StringBuilder / StringBuffer 성능비교
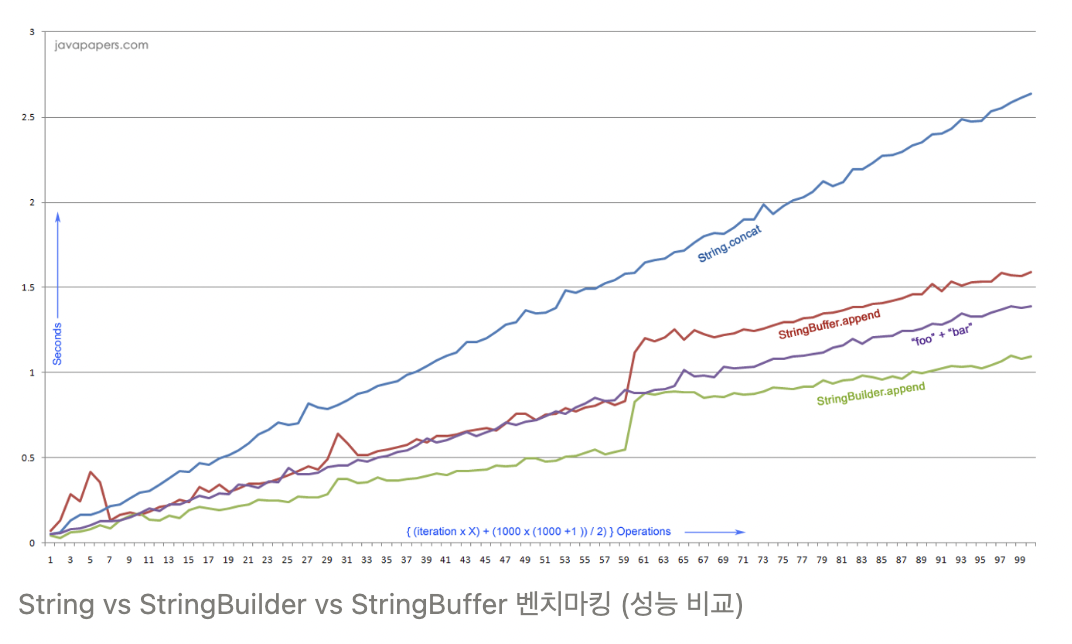
String.concat
"" + ""
- 기존 "foo", "bar" 와 다른 주소에 "foobar" 할당 (string pool)
- 메모리 할당하는 속도 더해짐
StringBuilder
- Heap에 저장
- 단일 스레드 환경에서 주로 사용. 동기화 지원X (코테 문제 풀기)
StringBuffer
- 동기화(여러개의 스레드(사용자)에 대해 순서화) 지원하기 때문에 Builder 보다 느림
- 멀티 스레드 (웹개발) 환경에서 주로 사용
StringBuilder
package me.day08.stringbuilder;
import java.util.Arrays;
public class StringBuilderExample {
public static void main(String[] args) {
StringBuilder stringBuilder1 = new StringBuilder("Java");
stringBuilder1.append(" is OOP Language");
stringBuilder1.insert(0, "The ");
System.out.println(stringBuilder1);
stringBuilder1.setLength(11);
System.out.println(stringBuilder1);
stringBuilder1.replace(4, 4 + "java".length(), "c++");
System.out.println(stringBuilder1);
System.out.println(stringBuilder1.capacity());
stringBuilder1.trimToSize();
System.out.println(stringBuilder1.capacity());
stringBuilder1.delete(0, 3);
System.out.println(stringBuilder1);
System.out.println();
String string = stringBuilder1.toString();
System.out.println(string);
System.out.println();
StringBuilder stringBuilder2 = new StringBuilder(string.strip());
System.out.println("CompareTo = " + stringBuilder2.compareTo(stringBuilder1));
System.out.printf("%d\n", (int)' ');
System.out.printf("%d\n", (int)'c');
System.out.println("indexOf = " + stringBuilder2.indexOf("is"));
System.out.println("lastIndexOf = " + stringBuilder2.lastIndexOf("is"));
System.out.println();
CharSequence charSequence = stringBuilder2.subSequence(1, 2);
System.out.println("SubString = " + charSequence);
System.out.println();
char[] chars = new char[100];
stringBuilder2.getChars(1, 5, chars, 2);
System.out.println(Arrays.toString(chars));
for (int i = 0; i < chars.length; i++) {
System.out.printf("%c = %d\n", chars[i], (int)chars[i]);
}
System.out.println();
StringBuilder stringBuilder3 = stringBuilder2.reverse();
System.out.println("Reverse = " + stringBuilder3);
System.out.println("stringBuilder2 = " + stringBuilder2);
}
}
StringBuffer
- 메소드는 전부 동일
- 동기화 지원하는 것만 다름
StringTokenizer
- 쪼개진 문자열 : token
구분자 : delimiter
- 생성자
public StringTokenizer(String str);
- 절달된 매개변수 str을 기본 delim 으로 분리
- 기본 delimiter: " \t\n\r\t" (공백문자)
public StringTokenizer(String str, String delim);public StringTokenizer(String str, String delim, boolean returnDelims);
- str을 특정 delim으로 분리시키는데 그 delim까지 token으로 포함할지를 결정
- 매개변수가 returnDelims로 true 포함, false일땐 포함하지 않음
package me.day08.stringtokenzier;
import java.util.Iterator;
import java.util.StringTokenizer;
public class StringTokenizerExample {
public static void main(String[] args) {
final String str = "홍홍, 박박, 김김";
String[] splitString = str.split(", ");
for (String s: splitString) {
System.out.println("s = " + s);
}
System.out.println();
StringTokenizer stringTokenizer1 = new StringTokenizer(str, ", ");
int count = stringTokenizer1.countTokens();
System.out.println("count = " + count);
System.out.println();
for (int i = 0; i < count; i++) {
String token = stringTokenizer1.nextToken();
System.out.println("token = " + token);
}
System.out.println();
StringTokenizer stringTokenizer2 = new StringTokenizer(str, ", ");
while (stringTokenizer2.hasMoreTokens()) {
String token = stringTokenizer2.nextToken();
Object token2 = stringTokenizer2.nextElement();
Integer token3 = (Integer) token2;
System.out.println("token = " + token);
System.out.println("token2 = " + token2);
System.out.println("token3 = " + token3);
}
System.out.println();
StringTokenizer stringTokenizer3 = new StringTokenizer(str, ", ");
Iterator<Object> iterator = stringTokenizer3.asIterator();
while (iterator.hasNext()) {
Object token = iterator.next();
System.out.println("token = " + token);
}
System.out.println();
String data = "100,,,200,300";
String[] strings = data.split(",");
for (int i = 0; i < strings.length; i++) {
System.out.println("strings[i] = " + strings[i]);
}
System.out.println("strings.length = " + strings.length);
System.out.println();
StringTokenizer stringTokenizer = new StringTokenizer(data, ",");
System.out.println("stringTokenizer.countTokens() = " + stringTokenizer.countTokens());
while (stringTokenizer.hasMoreTokens()) {
System.out.println("stringTokenizer.nextToken() = " + stringTokenizer.nextToken());
}
System.out.println("stringTokenizer.countTokens() = " + stringTokenizer.countTokens());
}
}
String split()
- 빈 문자열도 토큰으로 인식 (중간을 기준으로 양 옆을 자르므로)
- 정규식 사용 가능
- 잘라낸 결과를 배열에 담아 반환 (데이터 양이 많은 경우 성능 떨어짐)
StringTokenizer()
- 자르는 순간마다 String 으로 반환시켜 성능 더 좋다. -> 코테에서 더 유리.
- split() 후 모든 공백문자 삭제하여 반환 (빈 문자열은 토큰으로 인식하지 않음)
object
- 제일 최상위의 클래스여서
String 뿐만 아니라 다른 데이터 타입도 들어 올 수 있다.
- 즉, 자른 데이터를 다른 데이터 타입 (
Integer, Double, ..) 으로 전달 할 수 있다. (원시타입을 매핑 시킨 Wrapper 클래스)
Integer.parseInt() 로 함수 부르는 것보다 바로 타입 캐스팅 하는 것이 좋다.
throws NumberFormatException 하므로 trt ~ catch 로 또 잡아줘야함
