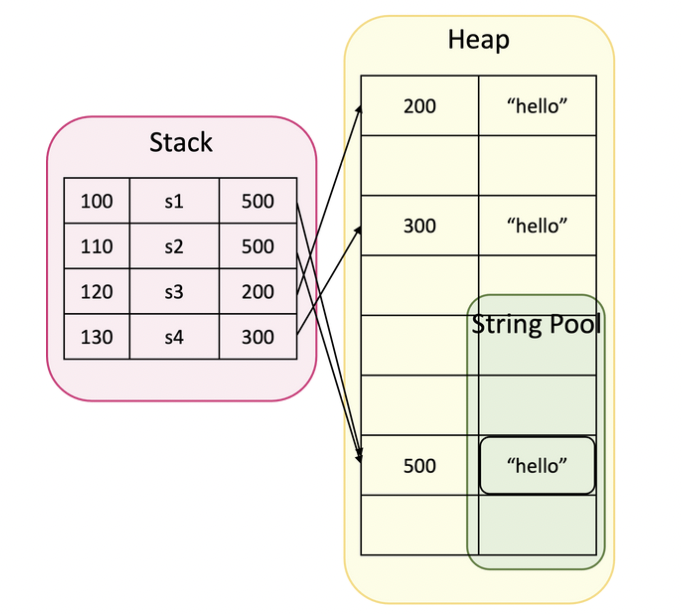
String Pool (상수풀)
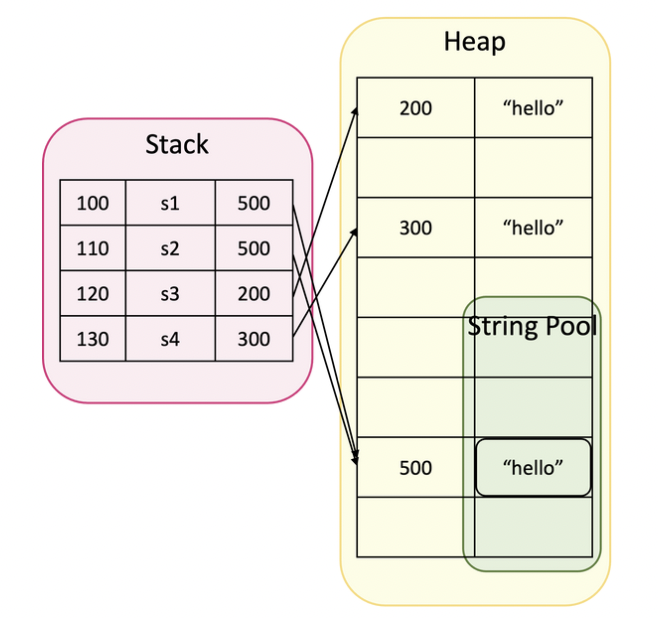
=
- 변수 달라도 메모리 주소, 데이터 동일 (s1, s2)
- String Pool에서 데이터 재사용 하여 메모리 관리에 더 효과적
new String("");
- 새로운 메모리 주소 할당 (s3, s4)
- 사용하는 경우 거의 없음
- 상수적 특징 (여러 변수가 참조 할 수 있으므로)
- 일부 원소 수정 불가. 수정하려면 새로운 주소 참조
- 하나의 공간에서 append(+) 되지 않음
- 수정할 데이터를 Stirng 에 넣는 것은 좋지 않음. 메모리를 많이 차지
package me.day07.string;
public class StringInitExample {
public static void main(String[] args) {
//// 참조 : 변수와 주소는 스택에, 객체 데이터는 힙에 저장
String s1 = "hello";
String s2 = "hello"; // s1, s2 주소(데이터) 공유
String s3 = new String("hello");
String s4 = new String ("hello"); // 다른 메모리 주소 (거의 사용하지 않음)
// == : 주소값 비교
System.out.println(s1 == s2); // true
System.out.println(s3 == s4); // false
// equals() : 내용물 비교
System.out.println(s1.equals(s2)); // true
System.out.println(s3.equals(s4)); // true
// eauals() 내부 구현
/*
public static boolean equals(byte[] value, byte[] other) { // String -> char[] -> byte[] // 가장 밑단에서 실행되므로 byte로 받음
if (value.length == other.length) { // 길이 다르면 false
int len = value.length >> 1;
for (int i = 0; i < len; i++) {
if (getChar(value, i) != getChar(other, i)) { // i번째 끼리 비교
return false;
}
}
return true;
}
return false;
}
*/
//// String Pool의 상수적 특징 (여러 변수가 참조 할 수 있기 때문)
String s = "hello";
// 1. 일부 원소 수정 불가
// s.charAt(0) = 'H';
// 수정하려면 새로운 주소 참조
s = "olleh"; // 데이터가 수정 된 것이 아니라, String Pool에서 새로운 공간을 참조하는 (가리키는) 것
// 2. 하나의 공간 안에서 + 되는 것 아님
s += " world"; // "hello", "olleh", "olleh world" 공간 따로 있고 s는 "olleh world"를 참조 // 참조되지 않으면 GC
// StringBuilder, StringBuffer 가 나온 이유
}
}StringBuilder
- 데이터의 원소 수정 가능
- 계속 공간 생기지 않고 하나의 공간에서 값 수정, 완성되면 String Pool에 넣을 수 있음
- string pool 밖의 heap 공간 사용
- 동기화 불가 (동시 접근시 문제 발생)
StringBuffer
- 데이터의 원소 수정 가능
- 여러개의 스레드(사용자) 있을때, 동기화(순서화) 가능하지만 속도 더 느림
public class StringBuilderExample {
public static void main(String[] args) {
// 수정이 필요한 문자열은 StringBuilder 객체에 저장
StringBuilder sb = new StringBuilder("hello");
sb.append(" world"); // 하나의 공간 사용
String s = sb.toString(); // 수정 완료되면 상수로 바꾸기
System.out.println(s);
}
}equals(), equalsIgnoreCase()
- String => char[] =>
byte로 변환 (아스키코드)
package me.day07.string;
public class StringEqualsExample {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "Hello";
// equals() 내부 구현
// 같은 경우 말고 다른 경우를 체크
boolean isEquals1 = s1.equals(s2);
/*
@HotSpotIntrinsicCandidate
public static boolean equals(byte[] value, byte[] other) {
// byte : String => char[] => byte 로 변환(아스키코드)되어 비교됨. 가장 밑단에서 실행되는 함수이므로 byte 로 실행됨
if (value.length == other.length) { // 길이가 다른 경우
int len = value.length >> 1; // >> 1 은 왜한거임
for (int i = 0; i < len; i++) {
if (getChar(value, i) != getChar(other, i)) {
return false;
}
}
return true;
}
return false;
}
*/
boolean isEquals2 = s1.equalsIgnoreCase(s2);
boolean isEquals3 = s1.equalsIgnoreCase(s2);
System.out.println(isEquals1); // false
System.out.println(isEquals2); // true
System.out.println(isEquals3); // true
}
}length()
package me.day07.string;
public class StringLengthExample {
public static void main(String[] args) {
String s1 = " ";
String s2 = "hello ";
// whitespace도 계산
System.out.println(s1.length());
System.out.println(s2.length());
// whitespace 제거하고 계산
System.out.println(s2.strip().length()); // method1().method2().. 이어서 작성가능 (function chaining)
}
}
charAt()
package me.day07.string;
public class StringCharAtExample {
public static void main(String[] args) {
// 문자열에는 인덱스라는 개념 존재
// 문자열도 문자들의 열거. 즉 배열이기 때문에 문자열 내에 순서가 존재함
// 인덱스 - 원소 순서대로 번호를 매겨 원소를 접근할 수 있도록 하는 숫자 (0 <= < 문자열 길이)
// 인덱싱 - 인덱스를 통해 원소 접근 방법
String s = "hello";
char c = s.charAt(0);
System.out.println(c); // "h"
c = s.charAt(s.length()-1);
System.out.println(c); // "o"
}
}indexOf()
package me.day07.string;
public class StringIndexOfExample {
public static void main(String[] args) {
String s = "helloh";
int idx = s.indexOf('h'); // 처음으로 등장하는 'h' 인덱스 반환
System.out.println(idx); // 0
idx = s.lastIndexOf('h'); // 뒤에서부터 처음으로 등장하는 'h' 인덱스 반환
System.out.println(idx);
idx = s.indexOf('h', 2); // 인덱스 2부터 'h' 찾아 인덱스 반환
System.out.println(idx);
idx = s.indexOf("llo"); // 처음으로 등장하는 "llo" 인덱스 반환
System.out.println(idx);
idx = s.indexOf("llo", 3); // 인덱스 3부터 "llo"를 찾아 인덱스 반환
System.out.println(idx); // 문자열 찾지 못하면 -1 반환
}
}contains()
package me.day07.string;
public class StringContainsExample {
public static void main(String[] args) {
String str = "hello";
boolean isContains1 = str.contains("ell"); // 해당 문자열을 포함하는지
// 내부 구현 살펴 볼 것! : e 발견하면 뒤에 ll 있는지 체크 (이중 for문)
boolean isContains2 = str.contains("llo");
boolean isContains3 = str.contains("lle");
boolean isContains4 = str.contains("H");
System.out.println(isContains1); // true
System.out.println(isContains2); // true
System.out.println(isContains3); // false
System.out.println(isContains4); // false (case sensitive)
}
}compareTo()
package me.day07.string;
public class StringCompareToExample {
public static void main(String[] args) {
// 문자열 사전식 비교
// 왼쪽이 더 앞이면 음수, 같으면 0, 뒤면 양수 반환
// 길이 다르면 -1 반환 (비교불가)
System.out.println("a".compareTo("aa")); // -1
System.out.println("a".compareTo("c")); // -2 // == 'a' - 'c' (2칸 더 뒤에 있다)
System.out.println("a".compareTo("A")); // 32 // == 'a' - 'A'
System.out.println("a".compareToIgnoreCase("A")); // 0
}
}subString()
package me.day07.string;
public class StringSubStringExample {
public static void main(String[] args) {
String str = "Java is Fun.";
// str.substring : String 클래스의 메서드 -> 수동태 처럼 주체부터 나옴
String substring1 = str.substring(0, 4); // 0 ~ 3 (0 <= < 4)
String substring2 = str.substring(5); // 5 ~
String substring3 = str.substring(5, str.length()); // 5 ~
System.out.println("substring1 = " + substring1);
System.out.println("substring2 = " + substring2);
System.out.println("substring3 = " + substring3);
// subString(str) : static 으로 직접 만든 함수 이므로 str 인자로 전달 해줘야함 -> 동사부터 나옴 (객체 지향적이지 않음)
String substring4 = subString(str, 0, 4);
String substring5 = subString(str, 5);
String substring6 = subString(str, 5, str.length()); // str.length() 생략가능
System.out.println("substring1 = " + substring4);
System.out.println("substring2 = " + substring5);
System.out.println("substring3 = " + substring6);
}
public static String subString(String s, int beginIndex, int endIndex) {
String result = "";
for(int i = beginIndex; i < endIndex; i++) { // 시작 인덱스에서 끝 인덱스까지 다 가지고 와서
result += s.charAt(i); // apend
}
return result;
}
public static String subString(String s, int beginIndex) {
String result = "";
for(int i = beginIndex; i < s.length(); i++) {
result += s.charAt(i);
}
return result;
}
}trim(), strip()
package me.day07.string;
public class StringTrimStripExample {
public static void main(String[] args) {
// 양쪽 끝에 있는 공백문자(white space) 삭제 (중간의 공백은 유지)
// 크롤링에 많이 사용
// 아스키코드
String str1 = " \t\t\n\rhello \t\t\n\r"; // t: tap, n: enter, r: 윈도우에서 엔터와 같이 출력됨
System.out.println("Before: \"" + str1 + "\"");
System.out.println("After trim: \"" + str1.trim() + "\""); // 더 느림
System.out.println("After strip: \"" + str1.strip() + "\""); // 공백문자 종류 더 많고, 최적화, 유니코드에서도 동작 (JDK11~)
System.out.println();
// 유니코드 (더 많은 공백문자 있음)
String str2 = '\u2001' + "String with space" + '\u2001';
System.out.println("Before: \"" + str2 + "\"");
System.out.println("After trim: \"" + str2.trim() + "\""); // 공백 살아 있음
System.out.println("After strip: \"" + str2.strip() + "\"");
}
}toCharArray()
package me.day07.string;
import java.util.Arrays;
public class StringToCharArrayExample {
public static void main(String[] args) {
String str = "this is constant string. Immutable"; // string pool
// str.charAt(0) = 'T'; // 원소 수정 불가능
char[] charArr = str.toCharArray(); // 문자열(string pool) -> 문자 배열(heap)
System.out.println(Arrays.toString(charArr));
charArr[0] = 'T'; // 원소 수정 가능
System.out.println(Arrays.toString(charArr));
// char[]을 객체화 시킨 것이 StringBuilder, StringBuffer
// 문자 배열보다 더 많은 함수 가지고 있음
String res = String.valueOf(charArr); // char[] -> string (다시 상수화)
System.out.println(res);
}
}toUpperCase(), toLowerCase()
package me.day07.string;
public class StringToUpperLowerCaseExample {
public static void main(String[] args) {
String s1 = "HeLLo";
String s2 = "hello";
String s3 = "1231123!";
System.out.println(s1.toLowerCase()); // 소문자로 바꾸기
System.out.println(s2.toUpperCase()); // 대문자로 바꾸기
System.out.println(s3.toLowerCase()); // 영문자가 아닌 경우에는 그대로 출력
// 대소문자 구분 없이 비교하기
System.out.println(s1.toLowerCase().equals(s2.toLowerCase())); // 두개 다 소문자/대문자로 바꾸기
System.out.println(s1.equalsIgnoreCase(s2)); // 함수로 만듦
}
}toString()
- StringBuilder / StringBuilder → String 할 때 사용
- 객체 변수를 출력시 원래 주소값이 아닌 내용물을 출력하기 위해 사용 (재정의)
isEmpty(), isBlank()
package me.day07.string;
public class StringIsEmptyExample {
public static void main(String[] args) {
String s1 = "";
String s2 = "\t\n ";
// isEmpty() : s.length() == 0 인지 체크
System.out.println(s1.isEmpty()); // true
System.out.println(s2.isEmpty()); // false
// isBlank() : s.strip().length() == 0 인지 체크
System.out.println(s1.isBlank()); // true
System.out.println(s2.isBlank()); // true
}
}parse~()
Byte.parseByte(String str) : String → byte
Short.parseShort(String str) : String → short
Integer.parseInt(String str) : String → int ("1234" -> 1234)
Long.parseLong(String str) : Strign → long
Float.parseFloat(String str) : String → float
Double.parseDouble(String str) : String → double
정규표현식(regex), Pattern.matches()
- 입력받은 데이터의 유효성 검사에 많이 사용 (이메일, 전화번호, ..)
- 내부적으로 for, if 사용
https://hbase.tistory.com/160
package me.day07.regex;
import java.util.regex.Pattern;
public class PatternClassExample {
// 정규표현식
// 입력 받은 데이터의 유효성 검사할때 사용
static final String EMAIL_REGEX = "^\\w+@\\w+\\.\\w+(\\.\\w+)?$";
// @ . .
// ()? : 있어도 없어도 된다 (co.kr)
// \w: 알파벳이나 숫자, \d: 0~9, +: 하나 이상 오냐, ^: 시작, $: 끝
static final String PHONE_REGEX = "^\\d{2,3}-\\d{3,4}-\\d{4}$";
// - -
// {2,3}: 2개 이상 3개 이하
// \d : 숫자
public static void main(String[] args) {
// Pattern.matches : 입력받은 데이터와 정규표현식을 비교
String email = "qwerty@gmail.com";
System.out.println(Pattern.matches(EMAIL_REGEX, email)); // true
email = "qweqw@naver.co.kr";
System.out.println(Pattern.matches(EMAIL_REGEX, email));
email = "qwe@naver.";
System.out.println(Pattern.matches(EMAIL_REGEX, email)); // false
String phone = "010-1234-5678";
System.out.println(Pattern.matches(PHONE_REGEX, phone));
phone = "02-000-0000";
System.out.println(Pattern.matches(PHONE_REGEX, phone));
phone = "010-00000-0000";
System.out.println(Pattern.matches(PHONE_REGEX, phone));
// String.matches()
email.matches(EMAIL_REGEX); // 내부 보면 Pattern.matches() 사용함
// Matcher : api에서 다시
}
}replace(), replaceAll(), replaceFirst()
package me.day07.string;
public class StringReplaceExample {
static final String SMALL_LETTER_REGEX = "[a-z]"; // 소문자
static final String NOT_ALNUM_REGEX = "[^a-z0-9]"; // 알파벳, 소문자 아닌 것들 (특수문자)
static final String KOREAN_REGEX = "[가-힣]"; // 한글
public static void main(String[] args) {
String str1 = "hello world world"; // string pool, 수정 불가
String str2 = "hello world world";
// replace() : str1 가 수정되는 것은 아님 (str1 값 가져와서 StringBuilder 로 수정하여 리턴)
String replace1 = str1.replace("world", "WORLD"); // hello WORLD WORLD
System.out.println("replace1 = " + replace1);
String replace2 = str1.replace("w", "W"); // 문자 가능
System.out.println("replace2 = " + replace2);
System.out.println();
String strAll1 = "hello world world";
String strAll2 = "hello world worlD";
// replaceAll() : 정규표현식 사용 가능
String replaceAll1 = strAll1.replaceAll("world", "WORLD"); // replace() 와 동일
// String replaceAll2 = strAll2.replaceAll('w', 'W'); // 문자 불가
String replaceAll2 = strAll2.replaceAll(SMALL_LETTER_REGEX, "_"); // _____ _____ ____D
System.out.println("replaceAll1 = " + replaceAll1);
System.out.println("replaceAll2 = " + replaceAll2);
System.out.println();
String strAll4 = "abasdasd!!012345^~*#";
String replaceAllRegEx1 = strAll4.toLowerCase().replaceAll(NOT_ALNUM_REGEX, ""); // 특수문자 제거
System.out.println("replaceAllRegEx1 = " + replaceAllRegEx1);
String strAll5 = "가나다라마바사ABCDEFG";
String replaceAllRegEx2 = strAll5.replaceAll(KOREAN_REGEX, ""); // 한글 제거
System.out.println("replaceAllRegEx2 = " + replaceAllRegEx2);
System.out.println();
}
}split()
package me.day07.string;
import java.util.Arrays;
public class StringSplitExample {
public static void main(String[] args) {
// split() : 삭제
String str1 = "010-1234--5678";
String[] strSplit1 = str1.split("-"); // [010, 1234, , 5678]
System.out.println("strSplit2 = " + Arrays.toString(strSplit1));
// +
String[] strSplit2 = str1.split("[-]+"); // [010, 1234, 5678]
System.out.println("strSplit2 = " + Arrays.toString(strSplit2));
// limit
String str2 = "010.1234...5678";
String[] strSplit3 = str2.split("[.]+", 2); // [010, 1234...5678]
System.out.println("strSplit1 = " + Arrays.toString(strSplit3));
// join()
String str3 = "22/09/23";
String[] strSplit4 = str3.split("/"); // [22, 09, 23]
System.out.println("strSplit3 = " + Arrays.toString(strSplit4));
String strJoin = String.join(".", strSplit4); // "22.09.23"
System.out.println("strJoin = " + strJoin);
// split vs StringTokenizer
// split : 중간을 기준으로 왼쪽 오른쪽 자름 -> 처음부터 삭제할 문자열 들어오면 빈문자열로 바꿈
// StringTokenizer : 빈문자열도 다 제거
String str4 = "adkasd100200asd1";
String[] strSplit5 = str4.split("[a-zA-Z]+"); // [, 100200, 1] // 알파벳 하나이상
System.out.println("strSplit5 = " + Arrays.toString(strSplit5));
}
}문자열 활용 범위
- 웹개발에서 클라이언트와의 통신할때
String(JSON)이byte[]형식보다 간편 - 크롤링에 사용 (웹페이지에서 html 태그 제거 후 데이터만 디비에 넣는 행위)
