🎯 학습 목표
✅ RAG 성능 평가를 위한 핵심 지표 (HitRate, MRR, NDCG) 를 이해한다.
✅ 검색 시스템에서 문서 검색의 성능을 평가하는 방법을 익힌다.
✅ 검색 결과의 정확성, 순위, 유용성 등을 다각도로 측정하는 지표를 배운다.
📌 1. 정보 검색 평가란?
검색 시스템의 목표는 사용자의 질문(쿼리)에 대해 가장 관련성이 높은 문서를 찾는 것이에요.
하지만 검색 시스템이 정말 잘 작동하는지 어떻게 알 수 있을까요? 🤔
👉 검색된 문서가 정확한지? (Hit Rate)
👉 정확한 문서가 상위에 나왔는지? (MRR)
👉 검색된 문서 전체가 얼마나 유용한지? (NDCG)
이러한 질문에 답하기 위해 검색 성능 평가 지표를 사용합니다! 🎯
📊 2. 검색 성능 평가 지표
검색 시스템의 성능을 평가하기 위해 크게 두 가지 접근법이 있어요.
✅ 1) 검색 성능 평가 (Retrieval Evaluation)
🔹 검색된 문서가 정확한지, 순위가 적절한지를 평가
🔹 예시: Hit Rate, Precision, Recall, MRR, NDCG
✅ 2) 생성 성능 평가 (Generation Evaluation)
🔹 검색된 문서를 바탕으로 LLM이 생성한 답변이 좋은지 평가
🔹 예시: ROUGE, BLEU, BertScore
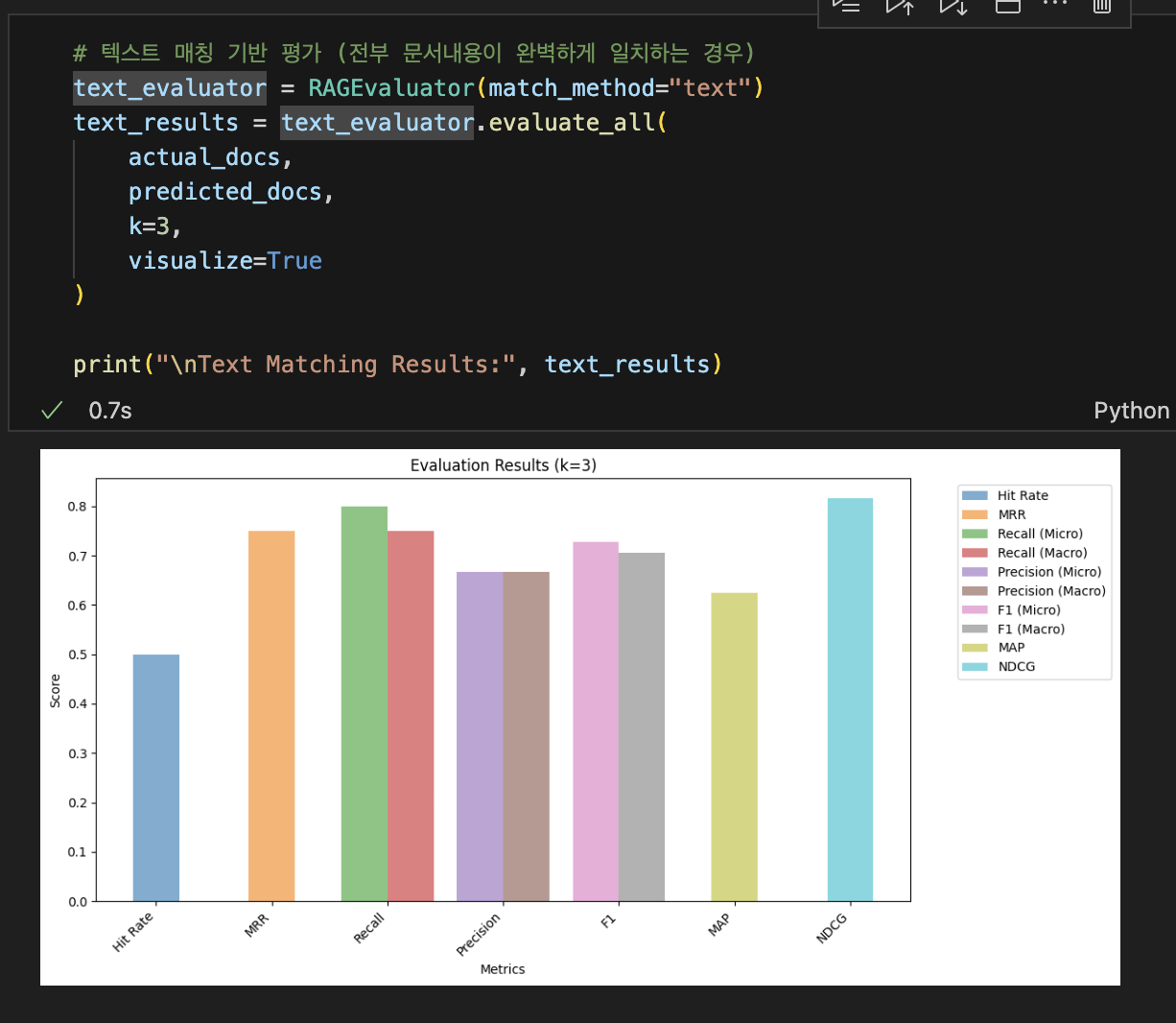
🏆 3. 검색 성능 평가 지표 (Retrieval Metrics)
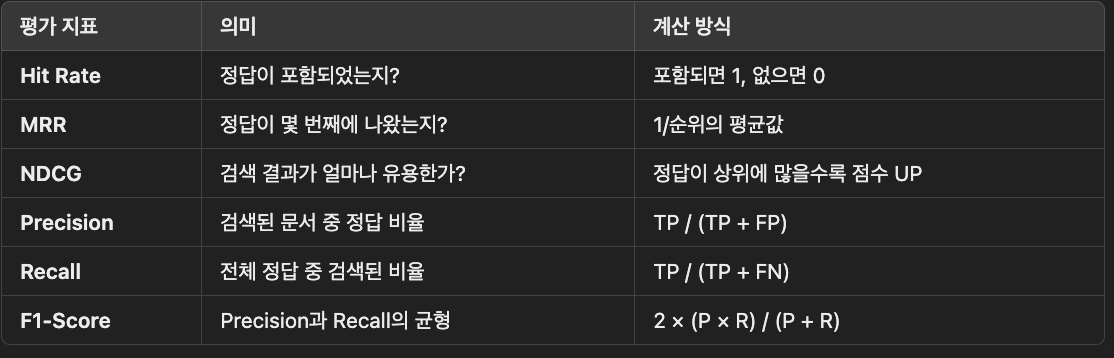
🔹 1) Hit Rate (적중률) - 정답이 검색 결과에 포함되었나요? 🎯
📌 개념:
✅ 검색된 문서 중에 정답이 포함되어 있는지 평가
✅ 정답이 하나라도 포함되어 있으면 Hit! (1점)
✅ 정답이 전혀 없으면 Miss! (0점)
📌 계산 공식:

📌 예제:

💡 정답이 포함된 쿼리 개수 / 전체 쿼리 개수 = Hit Rate!
🔹 2) MRR (Mean Reciprocal Rank) - 정답이 몇 번째에 나왔나요? ⏳
📌 개념:
✅ 검색 결과에서 첫 번째로 등장하는 정답의 순위를 평가
✅ 정답이 위쪽에 있을수록 좋은 검색 결과!
📌 계산 공식:
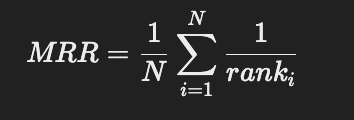
📌 예제:

💡 MRR = (1/순위)의 평균값!
🔹 3) NDCG (순위 정규화된 누적 이득) - 검색 결과가 얼마나 유용한가요? ⭐️
📌 개념:
✅ 검색된 문서가 얼마나 유용한 순서로 정렬되었는지 평가
✅ 정답이 순위가 높을수록 점수가 높아짐
✅ 검색 결과를 이상적인 순위와 비교하여 정규화
📌 계산 공식:
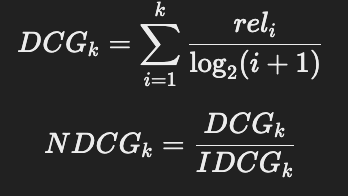
📌 예제:

💡 NDCG는 검색 결과가 얼마나 좋은 순서로 정렬되었는지를 평가!
⚡ 4. Precision, Recall, F1-Score 계산
🔹 1) Precision (정밀도)
✅ 검색된 문서 중에서 실제 정답인 문서의 비율
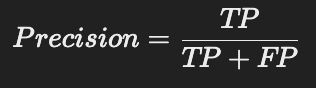
🔹 2) Recall (재현율)
✅ 전체 정답 문서 중에서 검색된 문서의 비율
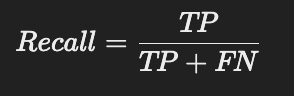
🔹 3) F1-Score
✅ Precision과 Recall의 조화 평균

💡 정확한 문서를 많이 찾는 것이 중요! (Precision) → 하지만 놓치면 안 됨! (Recall) → 둘을 균형 있게 평가 (F1-Score)!
🚀 5. TP, FP, FN 계산 코드
# True Positive (TP) 계산
test_true_positives = [
doc.page_content for doc in predicted_context if doc.page_content in test_context
]
print(f"✅ True Positives: {len(test_true_positives)}개 문서")
# False Positive (FP) 계산
test_false_positives = [
doc.page_content for doc in predicted_context if doc.page_content not in test_context
]
print(f"🚨 False Positives: {len(test_false_positives)}개 문서")
# False Negative (FN) 계산
test_false_negatives = [
doc for doc in test_context if doc not in [pred.page_content for pred in predicted_context]
]
print(f"⚠️ False Negatives: {len(test_false_negatives)}개 문서")
🎯 6. 전체 요약
🎯 7. 검색 성능을 높이려면?
✅ 정확한 문서를 많이 찾아야 함! (Precision)
✅ 사용자가 원하는 정답을 빠르게 찾아야 함! (MRR)
✅ 검색 결과 전체가 유용해야 함! (NDCG)
