연결리스트 2
앞서 구현한 연결리스트는 배열을 활용한 연결리스트이다
배열을 통해 만드는 리스트는 좋긴 하지만 명확하게 단점이 있다.
배열의 메모리 특성이 정적이기 때문에 메모리 길이를 변경하는 것이 불가능하다.
아래 예제는 배열의 단점을 잘 보여주는 예제 코드이다.
연결리스트: 배열
#include <stdio.h>
int main()
{
int arr[10];
int readCount = 0;
int readData;
int i;
while (1)
{
printf("자연수 입력 : ");
scanf("%d", &readData);
if (readData < 1)
{
break;
}
arr[readCount++] = readData;
}
for (i = 0; i < readCount; i++)
{
printf("%d ", arr[i]);
}
return 0;
}연결리스트: 배열 결과
자연수 입력 : 1
자연수 입력 : 2
자연수 입력 : 3
자연수 입력 : 4
자연수 입력 : 5
자연수 입력 : 0
1 2 3 4 5 정적인 배열은 메모리의 크기에 유연하게 대처하지 못하는 문제, 단점이 존재한다.
그런 문제를 해결하기 위해 메모리를 동적으로 할당해 구성하는 방법을 사용할 수 있다.
메모리를 동적으로 구성하기 위해서는 기본적으로 malloc, free 함수를 사용할 줄 알아야 한다
연결리스트: 메모리 동적 할당
#include <stdio.h>
#include <stdlib.h>
typedef struct _node
{
int data;
struct _node *next;
} Node;
int main()
{
Node *head;
Node *tail;
Node *cur;
Node *newNode = NULL;
int readData;
// 데이터를 입력 받는 과정
while (1)
{
printf("자연수 입력 : ");
scanf("%d", &readData);
if (readData < 1)
{
break;
}
// 노드의 추가과정
newNode = (Node *)malloc(sizeof(Node));
newNode->data = readData;
newNode->next = NULL;
if (head == NULL)
{
head = newNode;
}
else
{
tail->next = newNode;
}
tail = newNode;
}
printf("\n");
// 입력 받은 데이터의 출력과정
printf("입력 받은 데이터의 전체출력! \n");
if (head == NULL)
{
printf("저장된 자연수가 존재하지 않습니다. \n");
}
else
{
cur = head;
printf("%d ", cur->data);
while (cur->next != NULL)
{
cur = cur->next;
printf("%d ", cur->data);
}
}
printf("\n");
// 메모리의 해제과정
if (head == NULL)
{
return 0;
}
else
{
Node *delNode = head;
Node *delNextNode = head->next;
printf("%d을(를) 삭제합니다. \n", head->data);
free(delNode);
while (delNextNode != NULL)
{
delNode = delNextNode;
delNextNode = delNextNode->next;
printf("%d을(를) 삭제합니다. \n", delNode->data);
free(delNode);
}
}
return 0;
}연결리스트: 동적할당 결과
자연수 입력 : 2
자연수 입력 : 4
자연수 입력 : 6
자연수 입력 : 8
자연수 입력 : 0
입력 받은 데이터의 전체출력!
2 4 6 8
2을(를) 삭제합니다.
4을(를) 삭제합니다.
6을(를) 삭제합니다.
8을(를) 삭제합니다.동적 할당 코드 이해하기
메모리를 동적으로 할당해 연결하는 리스트는 그림으로 이해하는 것이 아주 편하다
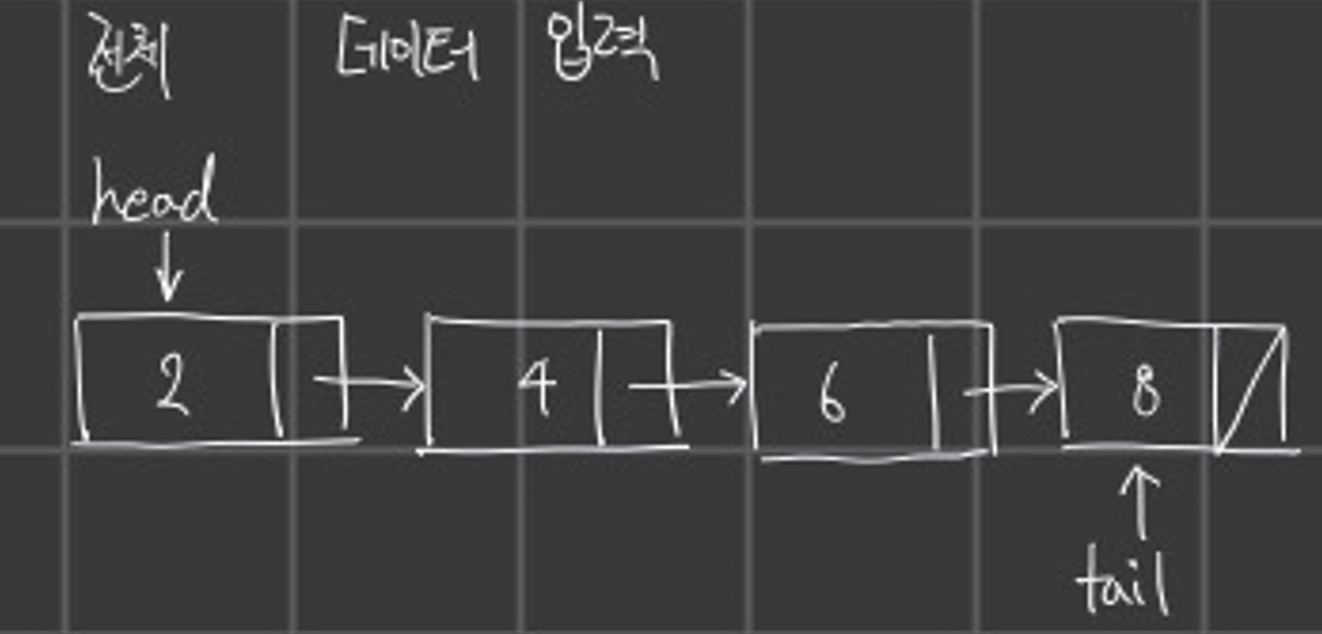
일단 기본적으로 완성된 연결리스트는 아래 그림과 같은 형태를 이루고 있다
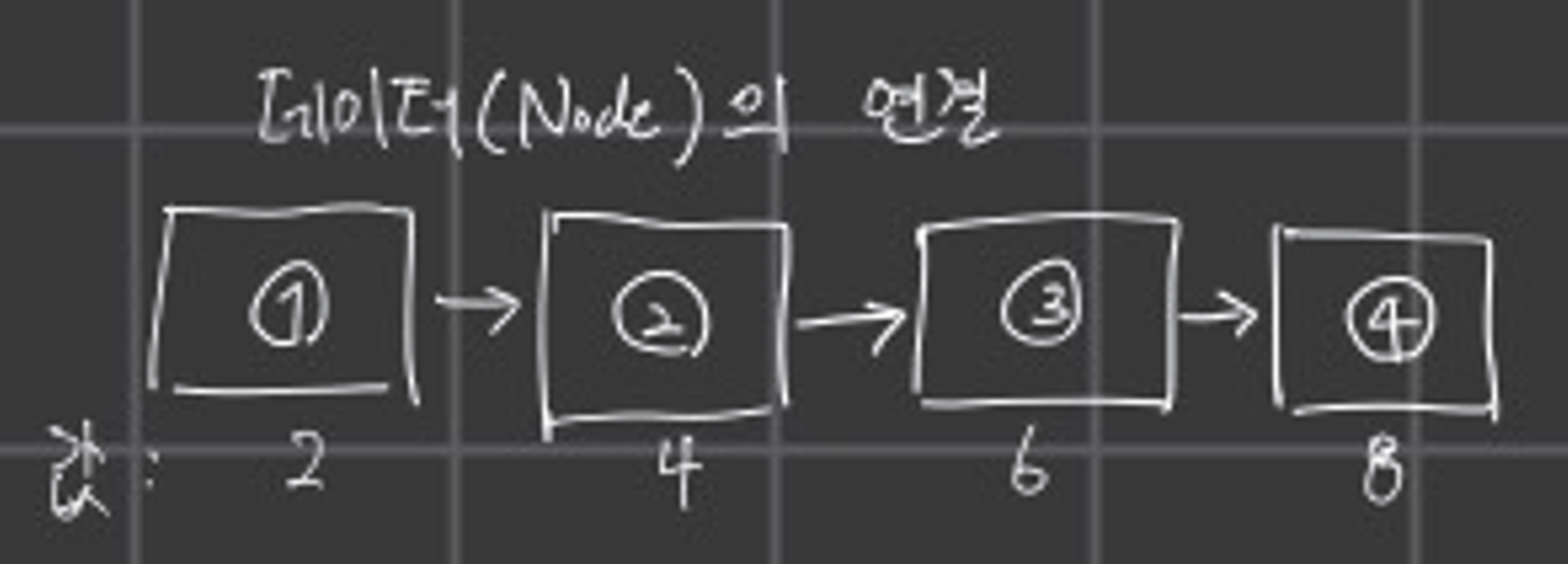
위 그림을 보면 각 박스에 데이터를 담고 각 박스를 연결한 형태이다
위 형태를 다음과 같이 표현할 수 있다.
필요할 때 마다 상자인 구조체 변수를 동적 할당해 생성하고 이들을 연결한다.
위 각 데이터들은 Node(노드)라고 지칭한다.
Node를 이해하기 쉽게 다음과 같이 표현한다.
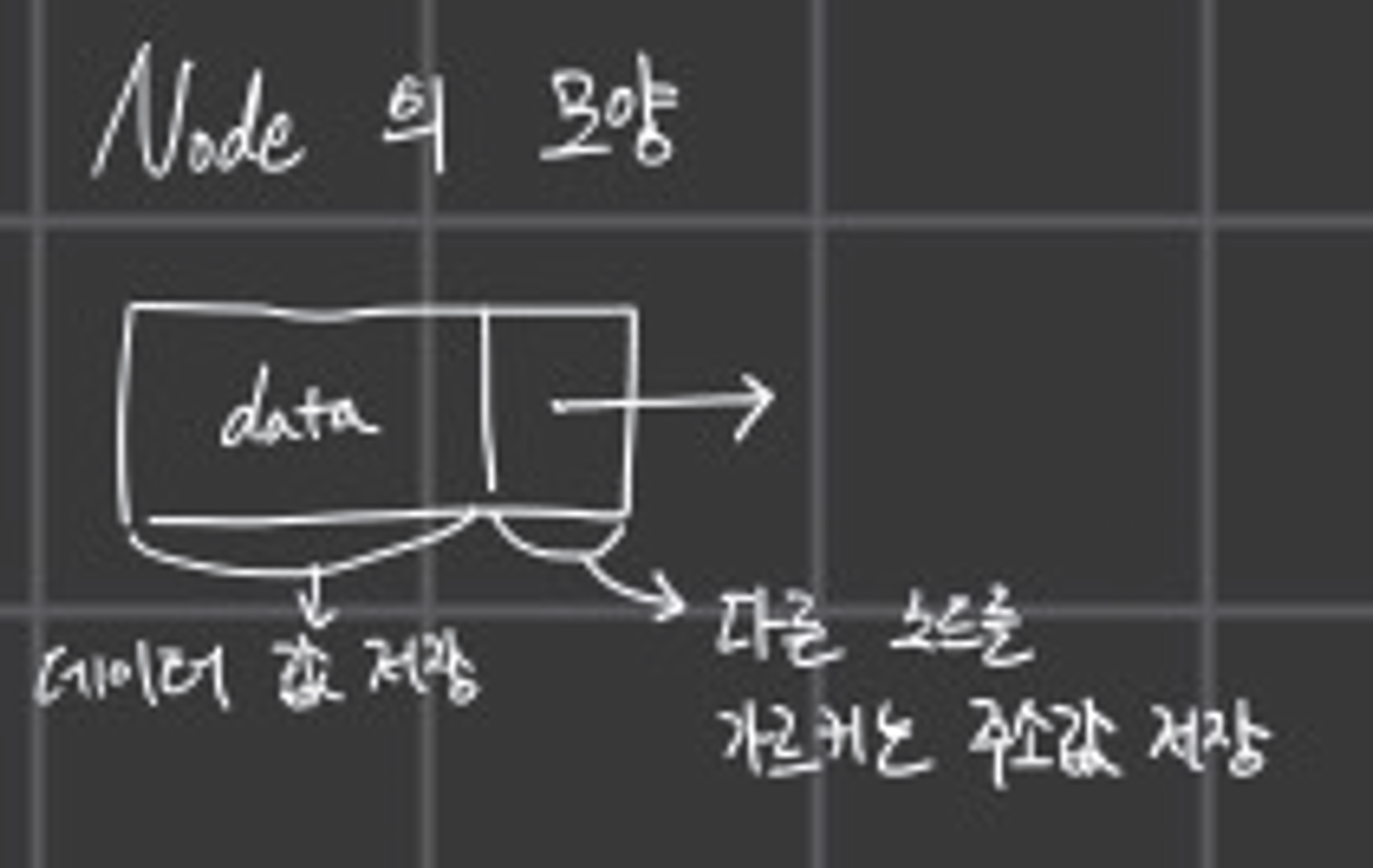
노드는 데이터 값을 저장하는 장소, 다른 노드 주소값을 저장하는 장소로 나눠져있다.
노드를 여러개 생성해 연결하면 아래와 같이 표현할 수 있다.
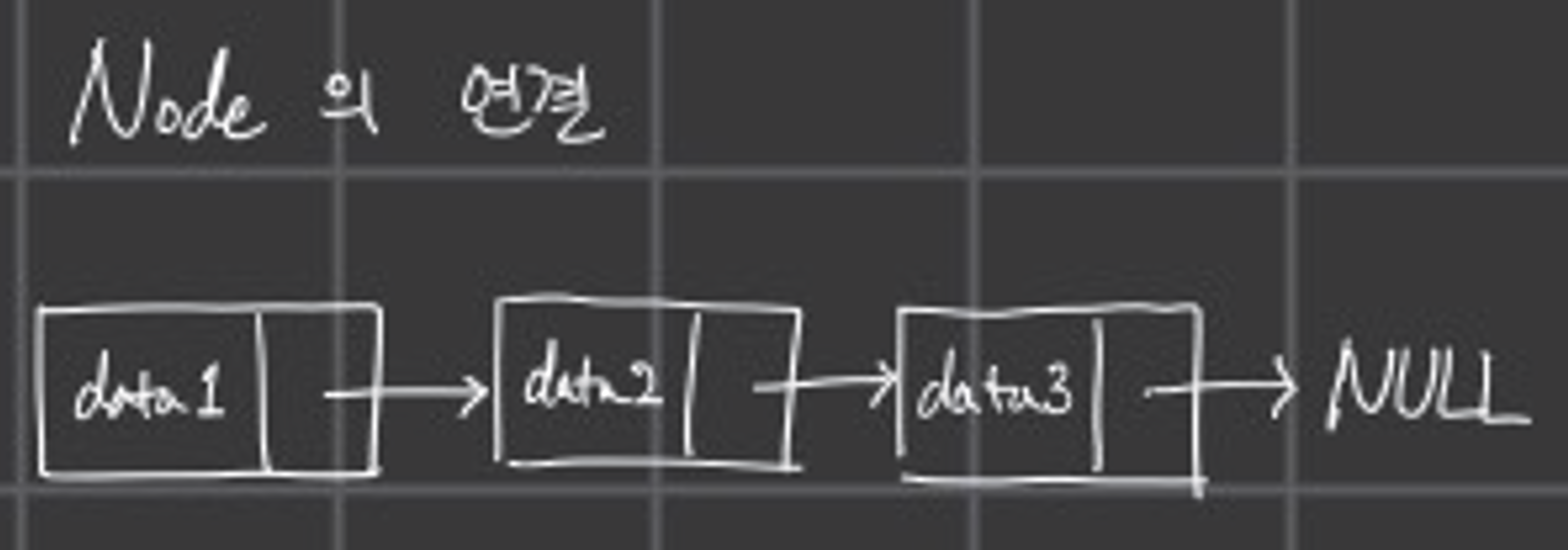
데이터 입력
데이터를 입력하기 전 먼저 해줘야 할 것이 데이터 초기화이다.
코드를 보면 제일 처음으로 Node 구조체 변수로 선언해준 head,tail,cur이 있다.
이 값들을 NULL 값으로 초기화 시켜준다.
이후 첫 번째 데이터를 입력하면
if (head == NULL) {
head = newNode;
} else {
...
}
tail = newNode;위 코드를 인해 head가 널 값이므로 새로운 데이터에 head는 newNode를 가르키고, 마지막에 tail = newNode로 tail도 newNode를 가르킨다.
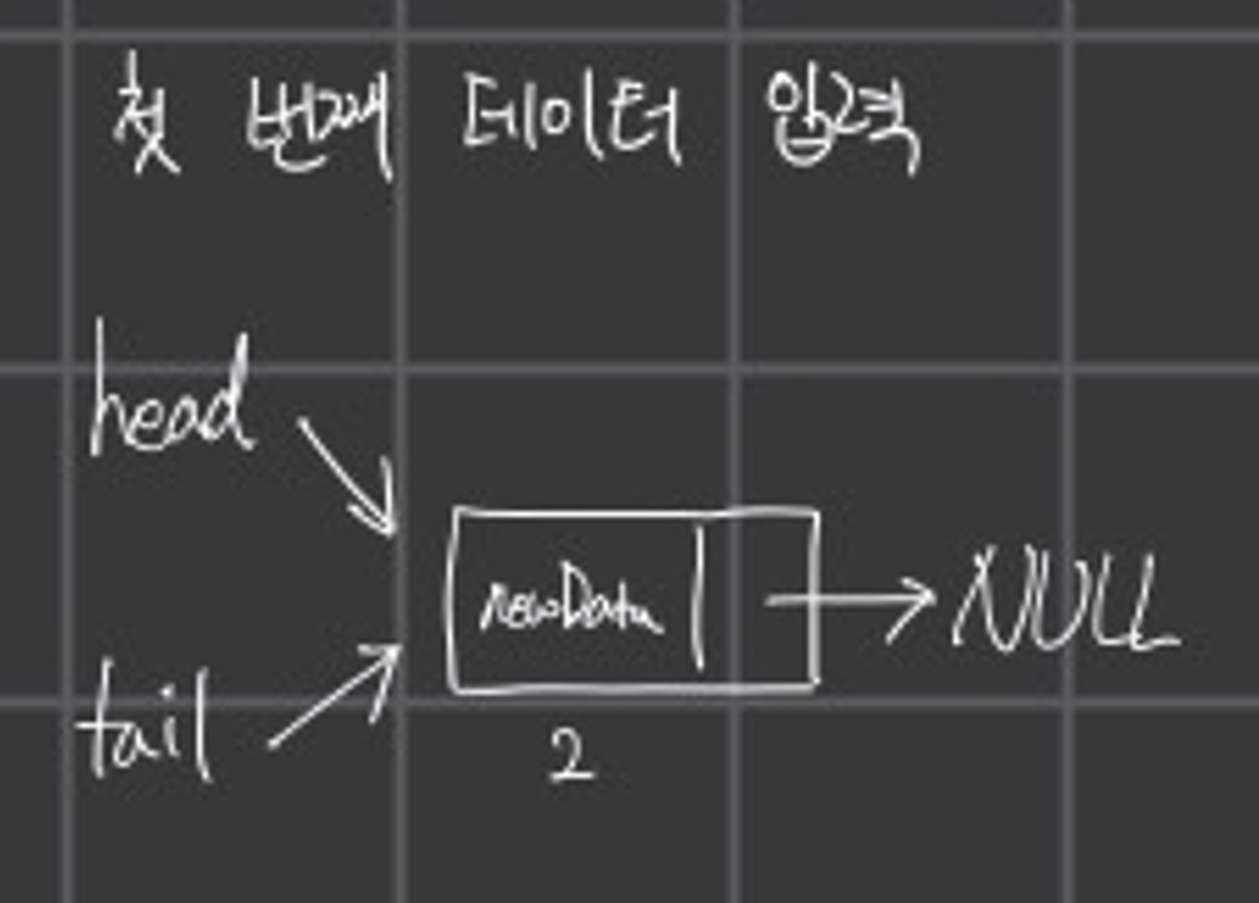
이후 두 번째 데이터를 입력하면,
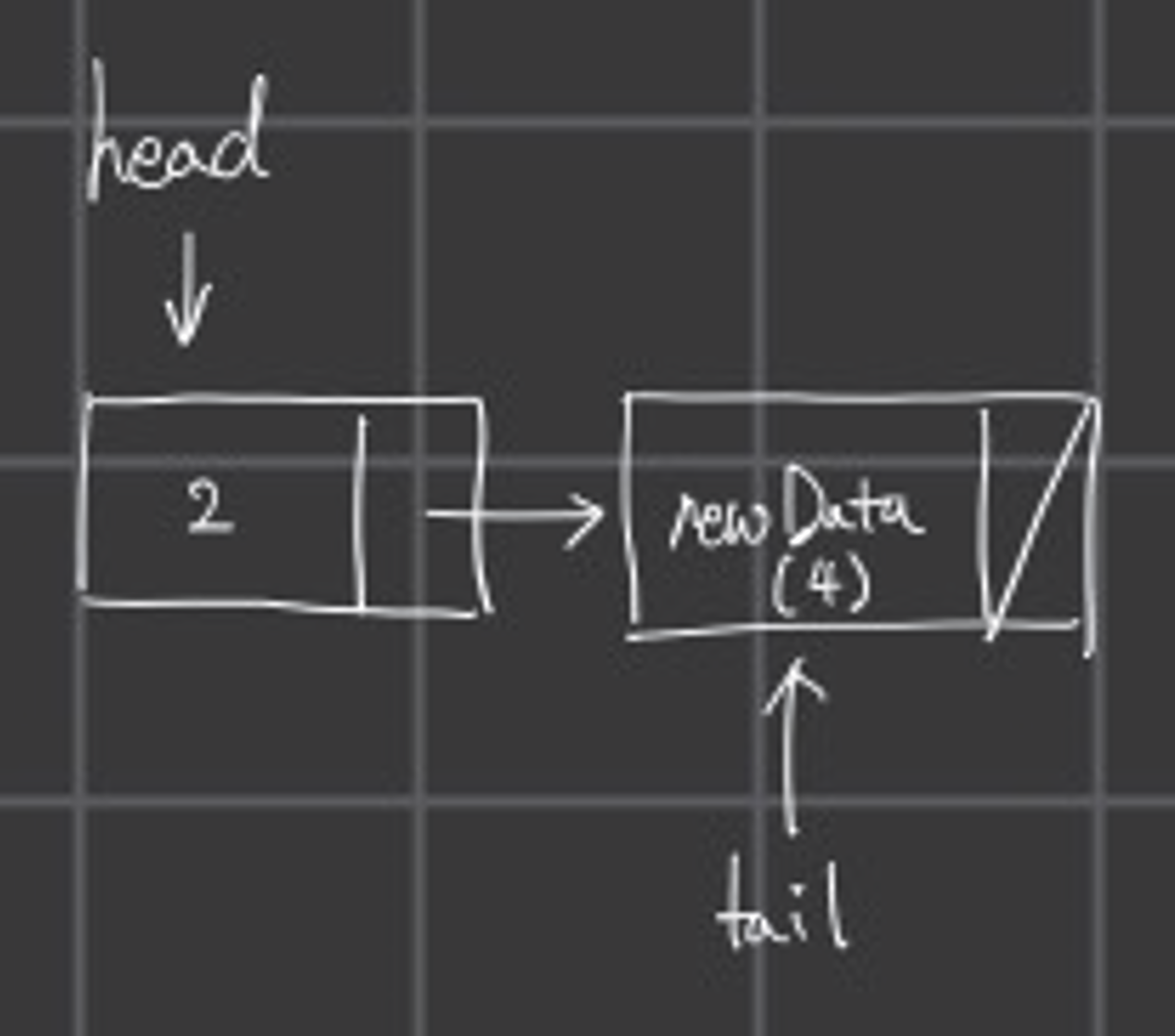
위 사진과 같은 방식으로 head는 그대로 첫 번째 노드를 가르키고 있고, tail이 새로 들어온 데이터를 가르키게 된다.
데이터 조회
위 입력 과정을 통해 데이터가 모두 입력됐다고 가정한다면, 조회는 아주 간단하게 구현할 수 있다.
...
} else {
cur = head;
printf(...);
while(cur->next != NULL) {
cur = cur->next;
printf(...);
}
}cur을 첫 번째 노드(head)를 가르키게 한다.
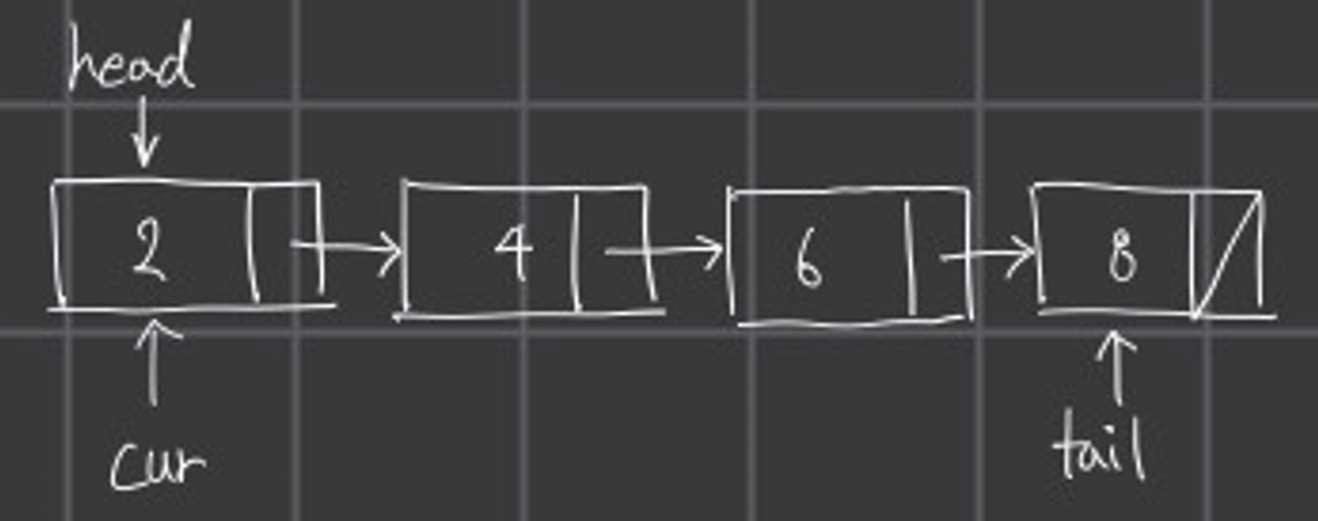
그리고 cur->next != NULL 연결된 노드가 존재한다면 다음 노드로 cur을 이동시킨다.
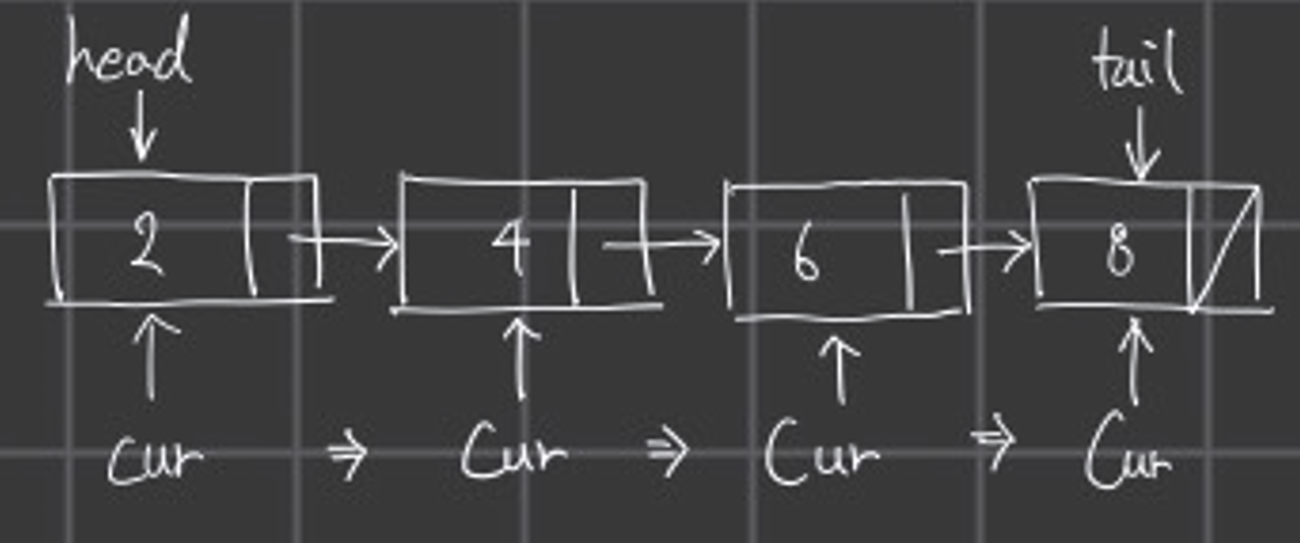
위 그림과 같이 이동하면서 조회를 진행하게 된다.
데이터 삭제
데이터를 삭제할 때는 새로운 노드를 선언하고 이를 활용한다.
Node * delNode = head;
Node * delNextNode = head->next;처음 코드가 선언됐을 때 그림은 아래와 같다.
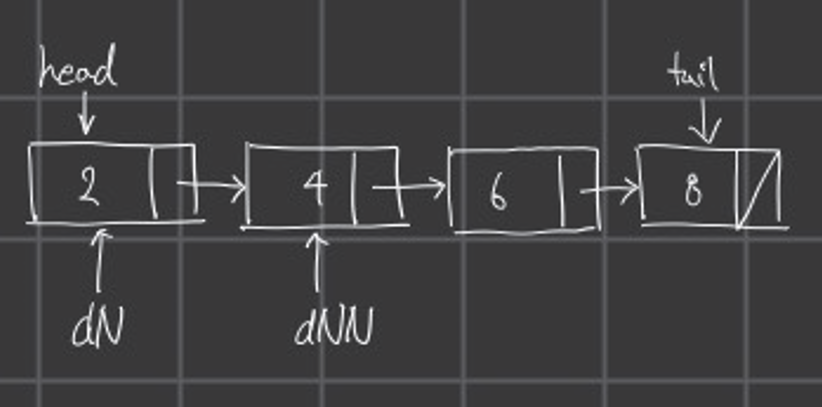
위 그림은 약어로 표현하였다. (dN : delNode, dNN : delNextNode)
dN만 선언한 것이 아니라 dNN까지 두 개의 변수를 선언한 이유는 처음 head를 삭제할 때
dN만 있다면 head를 삭제하고 난 이후에 주소가 저장된 값까지 함께 삭제되기 때문에 이후 다른 노드에 접근이 불가능하다.
그런 문제로 인해 변수를 두 개 선언해준다.
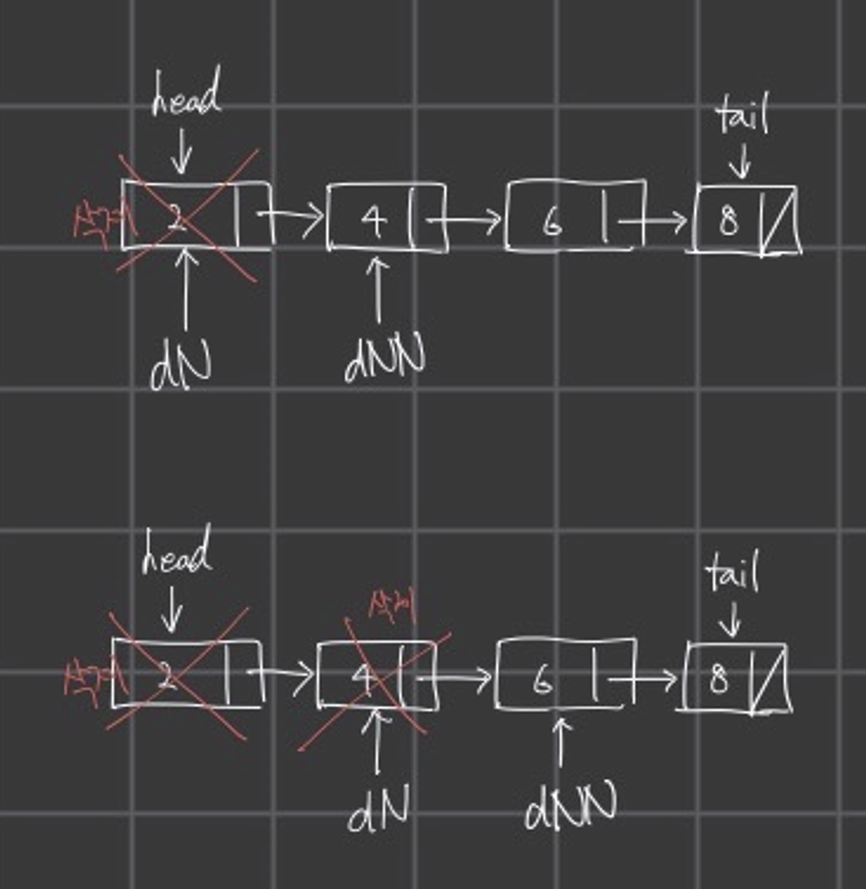
그럼 삭제되는 과정은 위 그림과 같다.
삭제할 때 가장 중요한 부분은 free(delNode)로 메모리 할당을 해제해주는 것이 가장 중요하다.
이제 연결리스트의 기초에 대해서 전체적으로 살펴봤다.
위 예제가 완벽한 연결리스트는 아니다 하지만 연결리스트를 이해하기에는 아주 좋은 예제이다.
