🎯 최종 목표: PDF 문서를 학습하고, 질문에 대한 정확한 답을 제공하는 RAG 챗봇 개발
🚀 1단계: 챗봇 개발 개요
우리 챗봇의 주요 목표는 다음과 같아.
- PDF 문서에서 정보를 추출하고 전처리(정제 → 청킹 → 임베딩 → 색인화)하는 것
- OpenAI 임베딩 모델을 사용하여 문서 내용을 벡터로 변환하고 ChromDB(벡터 DB)에 저장하는 것
- 올라마(OLlama) 기반 LLM을 활용하여 RAG 기법을 적용한 자연어 응답 생성하기
- Gradio를 이용하여 웹 인터페이스를 만들기
📂 2단계: PDF 문서 전처리
먼저, PDF 문서를 데이터로 활용할 수 있도록 전처리해야 해.
📌 2.1 데이터 정제
PDF 문서에서 텍스트만 추출하고, 불필요한 HTML 태그, 특수 문자, 공백 등을 제거해야 해.
표준화된 텍스트로 변환하면 검색 품질이 올라가!
📌 2.2 문서 청킹 (Chunking)
문서가 길면 벡터로 변환할 때 문맥이 깨질 수 있어.
문장 단위 또는 단락 단위로 나눠서 연속적인 의미가 유지되도록 해야 해.
청킹을 잘하면 검색 정확도가 올라가!
🔍 3단계: 문서 임베딩 및 벡터 데이터베이스 구축
문서를 작은 청크로 나눈 후, 이를 벡터로 변환해서 저장해야 해.
📌 3.1 임베딩(Embedding) 생성
OpenAI의 text-embedding-3-small 모델을 사용하여 각 문장(청크)을 벡터로 변환해.
벡터는 문장의 의미를 수치로 표현하는 방식이야.
📌 3.2 벡터 DB에 저장
변환된 벡터를 ChromDB에 저장할 거야.
나중에 사용자가 질문하면 가장 의미적으로 가까운 벡터(문장)를 찾아서 응답을 만들 수 있어.
💡 4단계: 챗봇의 RAG 기능 구현
이제 RAG (Retrieval-Augmented Generation, 검색 증강 생성)을 적용할 차례야.
📌 4.1 벡터 검색
사용자의 질문을 임베딩(벡터)으로 변환하고, 벡터 DB에서 가장 유사한 문장을 찾는 방식이야.
즉, 가장 관련성이 높은 정보를 검색해서 제공할 수 있어.
📌 4.2 관련성 평가
검색된 문서 중 관련성 높은 문서만 선별할꺼야
문서와 질문의 관련성을 평가하는 체인 구현하고
Pydantic을 사용하여 출력 형식(JSON)을 명확히 정의해야해
with_structured_output()을 사용하여 LangChain과 함께 구조화된 데이터를 반환할 수 있어
📌 4.3 올라마 기반 LLM 응답 생성
벡터 DB에서 찾은 내용을 LLM(올라마 모델)에 전달하면,
문맥을 반영한 자연스러운 답변을 생성할 수 있어.
🎨 5단계: Gradio를 활용한 웹 UI 개발
Gradio를 사용하면 쉽고 간단하게 챗봇을 웹에서 실행할 수 있어.
버튼 하나로 PDF 업로드 → 질문 입력 → AI가 답변 생성하는 흐름을 만들 거야.
📌 6단계: 챗봇 히스토리 관리
대화를 기록해서 이전 대화 맥락을 반영한 답변을 생성하도록 할 거야.
사용자의 대화 기록을 저장해서, 문맥을 더 잘 이해할 수 있도록 개선할 수 있어.
개념정리
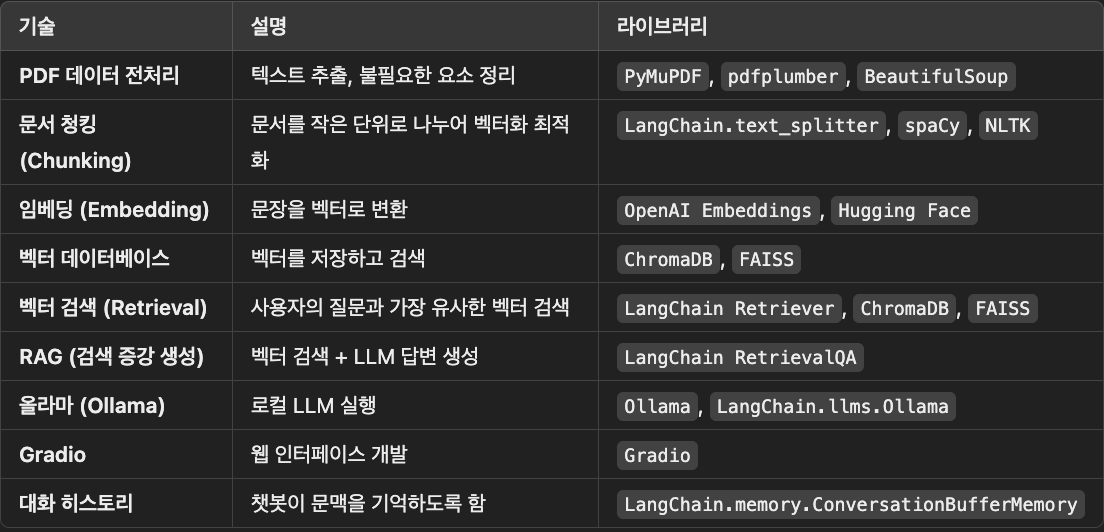
1️⃣ PDF 문서 전처리 관련 기술
문서를 AI가 이해할 수 있도록 가공하는 과정에서 필요한 기술들.
📌 1.1 데이터 정제 (Data Cleaning)
PDF에서 텍스트를 추출하고 불필요한 요소(HTML 태그, 특수문자, 공백 등)를 제거하는 과정.
사용 기술: PyMuPDF, pdfplumber, BeautifulSoup (HTML 정리)
📌 1.2 문서 청킹 (Chunking)
문서를 너무 길게 유지하면 LLM이 이해하기 어려우므로, 작은 단위(청크)로 분할하는 과정.
일반적으로 문장 단위, 단락 단위, 고정된 토큰 수 등으로 청킹 가능.
사용 기술: LangChain.text_splitter, NLTK, spaCy
2️⃣ 임베딩 및 벡터 데이터베이스 관련 기술
텍스트를 수치화(벡터화)하고 빠르게 검색할 수 있도록 저장하는 과정.
📌 2.1 임베딩 (Embedding)
텍스트를 **벡터(숫자로 이루어진 배열)**로 변환하는 과정.
벡터는 의미적 유사성을 계산하는 데 사용됨.
사용 기술:
OpenAI text-embedding-3-small (임베딩 생성)
Hugging Face Transformers (BERT, Sentence Transformers 등 대체 가능)
📌 2.2 벡터 데이터베이스 (Vector Database)
문장을 벡터로 변환한 후 저장하고, 유사한 벡터를 빠르게 검색하는 데이터베이스.
RAG 기법의 핵심 요소.
사용 기술:
ChromaDB (경량 벡터 데이터베이스)
FAISS (빠른 검색을 위한 오픈소스 라이브러리)
Weaviate, Pinecone (대체 가능)
3️⃣ RAG (Retrieval-Augmented Generation) 관련 기술
LLM이 검색을 활용하여 더 정확한 답변을 생성하는 방식.
📌 3.1 벡터 검색 (Vector Retrieval)
사용자의 질문을 벡터로 변환하고, 벡터 데이터베이스에서 가장 유사한 문장 검색.
사용 기술: ChromaDB, FAISS, LangChain Retriever
📌 3.2 RAG 기반 응답 생성
벡터 검색으로 찾은 문장을 LLM에 입력하여 답변을 생성.
단순 LLM보다 더 정확한 답변을 제공 가능.
사용 기술: LangChain RetrievalQA, Ollama
4️⃣ LLM 및 올라마 (Ollama) 관련 기술
LLM을 로컬에서 실행하여 자연어 이해 및 생성하는 과정.
📌 4.1 올라마 (Ollama)
로컬에서 실행 가능한 경량 LLM 프레임워크.
인터넷 없이도 AI 모델을 실행 가능.
사용 기술:
Ollama (LLaMA, Mistral 등 지원)
LangChain.llms.Ollama (LangChain과 연동)
📌 4.2 OpenAI API
외부 API를 통해 최신 모델을 사용할 수도 있음.
text-embedding-3-small, GPT-4, GPT-3.5-turbo 등 사용 가능.
사용 기술: openai 라이브러리
5️⃣ Gradio를 활용한 웹 UI 개발
Gradio를 이용하면 사용자가 직접 챗봇과 상호작용할 수 있는 인터페이스를 쉽게 만들 수 있어.
📌 5.1 Gradio 인터페이스
버튼 하나로 파일 업로드 → 질문 입력 → 답변 출력을 만들 수 있음.
API 없이도 브라우저에서 실행 가능.
사용 기술: Gradio, Gradio.Interface()
6️⃣ 챗봇 히스토리 (대화 맥락) 관리
챗봇이 문맥을 기억하도록 하는 기능.
📌 6.1 대화 기록 (Memory) 관리
사용자의 대화를 저장하여 맥락을 유지함.
사용 기술: LangChain.memory.ConversationBufferMemory()
🔍 추가로 고려할 수 있는 기술
✅ FastAPI: 챗봇을 API 서버로 배포할 때 사용
✅ Docker: 챗봇을 컨테이너화하여 배포
✅ Streamlit: Gradio 외에 UI 개발 대안