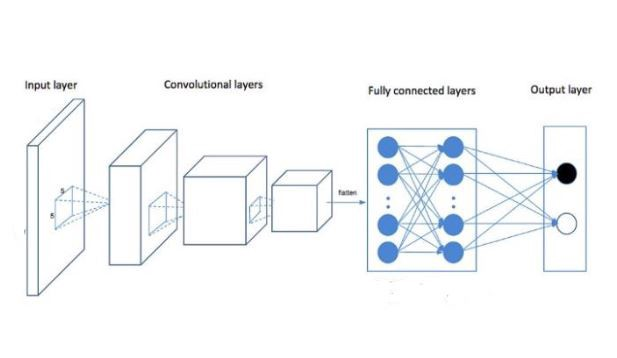
Convolutional Neural Network
딥러닝에서 convolutional neural network (CNN, or ConvNet)은 가상 신경망(ANN)의 한 종류로, 시각 이미지 분석에 주로 사용된다.
CNN 또한 Shift 불변 또는 Space 불변 가상 신경망인SIANN으로도 알려져 있다. 이는 convolution kernels 또는 filters의 shared-weight 아키텍처를 기반한다.
이때 convolution kernerls 와 filters는 input features를 따라 이동하고 translation-equivariant(known as feature maps)를 제공한다.
반직관적으로, 대부분의 convolutional neural networks 들은 변형에 대해 invariant 와 반대인 equivariant(등분산) 입니다.(?)
또한 이들은
- image and video recognition
- recommender systems
- image classification
- image segmentation
- medical image analysis
- natural language processing
- brain–computer interfaces
- financial time series
에 대한 응용프로그램이 있다.
Convolution Layer
https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/
from tensorflow.keras.layers import Conv2D
Conv2D(32, (5,5), padding='valid', input_shape=(28, 28, 1), activation='relu')convolution layer의 파라미터
- 1) convolution filter의 수
- 2) convolution kernel의 (행,열)
- 3) padding : 경계 처리 방법
- 'valid' : 유효한 영역만 출력 (출력 이미지 사이즈와 입력 사이즈보다 작다)
- 'same' : 출력 이미지 사이즈와 입력 사이즈가 동일
- 4) input_shape : 샘플 수를 제외한 입력 형태 (모델의 첫 레이어일 때만 정의)
- (행,열,채널 수) 로 정의 -> 흑백영상의 경우 채널 1, 컬러(RGB)의 경우 채널 3 으로 설정
- 5) activation : 활성화 함수 설정
- 'linear' : 디폴트 값, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력되어 나옴
- 'relu' : rectifier 함수, 은닉층에 주로 사용됨
- 'sigmoid' : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 사용됨
- 'softmax' : 소프트맥스 함수, 다중 클랫 분류 문제에서 출력층에 주로 사용됨
reference 속에서 아래 layer를 도식화한 이미지가 있습니다
Conv2D(1, (2,2), padding='valid', input_shape=(3,3,1))위 파라미터의 의미를 이해하고 상상해본 후 확인해보면 이해에 도움이 될듯 합니다.
filter
convolution layer의 가장 첫 파라미터는 위에서 보았듯
filter의 수입니다. 여기서 filter는 가중치 (weights)를 의미합니다.
하나의 필터가 입력 이미지를 순회하며 적용된 결과값을 모으면 출력이미지가 됩니다.
-
하나의 필터로 입력 이미지를 순회하기 때문에 적용되는 가중치가 모두 동일합니다. (이것이 가장 위에서 보았던 shared-weight 입니다) -> 이로인해 학습해야 하는 가중치 수를 현저히 줄여줍니다.
-
convolution layer에서는 오직 필터의 사이즈 만큼으이 가중치 수를 사용합니다. (필터가 1개인 layer 기준)
-
출력 이미지는 filter의 개수와 동일합니다
역시 래퍼런스에서 filter의 수가 3인 아래 layer의 도식화를 볼 수 있습니다. 미리 상상해보고 정답을 확인해봅시다!
Conv2D(3, (2,2), padding='same', input_shape=(3,3,1))위의 경우 출력 이미지가 3개가 되는데, 이를 출력 이미지 채널이 3개라고 말하기도 합니다.
input_shape channel
그렇다면 입력 이미지의 채널이 여러 개인 경우를 보겠습니다.
Conv2D(1, (2,2), padding='same', input_shape=(3,3,3))input_shape의 z 부분이 3임을 확인할 수 있습니다. (ex. (x,y,3) )
입력 이미지의 수가 늘어났으므로 이에 filter를 적용하는 Kenerl 수도 3으로 늘어납니다. 따라서 filter의 수가 하나이지만, 가중치는 4x3으로 총 12개가 됩니다.
이 예시 역시 reference에 도식화가 잘 되어있습니다. 😃
padding : 경계 처리 방법
paddin 즉 border_mode에는 'valid', 'same' 두 가지가 존재합니다.
valid는 입력 이미지 영역에 맞게 필터를 적용해 출력 이미지의 사이즈가 입력보다 작아집니다.
반면 same는 출력 사이즈를 입력과 동일하게 하기 위해서 입력 이미지 경계에 빈 영역을 추가해 필터를 적용합니다. (쉽게 입력 이미지의 사이즈를 늘림)
이는 입력 이미지의 경계를 학습시키는 효과를 가집니다.
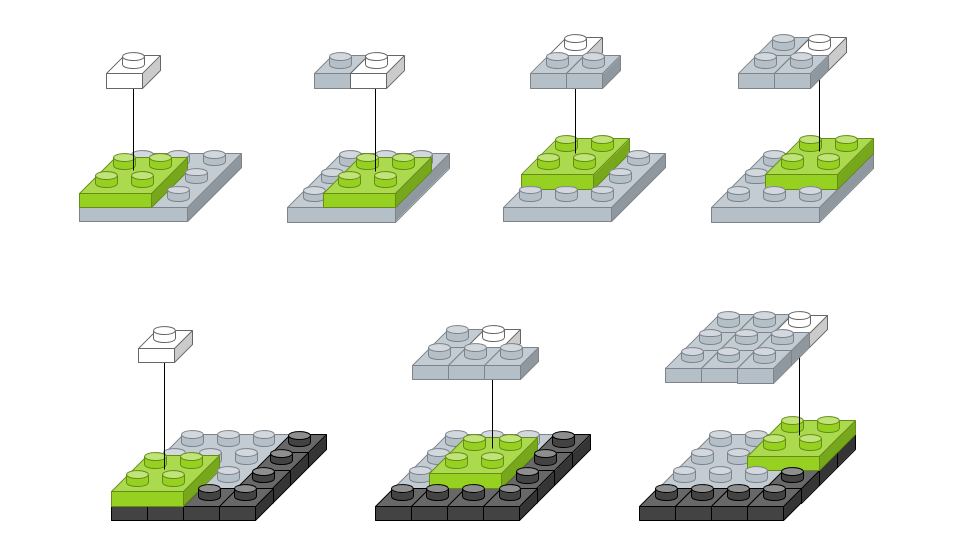
이 경우 말로는 쉽게 이해가 되지 않아, 원 글의 이미지를 첨부했습니다.
지금까지 Convolutional Neural Network와 Keras의 Convolution Layer class를 공부해보았습니다.
특히 많은 참고가 된 아래 reference는 이해에 큰 도움이 됨으로 저와 같은 초보자들에게 좋을 듯 합니다 😇
