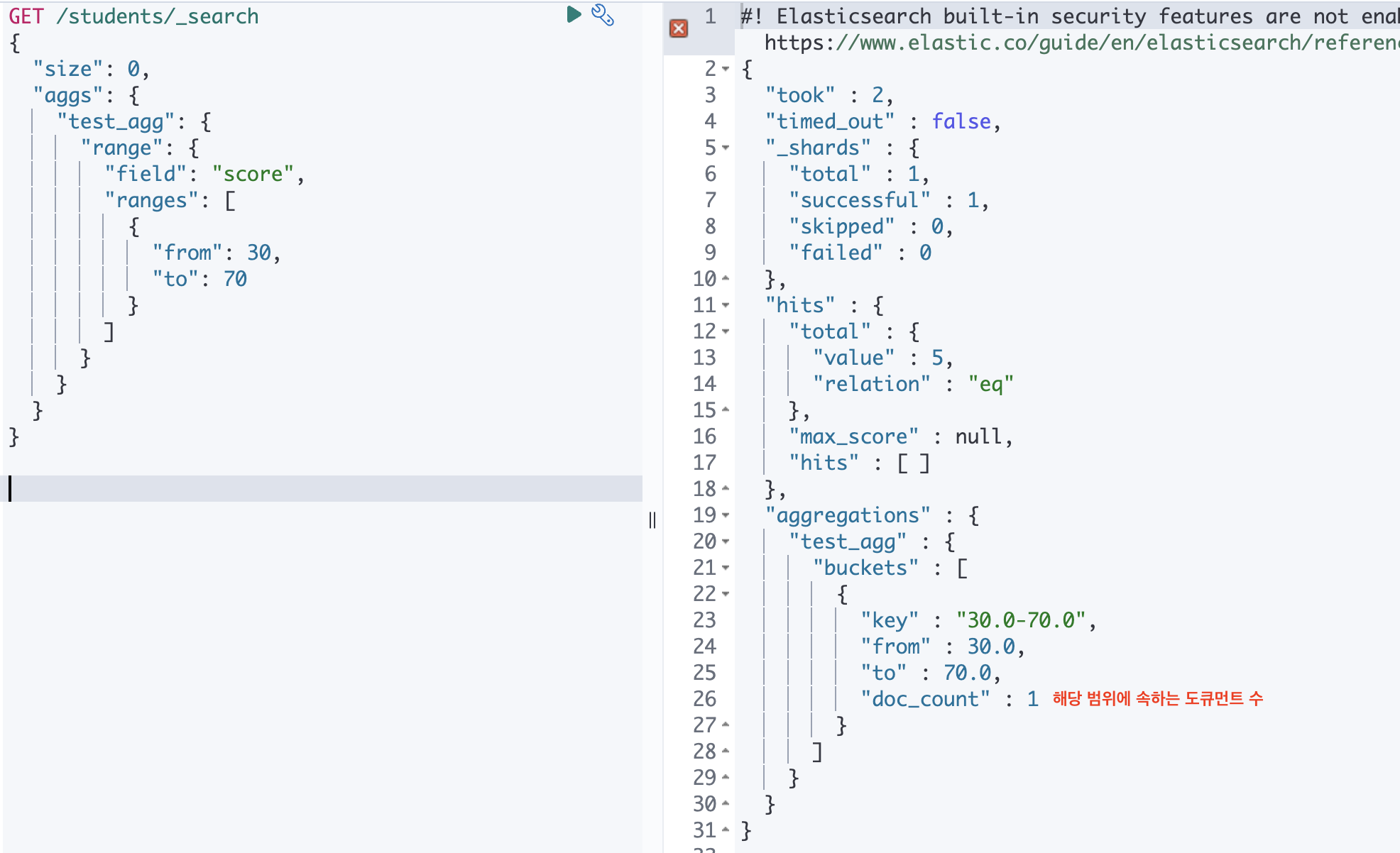
range
숫자 필드 값으로 범위를 지정하고 각 범위에 해당하는 버킷을 만드는 aggregation
histogram
range 와 동일하게 숫자 필드의 범위를 나누는 aggregation 입니다.
range 의 경우에는 from 과 to 를 이용해서 각 버킷의 범위를 지정하지만, histogram 은 interval 옵션을 이용해서 주어진 간격 크기대로 버킷을 구분합니다.

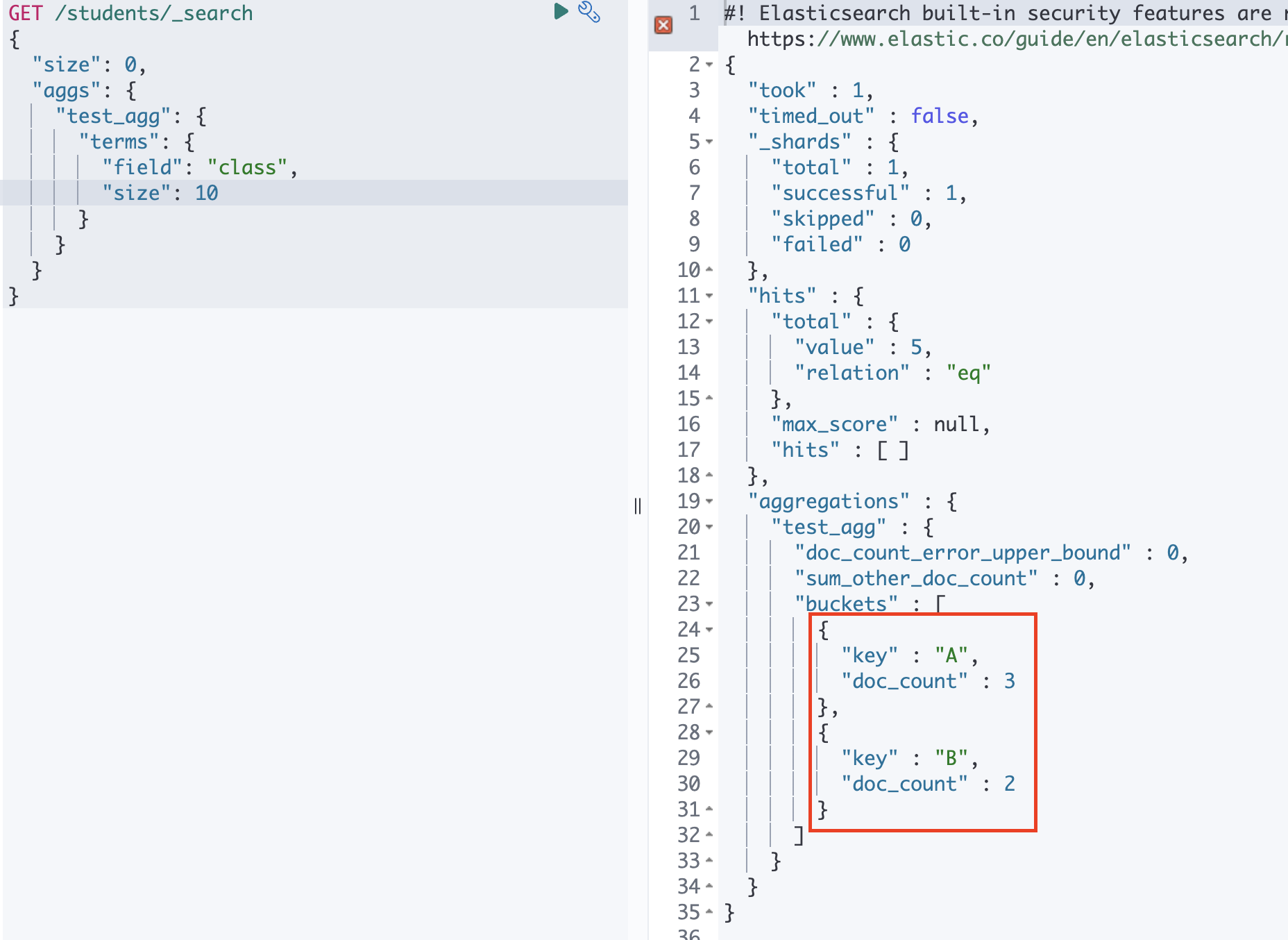
terms
keyword 필드의 문자열 별로 버킷을 나누는 aggregation 입니다.
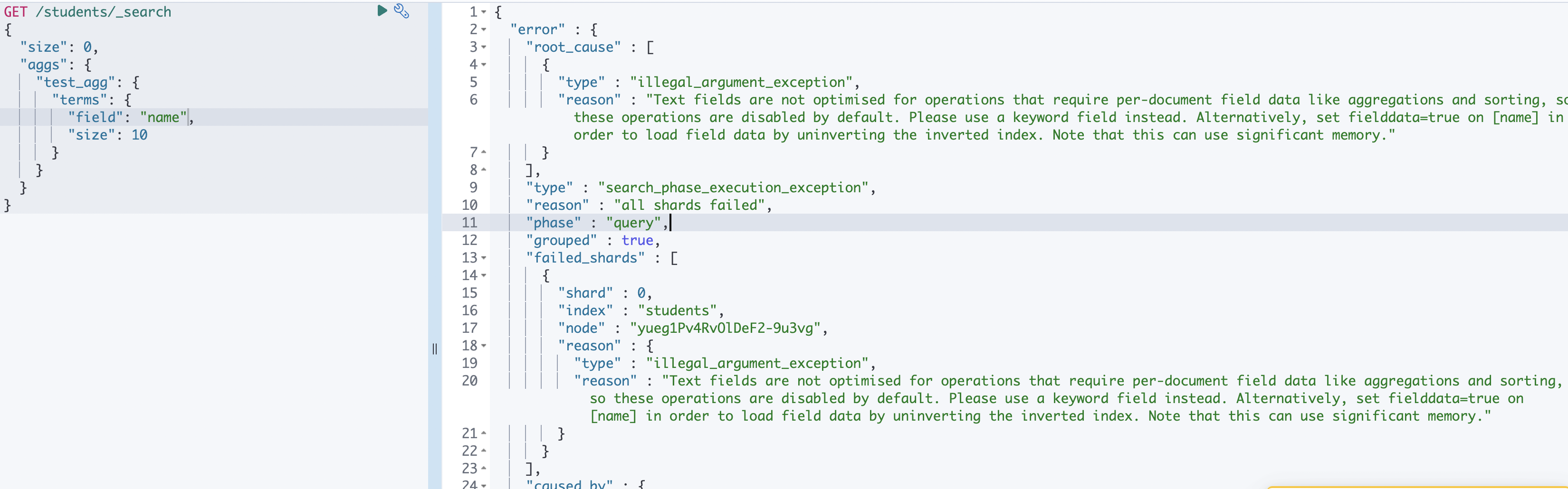
🚨 text 필드로 terms aggregation 을 사용하려고 하는 경우
아래와 같은 오류가 발생합니다.
reason 을 해석해보자면 ⬇️
텍스트 필드는 집계 및 정렬과 같은 문서별 필드 데이터가 필요한 작업에 최적화되지 않으므로, 기본적으로 이러한 작업은 실행 중지됩니다. 대신 키워드 필드를 사용하십시오. 또는 [name]에서 fielddata=true를 설정하여 반전된 인덱스를 해제하여 필드 데이터를 로드합니다. 이 경우 상당한 메모리가 사용될 수 있습니다.
즉, 텍스트 필드는 terms 로 나누어서 색인되기 때문에 버킷을 나누기에 적당하지 않고, 입력된 문자열을 하나의 토큰으로 저장하는 키워드 필드를 사용해야 한다
파이프라인 집계
다른 metrics aggregation의 결과를 새로운 입력으로 하는 aggregation 입니다.
min_bucket, max_buekct, avg_bucket, sum_bucket, stats_bucket, moving_avg(이동 평균을 구함), derivative(미분값을 구함), cumulative_sum(값의 누적 합을 구함) 이 있습니다.
"buckets_path": #{버킷 이름} 옵션을 이용해서 입력 값으로 사용할 버킷을 지정합니다.
GET my_stations/_search
{
"size": 0,
"aggs": {
"months": {
"date_histogram": {
"field": "date",
"interval": "month"
},
"aggs": {
"sum_psg": {
"sum": {
"field": "passangers"
}
},
"accum_sum_psg": {
"cumulative_sum": {
"buckets_path": "sum_psg"
}
}
}
}
}
}하위 집계 (sub)
Bucket Aggregation 으로 만든 버킷들 내부에 다시 "aggs" : { } 를 선언해서 또다른 버킷을 만들거나 Metrics Aggregation 을 만들어 사용하는 aggregation 입니다.
🚨 주의 사항
하위 버킷이 깊어질수록 elasticsearch 가 하는 작업량과 메모리 소모량이 기하급수적으로 늘어나기 때문에 예상치 못한 오류를 발생 시킬수도 있습니다. 보통은 2레벨의 깊이 이상의 버킷은 생성하지 않는 것이 좋습니다.