LLM
1.LLM Day 2 - 환경설정
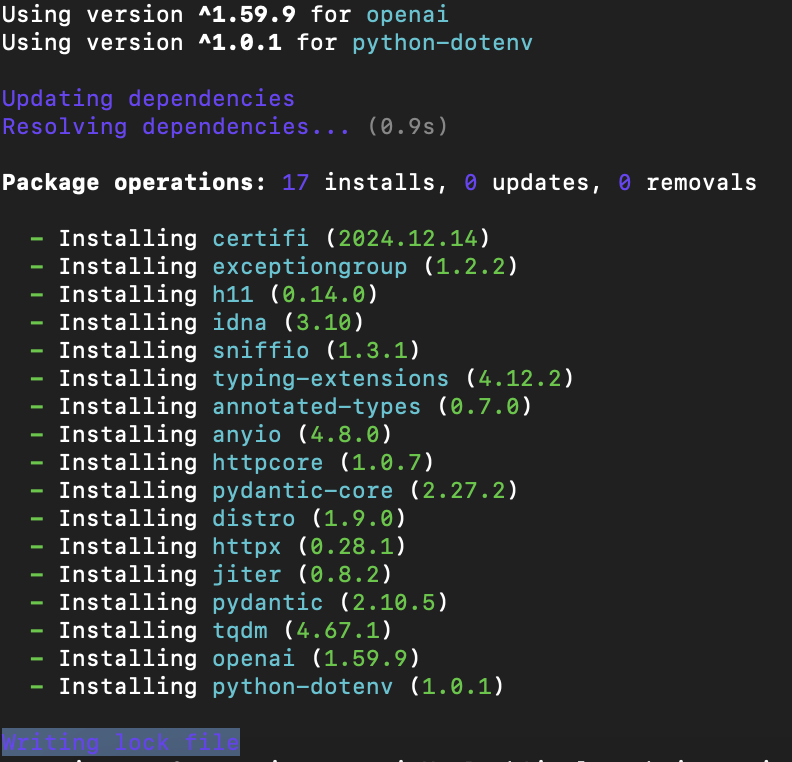
환경설정PoetryVS code (jupyter, python)Python 패키지(예: maturin, jiter)는 Rust 기반으로 작성되어 있으며, 이를 소스에서 빌드하려면 Rust 컴파일러가 필요Poetry 사용을 위해 기존 anaconda 비활성화 필요안하면
2.LLM Day 5

VS Code에서 작업할 디렉토리를 생성(poetry install은 에러가난다ㅠㅠ) Poetry 가상 환경 생성\+패키지 별도 설치Poetry 가상 환경을 Jupyter에 연결에러가 나서 아래로 다시 해주었다VS Code를 열고 my_project 폴더를 워크스페이스
3.LLM Day 2

LLM 생성 원리 OpenAI Chat Completion API 활용 poetry 프로젝트 설정 poetry --version 프로젝트 추가 : poetry new [프로젝트명] 가상환경 생성 : poetry install poetry
4.LLM Day 6
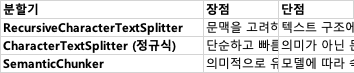
LLM DAY 7Retrieval-Augmented Generation (RAG) 시스템에서 Test Set을 설계할 때, 단순히 문서를 청크하고 벡터화하는 것만으로는 충분하지 않다. 어떤 유형의 데이터로 어떤 목표 수준의 시스템을 구축할 것인지에 따라, 적절한 청크
5.LLM Day 7

Fine-tuning은 사전 훈련된 모델을 특정 데이터셋에 맞춰 추가적으로 훈련하는 과정으로, 특정 도메인 또는 태스크에 대한 적합성(domain adaptation) 을 극대화할 수 있다. 그러나, 훈련 데이터에 대한 가중치를 높이는 과정에서 모델의 일반화 성능(ge
6.LLM Day8-실습

이 실습에서는 벡터 저장소(Vector Store) 를 활용하여 문서를 저장하고, 검색하는 기능을 구현할 거야!✅ 샘플 문서를 벡터 저장소에 저장✅ 임베딩 모델을 사용하여 벡터화✅ 문서를 추가/삭제/검색할 수 있는 기능 구현✅ 왜 벡터 저장소가 필요할까?일반 데이터베이
7.LLM Day8 - project
이 코드는 PDF 논문을 벡터로 변환하여 저장하고, 사용자가 질문을 입력하면 관련 정보를 검색하여 답변을 생성하는 Q&A 챗봇을 구현한 것입니다.Python의 여러 라이브러리를 사용하며, 핵심 기술 요소는 ChromaDB 기반 벡터 검색과 LangChain을 활용한 자
8.LLM Day9

📌 프롬프트 엔지니어링이란?프롬프트(Prompt)는 인공지능(AI)에게 명령을 내리는 문장쉽게 말하면 AI에게 원하는 결과를 얻기 위해 질문을 잘 던지는 기술이 프롬프트 엔지니어링💡 예제: AI한테 "고양이에 대해 알려줘"라고 하면?📌 프롬프트: "고양이에 대해
9.LLM Day10
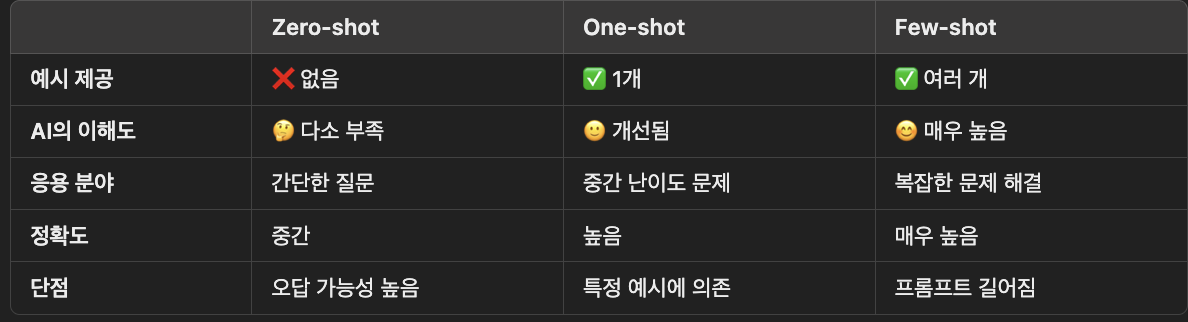
🔍 1. 프롬프트 엔지니어링 개요프롬프트 엔지니어링이란?👉 AI가 우리가 원하는 대로 답변하도록 질문을 효과적으로 설계하는 기술3가지 프롬프팅 기법:1️⃣ Zero-shot 프롬프팅 → 예시 없이 AI에게 바로 질문2️⃣ One-shot 프롬프팅 → 예시를 하나만
10.LLM Day 10 - Ollama

📌 Ollama란?Ollama는 로컬에서 LLM(대형 언어 모델)을 실행할 수 있도록 도와주는 AI 도구쉽게 말해서, 인터넷 없이 내 컴퓨터에서 ChatGPT 같은 AI 모델을 실행할 수 있게 해주는 프로그램🔍 Ollama의 핵심 기능✅ 로컬에서 LLM 실행 → 인
11.LLM Day 11 Chat History 관리

🤖 AI가 사람처럼 대화를 기억하는 방법이에요!우리가 친구와 이야기할 때, 예전에 한 대화를 기억하면 더 자연스럽게 이어갈 수 있죠?AI도 마찬가지로 대화 내용을 저장하고 관리하는 기능이 필요해요.AI가 대화를 주고받는 기본 구조예요!AI는 사용자가 보낸 메시지를
12.LLM Day12
오늘 할 것: 요악, 트리밍 활용하여 대화 히스토리 관리 + 검색할 때 메타데이터 활용hugging face finetuning 한 모델 비추천, open data로 학습되는데, 데이터의 품질이 좋지 못해 본래 모델보다 성능 떨어지는 경우 많음Langchain - t
13.LLM Day 13
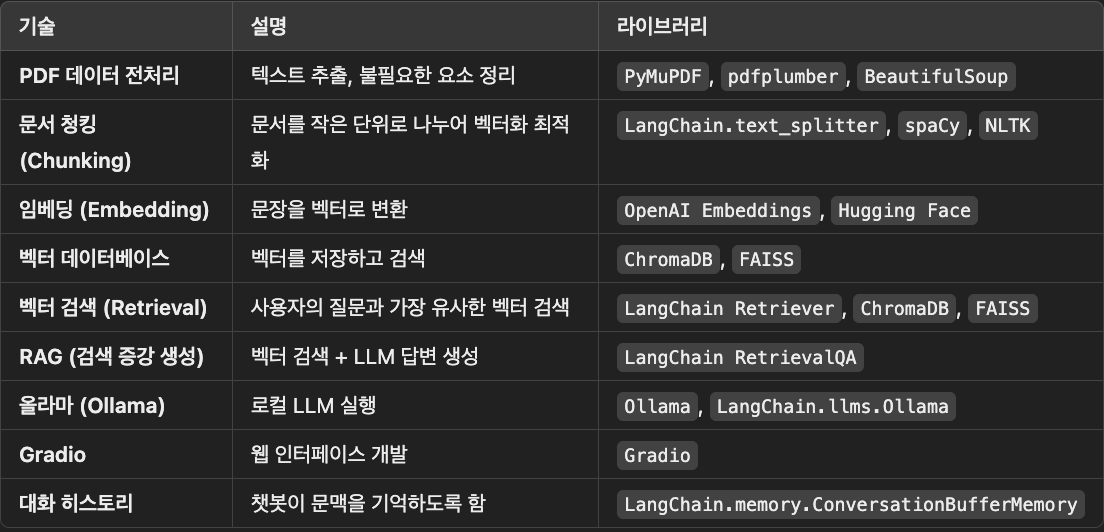
우리 챗봇의 주요 목표는 다음과 같아.PDF 문서에서 정보를 추출하고 전처리(정제 → 청킹 → 임베딩 → 색인화)하는 것OpenAI 임베딩 모델을 사용하여 문서 내용을 벡터로 변환하고 ChromDB(벡터 DB)에 저장하는 것올라마(OLlama) 기반 LLM을 활용하여
14.LLM Day13 - RAG 기반 챗봇+평가모델
이 코드는 RAG (Retrieval-Augmented Generation) 기반 챗봇 시스템을 구현하는 것으로,사용자의 질문을 받아 관련 문서를 검색하고, 신뢰도 점수를 매긴 후 답변을 생성하는 것이 목표다.즉, 단순한 AI 챗봇이 아니라 "근거가 있는 답변"을 제공
15.LLM Day13 - BERT

💡 BERT를 활용해 질문과 문서 내용을 숫자로 변환한 후, 코사인 유사도를 이용해 의미적 유사성을 계산하여 신뢰할 수 있는 문서를 찾는다. 코드에서 BERT 기반 문서와 질문의 유사도 평가는 evaluate_with_bert() 함수에서 수행된다.이 함수는 Sent
16.LLM Day13 - Cosine Similarity
코사인 유사도(Cosine Similarity)는 두 개의 벡터 간 각도를 기반으로 유사도를 측정하는 방법이다. \- 벡터의 크기(길이)는 고려하지 않고, 방향만 비교한다 \- 두 벡터의 각도가 작을수록(= 같은 방향일수록) 유사도가 높음 \- 값의 범
17.LLM Day14 - RAG 성능평가
RAG 시스템이 얼마나 잘 작동하는지 평가하는 방법 배우기RAG는 Retrieval-Augmented Generation의 줄임말로, 쉽게 말하면 "필요한 정보를 먼저 찾고(Retrieval), 그걸 활용해서 답변을 만들어주는(Generation) 시스템"컴퓨터가 정보
18.LLM Day 15 - LLM 평가지표 완벽 가이드

✅ RAG 성능 평가를 위한 핵심 지표 (HitRate, MRR, NDCG) 를 이해한다.✅ 검색 시스템에서 문서 검색의 성능을 평가하는 방법을 익힌다.✅ 검색 결과의 정확성, 순위, 유용성 등을 다각도로 측정하는 지표를 배운다.검색 시스템의 목표는 사용자의 질문(쿼리
19.LLM Day 15 - 데이터셋 품질이 중요한 이유: Fine-Tuning 성능에 미치는 영향
데이터셋 품질이 중요한 이유: Fine-Tuning 성능에 미치는 영향Fine-Tuning을 통해 모델을 학습시키려면 고품질의 데이터셋이 필수입니다.👉 만약 잘못된 데이터(오류, 편향, 노이즈)가 포함되면, 모델은 잘못된 패턴을 학습하게 됩니다.💡 예시 1: 잘못된
20.LLM Day 16 - RAG (Retrieval-Augmented Generation) 시스템의 정량적 평가 지표

Retrieval-Augmented Generation (RAG) 시스템의 정량적 평가 지표를 이해하고, 실제 데이터를 분석하여 성능을 측정하는 방법을 학습합니다.📌 RAG (Retrieval-Augmented Generation) 개념Retrieval (검색): 외
21.LLM Day 17 - Hallucination
인공지능(AI) 기술이 발전함에 따라, AI 시스템이 실제로 존재하지 않거나 사실이 아닌 정보를 마치 사실인 것처럼 생성하는 '환각 현상(Hallucination)'이 주목받고 있습니다. 이러한 현상은 AI의 신뢰성과 정확성에 직접적인 영향을 미치며, 특히 의료, 법률
22.LLM Day 18 - 학습용 데이터에서 개인정보 보호의 중요성
인공지능(AI) 모델을 학습시키기 위해 사용되는 데이터에는 종종 개인정보가 포함될 수 있습니다. 이러한 개인정보를 적절하게 보호하지 않으면 프라이버시 침해, 법적 문제, 신뢰도 저하 등의 심각한 문제가 발생할 수 있습니다. 이번 글에서는 AI 학습 데이터에서 개인정보
23.LLM Day 19 - Claude
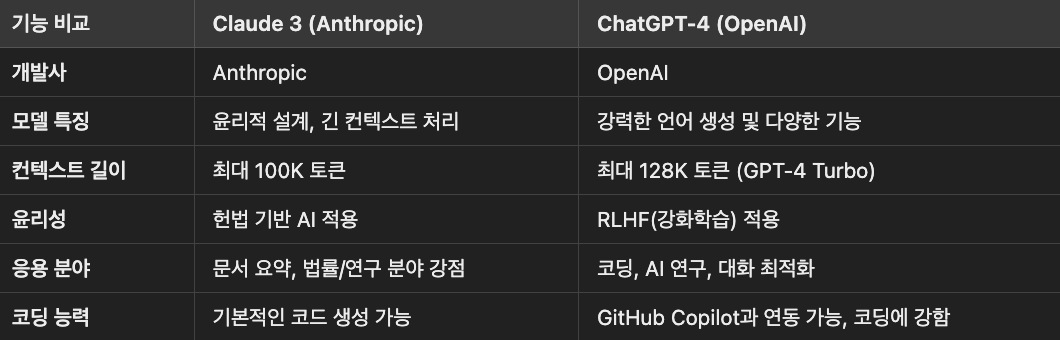
Claude는 Anthropic이라는 AI 연구 기업에서 개발한 대화형 인공지능(Chatbot AI)입니다. OpenAI의 ChatGPT와 비슷한 역할을 하지만, 특정한 윤리적 설계와 보안성을 강조하는 것이 특징입니다.✔️ 개발사: AnthropicClaude는 Ope
24.LLM Day 19 - RAG와 데이터
RAG(Retrieval-Augmented Generation)는 대규모 언어 모델(LLM)의 한계를 보완하기 위해 외부 데이터 소스를 활용하는 기술입니다. 이를 통해 모델이 최신 정보나 특정 도메인 지식을 반영하여 더 정확하고 관련성 높은 응답을 생성할 수 있습니다.
25.LLM Day 20 - Evaluation of Retrieval-Augmented Generation
논문 링크Retrieval-Augmented Generation (RAG)은 LLM(대규모 언어 모델)의 성능을 외부 정보 검색을 통해 향상시키는 기술. 기존 LLM이 사실과 다를 수 있는 응답을 생성하는 문제(환각, Hallucination)를 해결하기 위해 등장.
26.LLM Day21 - SQL QA

SQL 기반 Q&A 시스템은 구조화된 데이터(데이터베이스)를 활용해 사용자의 자연어 질문을 SQL 쿼리로 변환하고, 그 결과를 다시 자연어로 답변하는 시스템입니다.즉, 사용자가 “현재 가장 비싼 ETF는 뭐야?” 같은 질문을 하면:자연어 질문을 SQL 쿼리로 변환 →
27.LLM Day 22 - Text-to-SQL RAG 시스템 구현
ETF 데이터를 활용한 Text-to-SQL 및 RAG (Retrieval-Augmented Generation) 시스템 구현 과정을 다룹니다.✅ 핵심 개념 정리✅ 코드 설명 (데이터 처리, SQL 실행, LangChain 활용 등)✅ Text-to-SQL 변환 및 R
28.LLM Day 29 - Tool Calling

Tool Calling은 LLM(대형 언어 모델, Large Language Model)이 외부 시스템과 상호작용할 수 있도록 하는 함수 호출 기능이에요. 쉽게 말해, LLM이 단순히 텍스트만 생성하는 것이 아니라, 외부 API나 데이터베이스와 같은 시스템과 직접 연결
29.LLM Day 30 - Database Tool

LLM이 외부 시스템과 상호작용할 수 있도록 해주는 Tool Calling은 다양한 도구를 활용할 수 있어요. 그중에서도 Database Tool을 사용하면, LLM이 데이터베이스에서 직접 정보를 조회하고, 추가하거나, 수정, 삭제하는 작업까지 수행할 수 있어요.Dat
30.LLM Day 31 - LangGraph 활용 - 상태 그래프(StateGraph)

LangGraph는 상태 기반 그래프(StateGraph) 구조를 활용하여 대화 흐름을 체계적으로 관리하는 데 사용됩니다. 쉽게 말해, 챗봇이나 복잡한 데이터 흐름을 제어하기 위한 "노드(Node)와 엣지(Edge)를 활용한 시스템" 입니다.StateGraph는 "상태
31.LLM Day 32 - Adaptive RAG
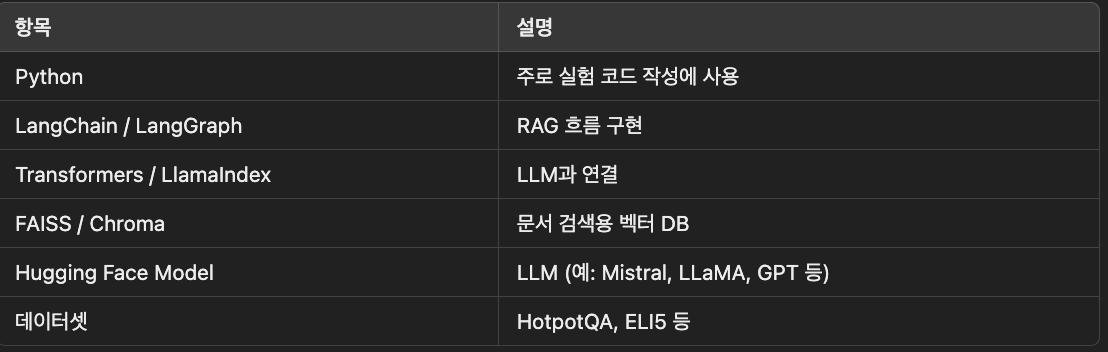
📚 뜻: "검색이랑 글쓰기(생성)를 같이 하는 똑똑한 챗봇 방법"🔍 예시: 질문하면, 먼저 구글처럼 자료를 검색해서 그걸 바탕으로 대답을 만들어주는 방식.🤖 챗봇이 모르는 걸 뇌에서 꺼내는 게 아니라, 찾아보고 알려줘!🎛️ 뜻: "질문에 맞춰 가장 똑똑한 방법을
32.LLM Day 33 - Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
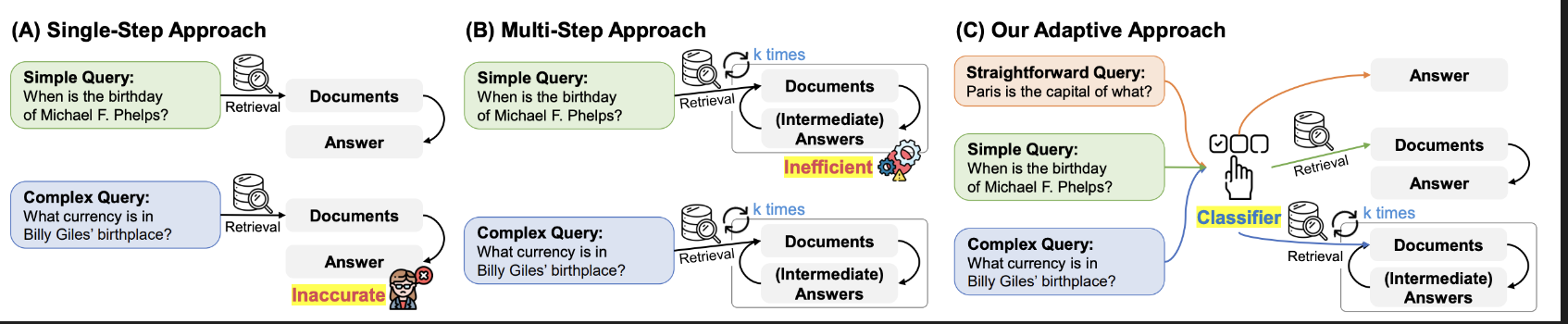
🔍 이 논문 실습 전에 알아야 할 것들✅ 1. RAG 구조 이해RAG는 "검색(Retrieval)" + "생성(Generation)"을 합친 구조야.모델이 답을 만들 때, 먼저 관련 정보를 외부 지식에서 검색해서 사용해.📚 예비 지식:어떻게 문서를 검색하고,그걸 L
33.LLM - Day34 Runpod

https://github.com/unslothai/unsloth RunPod 개요 RunPod는 사용자가 저렴하고 유연하게 GPU 인스턴스를 사용할 수 있도록 지원하는 GPU 클라우드 인프라 서비스다. 특히 딥러닝 모델 학습, 추론, 배치 서비스를 위한 최적화된 환
34.LLM Day 35 - Unsloth finetuning
ETF 데이터로 LLM 파인튜닝하기 (Unsloth 활용)데이터 품질: 더 많은 ETF 데이터와 다양한 질문-답변 쌍을 추가하면 모델 성능이 향상됩니다.하이퍼파라미터 튜닝: LoRA 랭크(r), 학습률, 배치 크기 등을 조정하여 최적의 성능을 찾으세요.평가 지표: 파인