✏️ 지도학습의 개념과 대표 알고리즘
✏️ 1. 지도학습
지도학습(Supervised Learning)이란, 정답 레이블 정보를 활용해 알고리즘을 학습하는 방법론이다. 이 방법은 데이터와 정답인 레이블 사이의 관계를 파악하는 것을 목적으로 한다.
특징 및 장점
- 정답 존재: 정답이 존재하므로 모델이 풀어야 하는 문제가 비교적 쉽고 잘 학습된다.
- 평가 수치: 명확한 평가 수치가 존재하여 학습된 모델의 성능을 쉽게 측정할 수 있다.
단점
- 추가 비용: 정답이 필요하므로 이를 위해 추가적인 시간, 노동, 비용이 필요하다.
- 전문 인력 필요: 정답을 매기는 행위에 필요한 전문인력과 같은 추가 비용이 발생한다.
✏️ 2. 문제(Task)와 대표적인 문제 유형
문제(Task)란?
문제란, 머신러닝 기법을 활용해 해결하고자 하는 대상으로 데이터를 통해 얻고자 하는 특정 목표나 결과를 의미한다. 이는 우리가 학창 시절 풀었던 여러 문제와 비슷하게, 머신러닝에서도 데이터를 통해 해결하고자 하는 목표나 결과를 문제라고 한다.
대표적인 문제 유형
-
회귀 문제(Regression problem)
- 정의: 주어진 입력 데이터에 대해 연속적인 숫자 값을 예측하는 문제.
- 예시:
- 내일 주식 가격은? 53,228.3 원
- 5년 뒤 나의 몸무게는? 73.2 kg
- 설명: 회귀 문제는 주관식 문제와 비슷하며, 입력 데이터를 바탕으로 정확한 숫자 형태의 결과를 예측하는 것이다. 정확한 숫자는 정수 혹은 실수 범위의 수이다.
-
분류 문제(Classification problem)
- 정의: 주어진 입력 데이터가 어떤 범주(클래스)에 속하는지를 판별하는 문제.
- 예시:
- 이메일이 스팸인가 아닌가?
- 고양이 사진을 보고 '동물', '포유류'로 분류
- 설명: 분류 문제는 5지선다형 객관식 문제와 비슷하다. 입력으로 주어진 데이터를 정해진 보기 중 하나로 분류하는 문제로, 보기를 클래스(
Class)라고 한다.
회귀 문제와 분류 문제 비교
- 회귀: 정확한 숫자 값을 찾는 문제
- 예: 내일 온도를 예측한다면 회귀 문제
- 분류: 보기 중 선택의 문제
- 예: 내일 날씨를 예측한다면 분류 문제 (맑음, 비, 흐림, 눈 중 택 1)
✏️ 3. 데이터 분할: 학습 / 검증 / 평가
머신러닝에서 모델을 학습시키고 평가하기 위해 데이터를 세 부분으로 나누어 사용한다.

학습 데이터(Train Data)
- 정의: 순수하게 학습을 하는 과정에서 사용하는 데이터.
- 비율: 전체 데이터 중 약 80% 정도를 할당.
- 설명: 이 데이터는 모델이 패턴을 학습하는 데 사용된다. 학습 데이터가 많을수록 모델의 성능이 좋아질 가능성이 크다.
검증 데이터(Validation Data)
- 정의: 학습을 진행하는 중간과정에서 모델이 어느 정도 학습되었는지 주기적으로 확인하는 데 사용하는 데이터.
- 비율: 전체 데이터 중 약 10% 정도를 할당.
- 설명: 검증 데이터는 학습 중간에 진행되는 평가라고 생각할 수 있다. 이는 모의고사를 통해 전체 시험 범위 중 부족한 단원을 찾는 것과 같으며, 학습의 정도를 판단할 수 있다.
평가 데이터(Test Data)
- 정의: 학습 과정과는 별도로, 최후의 머신러닝 모델이 생성된 후 학습한 모델의 최종 성능을 평가하기 위해 사용하는 데이터.
- 비율: 전체 데이터 중 약 10% 정도를 할당.
- 설명: 평가 데이터는 학습 과정에서는 절대 사용되지 않는다. 이는 완성된 머신러닝 모델이 서비스 혹은 제품과 같이 실제 사용 시나리오에서 보게 될 데이터라는 가정으로 만들어진다.
✏️ 4. 과적합(Overfitting)
과적합이란, 머신러닝 모델이 특정 훈련 데이터에 지나치게 학습되어 새로운 데이터나 테스트 데이터에서 잘 작동하지 않는 상태를 의미한다. 이를 일반화 능력(generalization)이 떨어진 상태라고 표현하며, 이는 모델이 학습 데이터에 포함된 특정 패턴이나 디테일, 그리고 작은 노이즈까지 학습하여 데이터를 단순히 외워버린 경우를 말한다.
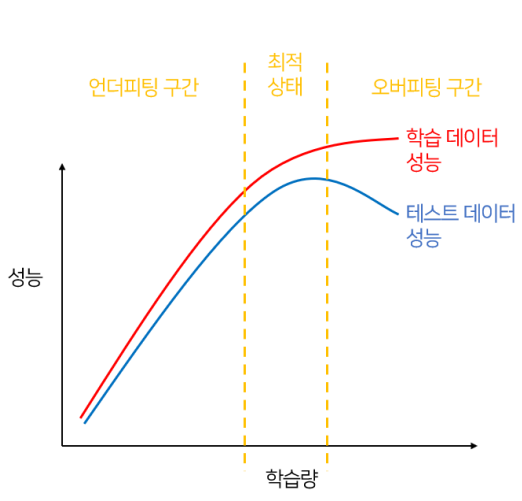
과적합 방지 방법
- 데이터 양 늘리기: 더 많은 데이터를 사용하여 학습.
- 모델의 복잡도 줄이기: 모델의 복잡성을 줄여 단순화.
- 정규화 기법 사용하기: 규제와 같은 정규화 기법을 사용하여 과적합을 방지.
✏️ 5. 손실 함수(Loss Function)
손실 함수란, 머신러닝 모델이 얼마나 잘하고 있는지 또는 못하고 있는지를 수치화한 손실(Loss)을 구하는 함수이다. 이는 모델의 예측값과 실제 정답 사이의 차이를 측정하는 지표로, 일반적으로 손실이 작을수록 모델의 성능이 좋다고 볼 수 있다.
손실 함수의 종류
- 회귀 문제: 평균제곱오차(
Mean Squared Error) - 분류 문제: 교차 엔트로피(
Cross Entropy)- 이진 분류 문제: 로그 손실(
Log Loss)
- 이진 분류 문제: 로그 손실(
✏️ 6. 파라미터(Parameter)와 최적화(Optimization)
파라미터(Parameter)
- 정의: 머신러닝 모델이 내부적으로 갖고 있는 변수.
- 설명: 이 변수는 모델이 데이터로부터 학습하는 패턴과 관계를 표현하며 모델의 예측 성능에 직접적인 영향을 미친다. 파라미터의 구조와 조합은 모델마다 다양하며, 이 변수의 값은 학습 과정을 통해 찾아야 한다.
최적화(Optimization)
- 정의: 머신러닝에서 모델의 성능을 최대화하거나 오류를 최소화하기 위해 모델의 파라미터를 조절하는 과정.
- 목표: 손실 값이 최소가 되는 파라미터를 찾는 것.
- 방법: 최적화 적용 과정은 모델마다 상이할 수 있으며, 최적의 해를 한 번에 구하는 경우와 점진적이고 반복적으로 해를 구하는 경우가 있다.
✏️ 7. 대표 알고리즘
분류 문제 알고리즘
- 로지스틱 회귀(
Logistic Regression)- 이진 분류 문제에 적합한 구조.
- 확률을 직접 예측하는 확률 추정 접근으로 결과를 예측.
- 결정 트리 분류기(
Decision Tree Classifier)- 데이터를 잘 분할하는 결정 트리를 사용하여 분류를 수행.
- 직관적이고 이해가 쉬움.
- 랜덤 포레스트(
Random Forest)- 여러 결정 트리의 결합으로 앙상블 기법에 해당.
- 높은 정확도를 보이면서도 과적합 문제를 방지함.
- 서포트 벡터 머신(
Support Vector Machine, SVM)- 데이터를 최적으로 분리하는 결정 경계를 찾는 데 강력한 알고리즘.
- 어려운 형태의 데이터라도 비선형 계산이 가능한 다양한 커널 트릭으로 해를 구할 수 있음.
회귀 문제 알고리즘
- 선형 회귀(
Linear Regression)- 기본적이고 널리 사용되는 회귀 알고리즘.
- 독립변수와 종속변수 간의 선형 관계를 모델링.
- 라쏘 회귀 혹은 릿지 회귀(
Lasso & Ridge Regression)- 규제 기법을 이용해 과적합을 방지하고 일반화 성능이 향상된 선형 모델.
- 결정 트리 회귀(
Decision Tree Regression)- 결정 트리를 이용해 회귀 문제에 적용.
- 서포트 벡터 회귀(
Support Vector Regression, SVR)- 분류 모델인 SVM을 회귀에 적용한 알고리즘.
- K-최근접 이웃 회귀(
K-Nearest Neighbors Regression)- 주어진 데이터 포인트에서 가장 가까운 K개의 이웃 데이터의 평균으로 예측값을 결정.
- 간단하면서도 데이터 자체만을 활용한 추정(비모수적 추정

Data Analyst Challenge